ToB企服应用市场:ToB评测及商务社交产业平台
标题:
大数据-110 Flink 安装摆设 下载解压配置 Standalone模式启动 打包依赖
[打印本页]
作者:
诗林
时间:
2024-12-5 23:21
标题:
大数据-110 Flink 安装摆设 下载解压配置 Standalone模式启动 打包依赖
点一下关注吧!!!非常感谢!!持续更新!!!
目前已经更新到了:
Hadoop(已更完)
HDFS(已更完)
MapReduce(已更完)
Hive(已更完)
Flume(已更完)
Sqoop(已更完)
Zookeeper(已更完)
HBase(已更完)
Redis (已更完)
Kafka(已更完)
Spark(已更完)
Flink(正在更新!)
章节内容
上节完成了如下的内容:
Flink 重要角色
TaskManager
ResourceManager
各个组件之间的关系
Sink Task SubTask 等等内容
安装模式
Flink支持多种安装模式:
local(本地):单机模式,一样寻常本地开辟调试
Standalone独立模式:Flink自带集群,本身管理资源调度,部分生产环境会这么用
YARN模式:盘算资源同一由Hadoop YRAN管理,生产环境大部分是这种
基础环境
基于我们之前的大数据的环境:
JAVA_HOME 之前已经配好了
SSH 免密登录 三台节点之间 之前也配置好了
集群规划
我们对应的呆板是:
h121 2C4G
h122 2C4G
h123 2C2G
下载安装
选择的版本是:Flink 1.11.1 版本
登录后复制
https://www.apache.org/dyn/closer.lua/flink/flink-1.11.1/flink-1.11.1-bin-scala_2.12.tgz
复制代码
1.
你也可以直接使用 wget 下载,目前我们登录到服务器 h121 节点上
登录后复制
cd /opt/software/
wget https://archive.apache.org/dist/flink/flink-1.11.1/flink-1.11.1-bin-scala_2.12.tgz
复制代码
1.
2.
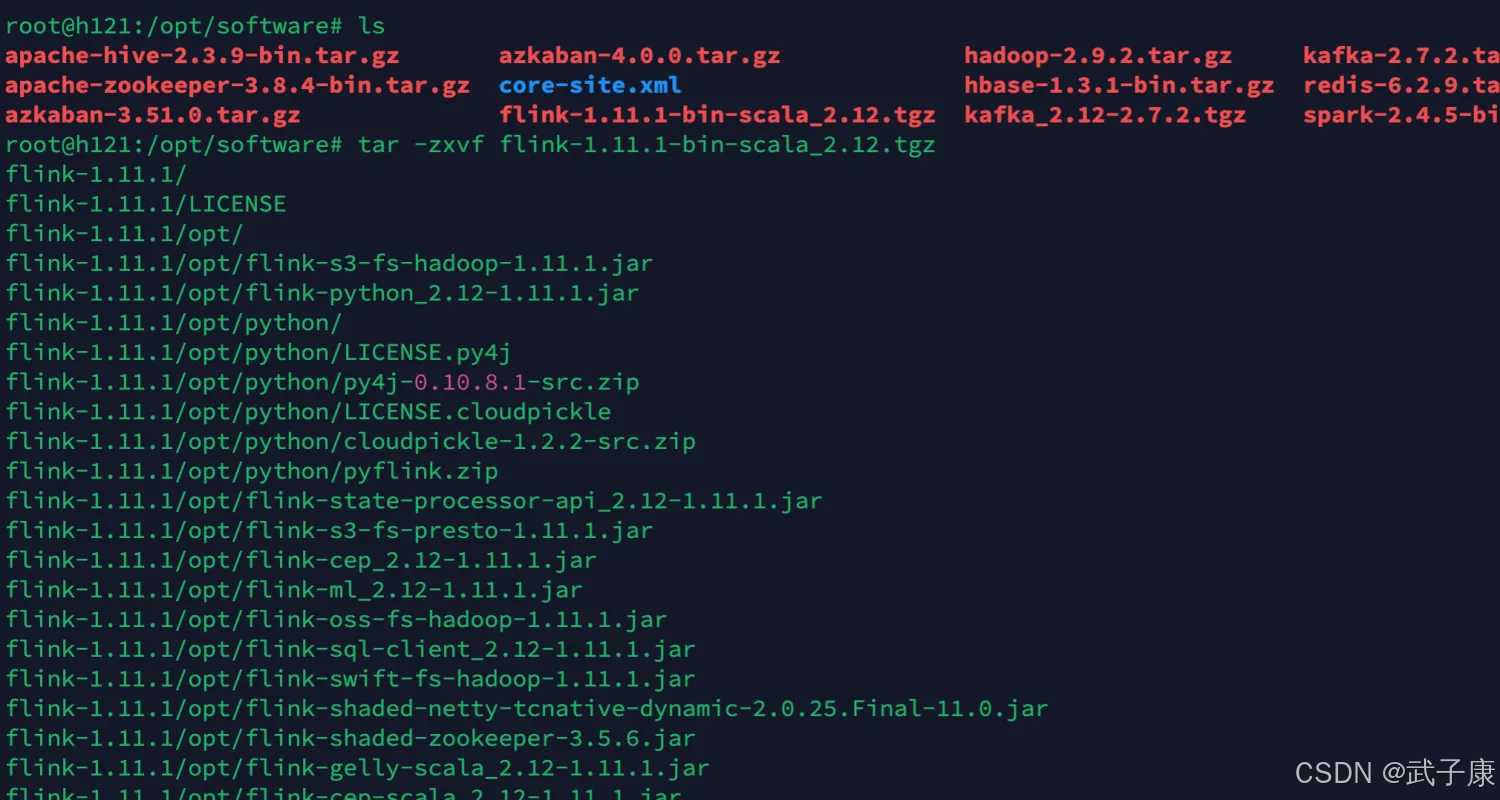
等候下载完毕:
解压配置:
登录后复制
tar -zxvf flink-1.11.1-bin-scala_2.12.tgz
复制代码
1.
处置惩罚过程如下:
解压完成之后,移动到目次下:
登录后复制
mv flink-1.11.1 ../servers/
cd ../servers/
ls
复制代码
1.
2.
3.
Standalone模式摆设
上述我们已经完成了 h121 服务器节点的配置安装,接下来我们修改配置文件。
Standalone 模式是一种相对简单的 Flink 集群摆设方式,得当在拥有固定资源的环境中运行 Flink 应用步伐。所有的 Flink 组件(如 JobManager 和 TaskManager)都是手动配置和启动的,没有依赖外部的资源管理系统。
启动与配置
手动启动:在 Standalone 模式下,JobManager 和 TaskManager 需要通过脚本手动启动。可以通过 Flink 提供的启动脚本(如 start-cluster.sh)来启动整个集群,大概单独启动每个组件。
配置文件:Standalone 模式的配置主要通过 flink-conf.yaml 文件进行,配置内容包括 JobManager 和 TaskManager 的数量、内存和 CPU 资源、网络设置等。
flink-conf.yaml
登录后复制
cd /opt/servers/flink-1.11.1/conf
vim flink-conf.yaml
复制代码
1.
2.
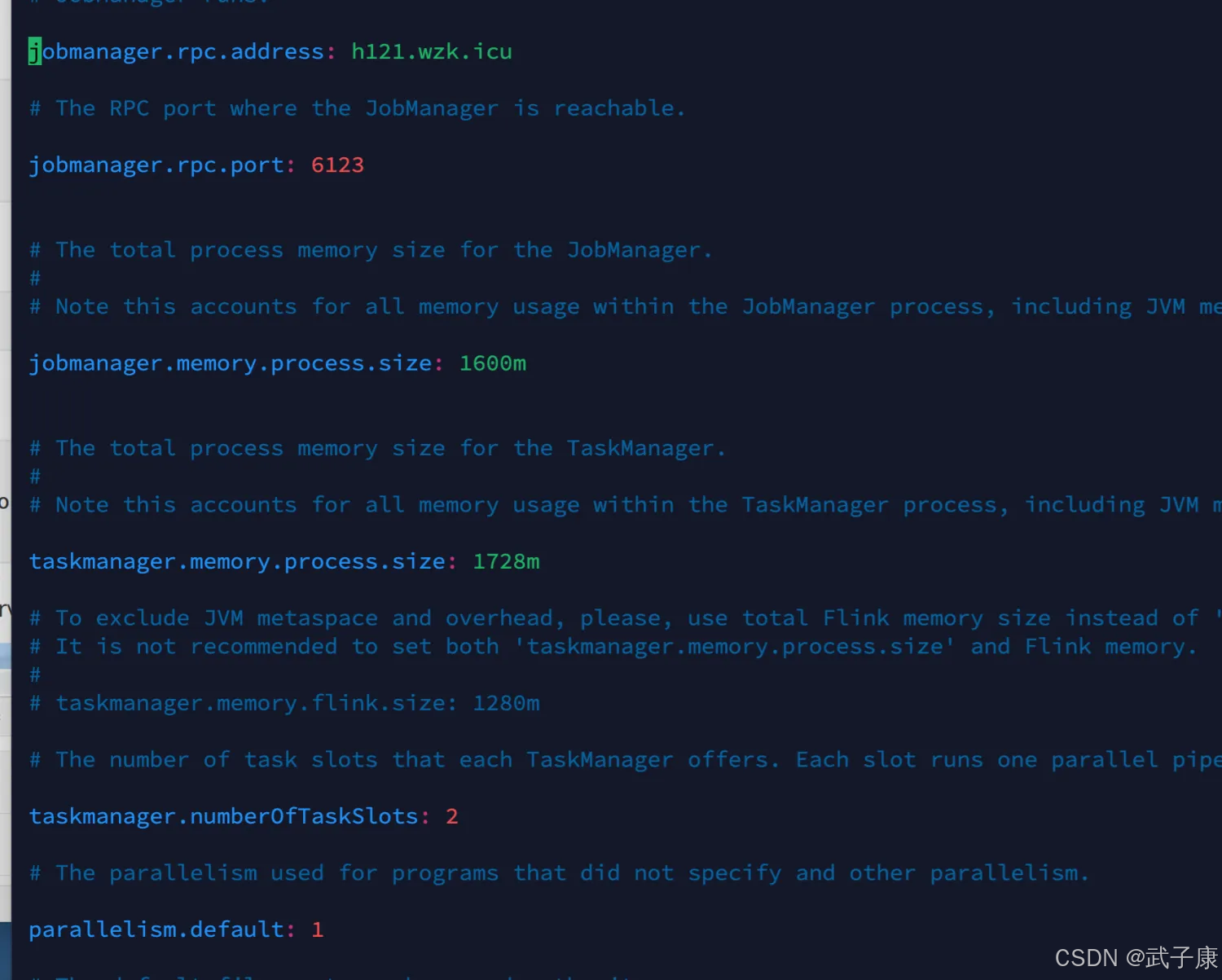
我们修改的内容有这么两处:
登录后复制
jobmanager.rpc.address: h121.wzk.icu
taskmanager.numberOfTaskSlots: 2
复制代码
1.
2.
修改内容如下所示:
Works
不同的版本大概叫不同的名字,我这里是 works
登录后复制
cd /opt/servers/flink-1.11.1/conf
vim workers
复制代码
1.
2.
写入如下的内容,我们有三台云节点:
登录后复制
h121.wzk.icu
h122.wzk.icu
h123.wzk.icu
复制代码
1.
2.
3.
写入的效果如下图所示:
Master
登录后复制
cd /opt/servers/flink-1.11.1/conf
vim masters
复制代码
1.
2.
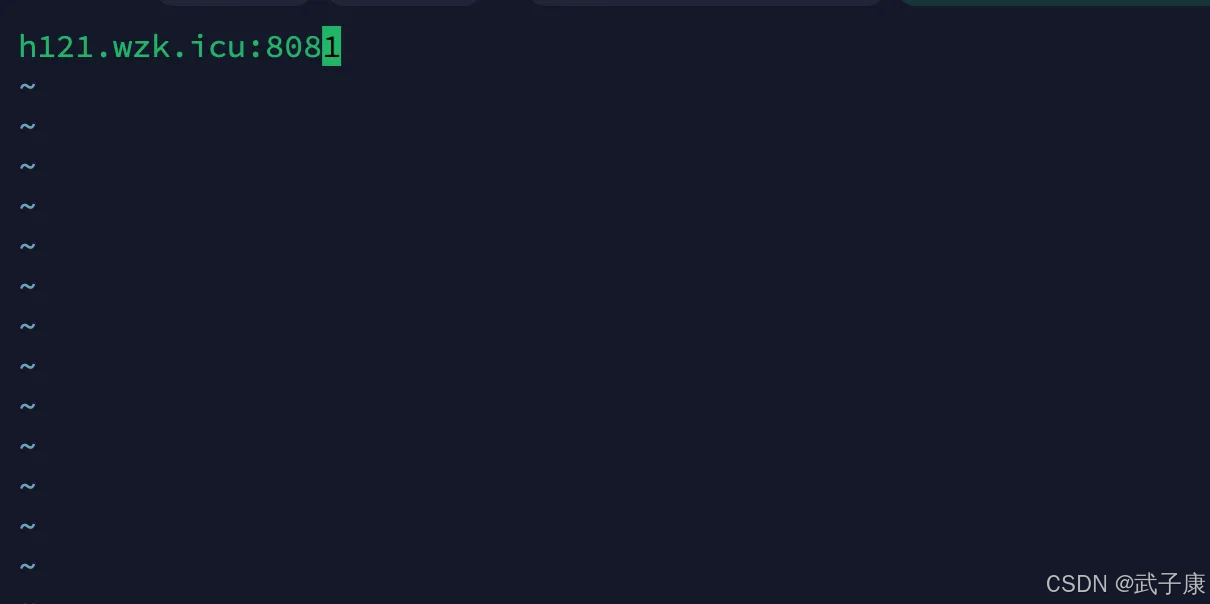
写入如下的内容:
登录后复制
h121.wzk.icu:8081
复制代码
1.
写入的效果如下图:
服务启动
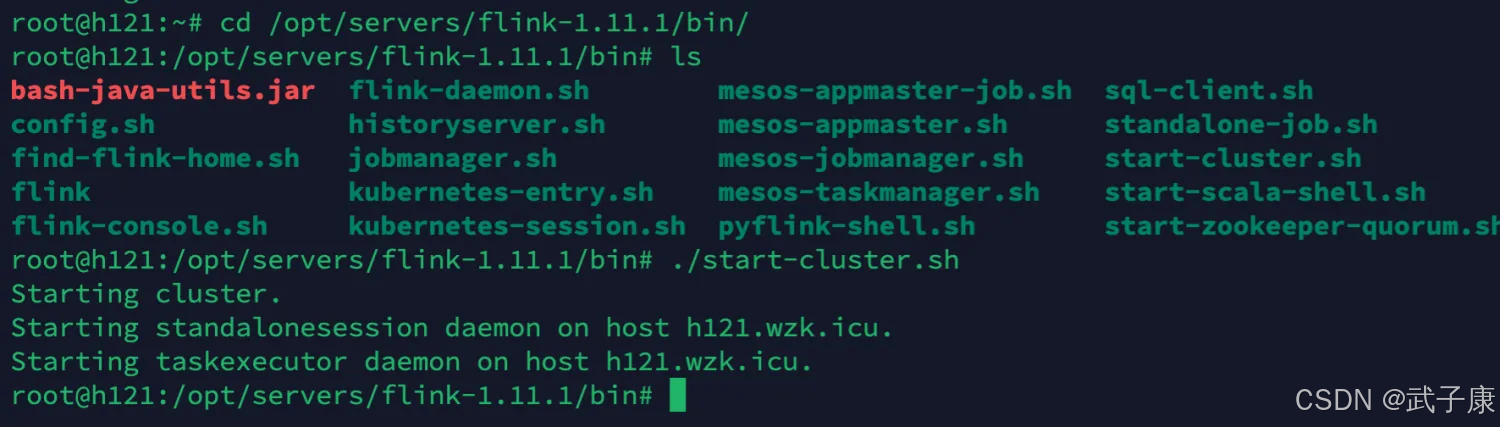
临时就可以先启动进行测试了:
登录后复制
cd /opt/servers/flink-1.11.1/bin/
./start-cluster.sh
复制代码
1.
2.
启动过程如下所示:
启动效果
这里要注意,由于我们之前配置过Spark环境,Spark的Web也是8081端口。
记得把Spark的服务停掉(临时用不到Spark相关的内容了)。
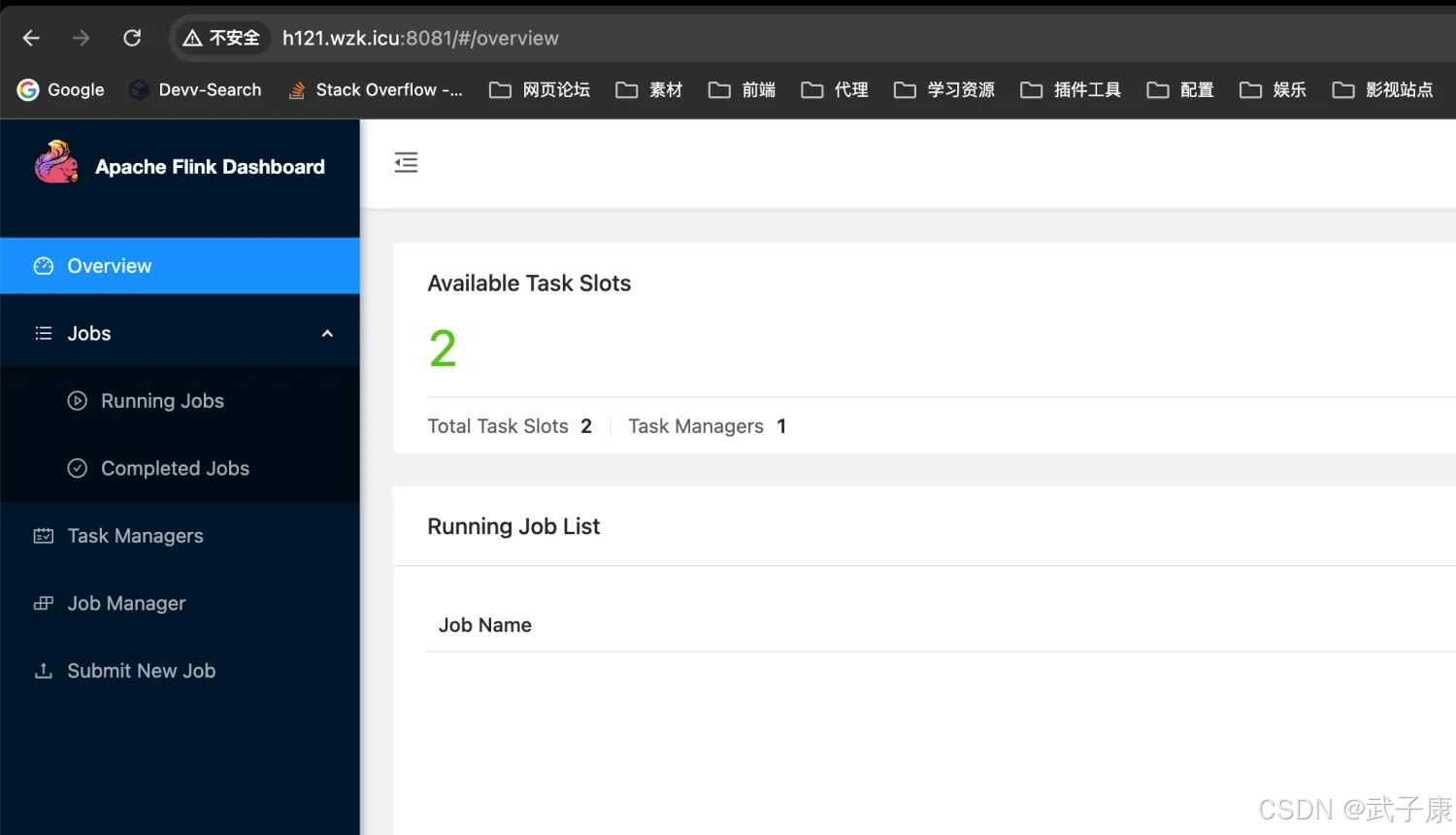
启动后,我们访问:
登录后复制
http://h121.wzk.icu:8081/#/overview
复制代码
1.
可以通过 JPS 命令查看主机当前的状态:(不需要的你可以停掉)
Hadoop
HDFS
Flink
等等
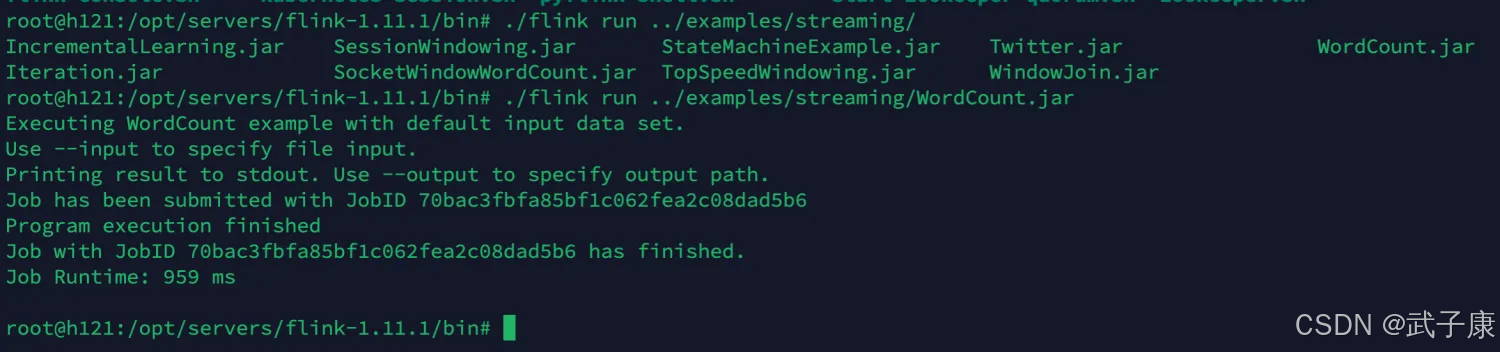
测试效果
官方提供的Demo,可以运行测试一下是否正常
登录后复制
cd /opt/servers/flink-1.11.1/bin
./flink run ../examples/streaming/WordCount.jar
复制代码
1.
2.
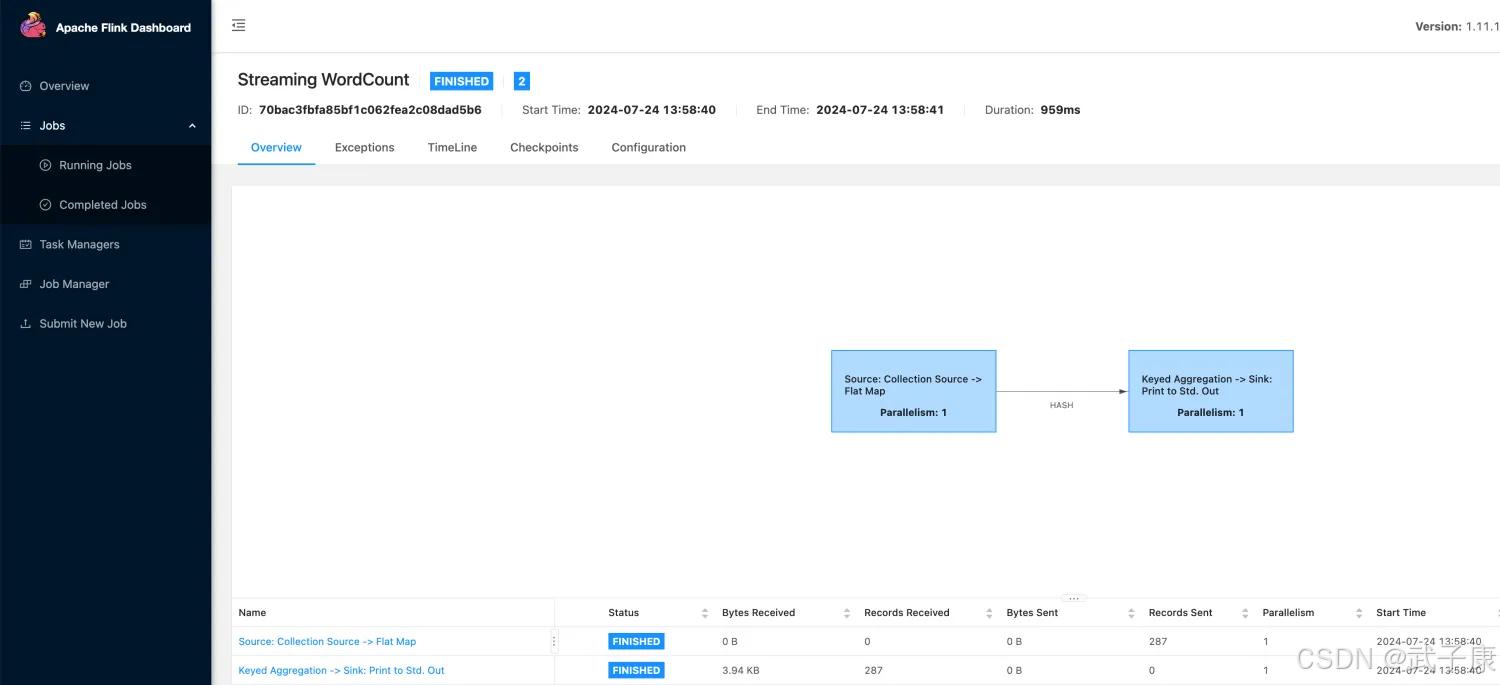
实行效果如下图:
可视化的页面也可以看到:
特点与优缺点
优点
轻便易用:Standalone 模式不需要额外的资源管理系统,配置相对简单,特别得当在资源固定的小型集群中运行。
独立性强:这种模式下,Flink 集群不依赖于外部系统,可以在没有 Yarn、Kubernetes 等资源管理平台的环境中独立运行。
低延迟:由于不涉及外部资源调度系统,Standalone 模式在资源调度上的延迟相对较低,得当需要低延迟使命调度的场景。
缺点
资源弹性差:由于没有集成外部资源管理系统,Standalone 模式的资源调度和管理相对固定,不支持动态扩展或缩减资源。这在面对变化的工作负载时,大概会导致资源浪费或不足。
管理复杂:在大规模集群中,手动管理多个 JobManager 和 TaskManager 大概变得复杂,特别是在需要高可用性和故障恢复的情况下。
缺乏高级特性:相比于集成 Yarn 或 Kubernetes 的摆设模式,Standalone 模式缺乏一些高级的资源管理特性,如自动化资源分配、动态扩展、集群隔离等。
使用场景
开辟与测试:Standalone 模式非常得当用于 Flink 应用的开辟与测试阶段,由于它配置简单,易于快速摆设和运行作业。
小型集群:在资源固定且规模较小的集群中,Standalone 模式可以提供充足的机动性和控制力。
边缘盘算:在某些资源有限的环境(如边缘盘算或嵌入式设备)中,Standalone 模式可以提供一种轻量级的分布式盘算解决方案。
扩展性与限定
扩展性有限:固然 Standalone 模式允许在固定资源下进行扩展,但由于缺乏动态资源管理,扩展本领有限,难以应对大规模或动态变化的工作负载。
适应性:对于需要频繁调整资源的场景,Standalone 模式大概不太实用,但在资源固定且作业负载相对稳固的情况下,它可以提供稳固可靠的服务。
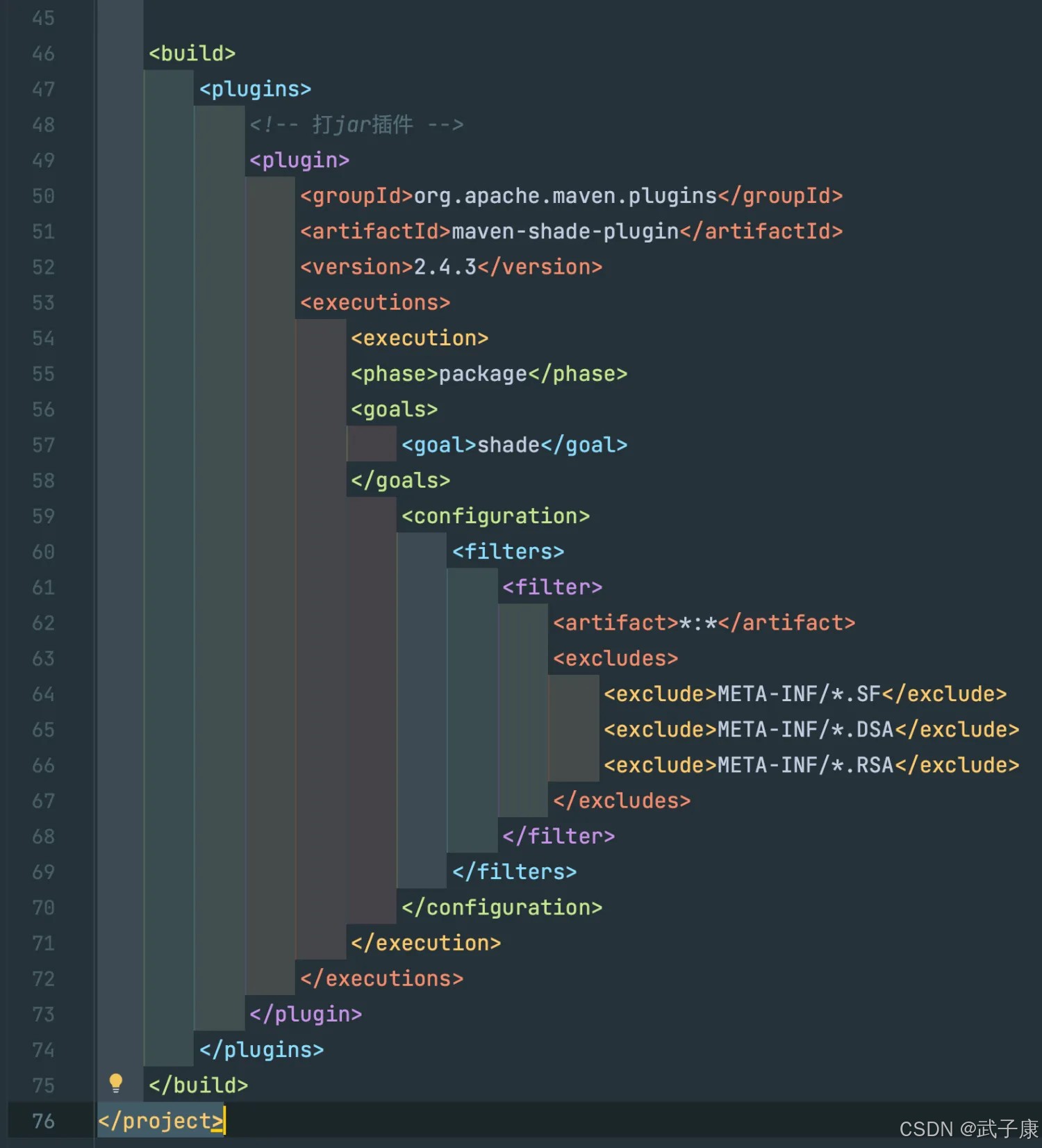
添加依赖
登录后复制
<build>
<plugins>
<!-- 打jar插件 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.4.3</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
复制代码
1.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
pom结构如下所示:
免责声明:如果侵犯了您的权益,请联系站长,我们会及时删除侵权内容,谢谢合作!更多信息从访问主页:qidao123.com:ToB企服之家,中国第一个企服评测及商务社交产业平台。
欢迎光临 ToB企服应用市场:ToB评测及商务社交产业平台 (https://dis.qidao123.com/)
Powered by Discuz! X3.4