ToB企服应用市场:ToB评测及商务社交产业平台
标题:
1亿条数据批量插入 MySQL,哪种方式最快
[打印本页]
作者:
惊雷无声
时间:
2022-6-24 19:02
标题:
1亿条数据批量插入 MySQL,哪种方式最快
利用JAVA向Mysql插入一亿数量级数据—效率测评
这几天研究mysql优化中查询效率时,发现测试的数据太少(10万级别),利用 EXPLAIN 比较不同的 SQL 语句,不能够得到比较有效的测评数据,大多模棱两可,不敢通过这些数据下定论。
所以通过随机生成人的姓名、年龄、性别、电话、email、地址 ,向mysql数据库大量插入数据,便于用大量的数据测试 SQL 语句优化效率。、在生成过程中发现使用不同的方法,效率天差万别。
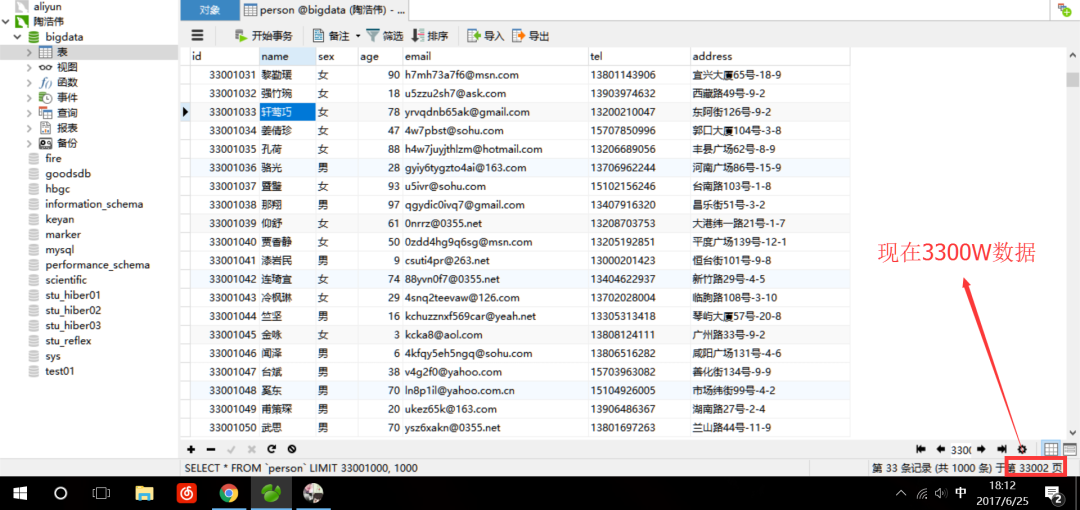
1、先上Mysql数据库,随机生成的人员数据图。分别是ID、姓名、性别、年龄、Email、电话、住址。
下图一共三千三百万数据:
在数据量在亿级别时,别点下面按钮,会导致Navicat持续加载这亿级别的数据,导致电脑死机。~觉着自己电脑配置不错的可以去试试,可能会有惊喜
2、本次测评一共通过三种策略,五种情况,进行大批量数据插入测试
策略分别是:
Mybatis 轻量级框架插入(无事务)
采用JDBC直接处理(开启事务、无事务)
采用JDBC批处理(开启事务、无事务)
测试结果:
Mybatis轻量级插入 -> JDBC直接处理 -> JDBC 批处理。
JDBC 批处理,效率最高
第一种策略测试:
2.1 Mybatis 轻量级框架插入(无事务)
Mybatis是一个轻量级框架,它比hibernate轻便、效率高。
但是处理大批量的数据插入操作时,需要过程中实现一个ORM的转换,本次测试存在实例,以及未开启事务,导致mybatis效率很一般。
这里实验内容是:
利用Spring框架生成mapper实例、创建人物实例对象
循环更改该实例对象属性、并插入。
[code]//代码内无事务 private long begin = 33112001;//起始id private long end = begin+100000;//每次循环插入的数据量 private String url = "jdbc:mysql://localhost:3306/bigdata?useServerPrepStmts=false&rewriteBatchedStatements=true&useUnicode=true&characterEncoding=UTF-8"; private String user = "root"; private String password = "0203"; @org.junit.Test public void insertBigData2() { //加载Spring,以及得到PersonMapper实例对象。这里创建的时间并不对最后结果产生很大的影响 ApplicationContext context = new ClassPathXmlApplicationContext("applicationContext.xml"); PersonMapper pMapper = (PersonMapper) context.getBean("personMapper"); //创建一个人实例 Person person = new Person(); //计开始时间 long bTime = System.currentTimeMillis(); //开始循环,循环次数500W次。 for(int i=0;i
欢迎光临 ToB企服应用市场:ToB评测及商务社交产业平台 (https://dis.qidao123.com/)
Powered by Discuz! X3.4