

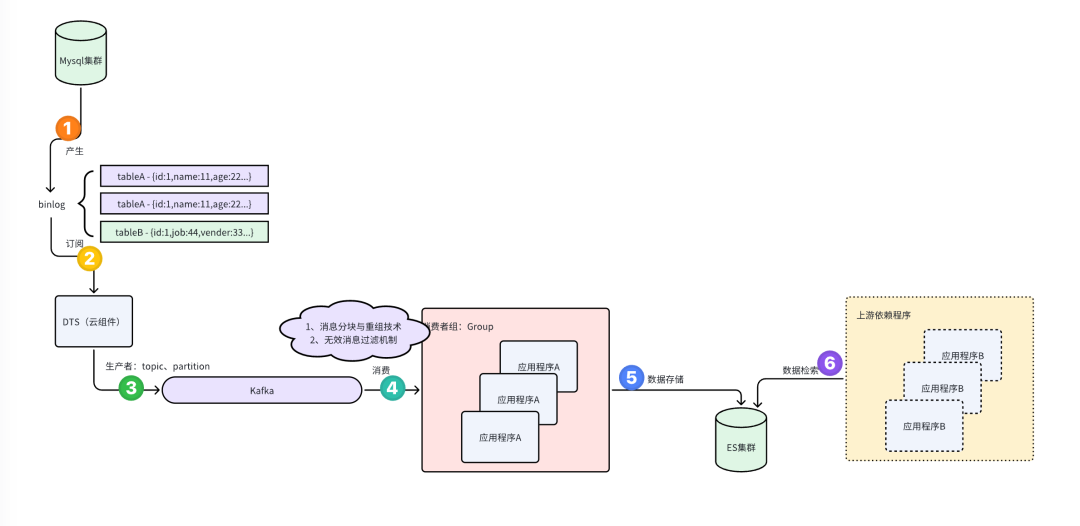
| log类型 | 日记类型 | 作用 | 数据类型 | 用法 | 支持级别 |
| redo log | 物理日记 - 在xx数据页做了xx修改” | 称为重做日记,当MySQL服务器意外崩溃或者宕机后,保证已经提交的事件恒久化到磁盘中(恒久性) | redo log 数据重要分为两类: - 内存中的日记缓冲(redo log buffer) - 磁盘上的日记文件(redo logfile) | - 崩溃恢复 | Innodb存储引擎 |
| undo log | 物理日记 - 在xx数据页做了xx修改” | 事件可以进行回滚从而保证事件操纵原子性则是通过undo log 来保证的 | undo log 数据重要分两类: - insert undo log - update undo log | - 事件回滚 - MVCC | Innodb存储引擎 |
| bin log | 逻辑日记 - 记录内容是语句的原始逻辑 | 记录了对MySQL数据库实行更改的全部的写操纵,包括全部对数据库的数据、表结构、索引等等变动的操纵。 | 三种格式,分别为 STATMENT 、 ROW 和 MIXED | - 数据恢复 - 主从复制 | MySQL Server层 |
| 能力 | 优点 | 不敷 | 备注 | |
| ROW | 基于行的复制(row-based replication, RBR),不记录每条SQL语句的上下文信息,仅需记录哪条数据被修改了 | 稳定性较好,不会出现某些特定情况下的存储过程、或function、或trigger的调用和触发无法被正确复制的题目; | 会产生大量的日记,尤其是 alter table 的时候会让日记暴涨。 | MySQL 5.7.7 之后,默认值是 ROW |
| STATMENT | 基于SQL语句的复制( statement-based replication, SBR ),每一条会修改数据的SQL语句会记录到 binlog 中 | 不需要记录每一行的变化,淘汰了 binlog 日记量,节约了 IO , 从而提高了性能; | 在某些情况下会导致主从数据不同等,好比实行sysdate() 、 slepp() 等 | MySQL 5.7.7 之前,默认的格式是 STATEMENT |
| MIXED | 基于 STATMENT 和 ROW 两种模式的混淆复制(mixed-based replication, MBR),一般的复制使用 STATEMENT 模式生存 binlog ,对于一些函数,STATEMENT 模式无法复制的操纵使用 ROW 模式生存 binlog。 |
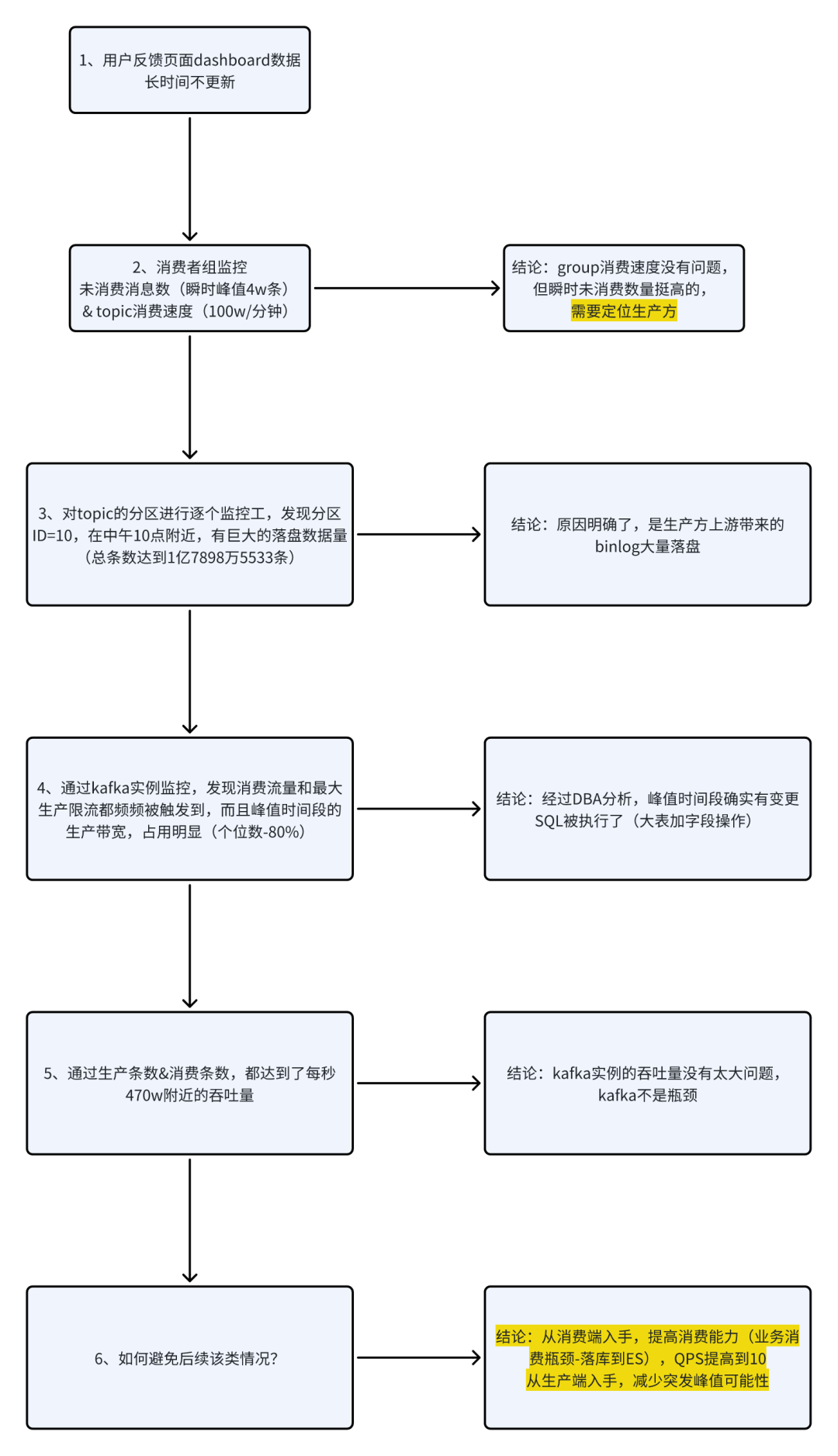
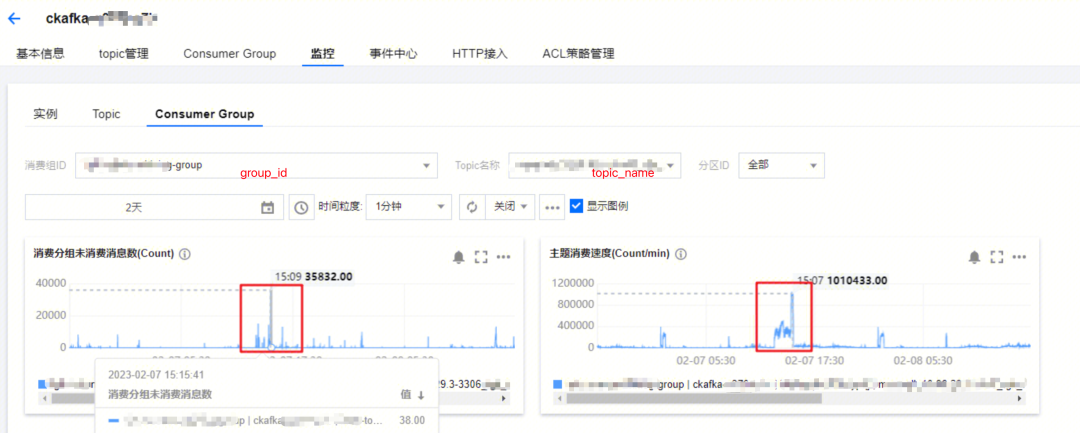
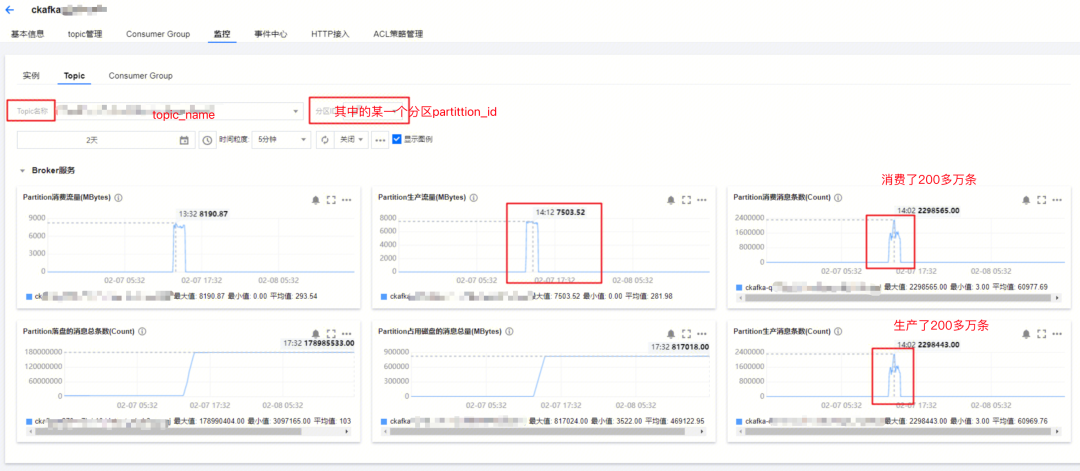
| 欢迎光临 ToB企服应用市场:ToB评测及商务社交产业平台 (https://dis.qidao123.com/) | Powered by Discuz! X3.4 |