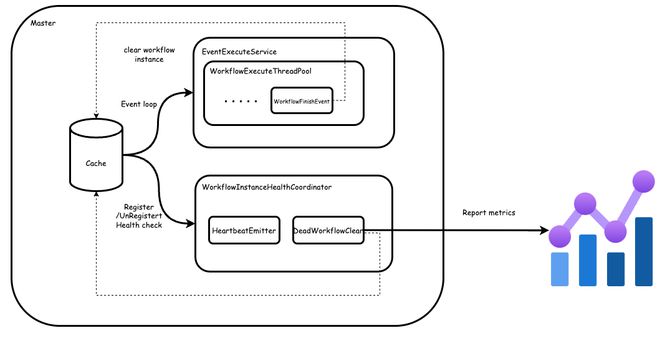
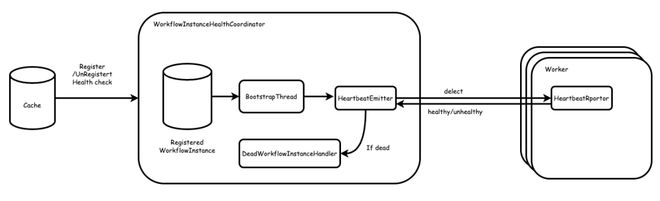
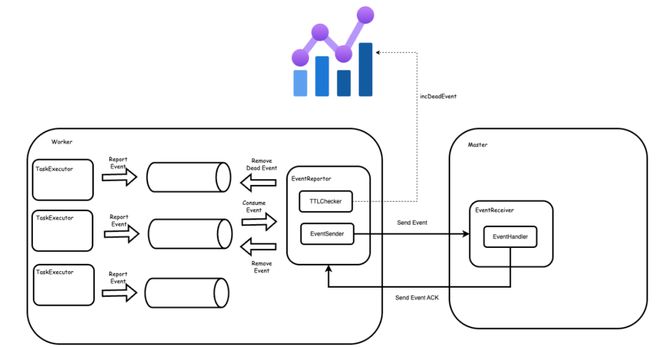
值得注意的是以上三种变乱都采用死信队列的方式存放,即只有当变乱被处置惩罚成功才会将变乱从队列移除,社区最初这么设计是希望在某些环境下由于基础设施故障,比方 db 抖动等不会影响到变乱的处置惩罚,但实际上有很多其他的意外环境会导致变乱处置惩罚失败,比方数据库存在非正常数据,变乱发送过程中出现乱序等。
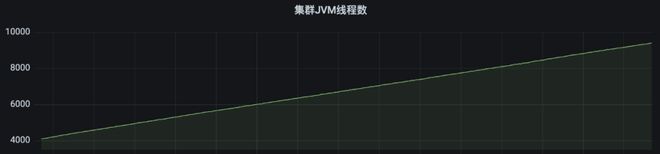
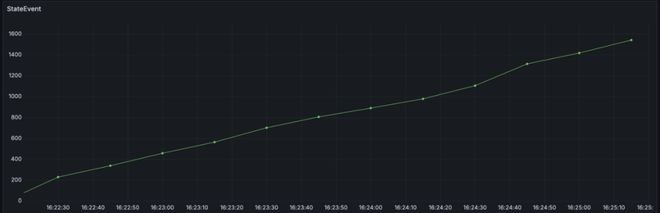
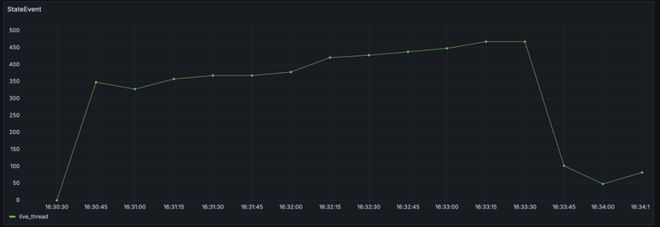
我们认为对于引擎来说,必要避免由于某一个工作流变乱处置惩罚出现题目,从而影响到引擎的稳定性。因此,我们移除了这里的死信队列,当变乱处置惩罚失败的时间,会直接扬弃变乱,并将工作流快速置为失败,由上层举行重试,并团结 Metrics 监控各类变乱的处置惩罚环境。修复后,Master CPU 保持稳定,服务日志也不再出现不绝重复处置惩罚某个变乱。
为了确保系统稳定运行,我们不光配置了大量告警,还定期举行一样平常、周、月巡检。通过巡检,我们可以或许提前发现潜伏题目,不断的美满自动化运维流程。我们如今发现的大多数题目都是通过巡检提前发现,避免了对业务造成实际影响。
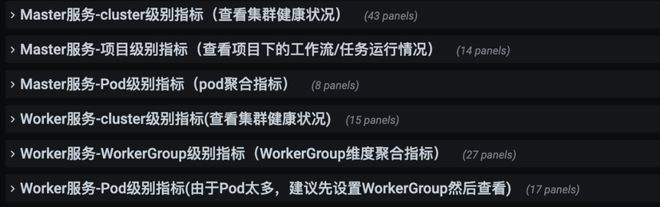
同时,巡检也帮助我们不断优化我们的监控大盘和告警项。如今我们从集群、项目、WorkerGroup 和 Pod 等维度搭建了监控面板和告警,以辅助巡检工作。