大数据最新DolphinScheduler海豚调度教程_海豚调度利用阐明
例如,A流程为周报任务,B、C流程为天任务,A任务需要B、C任务在上周的每一天都实行乐成,如图示:https://img-blog.csdnimg.cn/img_convert/17dde7eb44f86c44865fa520d0d590fc.png
如果,周报A同时还需要自身在上周二实行乐成:
https://img-blog.csdnimg.cn/img_convert/dbcd713bfcf352789680b9a6e7ddbb7c.png
存储过程节点
[*]根据选择的数据源,实行存储过程。
拖动工具栏中的https://img-blog.csdnimg.cn/img_convert/edf6d9cdda31458c944319ac5cc11b33.png任务节点到画板中,如下图所示:
https://img-blog.csdnimg.cn/img_convert/593833ad328ff174f20677a2410e1c52.png
[*]数据源:存储过程的数据源类型支持MySQL和POSTGRESQL两种,选择对应的数据源
[*]方法:是存储过程的方法名称
[*]自定义参数:存储过程的自定义参数类型支持IN、OUT两种,数据类型支持VARCHAR、INTEGER、LONG、FLOAT、DOUBLE、DATE、TIME、TIMESTAMP、BOOLEAN九种数据类型
SQL节点
[*]拖动工具栏中的https://img-blog.csdnimg.cn/img_convert/22a30e2a039da4b62b26acc1d2cf30d7.png任务节点到画板中
[*]非查询SQL功能:编辑非查询SQL任务信息,sql类型选择非查询,如下图所示:
https://img-blog.csdnimg.cn/img_convert/81522239973038067bf5008ed10c7381.png
[*]查询SQL功能:编辑查询SQL任务信息,sql类型选择查询,选择表格或附件形式发送邮件到指定的收件人,如下图所示。
https://img-blog.csdnimg.cn/img_convert/ed1c5c3639222a79db2f30faae7c40fe.png
[*]数据源:选择对应的数据源
[*]sql类型:支持查询和非查询两种,查询是select类型的查询,是有结果集返回的,可以指定邮件关照为表格、附件或表格附件三种模板。非查询是没有结果集返回的,是针对update、delete、insert三种类型的利用。
[*]sql参数:输入参数格式为key1=value1;key2=value2…
[*]sql语句:SQL语句
[*]UDF函数:对于HIVE类型的数据源,可以引用资源中心中创建的UDF函数,其他类型的数据源暂不支持UDF函数。
[*]自定义参数:SQL任务类型,而存储过程是自定义参数次序的给方法设置值自定义参数类型和数据类型同存储过程任务类型一样。区别在于SQL任务类型自定义参数会更换sql语句中${变量}。
[*]前置sql:前置sql在sql语句之前实行。
[*]后置sql:后置sql在sql语句之后实行。
SPARK节点
[*]通过SPARK节点,可以直接直接实行SPARK步伐,对于spark节点,worker会利用spark-submit方式提交任务
拖动工具栏中的https://img-blog.csdnimg.cn/img_convert/90c0746960a952a6424566631b1de474.png任务节点到画板中,如下图所示:
https://img-blog.csdnimg.cn/img_convert/595cc92e3276bdf2acc45d6e2d9dc05d.png
[*]步伐类型:支持JAVA、Scala和Python三种语言
[*]主函数的class:是Spark步伐的入口Main Class的全路径
[*]主jar包:是Spark的jar包
[*]摆设方式:支持yarn-cluster、yarn-client和local三种模式
[*]Driver内核数:可以设置Driver内核数及内存数
[*]Executor数量:可以设置Executor数量、Executor内存数和Executor内核数
[*]下令行参数:是设置Spark步伐的输入参数,支持自定义参数变量的更换。
[*]其他参数:支持 --jars、–files、–archives、–conf格式
[*]资源:如果其他参数中引用了资源文件,需要在资源中选择指定
[*]自定义参数:是MR局部的用户自定义参数,会更换脚本中以${变量}的内容
注意:JAVA和Scala只是用来标识,没有区别,如果是Python开辟的Spark则没有主函数的class,其他都是一样
MapReduce(MR)节点
[*]利用MR节点,可以直接实行MR步伐。对于mr节点,worker会利用hadoop jar方式提交任务
拖动工具栏中的https://img-blog.csdnimg.cn/img_convert/027059eee0f03bf1de06c7d99dbefa87.png任务节点到画板中,如下图所示:
JAVA步伐
https://img-blog.csdnimg.cn/img_convert/9d4869c93e086920b7601d5c0143c12c.png
[*]主函数的class:是MR步伐的入口Main Class的全路径
[*]步伐类型:选择JAVA语言
[*]主jar包:是MR的jar包
[*]下令行参数:是设置MR步伐的输入参数,支持自定义参数变量的更换
[*]其他参数:支持 –D、-files、-libjars、-archives格式
[*]资源: 如果其他参数中引用了资源文件,需要在资源中选择指定
[*]自定义参数:是MR局部的用户自定义参数,会更换脚本中以${变量}的内容
Python步伐
[外链图片转存失败,源站大概有防盗链机制,发起将图片保存下来直接上传(img-p1oexZeW-1683205971444)(null)]
[*]步伐类型:选择Python语言
[*]主jar包:是运行MR的Python jar包
[*]其他参数:支持 –D、-mapper、-reducer、-input -output格式,这里可以设置用户自定义参数的输入,比如:
[*]-mapper “mapper.py 1” -file mapper.py -reducer reducer.py -file reducer.py –input /journey/words.txt -output /journey/out/mr/${currentTimeMillis}
[*]其中 -mapper 后的 mapper.py 1是两个参数,第一个参数是mapper.py,第二个参数是1
[*]资源: 如果其他参数中引用了资源文件,需要在资源中选择指定
[*]自定义参数:是MR局部的用户自定义参数,会更换脚本中以${变量}的内容
Python节点
[*]利用python节点,可以直接实行python脚本,对于python节点,worker会利用python **方式提交任务。
拖动工具栏中的https://img-blog.csdnimg.cn/img_convert/08dee46026b3e34c5353d2fc765434eb.png任务节点到画板中,如下图所示:
https://img-blog.csdnimg.cn/img_convert/dce69d1aec048d01c8d9569581b0c31a.png
[*]脚本:用户开辟的Python步伐
[*]环境名称:实行Python步伐的表明器路径,指定运行脚本的表明器。当你需要利用 Python 虚拟环境 时,可以通过创建不同的环境名称来实现。
[*]资源:是指脚本中需要调用的资源文件列表
[*]自定义参数:是Python局部的用户自定义参数,会更换脚本中以${变量}的内容
[*]注意:若引入资源目录树下的python文件,需添加 __init__.py 文件
Flink节点
[*]拖动工具栏中的https://img-blog.csdnimg.cn/img_convert/de3e9645893ed243411875a5c6232f31.png任务节点到画板中,如下图所示:
[外链图片转存失败,源站大概有防盗链机制,发起将图片保存下来直接上传(img-D8Zut6Pc-1683205976158)(null)]
[*]步伐类型:支持JAVA、Scala和Python三种语言
[*]主函数的class:是Flink步伐的入口Main Class的全路径
[*]主jar包:是Flink的jar包
[*]摆设方式:支持cluster、local三种模式
[*]slot数量:可以设置slot数
[*]taskManage数量:可以设置taskManage数
[*]jobManager内存数:可以设置jobManager内存数
[*]taskManager内存数:可以设置taskManager内存数
[*]下令行参数:是设置Spark步伐的输入参数,支持自定义参数变量的更换。
[*]其他参数:支持 --jars、–files、–archives、–conf格式
[*]资源:如果其他参数中引用了资源文件,需要在资源中选择指定
[*]自定义参数:是Flink局部的用户自定义参数,会更换脚本中以${变量}的内容
注意:JAVA和Scala只是用来标识,没有区别,如果是Python开辟的Flink则没有主函数的class,其他都是一样
http节点
[*]拖动工具栏中的https://img-blog.csdnimg.cn/img_convert/39ff7c8a40e4a76c7de5115cc040ac67.png任务节点到画板中,如下图所示:
https://img-blog.csdnimg.cn/img_convert/8de0bc5a0d33e8161bec883f4eb37a1e.png
[*]节点名称:一个工作流定义中的节点名称是唯一的。
[*]运行标志:标识这个节点是否能正常调度,如果不需要实行,可以打开禁止实行开关。
[*]描述信息:描述该节点的功能。
[*]任务优先级:worker线程数不足时,根据优先级从高到低依次实行,优先级一样时根据先进先出原则实行。
[*]Worker分组:任务分配给worker组的机器机实行,选择Default,会随机选择一台worker机实行。
[*]失败重试次数:任务失败重新提交的次数,支持下拉和手填。
[*]失败重试间隔:任务失败重新提交任务的时间间隔,支持下拉和手填。
[*]超时告警:勾选超时告警、超时失败,当任务超过"超时时长"后,会发送告警邮件并且任务实行失败.
[*]哀求地点:http哀求URL。
[*]哀求类型:支持GET、POSt、HEAD、PUT、DELETE。
[*]哀求参数:支持Parameter、Body、Headers。
[*]校验条件:支持默认响应码、自定义响应码、内容包含、内容不包含。
[*]校验内容:当校验条件选择自定义响应码、内容包含、内容不包含时,需填写校验内容。
[*]自定义参数:是http局部的用户自定义参数,会更换脚本中以${变量}的内容。
DATAX节点
[*]拖动工具栏中的https://img-blog.csdnimg.cn/img_convert/df2f2b5ed285f0813ce4f240a1e2d6a3.png任务节点到画板中
https://img-blog.csdnimg.cn/img_convert/5293d693649d998af9278d4f3f0d9b21.png
[*]自定义模板:打开自定义模板开关时,可以自定义datax节点的json配置文件内容(实用于控件配置不满足需求时)
[*]数据源:选择抽取数据的数据源
[*]sql语句:目标库抽取数据的sql语句,节点实行时自动解析sql查询列名,映射为目标表同步列名,源表和目标表列名不一致时,可以通过列别名(as)转换
[*]目标库:选择数据同步的目标库
[*]目标表:数据同步的目标表名
[*]前置sql:前置sql在sql语句之前实行(目标库实行)。
[*]后置sql:后置sql在sql语句之后实行(目标库实行)。
[*]json:datax同步的json配置文件
[*]自定义参数:SQL任务类型,而存储过程是自定义参数次序的给方法设置值自定义参数类型和数据类型同存储过程任务类型一样。区别在于SQL任务类型自定义参数会更换sql语句中${变量}。
参数
内置参数
根本内置参数
变量名声明方式寄义system.biz.date${system.biz.date}一样平常调度实例定时的定时时间前一天,格式为 yyyyMMdd,补数据时,该日期 +1system.biz.curdate${system.biz.curdate}一样平常调度实例定时的定时时间,格式为 yyyyMMdd,补数据时,该日期 +1system.datetime${system.datetime}一样平常调度实例定时的定时时间,格式为 yyyyMMddHHmmss,补数据时,该日期 +1 衍生内置参数
[*]支持代码中自定义变量名,声明方式:${变量名}。可以是引用 “体系参数”
[*]我们定义这种基准变量为
[
.
.
.
]
格式的,
[…] 格式的,
[…]格式的, 是可以任意分解组合的,比如:$, $, $ 等
[*]也可以通过以下两种方式:
1.利用add_months()函数,该函数用于加减月份, 第一个入口参数为,表示返回时间的格式 第二个入口参数为月份偏移量,表示加减多少个月
+ 后 N 年:$
+ 前 N 年:$
+ 后 N 月:$
+ 前 N 月:$
2.直接加减数字 在自定义格式后直接“+/-”数字
+ 后 N 周:$
+ 前 N 周:$
+ 后 N 天:$
+ 前 N 天:$
+ 后 N 小时:$
+ 前 N 小时:$
+ 后 N 分钟:$
+ 前 N 分钟:$
全局参数
作用域
在工作流定义页面配置的参数,作用于该工作流中全部的任务
利用方式
全局参数配置方式如下:在工作流定义页面,点击“设置全局”右边的加号,填写对应的变量名称和对应的值,保存即可
https://img-blog.csdnimg.cn/img_convert/48e91579bb4cdff35b93fa61e05a3e5d.png
https://img-blog.csdnimg.cn/img_convert/fe03d79023b0b5ae7b59886309b3388b.png
这里定义的global_bizdate参数可以被其它任一节点的局部参数引用,并设置global_bizdate的value为通过引用体系参数system.biz.date获得的值
当地参数
作用域
在任务定义页面配置的参数,默认作用域仅限该任务,如果配置了参数传递则可将该参数作用到下游任务中。
利用方式
当地参数配置方式如下:在任务定义页面,点击“自定义参数”右边的加号,填写对应的变量名称和对应的值,保存即可
https://img-blog.csdnimg.cn/img_convert/69fc7bd55b7de6e8361bd285c2b90722.png
https://img-blog.csdnimg.cn/img_convert/9764d000beb546d84fbd2d6784f98a61.png
如果想要在当地参数中调用体系内置参数,将内置参数对应的值填到value中,如上图中的${biz_date}以及${curdate}
参数的引用
DolphinScheduler 提供参数间相互引用的本领,包括:当地参数引用全局参数、上下游参数传递。因为有引用的存在,就涉及当参数名相同时,参数的优先级问题,详见参数优先级
当地任务引用全局参数
当地任务引用全局参数的前提是,你已经定义了全局参数,利用方式和当地参数中的利用方式雷同,但是参数的值需要配置玉成局参数中的key
https://img-blog.csdnimg.cn/img_convert/9764d000beb546d84fbd2d6784f98a61.png
如上图中的${biz_date}以及${curdate},就是当地参数引用全局参数的例子。观察上图的末了一行,local_param_bizdate通过
g
l
o
b
a
l
b
i
z
d
a
t
e
来引用全局参数,在
s
h
e
l
l
脚本中可以通过
{global_bizdate}来引用全局参数,在shell脚本中可以通过
globalbizdate来引用全局参数,在shell脚本中可以通过{local_param_bizdate}来引全局变量 global_bizdate的值,或通过JDBC直接将local_param_bizdate的值set进去。同理,local_param通过{local_param}引用上一节中定义的全局参数。biz_date、biz_curdate、system.datetime都是用户自定义的参数,通过{全局参数}进行赋值。
上游任务传递给下游任务
DolphinScheduler 允许在任务间进行参数传递,目前传递方向仅支持上游单向传递给下游。目前支持这个特性的任务类型有:
[*]Shell
[*]SQL
[*]Procedure
当定义上游节点时,如果有需要将该节点的结果传递给有依赖关系的下游节点,需要在【当前节点设置】的【自定义参数】设置一个方向是 OUT 的变量。目前我们主要针对 SQL 和 SHELL 节点做了可以向下传递参数的功能。
SQL
prop 为用户指定;方向选择为 OUT,只有当方向为 OUT 时才会被定义为变量输出;数据类型可以根据需要选择不同数据布局;value 部分不需要填写。
如果 SQL 节点的结果只有一行,一个或多个字段,prop 的名字需要和字段名称一致。数据类型可选择为除 LIST 以外的其他类型。变量会选择 SQL 查询结果中的列名中与该变量名称相同的列对应的值。
如果 SQL 节点的结果为多行,一个或多个字段,prop 的名字需要和字段名称一致。数据类型选择为LIST。获取到 SQL 查询结果后会将对应列转化为 LIST,并将该结果转化为 JSON 后作为对应变量的值。
我们再以上图中包含 SQL 节点的流程举例阐明:
上图中节点【createParam1】的定义如下:
https://img-blog.csdnimg.cn/img_convert/639a65a8f32f8c2a03278acc9415c09e.png
节点【createParam2】的定义如下:
https://img-blog.csdnimg.cn/img_convert/d0bd423b32c88a65ed5affd1f58dc771.png
您可以在【工作流实例】页面,找到对应的节点实例,便可以查察该变量的值。
节点实例【createParam1】如下:
https://img-blog.csdnimg.cn/img_convert/216aaf9d9849b0a59977ddec1c8470ec.png
这里固然 “id” 的值会即是 12.
我们再来看节点实例【createParam2】的情况。
https://img-blog.csdnimg.cn/img_convert/d5778b4344edeb052153f7c8776b0b61.png
这里只有 “id” 的值。只管用户定义的 sql 查到的是 “id” 和 “database_name” 两个字段,但是由于只定义了一个为 out 的变量 “id”,所以只会设置一个变量。由于显示的原因,这里已经替您查好了该 list 的长度为 10。
Shell
prop 为用户指定;方向选择为 OUT,只有当方向为 OUT 时才会被定义为变量输出;数据类型可以根据需要选择不同数据布局;value 部分不需要填写。
用户需要传递参数,在定义 shell 脚本时,需要输特殊式为 ${setValue(key=value)} 的语句,key 为对应参数的 prop,value 为该参数的值。
例如下图中, 通过 echo '${setValue(trans=hello trans)}', 将’trans’设置为"hello trans", 在下游任务中就可以利用trans这个变量了:
https://img-blog.csdnimg.cn/img_convert/b0fa3884be57ca179d7cf7580ef82830.png
shell 节点定义时当日记检测到 ${setValue(key=value1)} 的格式时,会将 value1 赋值给 key,下游节点便可以直接利用变量 key 的值。同样,您可以在【工作流实例】页面,找到对应的节点实例,便可以查察该变量的值。
[外链图片转存失败,源站大概有防盗链机制,发起将图片保存下来直接上传(img-6pUPPoeR-1683205971021)(null)]
参数优先级
DolphinScheduler 中所涉及的参数值的定义大概来自三种类型:
[*]全局参数:在工作流保存页面定义时定义的变量
[*]上游任务传递的参数:上游任务传递过来的参数
[*]当地参数:节点的自有变量,用户在“自定义参数”定义的变量,并且用户可以在工作流定义时定义该部分变量的值
因为参数的值存在多个来源,当参数名相同时,就需要会存在参数优先级的问题。DolphinScheduler 参数的优先级从高到低为:全局参数 > 上游任务传递的参数 > 当地参数
在上游任务传递的参数的情况下,由于上游大概存在多个任务向下游传递参数。当上游传递的参数名称相同时:
[*]下游节点会优先利用值为非空的参数
[*]如果存在多个值为非空的参数,则按照上游任务的完成时间排序,选择完成时间最早的上游任务对应的参数
例子
下面例子向你展示如何利用任务参数传递的优先级问题
1:先以 shell 节点表明第一种情况
https://img-blog.csdnimg.cn/img_convert/2fcfc18fb431c2ff506e844577046786.png
节点 【useParam】可以利用到节点【createParam】中设置的变量。而节点 【useParam】与节点【noUseParam】中并没有依赖关系,所以并不会获取到节点【noUseParam】的变量。上图中只是以 shell 节点作为例子,其他类型节点具有相同的利用规则。
https://img-blog.csdnimg.cn/img_convert/95f13d02fc8b4314dbc3b5e947183772.png
其中节点【createParam】在利用变量时直接利用即可。另外该节点设置了 “key” 和 “key1” 两个变量,这里用户用定义了一个与上游节点传递的变量名相同的变量 key1,并且复制了值为 “12”,但是由于我们设置的优先级的关系,这里的值 “12” 会被抛弃,最终利用上游节点设置的变量值。
2:我们再以 sql 节点来表明另外一种情况
https://img-blog.csdnimg.cn/img_convert/c4f34e28924dbb19ffba486a435badf5.png
节点【use_create】的定义如下:
https://img-blog.csdnimg.cn/img_convert/2f3b358977c663f1e4c950f56592f78d.png
“status” 是当前节点设置的节点的自有变量。但是用户在保存时也同样设置了 “status” 变量,并且赋值为 -1。那在该 SQL 实行时,status 的值为优先级更高的 -1。抛弃了节点的自有变量的值。
这里的 “id” 是上游节点设置的变量,用户在节点【createParam1】、节点【createParam2】中设置了相同参数名 “id” 的参数。而节点【use_create】中利用了开始结束的【createParam1】的值。
数据源中心
数据源
数据源中心支持MySQL、POSTGRESQL、HIVE/IMPALA、SPARK、CLICKHOUSE、ORACLE、SQLSERVER等数据源。
[*]点击“数据源中心->创建数据源”,根据需求创建不同类型的数据源。
[*]点击“测试连接”,测试数据源是否可以连接乐成。
MySQL数据源
[*]数据源:选择MYSQL
[*]数据源名称:输入数据源的名称
[*]描述:输入数据源的描述
[*]IP主机名:输入连接MySQL的IP
[*]端口:输入连接MySQL的端口
[*]用户名:设置连接MySQL的用户名
[*]暗码:设置连接MySQL的暗码
[*]数据库名:输入连接MySQL的数据库名称
[*]Jdbc连接参数:用于MySQL连接的参数设置,以JSON形式填写
https://img-blog.csdnimg.cn/img_convert/7cb50daba3b7cc498b0ec62abeacf4a9.png
POSTGRESQL数据源
[*]数据源:选择POSTGRESQL
[*]数据源名称:输入数据源的名称
[*]描述:输入数据源的描述
[*]IP/主机名:输入连接POSTGRESQL的IP
[*]端口:输入连接POSTGRESQL的端口
[*]用户名:设置连接POSTGRESQL的用户名
[*]暗码:设置连接POSTGRESQL的暗码
[*]数据库名:输入连接POSTGRESQL的数据库名称
[*]Jdbc连接参数:用于POSTGRESQL连接的参数设置,以JSON形式填写
https://img-blog.csdnimg.cn/img_convert/856cc68ccbc7f67d87db71b4d85d34e0.png
HIVE数据源
利用HiveServer2
https://img-blog.csdnimg.cn/img_convert/ecadea30a620392cc9d96783353e0d09.png
[*]数据源:选择HIVE
[*]数据源名称:输入数据源的名称
[*]描述:输入数据源的描述
[*]IP/主机名:输入连接HIVE的IP
[*]端口:输入连接HIVE的端口
[*]用户名:设置连接HIVE的用户名
[*]暗码:设置连接HIVE的暗码
[*]数据库名:输入连接HIVE的数据库名称
[*]Jdbc连接参数:用于HIVE连接的参数设置,以JSON形式填写
利用HiveServer2 HA Zookeeper
https://img-blog.csdnimg.cn/img_convert/c9aab41bc83837199833145852f55a38.png
注意:如果开启了kerberos,则需要填写 Principal
https://img-blog.csdnimg.cn/img_convert/9b4d1e396dabd15e56ccc1ab90260220.png
Spark数据源
https://img-blog.csdnimg.cn/img_convert/374e421ccc5e6b1147029d254d1dd2a9.png
[*]数据源:选择Spark
[*]数据源名称:输入数据源的名称
[*]描述:输入数据源的描述
[*]IP/主机名:输入连接Spark的IP
[*]端口:输入连接Spark的端口
[*]用户名:设置连接Spark的用户名
[*]暗码:设置连接Spark的暗码
[*]数据库名:输入连接Spark的数据库名称
[*]Jdbc连接参数:用于Spark连接的参数设置,以JSON形式填写
注意:如果开启了kerberos,则需要填写 Principal
https://img-blog.csdnimg.cn/img_convert/296a3b824c5bebef03d4adf9f0110091.png
告警
如何创建告警插件以及告警组
在2.0.0版本中,用户需要创建告警实例,然后同告警组进行关联,一个告警组可以利用多个告警实例,我们会逐一进行进行告警关照。
首先需要进入到安全中心,选择告警组管理,然后点击左侧的告警实例管理,然后创建一个告警实例,然后选择对应的告警插件,填写相关告警参数。
然后选择告警组管理,创建告警组,选择相应的告警实例即可。
https://img-blog.csdnimg.cn/img_convert/a7960997154f5c85192d0395f2af5b52.png https://img-blog.csdnimg.cn/img_convert/8171fd1c34bebd554d237430b63e5d94.png https://img-blog.csdnimg.cn/img_convert/1b35a92566a9f226eaee3a1aae7c8ed0.png https://img-blog.csdnimg.cn/img_convert/96c2601803bad00e40f8c70971694943.png
企业微信
如果您需要利用到企业微信进行告警,请在安装完成后,修改 alert.properties 文件,然后重启 alert 服务即可。企业微信的配置样例如下
# 设置企业微信告警功能是否开启:开启为 true,否则为 false
enterprise.wechat.enable="true"
# 设置 corpid,每个企业都拥有唯一的 corpid,获取此信息可在管理后台 “我的企业” - “企业信息” 下查看 “企业 ID”(需要有管理员权限)
enterprise.wechat.corp.id="xxx"
# 设置 secret,secret 是企业应用里面用于保障数据安全的 “钥匙”,每一个应用都有一个独立的访问密钥
enterprise.wechat.secret="xxx"
# 设置 agentid,每个应用都有唯一的 agentid。在管理后台 -> “应用与小程序” -> “应用”,点进某个应用,即可看到 agentid
enterprise.wechat.agent.id="xxxx"
# 设置 userid,多个用逗号分隔。每个成员都有唯一的 userid,即所谓 “帐号”。在管理后台 -> “通讯录” -> 点进某个成员的详情页,可以看到
enterprise.wechat.users=zhangsan,lisi
# 获取 access\_token 的地址,使用如下例子无需修改
enterprise.wechat.token.url=https://qyapi.weixin.qq.com/cgi-bin/gettoken?corpid={corpId}&corpsecret={secret}
# 发送应用消息地址,使用如下例子无需改动
enterprise.wechat.push.url=https://qyapi.weixin.qq.com/cgi-bin/message/send?access_token={token}
# 发送消息格式,无需改动
enterprise.wechat.user.send.msg={\"touser\":\"{toUser}\",\"agentid\":\"{agentId}\",\"msgtype\":\"markdown\",\"markdown\":{\"content\":\"{msg}\"}}
资源中心
如果需要用到资源上传功能,针对单机可以选择当地文件目录作为上传文件夹(此利用不需要摆设 Hadoop)。固然也可以选择上传到 Hadoop or MinIO 集群上,此时则需要有Hadoop (2.6+) 大概 MinIO 等相关环境
*注意:*
[*]如果用到资源上传的功能,那么 安装摆设中,摆设用户需要有这部分的利用权限
[*]如果 Hadoop 集群的 NameNode 配置了 HA 的话,需要开启 HDFS 类型的资源上传,同时需要将 Hadoop 集群下的 core-site.xml 和 hdfs-site.xml 复制到 /opt/dolphinscheduler/conf,非 NameNode HA 跳过次步骤
hdfs资源配置
[*]上传资源文件和udf函数,全部上传的文件和资源都会被存储到hdfs上,所以需要以下配置项:
conf/common.properties
# Users who have permission to create directories under the HDFS root path
hdfs.root.user=hdfs
# data base dir, resource file will store to this hadoop hdfs path, self configuration, please make sure the directory exists on hdfs and have read write permissions。"/dolphinscheduler" is recommended
resource.upload.path=/dolphinscheduler
# resource storage type : HDFS,S3,NONE
resource.storage.type=HDFS
# whether kerberos starts
hadoop.security.authentication.startup.state=false
# java.security.krb5.conf path
java.security.krb5.conf.path=/opt/krb5.conf
# loginUserFromKeytab user
login.user.keytab.username=hdfs-mycluster@ESZ.COM
# loginUserFromKeytab path
login.user.keytab.path=/opt/hdfs.headless.keytab
# if resource.storage.type is HDFS,and your Hadoop Cluster NameNode has HA enabled, you need to put core-site.xml and hdfs-site.xml in the installPath/conf directory. In this example, it is placed under /opt/soft/dolphinscheduler/conf, and configure the namenode cluster name; if the NameNode is not HA, modify it to a specific IP or host name.
# if resource.storage.type is S3,write S3 address,HA,for example :s3a://dolphinscheduler,
# Note,s3 be sure to create the root directory /dolphinscheduler
fs.defaultFS=hdfs://mycluster:8020
#resourcemanager ha note this need ips , this empty if single
yarn.resourcemanager.ha.rm.ids=192.168.xx.xx,192.168.xx.xx
# If it is a single resourcemanager, you only need to configure one host name. If it is resourcemanager HA, the default configuration is fine
yarn.application.status.address=http://xxxx:8088/ws/v1/cluster/apps/%s
文件管理
是对各种资源文件的管理,包括创建基本的txt/log/sh/conf/py/java等文件、上传jar包等各种类型文件,可进行编辑、重定名、下载、删除等利用。
https://img-blog.csdnimg.cn/img_convert/d006f1f4fb65558ea47967bc21d164a3.png
[*]创建文件
文件格式支持以下几种类型:txt、log、sh、conf、cfg、py、java、sql、xml、hql、properties
https://img-blog.csdnimg.cn/img_convert/7325d6fb2e3a0e447939b578fcab2d45.png
[*]上传文件
上传文件:点击"上传文件"按钮进行上传,将文件拖拽到上传地区,文件名会自动以上传的文件名称补全
https://img-blog.csdnimg.cn/img_convert/eddc8ffd9a59029101d7a971a5593e6d.png
[*]文件查察
对可查察的文件类型,点击文件名称,可查察文件详情
[外链图片转存失败,源站大概有防盗链机制,发起将图片保存下来直接上传(img-rUFXelKK-1683205976507)(null)]
[*]下载文件
点击文件列表的"下载"按钮下载文件大概在文件详情中点击右上角"下载"按钮下载文件
[*]文件重定名
https://img-blog.csdnimg.cn/img_convert/c6fe18198c9adce825391c3f00450279.png
[*]删除
文件列表->点击"删除"按钮,删除指定文件
UDF管理
资源管理
资源管理和文件管理功能雷同,不同之处是资源管理是上传的UDF函数,文件管理上传的是用户步伐,脚本及配置文件 利用功能:重定名、下载、删除。
[*]上传udf资源
和上传文件相同。
函数管理
[*]创建udf函数
点击“创建UDF函数”,输入udf函数参数,选择udf资源,点击“提交”,创建udf函数。 目前只支持HIVE的临时UDF函数
[*]UDF函数名称:输入UDF函数时的名称
[*]包名类名:输入UDF函数的全路径
[*]UDF资源:设置创建的UDF对应的资源文件
https://img-blog.csdnimg.cn/img_convert/6e12ba360807173164123fd97d980f4a.png
监控中心
服务管理
[*]服务管理主要是对体系中的各个服务的康健状态和基本信息的监控和显示
master监控
[*]主要是master的相关信息。
https://img-blog.csdnimg.cn/img_convert/dd58a96dee98dabdfea6ef2bcb9ad42f.png
worker监控
[*]主要是worker的相关信息。
https://img-blog.csdnimg.cn/img_convert/f47fb90db30ba0eb1e24ea182fa101d7.png
Zookeeper监控
[*]主要是zookpeeper中各个worker和master的相关配置信息。
https://img-blog.csdnimg.cn/img_convert/19a1bf330004540856aece0de991183d.png
DB监控
[*]主要是DB的康健状态
https://img-blog.csdnimg.cn/img_convert/843c0514f5def3ca876aa98ede0d5b82.png
统计管理
https://img-blog.csdnimg.cn/img_convert/169697ee36f6d9ecd9b3efed05cd4738.png
[*]待实行下令数:统计t_ds_command表的数据
[*]实行失败的下令数:统计t_ds_error_command表的数据
[*]待运行任务数:统计Zookeeper中task_queue的数据
[*]待杀死任务数:统计Zookeeper中task_kill的数据
安全中心(权限体系)
[*]安全中心只有管理员账户才有权限利用,分别有队列管理、租户管理、用户管理、告警组管理、worker分组管理、令牌管理等功能,在用户管理模块可以对资源、数据源、项目等授权
[*]管理员登录,默认用户名暗码:admin/dolphinscheduler123
创建队列
[*]队列是在实行spark、mapreduce等步伐,需要用到“队列”参数时利用的。
[*]管理员进入安全中心->队列管理页面,点击“创建队列”按钮,创建队列。
https://img-blog.csdnimg.cn/img_convert/df2fbb19c9f43a7724b780381fda9d1d.png
添加租户
[*]租户对应的是Linux的用户,用于worker提交作业所利用的用户。如果linux没有这个用户,则会导致任务运行失败。你可以通过修改 worker.properties 配置文件中参数 worker.tenant.auto.create=true 实现当 linux 用户不存在时自动创建该用户。worker.tenant.auto.create=true 参数会要求 worker 可以免密运行 sudo 下令。
[*]租户编码:租户编码是Linux上的用户,唯一,不能重复
[*]管理员进入安全中心->租户管理页面,点击“创建租户”按钮,创建租户。
https://img-blog.csdnimg.cn/img_convert/0078c89e2d6705647f9f0c34129a54a9.png
创建平凡用户
[*]用户分为管理员用户和平凡用户
[*]管理员有授权和用户管理等权限,没有创建项目和工作流定义的利用的权限。
[*]平凡用户可以创建项目和对工作流定义的创建,编辑,实行等利用。
[*]注意:如果该用户切换了租户,则该用户所在租户下全部资源将复制到切换的新租户下。
[*]进入安全中心->用户管理页面,点击“创建用户”按钮,创建用户。
https://img-blog.csdnimg.cn/img_convert/c7d648485c211c42169032b3439bf75b.png
编辑用户信息
[*]管理员进入安全中心->用户管理页面,点击"编辑"按钮,编辑用户信息。
[*]平凡用户登录后,点击用户名下拉框中的用户信息,进入用户信息页面,点击"编辑"按钮,编辑用户信息。
修改用户暗码
[*]管理员进入安全中心->用户管理页面,点击"编辑"按钮,编辑用户信息时,输入新暗码修改用户暗码。
[*]平凡用户登录后,点击用户名下拉框中的用户信息,进入修改暗码页面,输入暗码并确认暗码后点击"编辑"按钮,则修改暗码乐成。
创建告警组
[*]告警组是在启动时设置的参数,在流程结束以后会将流程的状态和其他信息以邮件形式发送给告警组。
[*]管理员进入安全中心->告警组管理页面,点击“创建告警组”按钮,创建告警组。
https://img-blog.csdnimg.cn/img_convert/4c5509b43b77c1aaa358738a2f8e37ca.png
令牌管理
由于后端接口有登录检查,令牌管理提供了一种可以通过调用接口的方式对体系进行各种利用。
[*]管理员进入安全中心->令牌管理页面,点击“创建令牌”按钮,选择失效时间与用户,点击"生成令牌"按钮,点击"提交"按钮,则选择用户的token创建乐成。
[外链图片转存失败,源站大概有防盗链机制,发起将图片保存下来直接上传(img-MQj8OzXt-1683205975817)(null)]
[*]平凡用户登录后,点击用户名下拉框中的用户信息,进入令牌管理页面,选择失效时间,点击"生成令牌"按钮,点击"提交"按钮,则该用户创建token乐成。
[*]调用示例:
/\*\*
\* test token
\*/
publicvoid doPOSTParam()throws Exception{
// create HttpClient
CloseableHttpClient httpclient = HttpClients.createDefault();
// create http post request
HttpPost httpPost = new HttpPost("http://127.0.0.1:12345/escheduler/projects/create");
httpPost.setHeader("token", "123");
// set parameters
List<NameValuePair> parameters = new ArrayList<NameValuePair>();
parameters.add(new BasicNameValuePair("projectName", "qzw"));
parameters.add(new BasicNameValuePair("desc", "qzw"));
UrlEncodedFormEntity formEntity = new UrlEncodedFormEntity(parameters);
httpPost.setEntity(formEntity);
CloseableHttpResponse response = null;
try {
// execute
response = httpclient.execute(httpPost);
// response status code 200
if (response.getStatusLine().getStatusCode() == 200) {
String content = EntityUtils.toString(response.getEntity(), "UTF-8");
System.out.println(content);
}
} finally {
if (response != null) {
response.close();
}
httpclient.close();
}
}
授予权限
[*]授予权限包括项目权限,资源权限,数据源权限,UDF函数权限。
[*]管理员可以对平凡用户进行非其创建的项目、资源、数据源和UDF函数进行授权。因为项目、资源、数据源和UDF函数授权方式都是一样的,所以以项目授权为例先容。
[*]注意:对于用户本身创建的项目,该用户拥有全部的权限。则项目列表和已选项目列表中不会显示。
[*]管理员进入安全中心->用户管理页面,点击需授权用户的“授权”按钮,如下图所示:
https://img-blog.csdnimg.cn/img_convert/516c96f7612e8d4ad6ac7e98b5bc4903.png
[*]选择项目,进行项目授权。
https://img-blog.csdnimg.cn/img_convert/cff2726a742ead5731983f20fbad1721.png
[*]资源、数据源、UDF函数授权同项目授权。
Worker分组
每个worker节点都会归属于本身的Worker分组,默认分组为default.
在任务实行时,可以将任务分配给指定worker分组,最终由该组中的worker节点实行该任务.
新增/更新 worker分组
[*]打开要设置分组的worker节点上的"conf/worker.properties"配置文件. 修改worker.groups参数.
[*]worker.groups参数后面对应的为该worker节点对应的分组名称,默以为default.
[*]如果该worker节点对应多个分组,则以逗号隔开.
示例:
worker.groups=default,test
[*]也可以在运行中修改worker所属的worker分组,如果修改乐成,worker就会利用这个新建的分组,忽略worker.properties中的配置。修改步骤为"安全中心 -> worker分组管理 -> 点击 ‘新建worker分组’ -> 输入’组名称’ -> 选择已有worker -> 点击’提交’"
环境管理
[*]在线配置Worker运行环境,一个Worker可以指定多个环境,每个环境等价于dolphinscheduler_env.sh文件.
[*]默认环境为dolphinscheduler_env.sh文件.
[*]在任务实行时,可以将任务分配给指定worker分组,根据worker分组选择对应的环境,最终由该组中的worker节点实行环境后实行该任务.
创建/更新 环境
[*]环境配置等价于dolphinscheduler_env.sh文件内配置
https://img-blog.csdnimg.cn/img_convert/2faee7e9d243f1fafdf91224fc968b97.png
利用 环境
[*]在工作流定义中创建任务节点选择Worker分组和Worker分组对应的环境,任务实行时Worker会先实行环境在实行任务.
https://img-blog.csdnimg.cn/img_convert/c488b2ac0ae22f3beb3ee86cfd7d444f.png
API 调用
配景
一般都是通过页面来创建项目、流程等,但是与第三方体系集成就需要通过调用 API 来管理项目、流程
利用步骤
创建 token
[*]登录调度体系,点击 “安全中心”,再点击左侧的 “令牌管理”,点击 “令牌管理” 创建令牌
https://img-blog.csdnimg.cn/img_convert/2f0d9f7ea50a6d0ddb0ad4d82ff490c8.png
[*]选择 “失效时间” (Token有效期),选择 “用户” (以指定的用户实行接口利用),点击 “生成令牌” ,拷贝 Token 字符串,然后点击 “提交”
https://img-blog.csdnimg.cn/img_convert/2b33de161d2e56a7bf3dffdf7ad10d54.png
利用 Token
[*]打开 API文档页面
地点:http://{api server ip}:12345/dolphinscheduler/doc.html?language=zh_CN&lang=cn
https://img-blog.csdnimg.cn/img_convert/00220628e2cf44f0b7c97dd96d887085.png
[*]选一个测试的接口,本次测试选取的接口是:查询全部项目
projects/query-project-list
[*]打开 Postman,填写接口地点,并在 Headers 中填写 Token,发送哀求后即可查察结果
token:刚刚生成的Token
https://img-blog.csdnimg.cn/img_convert/1705b6d3d0e4ec16be05d8eff9e49d9b.png
创建项目
这里以创建名为 “wudl-flink-test” 的项目为例
https://img-blog.csdnimg.cn/img_convert/1167345363ff7833aa4a800b8ec4ce01.png
https://img-blog.csdnimg.cn/img_convert/cbe8534ffdf259f8cd682f2800c48538.png
https://img-blog.csdnimg.cn/img_convert/1d516b47df409da06262588a2d118ad3.png
返回 msg 信息为 “success”,阐明我们已经乐成通过 API 的方式创建了项目。
如果您对创建项目标源码感兴趣,欢迎继承阅读下面内容
附:创建项目源码
https://img-blog.csdnimg.cn/img_convert/796c8eb8dccf77280516bba78a029fec.png
https://img-blog.csdnimg.cn/img_convert/58debf7d04340d88b446c1cf3d3c331d.png
Flink调用
调用 flink 利用步骤
创建队列
[*]登录调度体系,点击 “安全中心”,再点击左侧的 “队列管理”,点击 “队列管理” 创建队列
[*]填写队列名称和队列值,然后点击 “提交”
[外链图片转存失败,源站大概有防盗链机制,发起将图片保存下来直接上传(img-QOXUFbby-1683205974909)(null)]
创建租户
1.租户对应的是 linux 用户, 用户 worker 提交作业所使用的的用户, 如果 linux 没有这个用户, worker 会在执行脚本的时候创建这个用户
2.租户和租户编码都是唯一不能重复,好比一个人有名字有身份证号。
3.创建完租户会在 hdfs 对应的目录上有相关的文件夹。
https://img-blog.csdnimg.cn/img_convert/ee351e9e6c3c94fc08eb1fa6bec76e1a.png
创建用户
https://img-blog.csdnimg.cn/img_convert/4d6c46b6bd70497da3cce66de468ae51.png
创建 Token
[*]登录调度体系,点击 “安全中心”,再点击左侧的 “令牌管理”,点击 “令牌管理” 创建令牌
https://img-blog.csdnimg.cn/img_convert/5514bcef3079b6914cb501ac808d8876.png
[*]选择 “失效时间” (Token有效期),选择 “用户” (以指定的用户实行接口利用),点击 “生成令牌” ,拷贝 Token 字符串,然后点击 “提交”
https://img-blog.csdnimg.cn/img_convert/423ab0731ae2f21bebdf45f456d525cc.png
利用 Token
[*]打开 API文档页面
地点:http://{api server ip}:12345/dolphinscheduler/doc.html?language=zh_CN&lang=cn
https://img-blog.csdnimg.cn/img_convert/7b88a976ac0811367b0635c26bc193fc.png
[*]选一个测试的接口,本次测试选取的接口是:查询全部项目
projects/query-project-list
[*]打开 Postman,填写接口地点,并在 Headers 中填写 Token,发送哀求后即可查察结果
token: 刚刚生成的 Token
https://img-blog.csdnimg.cn/img_convert/2f81e99958f7c725cc5b40759a0dc616.png
用户授权
https://img-blog.csdnimg.cn/img_convert/83a3fd3b1c87f2f5cd8115321bf46a8f.png
用户登录
http://192.168.1.163:12345/dolphinscheduler/ui/#/monitor/servers/master
https://img-blog.csdnimg.cn/img_convert/8bf5732113b973e878a219f87fd4e4c3.png
资源上传
https://img-blog.csdnimg.cn/img_convert/3e8dd0a93b5b558982eff1d0716d72e7.png
创建工作流
https://img-blog.csdnimg.cn/img_convert/edb08255f44ea55bf2efc3451995c6f6.png
https://img-blog.csdnimg.cn/img_convert/f21b9c80415640b440b18ce4e2e2050c.png
https://img-blog.csdnimg.cn/img_convert/9e653747cfcb78444c75ef7192170c92.png
https://img-blog.csdnimg.cn/img_convert/908db756afd94b3fcbec4e6a0862ab84.png
查察实行结果
https://img-blog.csdnimg.cn/img_convert/538c6728b347967d96a881c96a198b63.png
查察日记结果
https://img-blog.csdnimg.cn/img_convert/c747407a9bb99b049f1fe001964fc711.png
(二)高级指南
体系架构计划
本章节先容Apache DolphinScheduler调度体系架构
1.体系架构
1.1 体系架构图
https://img-blog.csdnimg.cn/img_convert/0db12404839f2435e67a4ebf31871471.jpeg
体系架构图
1.2 启动流程活动图
https://img-blog.csdnimg.cn/img_convert/e3c445577a27f5d612b917997a57c4a7.png
启动流程活动图
1.3 架构阐明
[*]MasterServer
MasterServer采用分布式无中心计划理念,MasterServer主要负责 DAG 任务切分、任务提交监控,并同时监听其它MasterServer和WorkerServer的康健状态。 MasterServer服务启动时向Zookeeper注册临时节点,通过监听Zookeeper临时节点变化来进行容错处理。 MasterServer基于netty提供监听服务。
该服务内主要包含:
+ **Distributed Quartz**分布式调度组件,主要负责定时任务的启停操作,当quartz调起任务后,Master内部会有线程池具体负责处理任务的后续操作
+ **MasterSchedulerService**是一个扫描线程,定时扫描数据库中的 **command** 表,生成工作流实例,根据不同的**命令类型**进行不同的业务操作
+ **WorkflowExecuteThread**主要是负责DAG任务切分、任务提交、各种不同命令类型的逻辑处理,处理任务状态和工作流状态事件
+ **EventExecuteService**处理master负责的工作流实例所有的状态变化事件,使用线程池处理工作流的状态事件
+ **StateWheelExecuteThread**处理依赖任务和超时任务的定时状态更新
[*]WorkerServer
WorkerServer也采用分布式无中心计划理念,支持自定义任务插件,主要负责任务的实行和提供日记服务。 WorkerServer服务启动时向Zookeeper注册临时节点,并维持心跳。
该服务包含:
+ **WorkerManagerThread**主要通过netty领取master发送过来的任务,并根据不同任务类型调用**TaskExecuteThread**对应执行器。
+ **RetryReportTaskStatusThread**主要通过netty向master汇报任务状态,如果汇报失败,会一直重试汇报
+ **LoggerServer**是一个日志服务,提供日志分片查看、刷新和下载等功能
[*]Registry
注册中心,利用插件化实现,默认支持Zookeeper, 体系中的MasterServer和WorkerServer节点通过注册中心来进行集群管理和容错。另外体系还基于注册中心进行事件监听和分布式锁。
[*]Alert
提供告警相关功能,仅支持单机服务。支持自定义告警插件。
[*]API
API接口层,主要负责处理前端UI层的哀求。该服务统一提供RESTful api向外部提供哀求服务。 接口包括工作流的创建、定义、查询、修改、发布、下线、手工启动、停止、暂停、规复、从该节点开始实行等等。
[*]UI
体系的前端页面,提供体系的各种可视化利用界面,详见体系利用手册部分。
1.4 架构计划头脑
一、去中心化vs中心化
中心化头脑
中心化的计划理念比力简单,分布式集群中的节点按照角色分工,大要上分为两种角色:
https://img-blog.csdnimg.cn/img_convert/f8303f0f50d23a55c5e985b800380175.png
[*]Master的角色主要负责任务分发并监视Slave的康健状态,可以动态的将任务平衡到Slave上,以致Slave节点不至于“忙死”或”闲死”的状态。
[*]Worker的角色主要负责任务的实行工作并维护和Master的心跳,以便Master可以分配任务给Slave。
中心化头脑计划存在的问题:
[*]一旦Master出现了问题,则群龙无首,整个集群就会崩溃。为了解决这个问题,大多数Master/Slave架构模式都采用了主备Master的计划方案,可以是热备大概冷备,也可以是自动切换或手动切换,而且越来越多的新体系都开始具备自动推选切换Master的本领,以提升体系的可用性。
[*]另外一个问题是如果Scheduler在Master上,虽然可以支持一个DAG中不同的任务运行在不同的机器上,但是会产生Master的过负载。如果Scheduler在Slave上,则一个DAG中全部的任务都只能在某一台机器上进行作业提交,则并行任务比力多的时候,Slave的压力大概会比力大。
去中心化
https://img-blog.csdnimg.cn/img_convert/f688cb5712aaafbcdf242e2feeeb937e.png
[*]在去中心化计划里,通常没有Master/Slave的概念,全部的角色都是一样的,职位是划一的,全球互联网就是一个范例的去中心化的分布式体系,联网的任意节点装备down机,都只会影响很小范围的功能。
[*]去中心化计划的核心计划在于整个分布式体系中不存在一个区别于其他节点的”管理者”,因此不存在单点故障问题。但由于不存在” 管理者”节点所以每个节点都需要跟其他节点通信才得到必须要的机器信息,而分布式体系通信的不可靠性,则大大增加了上述功能的实现难度。
[*]实际上,真正去中心化的分布式体系并不多见。反而动态中心化分布式体系正在不断涌出。在这种架构下,集群中的管理者是被动态选择出来的,而不是预置的,并且集群在发生故障的时候,集群的节点会自发的举行"会议"来推选新的"管理者"去主持工作。最范例的案例就是ZooKeeper及Go语言实现的Etcd。
[*]DolphinScheduler的去中心化是Master/Worker注册到Zookeeper中,实现Master集群和Worker集群无中心,利用分片机制,公平分配工作流在master上实行,并通过不同的发送策略将任务发送给worker实行具体的任务
二、Master实行流程
[*]DolphinScheduler利用分片算法将command取模,根据master的排序id分配,master将拿到的command转换成工作流实例,利用线程池处理工作流实例
[*]DolphinScheduler对工作流的处理流程:
[*]通过UI大概API调用,启动工作流,持久化一条command到数据库中
[*]Master通过分片算法,扫描Command表,生成工作流实例ProcessInstance,同时删除Command数据
[*]Master利用线程池运行WorkflowExecuteThread,实行工作流实例的流程,包括构建DAG,创建任务实例TaskInstance,将TaskInstance通过netty发送给worker
[*]Worker收到任务以后,修改任务状态,并将实行信息返回Master
[*]Master收到任务信息,持久化到数据库,并且将状态变化事件存入EventExecuteService事件队列
[*]EventExecuteService根据事件队列调用WorkflowExecuteThread进行后续任务的提交和工作流状态的修改
三、容错计划
容错分为服务宕机容错和任务重试,服务宕机容错又分为Master容错和Worker容错两种情况
1. 宕机容错
服务容错计划依赖于ZooKeeper的Watcher机制,实现原理如图:
https://img-blog.csdnimg.cn/img_convert/a472c43f07bc8f6d2f3194e278c43ffd.png
其中Master监控其他Master和Worker的目录,如果监听到remove事件,则会根据具体的业务逻辑进行流程实例容错大概任务实例容错。
[*]Master容错流程图:
https://img-blog.csdnimg.cn/img_convert/1a80d4679d7a2f9ad33ece2a63cc4f90.png
ZooKeeper Master容错完成之后则重新由DolphinScheduler中Scheduler线程调度,遍历 DAG 找到”正在运行”和“提交乐成”的任务,对”正在运行”的任务监控其任务实例的状态,对”提交乐成”的任务需要判定Task Queue中是否已经存在,如果存在则同样监控任务实例的状态,如果不存在则重新提交任务实例。
[*]Worker容错流程图:
https://img-blog.csdnimg.cn/img_convert/31906de0ba1737aef245765f1cc93750.png
Master Scheduler线程一旦发现任务实例为” 需要容错”状态,则接受任务并进行重新提交。
注意:由于” 网络抖动”大概会使得节点短时间内失去和ZooKeeper的心跳,从而发生节点的remove事件。对于这种情况,我们利用最简单的方式,那就是节点一旦和ZooKeeper发生超时连接,则直接将Master或Worker服务停掉。
2.任务失败重试
这里首先要区分任务失败重试、流程失败规复、流程失败重跑的概念:
[*]任务失败重试是任务级别的,是调度体系自动进行的,比如一个Shell任务设置重试次数为3次,那么在Shell任务运行失败后会本身再最多尝试运行3次
[*]流程失败规复是流程级别的,是手动进行的,规复是从只能从失败的节点开始实行或从当前节点开始实行
[*]流程失败重跑也是流程级别的,是手动进行的,重跑是从开始节点进行
接下来说正题,我们将工作流中的任务节点分了两种类型。
[*]一种是业务节点,这种节点都对应一个实际的脚本大概处理语句,比如Shell节点,MR节点、Spark节点、依赖节点等。
[*]还有一种是逻辑节点,这种节点不做实际的脚本或语句处理,只是整个流程流转的逻辑处理,比如子流程节等。
全部任务都可以配置失败重试的次数,当该任务节点失败,会自动重试,直到乐成大概超过配置的重试次数。
如果工作流中有任务失败到达最大重试次数,工作流就会失败停止,失败的工作流可以手动进行重跑利用大概流程规复利用
四、任务优先级计划
在早期调度计划中,如果没有优先级计划,采用公平调度计划的话,会碰到先行提交的任务大概会和后继提交的任务同时完成的情况,而不能做到设置流程大概任务的优先级,因此我们对此进行了重新计划,目前我们计划如下:
[*]按照
不同流程实例优先级
优先于
同一个流程实例优先级
优先于
同一流程内任务优先级
优先于
同一流程内任务
提交次序依次从高到低进行任务处理。
+ 具体实现是根据任务实例的json解析优先级,然后把**流程实例优先级\_流程实例id\_任务优先级\_任务id**信息保存在ZooKeeper任务队列中,当从任务队列获取的时候,通过字符串比较即可得出最需要优先执行的任务
- 其中流程定义的优先级是考虑到有些流程需要先于其他流程进行处理,这个可以在流程启动或者定时启动时配置,共有5级,依次为HIGHEST、HIGH、MEDIUM、LOW、LOWEST。如下图
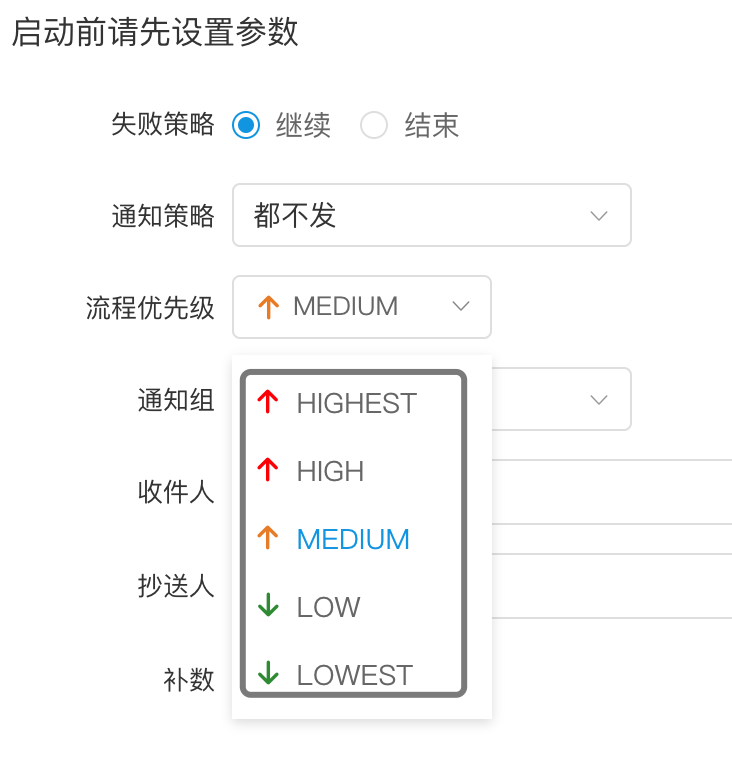
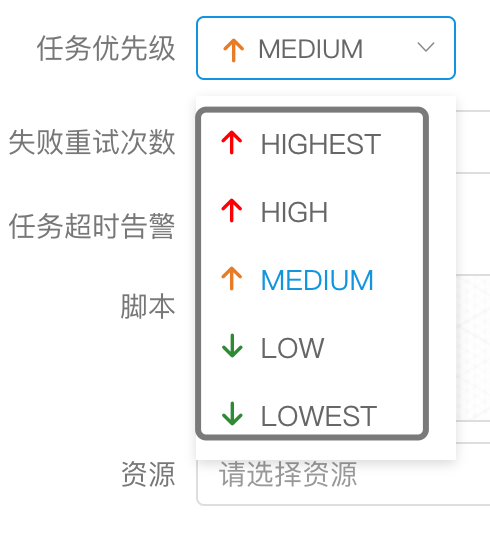
- 任务的优先级也分为5级,依次为HIGHEST、HIGH、MEDIUM、LOW、LOWEST。如下图
五、Logback和netty实现日记访问
[*]由于Web(UI)和Worker不一定在同一台机器上,所以查察日记不能像查询当地文件那样。有两种方案:
[*]将日记放到ES搜索引擎上
[*]通过netty通信获取远程日记信息
[*]介于思量到尽大概的DolphinScheduler的轻量级性,所以选择了gRPC实现远程访问日记信息。
https://img-blog.csdnimg.cn/img_convert/5b6adbeb8300ce346e094da0a2f1c1f8.png
[*]我们利用自定义Logback的FileAppender和Filter功能,实现每个任务实例生成一个日记文件。
[*]FileAppender主要实现如下:
/\*\*
\* task log appender
\*/
public class TaskLogAppender extends FileAppender<ILoggingEvent> {
...
@Override
protected void append(ILoggingEvent event) {
if (currentlyActiveFile == null){
currentlyActiveFile = getFile();
}
String activeFile = currentlyActiveFile;
// thread name: taskThreadName-processDefineId\_processInstanceId\_taskInstanceId
String threadName = event.getThreadName();
String[] threadNameArr = threadName.split("-");
// logId = processDefineId\_processInstanceId\_taskInstanceId
String logId = threadNameArr;
...
super.subAppend(event);
}
}
以/流程定义id/流程实例id/任务实例id.log的形式生成日记
[*]过滤匹配以TaskLogInfo开始的线程名称:
[*]TaskLogFilter实现如下:
/\*\*
\* task log filter
\*/
public class TaskLogFilter extends Filter<ILoggingEvent> {
@Override
public FilterReply decide(ILoggingEvent event) {
if (event.getThreadName().startsWith("TaskLogInfo-")){
return FilterReply.ACCEPT;
}
return FilterReply.DENY;
}
}
Dolphin Scheduler 2.0元数据文档
表概览
表名表信息t_ds_access_token访问ds后端的tokent_ds_alert告警信息t_ds_alertgroup告警组t_ds_command实行下令t_ds_datasource数据源t_ds_error_command错误下令t_ds_process_definition流程定义t_ds_process_instance流程实例t_ds_project项目t_ds_queue队列t_ds_relation_datasource_user用户关联数据源t_ds_relation_process_instance子流程t_ds_relation_project_user用户关联项目t_ds_relation_resources_user用户关联资源t_ds_relation_udfs_user用户关联UDF函数t_ds_relation_user_alertgroup用户关联告警组t_ds_resources资源文件t_ds_schedules流程定时调度t_ds_session用户登录的sessiont_ds_task_instance任务实例t_ds_tenant租户t_ds_udfsUDF资源t_ds_user用户t_ds_versionds版本信息 用户 队列 数据源
https://img-blog.csdnimg.cn/img_convert/db036397fbe4b3c6f444c0f4676a8a3a.png
[*]一个租户下可以有多个用户
[*]t_ds_user中的queue字段存储的是队列表中的queue_name信息,t_ds_tenant下存的是queue_id,在流程定义实行过程中,用户队列优先级最高,用户队列为空则采用租户队列
[*]t_ds_datasource表中的user_id字段表示创建该数据源的用户,t_ds_relation_datasource_user中的user_id表示,对数据源有权限的用户
项目 资源 告警
https://img-blog.csdnimg.cn/img_convert/fa46af8f2da057231ec1312e2489ce15.png
[*]一个用户可以有多个项目,用户项目授权通过t_ds_relation_project_user表完成project_id和user_id的关系绑定
[*]t_ds_projcet表中的user_id表示创建该项目标用户,t_ds_relation_project_user表中的user_id表示对项目有权限的用户
[*]t_ds_resources表中的user_id表示创建该资源的用户,t_ds_relation_resources_user中的user_id表示对资源有权限的用户
[*]t_ds_udfs表中的user_id表示创建该UDF的用户,t_ds_relation_udfs_user表中的user_id表示对UDF有权限的用户
下令 流程 任务
https://img-blog.csdnimg.cn/img_convert/99541e43e1c248f4d30f9efbfb19094f.png
https://img-blog.csdnimg.cn/img_convert/f03ad1393f37d85bf1b24284ebb6bdcc.png
[*]一个项目有多个流程定义,一个流程定义可以生成多个流程实例,一个流程实例可以生成多个任务实例
[*]t_ds_schedulers表存放流程定义的定时调度信息
[*]t_ds_relation_process_instance表存放的数据用于处理流程定义中含有子流程的情况,parent_process_instance_id表示含有子流程的主流程实例id,process_instance_id表示子流程实例的id,parent_task_instance_id表示子流程节点的任务实例id,流程实例表和任务实例表分别对应t_ds_process_instance表和t_ds_task_instance表
核心表Schema
t_ds_process_definition
字段类型解释idint主键namevarchar流程定义名称versionint流程定义版本release_statetinyint流程定义的发布状态:0 未上线 1已上线project_idint项目iduser_idint流程定义所属用户idprocess_definition_jsonlongtext流程定义json串descriptiontext流程定义描述global_paramstext全局参数flagtinyint流程是否可用:0 不可用,1 可用locationstext节点坐标信息connectstext节点连线信息receiverstext收件人receivers_cctext抄送人create_timedatetime创建时间timeoutint超时时间tenant_idint租户idupdate_timedatetime更新时间modify_byvarchar修改用户resource_idsvarchar资源id集 t_ds_process_instance
字段类型解释idint主键namevarchar流程实例名称process_definition_idint流程定义idstatetinyint流程实例状态:0 提交乐成,1 正在运行,2 准备暂停,3 暂停,4 准备停止,5 停止,6 失败,7 乐成,8 需要容错,9 kill,10 等待线程,11 等待依赖完成recoverytinyint流程实例容错标识:0 正常,1 需要被容错重启start_timedatetime流程实例开始时间end_timedatetime流程实例结束时间run_timesint流程实例运行次数hostvarchar流程实例所在的机器command_typetinyint下令类型:0 启动工作流,1 从当前节点开始实行,2 规复被容错的工作流,3 规复暂停流程,4 从失败节点开始实行,5 补数,6 调度,7 重跑,8 暂停,9 停止,10 规复等待线程command_paramtext下令的参数(json格式)task_depend_typetinyint节点依赖类型:0 当前节点,1 向前实行,2 向后实行max_try_timestinyint最大重试次数failure_strategytinyint失败策略 0 失败后结束,1 失败后继承warning_typetinyint告警类型:0 不发,1 流程乐成发,2 流程失败发,3 乐成失败都发warning_group_idint告警组idschedule_timedatetime预期运行时间command_start_timedatetime开始下令时间global_paramstext全局参数(固化流程定义的参数)process_instance_jsonlongtext流程实例json(copy的流程定义的json)flagtinyint是否可用,1 可用,0不可用update_timetimestamp更新时间is_sub_processint是否是子工作流 1 是,0 不是executor_idint下令实行用户locationstext节点坐标信息connectstext节点连线信息history_cmdtext汗青下令,记录全部对流程实例的利用dependence_schedule_timestext依赖节点的预估时间process_instance_priorityint流程实例优先级:0 Highest,1 High,2 Medium,3 Low,4 Lowestworker_groupvarchar任务指定运行的worker分组timeoutint超时时间tenant_idint租户id t_ds_task_instance
字段类型解释idint主键namevarchar任务名称task_typevarchar任务类型process_definition_idint流程定义idprocess_instance_idint流程实例idtask_jsonlongtext任务节点jsonstatetinyint任务实例状态:0 提交乐成,1 正在运行,2 准备暂停,3 暂停,4 准备停止,5 停止,6 失败,7 乐成,8 需要容错,9 kill,10 等待线程,11 等待依赖完成submit_timedatetime任务提交时间start_timedatetime任务开始时间end_timedatetime任务结束时间hostvarchar实行任务的机器execute_pathvarchar任务实行路径log_pathvarchar任务日记路径alert_flagtinyint是否告警retry_timesint重试次数pidint历程pidapp_linkvarcharyarn app idflagtinyint是否可用:0 不可用,1 可用retry_intervalint重试间隔max_retry_timesint最大重试次数task_instance_priorityint任务实例优先级:0 Highest,1 High,2 Medium,3 Low,4 Lowestworker_groupvarchar任务指定运行的worker分组 t_ds_schedules
字段类型解释idint主键process_definition_idint流程定义idstart_timedatetime调度开始时间end_timedatetime调度结束时间crontabvarcharcrontab 表达式failure_strategytinyint失败策略: 0 结束,1 继承user_idint用户idrelease_statetinyint状态:0 未上线,1 上线warning_typetinyint告警类型:0 不发,1 流程乐成发,2 流程失败发,3 乐成失败都发warning_group_idint告警组idprocess_instance_priorityint流程实例优先级:0 Highest,1 High,2 Medium,3 Low,4 Lowestworker_groupvarchar任务指定运行的worker分组create_timedatetime创建时间update_timedatetime更新时间 t_ds_command
字段类型解释idint主键command_typetinyint下令类型:0 启动工作流,1 从当前节点开始实行,2 规复被容错的工作流,3 规复暂停流程,4 从失败节点开始实行,5 补数,6 调度,7 重跑,8 暂停,9 停止,10 规复等待线程process_definition_idint流程定义idcommand_paramtext下令的参数(json格式)task_depend_typetinyint节点依赖类型:0 当前节点,1 向前实行,2 向后实行failure_strategytinyint失败策略:0结束,1继承warning_typetinyint告警类型:0 不发,1 流程乐成发,2 流程失败发,3 乐成失败都发warning_group_idint告警组schedule_timedatetime预期运行时间start_timedatetime开始时间executor_idint实行用户iddependencevarchar依赖字段update_timedatetime更新时间process_instance_priorityint流程实例优先级:0 Highest,1 High,2 Medium,3 Low,4 Lowestworker_groupvarchar任务指定运行的worker分组 配置文件
前言
本文档为dolphinscheduler配置文件阐明文档,针对版本为 dolphinscheduler-1.3.x 版本.
目录布局
目前dolphinscheduler 全部的配置文件都在 目录中. 为了更直观的了解目录所在的位置以及包含的配置文件,请查察下面dolphinscheduler安装目录的简化阐明. 本文主要讲述dolphinscheduler的配置文件.其他部分先不做赘述.
[注:以下 dolphinscheduler 简称为DS.]
├─bin DS命令存放目录
│├─dolphinscheduler-daemon.sh 启动/关闭DS服务脚本
│├─start-all.sh 根据配置文件启动所有DS服务
│├─stop-all.sh 根据配置文件关闭所有DS服务
├─conf 配置文件目录
│├─application-api.properties api服务配置文件
│├─datasource.properties 数据库配置文件
│├─zookeeper.properties zookeeper配置文件
│├─master.properties master服务配置文件
│├─worker.properties worker服务配置文件
│├─quartz.properties quartz服务配置文件
│├─common.properties 公共服务[存储]配置文件
│├─alert.properties alert服务配置文件
│├─config 环境变量配置文件夹
│ ├─install_config.conf DS环境变量配置脚本[用于DS安装/启动]
│├─env 运行脚本环境变量配置目录
│ ├─dolphinscheduler_env.sh 运行脚本加载环境变量配置文件[如: JAVA_HOME,HADOOP_HOME, HIVE_HOME ...]
│├─org mybatis mapper文件目录
│├─i18n i18n配置文件目录
│├─logback-api.xml api服务日志配置文件
│├─logback-master.xml master服务日志配置文件
│├─logback-worker.xml worker服务日志配置文件
│├─logback-alert.xml alert服务日志配置文件
├─sql DS的元数据创建升级sql文件
│├─create 创建SQL脚本目录
│├─upgrade 升级SQL脚本目录
│├─dolphinscheduler_postgre.sql postgre数据库初始化脚本
│├─dolphinscheduler_mysql.sql mysql数据库初始化脚本
│├─soft_version 当前DS版本标识文件
├─script DS服务部署,数据库创建/升级脚本目录
│├─create-dolphinscheduler.sh DS数据库初始化脚本
│├─upgrade-dolphinscheduler.sh DS数据库升级脚本
│├─monitor-server.sh DS服务监控启动脚本
│├─scp-hosts.sh 安装文件传输脚本
│├─remove-zk-node.sh 清理zookeeper缓存文件脚本
├─ui 前端WEB资源目录
├─lib DS依赖的jar存放目录
├─install.sh 自动安装DS服务脚本
配置文件详解
序号服务分类配置文件1启动/关闭DS服务脚本dolphinscheduler-daemon.sh2数据库连接配置datasource.properties3zookeeper连接配置zookeeper.properties4公共[存储]配置common.properties5API服务配置application-api.properties6Master服务配置master.properties7Worker服务配置worker.properties8Alert 服务配置alert.properties9Quartz配置quartz.properties10DS环境变量配置脚本[用于DS安装/启动]install_config.conf11运行脚本加载环境变量配置文件 [如: JAVA_HOME,HADOOP_HOME, HIVE_HOME …]dolphinscheduler_env.sh12各服务日记配置文件api服务日记配置文件 : logback-api.xml master服务日记配置文件 : logback-master.xml worker服务日记配置文件 : logback-worker.xml alert服务日记配置文件 : logback-alert.xml 1.dolphinscheduler-daemon.sh [启动/关闭DS服务脚本]
dolphinscheduler-daemon.sh脚本负责DS的启动&关闭. start-all.sh/stop-all.sh最终也是通过dolphinscheduler-daemon.sh对集群进行启动/关闭利用. 目前DS只是做了一个基本的设置,JVM参数请根据各自资源的实际情况自行设置.
默认简化参数如下:
export DOLPHINSCHEDULER\_OPTS="
-server
-Xmx16g
-Xms1g
-Xss512k
-XX:+UseConcMarkSweepGC
-XX:+CMSParallelRemarkEnabled
-XX:+UseFastAccessorMethods
-XX:+UseCMSInitiatingOccupancyOnly
-XX:CMSInitiatingOccupancyFraction=70
"
不发起设置"-XX:DisableExplicitGC" , DS利用Netty进行通讯,设置该参数,大概会导致内存走漏.
2.datasource.properties [数据库连接]
在DS中利用Druid对数据库连接进行管理,默认简化配置如下.
参数默认值描述spring.datasource.driver-class-name数据库驱动spring.datasource.url数据库连接地点spring.datasource.username数据库用户名spring.datasource.password数据库暗码spring.datasource.initialSize5初始连接池数量spring.datasource.minIdle5最小连接池数量spring.datasource.maxActive5最大连接池数量spring.datasource.maxWait60000最大等待时长spring.datasource.timeBetweenEvictionRunsMillis60000连接检测周期spring.datasource.timeBetweenConnectErrorMillis60000重试间隔spring.datasource.minEvictableIdleTimeMillis300000连接保持空闲而不被驱逐的最小时间spring.datasource.validationQuerySELECT 1检测连接是否有效的sqlspring.datasource.validationQueryTimeout3检测连接是否有效的超时时间spring.datasource.testWhileIdletrue申请连接的时候检测,如果空闲时间大于timeBetweenEvictionRunsMillis,实行validationQuery检测连接是否有效。spring.datasource.testOnBorrowtrue申请连接时实行validationQuery检测连接是否有效spring.datasource.testOnReturnfalse归还连接时实行validationQuery检测连接是否有效spring.datasource.defaultAutoCommittrue是否开启自动提交spring.datasource.keepAlivetrue连接池中的minIdle数量以内的连接,空闲时间超过minEvictableIdleTimeMillis,则会实行keepAlive利用。spring.datasource.poolPreparedStatementstrue开启PSCachespring.datasource.maxPoolPreparedStatementPerConnectionSize20要启用PSCache,必须配置大于0,当大于0时,poolPreparedStatements自动触发修改为true。 3.zookeeper.properties
参数默认值描述zookeeper.quorumlocalhost:2181zk集群连接信息zookeeper.dolphinscheduler.root/dolphinschedulerDS在zookeeper存储根目录zookeeper.session.timeout60000session 超时zookeeper.connection.timeout30000连接超时zookeeper.retry.base.sleep100基本重试时间差zookeeper.retry.max.sleep30000最大重试时间zookeeper.retry.maxtime10最大重试次数 4.common.properties
common.properties配置文件目前主要是配置hadoop/s3a相关的配置.
参数默认值描述data.basedir.path/tmp/dolphinscheduler当地工作目录,用于存放临时文件resource.storage.typeNONE资源文件存储类型: HDFS,S3,NONEresource.upload.path/dolphinscheduler资源文件存储路径hadoop.security.authentication.startup.statefalsehadoop是否开启kerberos权限java.security.krb5.conf.path/opt/krb5.confkerberos配置目录login.user.keytab.usernamehdfs-mycluster@ESZ.COMkerberos登任命户login.user.keytab.path/opt/hdfs.headless.keytabkerberos登任命户keytabkerberos.expire.time2kerberos过期时间,整数,单位为小时resource.view.suffixstxt,log,sh,conf,cfg,py,java,sql,hql,xml,properties资源中心支持的文件格式hdfs.root.userhdfs如果存储类型为HDFS,需要配置拥有对应利用权限的用户fs.defaultFShdfs://mycluster:8020哀求地点如果resource.storage.type=S3,该值雷同为: s3a://dolphinscheduler. 如果resource.storage.type=HDFS, 如果 hadoop 配置了 HA,需要复制core-site.xml 和 hdfs-site.xml 文件到conf目录fs.s3a.endpoints3 endpoint地点fs.s3a.access.keys3 access keyfs.s3a.secret.keys3 secret keyyarn.resourcemanager.ha.rm.idsyarn resourcemanager 地点, 如果resourcemanager开启了HA, 输入HA的IP地点(以逗号分隔),如果resourcemanager为单节点, 该值为空即可yarn.application.status.addresshttp://ds1:8088/ws/v1/cluster/apps/%s如果resourcemanager开启了HA大概没有利用resourcemanager,保持默认值即可. 如果resourcemanager为单节点,你需要将ds1 配置为resourcemanager对应的hostnamedolphinscheduler.env.pathenv/dolphinscheduler_env.sh运行脚本加载环境变量配置文件[如: JAVA_HOME,HADOOP_HOME, HIVE_HOME …]development.statefalse是否处于开辟模式 5.application-api.properties
参数默认值描述server.port12345api服务通讯端口server.servlet.session.timeout7200session超时时间server.servlet.context-path/dolphinscheduler哀求路径spring.servlet.multipart.max-file-size1024MB最大上传文件大小spring.servlet.multipart.max-request-size1024MB最大哀求大小server.jetty.max-http-post-size5000000jetty服务最大发送哀求大小spring.messages.encodingUTF-8哀求编码spring.jackson.time-zoneGMT+8设置时区spring.messages.basenamei18n/messagesi18n配置security.authentication.typePASSWORD权限校验类型 6.master.properties
参数默认值描述master.listen.port5678master监听端口master.exec.threads100master工作线程数量,用于限制并行的流程实例数量master.exec.task.num20master每个流程实例的并行任务数量master.dispatch.task.num3master每个批次的派发任务数量master.host.selectorLowerWeightmaster host选择器,用于选择合适的worker实行任务,可选值: Random, RoundRobin, LowerWeightmaster.heartbeat.interval10master心跳间隔,单位为秒master.task.commit.retryTimes5任务重试次数master.task.commit.interval1000任务提交间隔,单位为毫秒master.max.cpuload.avg-1master最大cpuload均值,只有高于体系cpuload均值时,master服务才气调度任务. 默认值为-1: cpu cores * 2master.reserved.memory0.3master预留内存,只有低于体系可用内存时,master服务才气调度任务,单位为G 7.worker.properties
参数默认值描述worker.listen.port1234worker监听端口worker.exec.threads100worker工作线程数量,用于限制并行的任务实例数量worker.heartbeat.interval10worker心跳间隔,单位为秒worker.max.cpuload.avg-1worker最大cpuload均值,只有高于体系cpuload均值时,worker服务才气被派发任务. 默认值为-1: cpu cores * 2worker.reserved.memory0.3worker预留内存,只有低于体系可用内存时,worker服务才气被派发任务,单位为Gworker.groupsdefaultworker分组配置,逗号分隔,例如’worker.groups=default,test’ worker启动时会根据该配置自动到场对应的分组 8.alert.properties
参数默认值描述alert.typeEMAIL告警类型mail.protocolSMTP邮件服务器协议mail.server.hostxxx.xxx.com邮件服务器地点mail.server.port25邮件服务器端口mail.senderxxx@xxx.com发送人邮箱mail.userxxx@xxx.com发送人邮箱名称mail.passwd111111发送人邮箱暗码mail.smtp.starttls.enabletrue邮箱是否开启tlsmail.smtp.ssl.enablefalse邮箱是否开启sslmail.smtp.ssl.trustxxx.xxx.com邮箱ssl白名单xls.file.path/tmp/xls邮箱附件临时工作目录以下为企业微信配置[选填]enterprise.wechat.enablefalse企业微信是否启用enterprise.wechat.corp.idxxxxxxxenterprise.wechat.secretxxxxxxxenterprise.wechat.agent.idxxxxxxxenterprise.wechat.usersxxxxxxxenterprise.wechat.token.urlhttps://qyapi.weixin.qq.com/cgi-bin/gettoken? corpid=corpId&corpsecret=secretenterprise.wechat.push.urlhttps://qyapi.weixin.qq.com/cgi-bin/message/send? access_token=$tokenenterprise.wechat.user.send.msg发送消息格式enterprise.wechat.team.send.msg群发消息格式plugin.dir/Users/xx/your/path/to/plugin/dir插件目录 9.quartz.properties
这里面主要是quartz配置,请结合实际业务场景&资源进行配置,本文暂时不做睁开.
参数默认值描述org.quartz.jobStore.driverDelegateClassorg.quartz.impl.jdbcjobstore.StdJDBCDelegateorg.quartz.jobStore.driverDelegateClassorg.quartz.impl.jdbcjobstore.PostgreSQLDelegateorg.quartz.scheduler.instanceNameDolphinSchedulerorg.quartz.scheduler.instanceIdAUTOorg.quartz.scheduler.makeSchedulerThreadDaemontrueorg.quartz.jobStore.usePropertiesfalseorg.quartz.threadPool.classorg.quartz.simpl.SimpleThreadPoolorg.quartz.threadPool.makeThreadsDaemonstrueorg.quartz.threadPool.threadCount25org.quartz.threadPool.threadPriority5org.quartz.jobStore.classorg.quartz.impl.jdbcjobstore.JobStoreTXorg.quartz.jobStore.tablePrefixQRTZ_org.quartz.jobStore.isClusteredtrueorg.quartz.jobStore.misfireThreshold60000org.quartz.jobStore.clusterCheckinInterval5000org.quartz.jobStore.acquireTriggersWithinLocktrueorg.quartz.jobStore.dataSourcemyDsorg.quartz.dataSource.myDs.connectionProvider.classorg.apache.dolphinscheduler.service.quartz.DruidConnectionProvider 10.install_config.conf ]
install_config.conf这个配置文件比力繁琐,这个文件主要有两个地方会用到.
[*]1.DS集群的自动安装.
调用install.sh脚本会自动加载该文件中的配置.并根据该文件中的内容自动配置上述的配置文件中的内容. 比如:dolphinscheduler-daemon.sh、datasource.properties、zookeeper.properties、common.properties、application-api.properties、master.properties、worker.properties、alert.properties、quartz.properties 等文件.
[*]2.DS集群的启动&关闭.
DS集群在启动&关闭的时候,会加载该配置文件中的masters,workers,alertServer,apiServers等参数,启动/关闭DS集群.
文件内容如下:
# 注意: 该配置文件中如果包含特殊字符,如: `.\*[]^${}\+?|()@#&`, 请转义,
# 示例: `[` 转义为 `\[`
# 数据库类型, 目前仅支持 postgresql 或者 mysql
dbtype="mysql"
# 数据库 地址 & 端口
dbhost="192.168.xx.xx:3306"
# 数据库 名称
dbname="dolphinscheduler"
# 数据库 用户名
username="xx"
# 数据库 密码
password="xx"
# Zookeeper地址
zkQuorum="192.168.xx.xx:2181,192.168.xx.xx:2181,192.168.xx.xx:2181"
# 将DS安装到哪个目录,如: /data1\_1T/dolphinscheduler,
installPath="/data1\_1T/dolphinscheduler"
# 使用哪个用户部署
# 注意: 部署用户需要sudo 权限, 并且可以操作 hdfs .
# 如果使用hdfs的话,根目录必须使用该用户进行创建.否则会有权限相关的问题.
deployUser="dolphinscheduler"
# 以下为告警服务配置
# 邮件服务器地址
mailServerHost="smtp.exmail.qq.com"
# 邮件服务器 端口
mailServerPort="25"
# 发送者
mailSender="xxxxxxxxxx"
# 发送用户
mailUser="xxxxxxxxxx"
# 邮箱密码
mailPassword="xxxxxxxxxx"
# TLS协议的邮箱设置为true,否则设置为false
starttlsEnable="true"
# 开启SSL协议的邮箱配置为true,否则为false。注意: starttlsEnable和sslEnable不能同时为true
sslEnable="false"
# 邮件服务地址值,同 mailServerHost
sslTrust="smtp.exmail.qq.com"
#业务用到的比如sql等资源文件上传到哪里,可以设置:HDFS,S3,NONE。如果想上传到HDFS,请配置为HDFS;如果不需要资源上传功能请选择NONE。
resourceStorageType="NONE"
# if S3,write S3 address,HA,for example :s3a://dolphinscheduler,
# Note,s3 be sure to create the root directory /dolphinscheduler
defaultFS="hdfs://mycluster:8020"
# 如果resourceStorageType 为S3 需要配置的参数如下:
s3Endpoint="http://192.168.xx.xx:9010"
s3AccessKey="xxxxxxxxxx"
s3SecretKey="xxxxxxxxxx"
# 如果ResourceManager是HA,则配置为ResourceManager节点的主备ip或者hostname,比如"192.168.xx.xx,192.168.xx.xx",否则如果是单ResourceManager或者根本没用到yarn,请配置yarnHaIps=""即可,如果没用到yarn,配置为""
yarnHaIps="192.168.xx.xx,192.168.xx.xx"
# 如果是单ResourceManager,则配置为ResourceManager节点ip或主机名,否则保持默认值即可。
singleYarnIp="yarnIp1"
# 资源文件在 HDFS/S3 存储路径
resourceUploadPath="/dolphinscheduler"
# HDFS/S3 操作用户
hdfsRootUser="hdfs"
# 以下为 kerberos 配置
# kerberos是否开启
kerberosStartUp="false"
# kdc krb5 config file path
krb5ConfPath="$installPath/conf/krb5.conf"
# keytab username
keytabUserName="hdfs-mycluster@ESZ.COM"
# username keytab path
keytabPath="$installPath/conf/hdfs.headless.keytab"
# api 服务端口
apiServerPort="12345"
# 部署DS的所有主机hostname
ips="ds1,ds2,ds3,ds4,ds5"
# ssh 端口 , 默认 22
sshPort="22"
# 部署master服务主机
masters="ds1,ds2"
# 部署 worker服务的主机
# 注意: 每一个worker都需要设置一个worker 分组的名称,默认值为 "default"
workers="ds1:default,ds2:default,ds3:default,ds4:default,ds5:default"
# 部署alert服务主机
alertServer="ds3"
# 部署api服务主机
apiServers="ds1"
11.dolphinscheduler_env.sh [环境变量配置]
通过雷同shell方式提交任务的的时候,会加载该配置文件中的环境变量到主机中. 涉及到的任务类型有: Shell任务、Python任务、Spark任务、Flink任务、Datax任务等等
export HADOOP\_HOME=/opt/soft/hadoop
export HADOOP\_CONF\_DIR=/opt/soft/hadoop/etc/hadoop
export SPARK\_HOME1=/opt/soft/spark1
export SPARK\_HOME2=/opt/soft/spark2
export PYTHON\_HOME=/opt/soft/python
export JAVA\_HOME=/opt/soft/java
export HIVE\_HOME=/opt/soft/hive
export FLINK\_HOME=/opt/soft/flink
export DATAX\_HOME=/opt/soft/datax/bin/datax.py
export PATH=$HADOOP\_HOME/bin:$SPARK\_HOME1/bin:$SPARK\_HOME2/bin:$PYTHON\_HOME:$JAVA\_HOME/bin:$HIVE\_HOME/bin:$PATH:$FLINK\_HOME/bin:$DATAX\_HOME:$PATH
12.各服务日记配置文件
对应服务服务名称日记文件名api服务日记配置文件logback-api.xmlmaster服务日记配置文件logback-master.xmlworker服务日记配置文件logback-worker.xmlalert服务日记配置文件logback-alert.xml 任务总体存储布局
在dolphinscheduler中创建的全部任务都保存在t_ds_process_definition 表中.
该数据库表布局如下表所示:
序号字段类型描述1idint(11)主键2namevarchar(255)流程定义名称3versionint(11)流程定义版本4release_statetinyint(4)流程定义的发布状态:0 未上线 , 1已上线5project_idint(11)项目id6user_idint(11)流程定义所属用户id7process_definition_jsonlongtext流程定义JSON8descriptiontext流程定义描述9global_paramstext全局参数10flagtinyint(4)流程是否可用:0 不可用,1 可用11locationstext节点坐标信息12connectstext节点连线信息13receiverstext收件人14receivers_cctext抄送人15create_timedatetime创建时间16timeoutint(11)超时时间17tenant_idint(11)租户id18update_timedatetime更新时间19modify_byvarchar(36)修改用户20resource_idsvarchar(255)资源ids 其中process_definition_json 字段为核心字段, 定义了 DAG 图中的任务信息.该数据以JSON 的方式进行存储.
公共的数据布局如下表.
序号字段类型描述1globalParamsArray全局参数2tasksArray流程中的任务聚集 [ 各个类型的布局请参考如下章节]3tenantIdint租户id4timeoutint超时时间 数据示例:
{
"globalParams":[
{
"prop":"golbal\_bizdate",
"direct":"IN",
"type":"VARCHAR",
"value":"${system.biz.date}"
}
],
"tasks":Array,
"tenantId":0,
"timeout":0
}
任务布局
各任务类型存储布局详解
Shell节点
节点数据布局如下:
序号参数名类型描述描述1idString任务编码2typeString类型SHELL3nameString名称4paramsObject自定义参数Json 格式5rawScriptStringShell脚本6localParamsArray自定义参数7resourceListArray资源文件8descriptionString描述9runFlagString运行标识10conditionResultObject条件分支11successNodeArray乐成跳转节点12failedNodeArray失败跳转节点13dependenceObject任务依赖与params互斥14maxRetryTimesString最大重试次数15retryIntervalString重试间隔16timeoutObject超时控制17taskInstancePriorityString任务优先级18workerGroupStringWorker 分组19preTasksArray前置任务 节点数据样例:
{
"type":"SHELL",
"id":"tasks-80760",
"name":"Shell Task",
"params":{
"resourceList":[
{
"id":3,
"name":"run.sh",
"res":"run.sh"
}
],
"localParams":[
],
"rawScript":"echo "This is a shell script""
},
"description":"",
"runFlag":"NORMAL",
"conditionResult":{
"successNode":[
""
],
"failedNode":[
""
]
},
"dependence":{
},
"maxRetryTimes":"0",
"retryInterval":"1",
"timeout":{
"strategy":"",
"interval":null,
"enable":false
},
"taskInstancePriority":"MEDIUM",
"workerGroup":"default",
"preTasks":[
]
}
SQL节点
通过 SQL对指定的数据源进行数据查询、更新利用.
节点数据布局如下:
序号参数名类型描述描述1idString任务编码2typeString类型SQL3nameString名称4paramsObject自定义参数Json 格式5typeString数据库类型6datasourceInt数据源id7sqlString查询SQL语句8udfsStringudf函数UDF函数id,以逗号分隔.9sqlTypeStringSQL节点类型0 查询 , 1 非查询10titleString邮件标题11receiversString收件人12receiversCcString抄送人13showTypeString邮件显示类型TABLE 表格 , ATTACHMENT附件14connParamsString连接参数15preStatementsArray前置SQL16postStatementsArray后置SQL17localParamsArray自定义参数18descriptionString描述19runFlagString运行标识20conditionResultObject条件分支21successNodeArray乐成跳转节点22failedNodeArray失败跳转节点23dependenceObject任务依赖与params互斥24maxRetryTimesString最大重试次数25retryIntervalString重试间隔26timeoutObject超时控制27taskInstancePriorityString任务优先级28workerGroupStringWorker 分组29preTasksArray前置任务 节点数据样例:
{
"type":"SQL",
"id":"tasks-95648",
"name":"SqlTask-Query",
"params":{
"type":"MYSQL",
"datasource":1,
"sql":"select id , namge , age from emp where id = ${id}",
"udfs":"",
"sqlType":"0",
"title":"xxxx@xxx.com",
"receivers":"xxxx@xxx.com",
"receiversCc":"",
"showType":"TABLE",
"localParams":[
{
"prop":"id",
"direct":"IN",
"type":"INTEGER",
"value":"1"
}
],
"connParams":"",
"preStatements":[
"insert into emp ( id,name ) value (1,'Li' )"
],
"postStatements":[
]
},
"description":"",
"runFlag":"NORMAL",
"conditionResult":{
"successNode":[
""
],
"failedNode":[
""
]
},
"dependence":{
},
"maxRetryTimes":"0",
"retryInterval":"1",
"timeout":{
"strategy":"",
"interval":null,
"enable":false
},
"taskInstancePriority":"MEDIUM",
"workerGroup":"default",
"preTasks":[
]
}
PROCEDURE[存储过程]节点
节点数据布局如下: 节点数据样例:
SPARK节点
节点数据布局如下:
序号参数名类型描述描述1idString任务编码2typeString类型SPARK3nameString名称4paramsObject自定义参数Json 格式5mainClassString运行主类6mainArgsString运行参数7othersString其他参数8mainJarObject步伐 jar 包 https://img-blog.csdnimg.cn/img_convert/9768c15c3d3fd9172916f923115c7091.png
https://img-blog.csdnimg.cn/img_convert/729cfab30853db91a2f3eb11f249eed9.png
https://img-blog.csdnimg.cn/img_convert/afd06946ed86b950cbefd6ea47f16246.png
既有适合小白学习的零根本资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比力多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲蹊径、讲解视频,并且后续会持续更新
需要这份体系化资料的朋友,可以戳这里获取
|
| 16 | | postStatements | Array | 后置SQL | |
| 17 | | localParams | Array | 自定义参数 | |
| 18 | description | | String | 描述 | |
| 19 | runFlag | | String | 运行标识 | |
| 20 | conditionResult | | Object | 条件分支 | |
| 21 | | successNode | Array | 乐成跳转节点 | |
| 22 | | failedNode | Array | 失败跳转节点 | |
| 23 | dependence | | Object | 任务依赖 | 与params互斥 |
| 24 | maxRetryTimes | | String | 最大重试次数 | |
| 25 | retryInterval | | String | 重试间隔 | |
| 26 | timeout | | Object | 超时控制 | |
| 27 | taskInstancePriority | | String | 任务优先级 | |
| 28 | workerGroup | | String | Worker 分组 | |
| 29 | preTasks | | Array | 前置任务 | |
节点数据样例:
{
"type":"SQL",
"id":"tasks-95648",
"name":"SqlTask-Query",
"params":{
"type":"MYSQL",
"datasource":1,
"sql":"select id , namge , age from emp where id = ${id}",
"udfs":"",
"sqlType":"0",
"title":"xxxx@xxx.com",
"receivers":"xxxx@xxx.com",
"receiversCc":"",
"showType":"TABLE",
"localParams":[
{
"prop":"id",
"direct":"IN",
"type":"INTEGER",
"value":"1"
}
],
"connParams":"",
"preStatements":[
"insert into emp ( id,name ) value (1,'Li' )"
],
"postStatements":[
]
},
"description":"",
"runFlag":"NORMAL",
"conditionResult":{
"successNode":[
""
],
"failedNode":[
""
]
},
"dependence":{
},
"maxRetryTimes":"0",
"retryInterval":"1",
"timeout":{
"strategy":"",
"interval":null,
"enable":false
},
"taskInstancePriority":"MEDIUM",
"workerGroup":"default",
"preTasks":[
]
}
PROCEDURE[存储过程]节点
节点数据布局如下: 节点数据样例:
SPARK节点
节点数据布局如下:
序号参数名类型描述描述1idString任务编码2typeString类型SPARK3nameString名称4paramsObject自定义参数Json 格式5mainClassString运行主类6mainArgsString运行参数7othersString其他参数8mainJarObject步伐 jar 包 [外链图片转存中…(img-zIBnsEFK-1714781325334)]
[外链图片转存中…(img-naiZyJFn-1714781325334)]
[外链图片转存中…(img-kYEtjc5F-1714781325335)]
既有适合小白学习的零根本资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比力多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲蹊径、讲解视频,并且后续会持续更新
需要这份体系化资料的朋友,可以戳这里获取
免责声明:如果侵犯了您的权益,请联系站长,我们会及时删除侵权内容,谢谢合作!更多信息从访问主页:qidao123.com:ToB企服之家,中国第一个企服评测及商务社交产业平台。
页:
[1]