qidao123.com技术社区-IT企服评测·应用市场
标题:
torchserve在转转GPU推理服务架构下的实践
[打印本页]
作者:
王海鱼
时间:
2024-12-7 00:57
标题:
torchserve在转转GPU推理服务架构下的实践
1 配景
转转面向二手电商业务,在搜索保举、智能质检、智能客服等场景落地了AI技能。在实践的过程中,也发现了存在GPU利用率广泛较低,浪费盘算资源,增加应用本钱等标题。别的还存在线上线下处理逻辑需要分别开发的环境,造成额外的开发本钱和错误排查本钱,对一些需要高速迭代的业务场景的负面影响不可忽视。
本文将会重点先容基于Torchserve举行推理服务部署架构优化的工程实践,希望对面临类似标题的同砚们有所资助。
2 标题息争决思路
2.1 近况分析
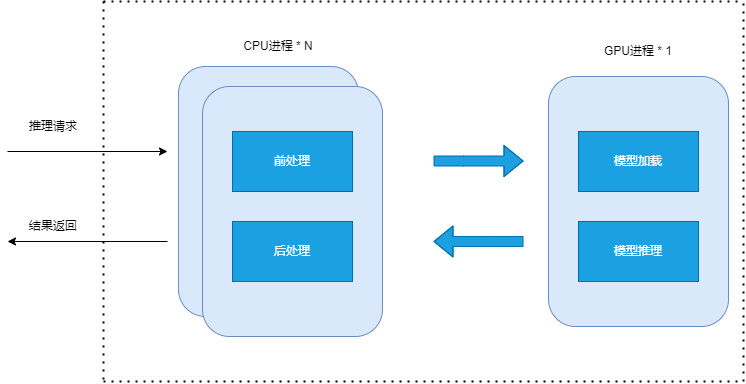
上图为之前的推理体系架构图,采用CPU和GPU分离的架构。这种架构的特点是:
GPU部分和CPU部分解耦分别部署微服务,预处理部分一般是在CPU上实行,轻易成为推理服务的性能瓶颈。解耦后可以将CPU部分部署在单独的机器上,无穷水平扩容扩容。
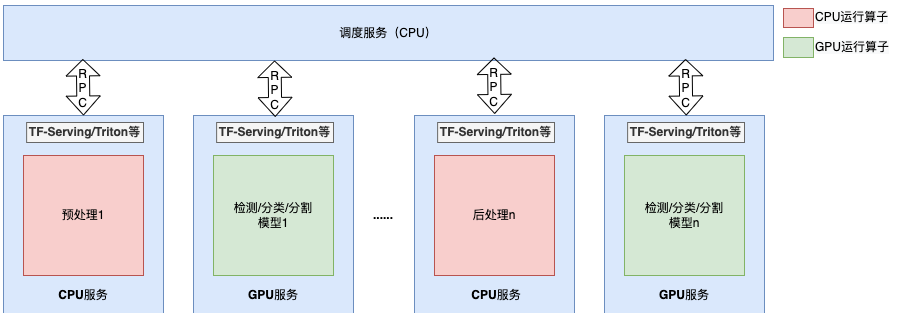
上图为美团通用高效的推理服务部署架构方案,可以看到架构思路基本相同。
2.2 标题
该方案具有很大的优点,也是业界多个公司采取的方案,但是架构的选项也需要考虑具体的业务场景。该方案在转转的的场景里就出现了一些标题,好比:
迭代效率:GPU实行部分的是基于torch或者tf的模型,可以接近0本钱的部署到推理微服务上,但是CPU实行部分包罗一些预处理、后处理的部分,除了一些常见的图像解码、缩放、NMS等操纵,另有很多自界说的逻辑,难以通过同一协议举行低本钱部署,需要在微服务里举行二次开发,并且大部分环境下需要采用和离线算法实现差别的开发语言,拖累业务迭代效率。当前业界算法工程师的重要工作语言为python,对其他的语言或者dsl都存在肯定的学习本钱。
网络通讯:转转的部分业务场景存在图片尺寸较大的环境,由于二手的某些质检场景需要高清图片判断有没有破损、划痕、污渍等细小痕迹。这样微服务之间的网络通讯开销负担比一般场景大很多。
2.3 办理思路
2.3.1框架调研
深度学习模型的常见的部署框架有以下几个:
特性TritonTorchServeTensorFlow Serving
支持的框架
多种深度学习框架,包括 TensorFlow、PyTorch、ONNX、TensorRT、OpenVINO 等专为 PyTorch 筹划,支持 PyTorch 模型专为 TensorFlow 筹划,支持 TensorFlow 模型
性能
高性能推理服务器,支持动态批处理、模型并行、多模型并发等性能较好,支持多线程推理,GPU 支持精良性能较好,支持多线程推理,GPU 支持精良
易用性
设置相对复杂,需要手动设置模型仓库、推理服务等易用性较好,提供了命令行工具和 Python API易用性较好,提供了命令行工具和 gRPC/REST API
社区和支持
由 NVIDIA 开发和维护,社区活跃,文档和示例丰富由 Facebook 开发和维护,社区活跃,文档和示例丰富由 Google 开发和维护,社区非常活跃,文档和示例丰富 从性能和质量的角度,三个框架水平都可以到达要求。重点考虑三个框架对于非深度学习部分的自界说逻辑支持:
tensoflow的tf.function装饰器和AutoGraph机制
tf.function是TensorFlow 2.x中引入的一个重要特性,它通过在Python函数上应用一个装饰器,将原生Python代码转换为TensorFlow图代码,从而享受图实行带来的性能上风。AutoGraph是tf.function底层的一项关键技能,它可以将复杂的Python代码,好比包罗while,for,if的控制流,转换为TensorFlow的图,例如:
@tf.function
def fizzbuzz(n):
for i in tf.range(n):
if i % 3 == 0:
tf.print('Fizz')
elif i % 5 == 0:
tf.print('Buzz')
else:
tf.print(i)
fizzbuzz(tf.constant(15))
复制代码
triton Python Backend机制
triton允许使用Python编写后端逻辑,这样可以利用Python的灵活性和丰富的库。Python Backend通过实现initialize、execute和finalize等接口来完成模型的加载、推理和卸载。这种方式得当于需要复杂逻辑处理的场景,好比多模型协同工作或者需要自界说预处理和后处理的环境。Python Backend可以与Triton的pipeline功能结合,实现更复杂的推理流程。例如下面的代码中,实现了一个initialize方法初始化,并且实现一个execute方法实行具体的逻辑,代码为python实现。
import numpy as np
class PythonAddModel:
def initialize(self, args):
self.model_config = args['model_config']
def execute(self, requests):
responses = []
for request in requests:
out_0 = request.inputs[0].as_numpy() + request.inputs[1].as_numpy()
out_tensor_0 = pb_utils.Tensor("OUT0", out_0.astype(np.float32))
responses.append(pb_utils.InferenceResponse([out_tensor_0]))
return responses
复制代码
torchserve Custom handlers
TorchServe通过界说handler来处理模型的加载、预处理、推理和后处理。handler通常继承自BaseHandler类,并重写initialize、preprocess、inference和postprocess等方法。如下面代码所示,与Triton Python Backend有些类似。
from ts.torch_handler import TorchHandler
class ImageClassifierHandler(TorchHandler):
def initialize(self, params):
"""初始化模型"""
self.model = SimpleCNN()
self.model.load_state_dict(torch.load('model.pth', map_location=torch.device('cuda:0')))
self.model.eval()
def preprocess(self, batch):
"""预处理输入数据"""
images = [img.convert('RGB') for img in batch]
images = [img.resize((224, 224)) for img in images]
images = [torch.tensor(np.array(img)).permute(2, 0, 1).float() for img in images]
images = [img / 255.0 for img in images]
return images
def postprocess(self, outputs):
"""后处理输出结果"""
_, predicted = torch.max(outputs, 1)
return predicted
复制代码
2.3.2框架选型
tensorflow serving的tf.function装饰器和AutoGraph机制并不能包管兼容所有的python代码和控制流,并不满足需求,在兼容第三方python包上也存在标题。别的tensorflow作为从前应用最广的深度学习框架,比年来在流行度上已经有被后来追上的趋势,tensorflow serving基本上只支持tensorflow框架,所以第一个排除。
Triton Python Backend和torchserve Custom handlers在功能和机制上比较类似。都提供了一个灵活、易用且可扩展的办理方案,特别得当于需要快速部署和灵活处理模型的场景。框架兼容上triton支持主流的所有框架,torchserve重要支持pytorch和onnx协议,都可以满足转转的需求。经过调研和试用,我们最终选择了torchserve作为本次的框架选项,原因如下:
torchserve与PyTorch生态深度集成,而Triton的学习曲线相对陡峭。torchserve重要支持torch框架,同时只兼容onnx协议。在轻量级和易用性上更符合转转当前的业务场景要求。例如在模型部署的格式转换和设置上,torchserve相较于triton要简易很多。
从后续转转GPU推理服务的演进来看,恒久来看支持所有主流推理框架是必需的,短期在业务高速成恒久优先选择一个框架与恒久支持所有主流并不冲突。
3 torchserve实践过程
3.1 torchserve使用与调优
3.1.1 使用流程
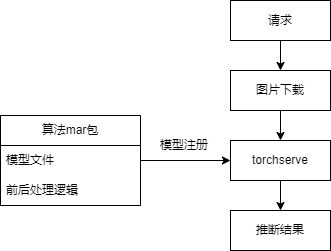
以一个图像模型简朴举例,如图所示:
将模型权重文件及前后处理逻辑python代码打包成一个mar包
mar包提交到torchserve历程中举行模型注册
请求到来后实行图片下载和模型前处理、推理、后处理,返回结果
mar包打包指令:
torch-model-archiver --model-name your_model_name --version 1.0 --serialized-file path_to_your_model.pth --handler custom_handler.py --extra-files path_to_any_extra_files
复制代码
your_model_name:你为模型指定的名称。
1.0:模型的版本号,可以根据实际环境举行修改。
path_to_your_model.pth:你的 PyTorch 模型文件的路径。
custom_handler.py:处理模型输入和输出的自界说处理函数文件。
path_to_any_extra_files:如果有其他需要一起打包的文件,可以在这里指定路径,可以是多个文件路径用逗号分隔。
torchserve的custom handler机制和易用性对于开发效率的提升是显著的,在我们的内部场景里,一个单人维护的推理服务,在半年内节省了约32PD(人日)的开发本钱。
3.1.2 torch-trt
模型的主干网络部分,需要举行优化,否则实行效率差耗时较长。torch-trt允许将PyTorch 模型转换为 TensorRT 格式,从而可以大概利用 TensorRT 强盛的优化引擎。TensorRT 针对 NVIDIA GPU 举行了高度优化,可以大概实现快速的推理性能。它通过对模型举行层融合、内核自动调整和内存优化等操纵,显著提高了模型的推理速率。
import torch
import torch_tensorrt
# Load your PyTorch model
model = torch.load('path_to_your_model.pth')
# Convert the model to TensorRT
trt_model = torch_tensorrt.compile(model, inputs=[torch_tensorrt.Input((1, 3, 224, 224))], enabled_precisions={torch.float32})
# Save the converted model
torch.save(trt_model, 'path_to_trt_model.pth')
复制代码
torch-trt比起tensorflow-trt和triton-trt相对来说比较简朴:
使用torch.compile可以一键转换。
整个流程用python用简朴的代码实现,学习本钱较低。
与pytorch和torchserve无缝衔接。
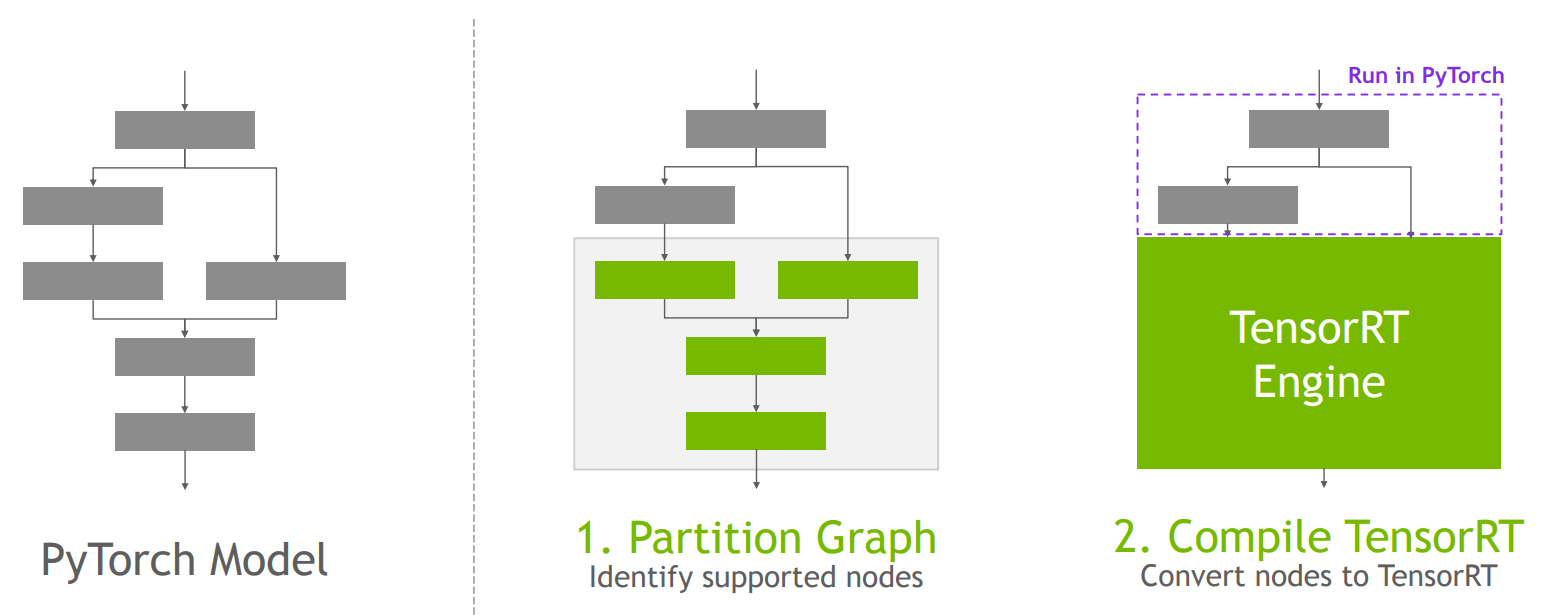
如上图所示为torch-trt的优化流程:
Partition Graph(划分图)
首先要对 PyTorch 模型的盘算图举行分析,找出此中 TensorRT 所支持的节点。这是由于并非所有的 PyTorch 操纵都能直接被 TensorRT 处理,需要确定哪些部分可以利用 TensorRT 的优化能力。根据识别出的支持节点环境,决定哪些部分在 PyTorch 中运行,哪些部分可以在 TensorRT 中运行。对于可以在 TensorRT 中运行的部分,将举行后续的转换操纵。
Compile TensorRT(编译 TensorRT)
对于在 Partition Graph 步骤中确定可以由 TensorRT 处理的节点,将其转换为 TensorRT 格式。这一步骤会利用 TensorRT 的优化技能,如层融合、内核自动调整和内存优化等,将这些节点转换为高效的 TensorRT Engine(引擎),从而提高模型的推理速率。
分组GPU利用率CPU利用率QPS显存占用torch-base40% ~ 80%20%~40%102GBtorch-trt10% ~ 50%100%17680MB 加入torch-trt之后的优化效果如上面表格,可以看出:
trt优化后,吞吐获得了提升,符合预期,吞吐的提升重要是半精度和实行流程优化带来的。显存占用也由于半精度和算子融合大幅降落,符合预期。
trt组的GPU没有打满,但是CPU打满了,吞吐的瓶颈从GPU转移到CPU,经过排查原因是预处理和后处理部分的CPU操纵在请求量大的时间已经将CPU打满了。
这个标题已往是通过CPU微服务水平扩容办理的,在torchserve中CPU和GPU的实行在一个历程内,无法水平扩容,下面将先容办理方案。
3.2 预处理和后处理部分优化
排查CPU实行部分占用率较高的逻辑,原由于部分盘算密集型逻辑被放在了前后处理中,例如opencv库中的一些api实行和通过numpy、pandas等库举行矩阵盘算。办理思路是将原来的python替换成NVIDIA官方提供的一些列对应的cuda版本库。例如cvCuda和cuDF分别对应OpenCV与pandas,并且提供了相同的api,只需要在import包的时间举行替换,开发本钱较低。
import cv2
import numpy as np
import cv2.cuda as cvcuda
# 读取图像
img = cv2.imread('your_image.jpg')
# 将图像转换为 GPU 上的格式
gpu_img = cvcuda.GpuMat(img)
# 使用 cvCuda 进行高斯模糊
gaussian_filter = cvcuda.createGaussianFilter(gpu_img.type(), -1, (5, 5), 1.5)
blurred_gpu = gaussian_filter.apply(gpu_img)
# 将处理后的图像转换回 CPU 格式
blurred_img = blurred_gpu.download()
# 显示结果
cv2.imshow('Original Image', img)
cv2.imshow('Blurred Image (cvCuda)', blurred_img)
cv2.waitKey(0)
cv2.destroyAllWindows()
复制代码
以上demo为例,只需要将cv2库替换为cvcuda库即可。
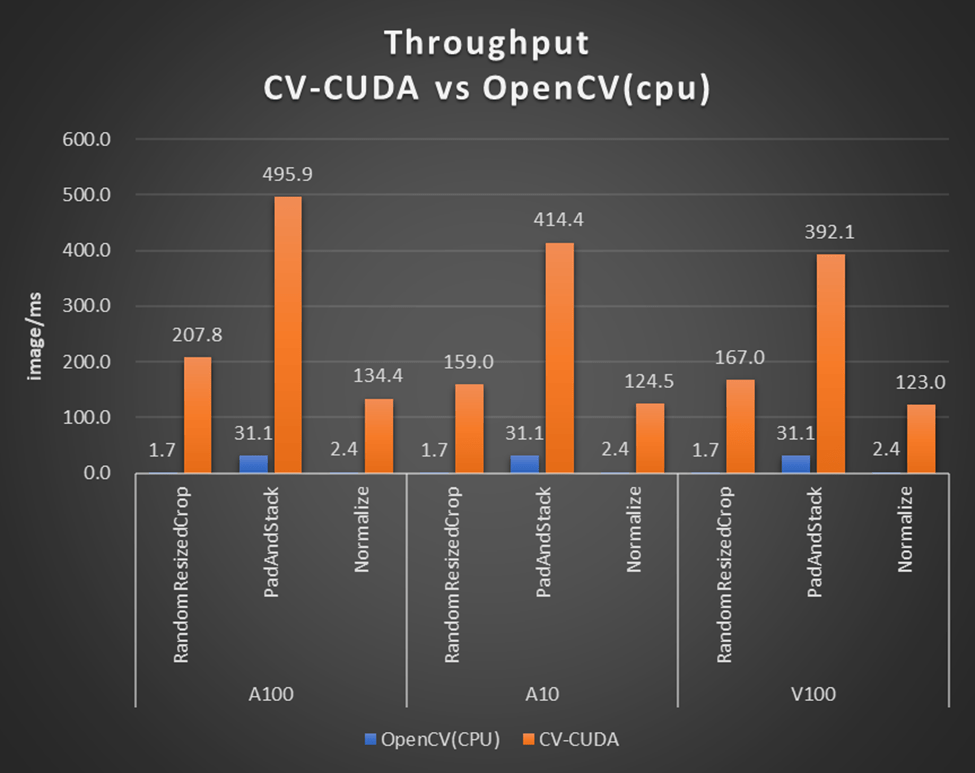
别的盘算密集型逻辑在CPU上实行性价比并不高,很多时间是使用风俗所致,在深度学习时代之前OpenCV和pandas就比较流行了,后续相沿之前的用法。从下面NVIDIA官方提供的测试结果来看,相干盘算逻辑在GPU上实行可以获得极大的性能提升。
上图为OpenCV和CV-CUDA在差别算子上的吞吐表现对比。
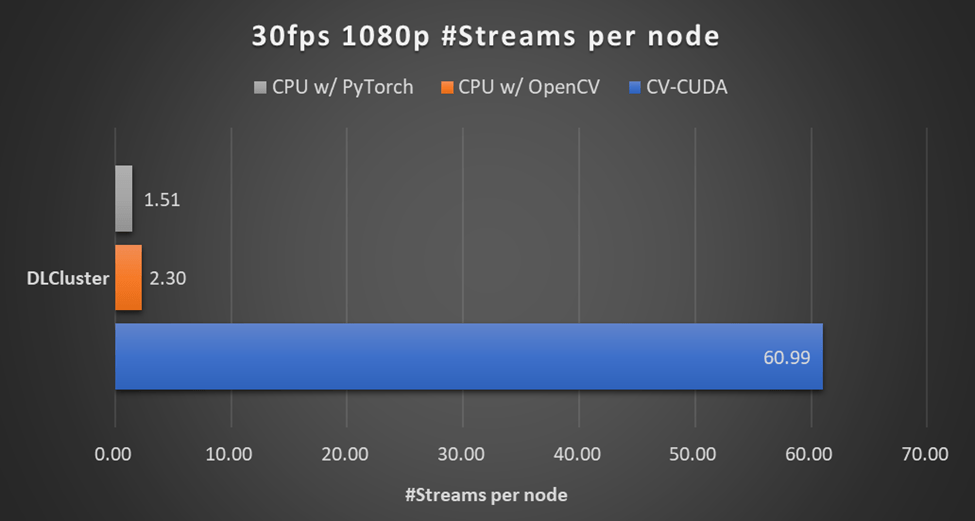
下图展示了在同一个盘算节点上(2x Intel Xeon Platinum 8168 CPUs , 1x NVIDIA A100 GPU),以 30fps 的帧率处理 1080p 视频,采用差别的 CV 库所能支持的最大的并行流数
下表为我们内部的测试结果:
分组GPU利用率CPU利用率QPS显存占用torch-base40% ~ 80%20%~40%102GBtorch-trt10% ~ 50%100%17680MBGPU预处理+trt60% ~ 80%60%402.1GB 从中可以看出,将预处理中盘算密集型部分放在GPU上乐成办理了此前碰到的标题。吞吐比base提升了4倍,GPU占用率提升显著,CPU占用率没有打满。需要注意的是显存占用率相应也会提升,由于之前在内存中举行的操纵被移到了显存上举行。
3.3 Torchserve on Kubernetes
torchserve官方通过Helm Charts提供了一个轻量级的k8s部署方案,可以实现服务的可靠运行和高可用性,,这也是我们在框架选型中看中torchserve的一个上风。
kubectl get pods
NAME READY STATUS RESTARTS AGE
grafana-cbd8775fd-6f8l5 1/1 Running 0 4h12m
model-store-pod 1/1 Running 0 4h35m
prometheus-alertmanager-776df7bfb5-hpsp4 2/2 Running 0 4h42m
prometheus-kube-state-metrics-6df5d44568-zkcm2 1/1 Running 0 4h42m
prometheus-node-exporter-fvsd6 1/1 Running 0 4h42m
prometheus-node-exporter-tmfh8 1/1 Running 0 4h42m
prometheus-pushgateway-85948997f7-4s4bj 1/1 Running 0 4h42m
prometheus-server-f8677599b-xmjbt 2/2 Running 0 4h42m
torchserve-7d468f9894-fvmpj 1/1 Running 0 4h33m
复制代码
以上为一个集群的pods列表,除了torchserve的微服务阶段,还提供了model-store功能,以及基于prometheus、grafana的监控报警体系。再加上k8s原有的能力,既可实现一个轻量级的支持故障自动恢复、负载均衡、滚动更新、模型管理、安全设置的高可用性和可弹性扩展体系。
4 后续工作
torchserve在转转GPU推理服务体系里的落地是一次均衡开发效率与体系性能的工程实践,总体上到达了筹划目标并且取得了业务价值。但是也存在一些不足,好比说原筹划前后处理部分线上和线下完全一致,共用相同的python代码,但是实践中碰到了CPU被打满的环境改变了方案。只管替换方案开发本钱较低但是仍然做不到Write once, run anywhere。
别的,当前提供的办理方案以效率为先,兼顾性能,得当快速落地及迭代。后续筹划针对更复杂的业务场景(多模型推理等)及推理模型(llm推理等),提供进阶的办理方案。同时,在云原一生台建设上,当前只是实现了一个入门版本,需要补课的内容还很多。
关于作者
杨训政,转转算法工程方向架构师,负责搜索保举、图像、大模型等方向的算法工程架构工作。
转转研发中心及业界小同伴们的技能学习交流平台,定期分享一线的实战经验及业界前沿的技能话题。
关注公众号「转转技能」(综合性)、「大转转FE」(专注于FE)、「转转QA」(专注于QA),更多干货实践,欢迎交流分享~
免责声明:如果侵犯了您的权益,请联系站长,我们会及时删除侵权内容,谢谢合作!更多信息从访问主页:qidao123.com:ToB企服之家,中国第一个企服评测及商务社交产业平台。
欢迎光临 qidao123.com技术社区-IT企服评测·应用市场 (https://dis.qidao123.com/)
Powered by Discuz! X3.4