例如,如果某个对象的散列码为76268, 并且有128个桶,对象应该保存在第108号桶中(76268除以128余108)。或许会很幸运,在这个桶中没有其他元素,此时将元素直接插人到桶中就可以了。
散列表为每个对象盘算一个整数,称为散列码(hashcode)。散列码是由对象的实例域产生的一个整数。更准确地说,具有差别数据域的对象将产生差别的散列码。
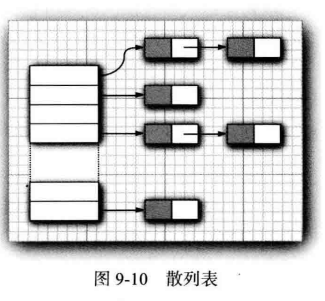
在 Java 中,散列表用链表数组实现。每个列表被称为桶(bucket) (参看图 9-10)。要想査找表中对象的位置,就要先盘算它的散列码,然后与桶的总数取余,所得到的结果就是保存这个元素的桶的索引。
例如,如果某个对象的散列码为76268, 并且有128个桶,对象应该保存在第108号桶中(76268除以128余108)。或许会很幸运,在这个桶中没有其他元素,此时将元素直接插人到桶中就可以了。
当然,有时候会遇到桶被占满的环境,这也是不可制止的。这种现象被称为散列辩论(hash collision)。这时,需要用新对象与桶中的所有对象进行比较,査看这个对象是否已经存在。如果散列码是合理且随机分布的,桶的数目也足够大,需要比较的次数就会很少。
如果想更多地控制散列表的运行性能,就要指定一个初始的桶数。桶数是指用于收集具有相同散列值的桶的数目。如果要插入到散列表中的元素太多,就会增加辩论的可能性,降低运行性能。思考
如果大致知道最终会有多少个元素要插人到散列表中,就可以设置桶数。通常,将桶数设置为预计元素个数的75% ~ 150%。有些研究人员以为:尽管还没有确凿的证据,但最好将桶数设置为一个素数,以防键的集聚。
标准类库使用的桶数是2的幂,默认值为16(为表巨细提供的任何值都将被自动地转换为2的下一个幂)。当然,并不是总能够知道需要存储多少个元素的, 也有可能最初的估计过低。如果散列表太满,就需要再散列(rehashed)。如果要对散列表再散列, 就需要创建一个桶数更多的表,并将所有元素插入到这个新表中,然后抛弃原来的表。
装填因子(load factor) 决定何时对散列表进行再散列。例如,如果装填因子为0.75 (默认值)而表中超过75%的位置已经填人元素, 这个表就会用双倍的桶数自动地进行再散列。对于大多数应用程序来说, 装填因子为0.75 是比较合理的。
性能,桶数,装填因子还提到了一个条件条件,也就是我们能约莫估计出散列表的巨细,大概不妨更大胆一点,这个散列表就是固定的,那我们就可以从桶数和装填因子下手,对性能进行优化,防止触发不必要的扩容机制。
| 欢迎光临 ToB企服应用市场:ToB评测及商务社交产业平台 (https://dis.qidao123.com/) | Powered by Discuz! X3.4 |