return x \* torch.rsqrt(x.pow(2).mean(dim\=-1, keepdim\=True) + self.eps).to(device)
def forward(self, x):
#形状: x\[bs,seq,dim\]
output \= self.\_norm(x.float()).type\_as(x)
#形状: x\[bs,seq,dim\] -> x\_norm\[bs,seq,dim\]
return output \* self.weight
\### RMSNorm代码测试 ###
\# 取消下面的三重引号来执行测试
"""
x = torch.randn((ModelArgs.max\_batch\_size, ModelArgs.max\_seq\_len, ModelArgs.dim), device=device)
rms\_norm = RMSNorm(dim=ModelArgs.dim)
x\_norm = rms\_norm(x)
print(f"x的形状: {x.shape}")
print(f"x\_norm的形状: {x\_norm.shape}")
"""
\### 测试结果: ###
"""
x的形状: torch.Size(\[10, 256, 512\])
x\_norm的形状: torch.Size(\[10, 256, 512\])
"""
复制代码
旋转位置编码(Rotary Positional Encoding, RoPE)
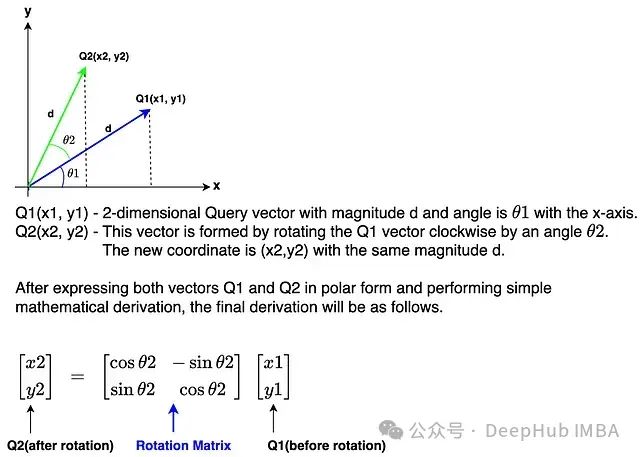
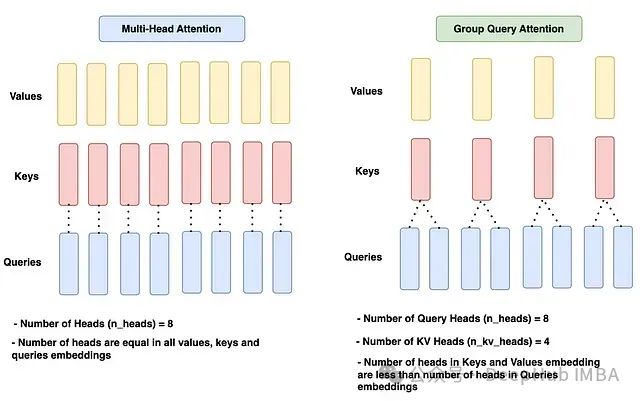
回首之前的步调,我们已将输入文本转换为嵌入,并对嵌入应用了RMSNorm。然而,这里存在一个问题:假设输入文本是"I love apple"或"apple love I",模型会将两个句子视为相同并以相同方式学习。这是因为嵌入中没有为模型定义顺序信息。因此对于任何语言模型来说,保持标记的顺序至关重要。在Llama 3模型架构中,引入了旋转位置编码(RoPE)来定义句子中每个标记的位置,这不仅维护了顺序,还保存了句子中标记的相对位置信息。 旋转位置编码的工作原理
RoPE是一种位置编码方法,它通过添加绝对位置信息以及包罗标记之间的相对位置信息来编码嵌入,从而维护句子中标记的顺序。它通过利用一个特殊的旋转矩阵来旋转给定的嵌入来执行编码操作。这种利用旋转矩阵的简洁而强大的数学推导是RoPE的焦点。