qidao123.com技术社区-IT企服评测·应用市场
标题:
LLama factory 单机多卡-浅易版-教程
[打印本页]
作者:
拉不拉稀肚拉稀
时间:
2025-1-12 02:03
标题:
LLama factory 单机多卡-浅易版-教程
老规矩先贴官网代码:
https://github.com/hiyouga/LLaMA-Factory/blob/main/examples/README_zh.md
但是我还是没有根据这个下令跑出来,所以还是上其他方法把,有简单的就用
配景知识增补:
LLama factory 多卡 ZeRO-3 、ZeRO-2、 ZeRO-0什么意思?以及为什么没有ZeRO1
【深度学习】多卡训练__单机多GPU方法详解(torch.nn.DataParallel、torch.distributed)
Step1:先把webUI服务起起来
CUDA_VISIBLE_DEVICES=0 GRADIO_SHARE=1 llamafactory-cli webui
复制代码
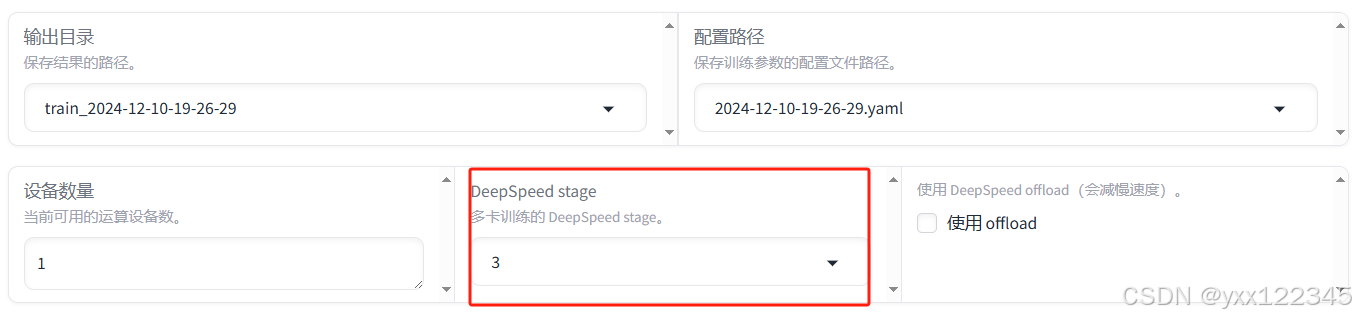
Step2:在webUI上设置好你的模子、数据集、输出文件夹、(可选wandb见之前的帖子)
声明llama3-8b-instruct不支持deepspeed不要轻易实验不然debug就是一整天,这个deepspeed不消选!!!
deepspeed stage
offload操作同理
此时预览训练下令行不在这里运行,网页端无法实现单机多卡!
llamafactory-cli train \
--stage sft \
--do_train True \
--model_name_or_path {模型地址} \
--preprocessing_num_workers 16 \
--finetuning_type lora \
--template llama3 \
--flash_attn auto \
--dataset_dir data \
--dataset {训练集} \
--cutoff_len 1024 \
--learning_rate 5e-05 \
--num_train_epochs 3.0 \
--max_samples 100000 \
--per_device_train_batch_size 2 \
--gradient_accumulation_steps 8 \
--lr_scheduler_type cosine \
--max_grad_norm 1.0 \
--logging_steps 5 \
--save_steps 100 \
--warmup_steps 0 \
--optim adamw_torch \
--packing False \
--report_to all \
--output_dir {输出路径} \
--bf16 True \
--plot_loss True \
--ddp_timeout 180000000 \
--include_num_input_tokens_seen True \
--lora_rank 8 \
--lora_alpha 16 \
--lora_dropout 0 \
--lora_target all \
--deepspeed cache/ds_z3_config.json
复制代码
Step3:打开bash,启动虚拟环境,粘贴以下下令
#!/bin/bash
CUDA_VISIBLE_DEVICES=0,1 python -m torch.distributed.run --nproc_per_node=2 src/train.py\
{复制网页端的配置}
复制代码
就像这样
#!/bin/bash
CUDA_VISIBLE_DEVICES=0,1 python -m torch.distributed.run --nproc_per_node=2 src/train.py\
--stage sft \
--do_train True \
--model_name_or_path {模型路径} \
--preprocessing_num_workers 16 \
--finetuning_type lora \
--template llama3 \
--flash_attn auto \
--dataset_dir data \
--dataset {数据集} \
--cutoff_len 1024 \
--learning_rate 5e-05 \
--num_train_epochs 3.0 \
--max_samples 100000 \
--per_device_train_batch_size 2 \
--gradient_accumulation_steps 8 \
--lr_scheduler_type cosine \
--max_grad_norm 1.0 \
--logging_steps 5 \
--save_steps 100 \
--warmup_steps 0 \
--optim adamw_torch \
--packing False \
--report_to all \
--output_dir {输出路径} \
--bf16 True \
--plot_loss True \
--ddp_timeout 180000000 \
--include_num_input_tokens_seen True \
--lora_rank 8 \
--lora_alpha 16 \
--lora_dropout 0 \
--lora_target all
复制代码
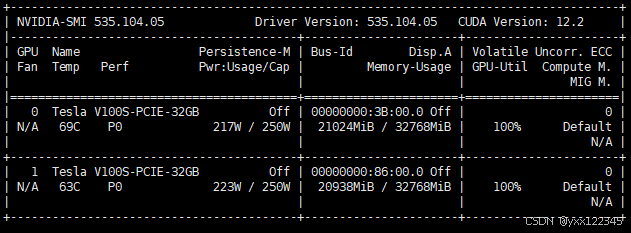
运行即可,运行时可以看到两个卡都被占用
用deepspeed的环境下报错处理:
可能会提示没有deepspeed这个库,pip install 一下即可
–deepspeed cache/ds_z3_config.json 这句话很可能会引起报错
不是全部的模子都支持deepspeed3!!
报错
AssertionError: no_sync context manager is incompatible with gradient partitioning logic of ZeRO stage 3
复制代码
这个错误表明你当前的设置存在辩论:
你正在使用 DeepSpeed ZeRO stage 3 优化
同期间码实验使用 no_sync context manager 举行梯度累积
这两个功能是不兼容的,因为:
ZeRO stage 3 会对梯度举行分区处理
而 no_sync 管理器试图阻止梯度同步,这与 ZeRO stage 3 的工作方式辩论
解决方案:
1.修改 DeepSpeed 设置,使用较低的 ZeRO stage (好比 stage 2 或 1)
2.或者调整训练参数,避免使用梯度累积(gradient accumulation):
examples/deepspeed/ds_z3_config.json这个文件的设置坑很多,偶然候需要把auto替换成整数值
{
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
"gradient_accumulation_steps": "auto",
"gradient_clipping": "auto",
"zero_allow_untested_optimizer": true,
"fp16": {
"enabled": "auto",
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
},
"bf16": {
"enabled": "auto"
},
"zero_optimization": {
"stage": 3,
"overlap_comm": true,
"contiguous_gradients": true,
"sub_group_size": 1e9,
"reduce_bucket_size": "auto",
"stage3_prefetch_bucket_size": "auto",
"stage3_param_persistence_threshold": "auto",
"stage3_max_live_parameters": 1e9,
"stage3_max_reuse_distance": 1e9,
"stage3_gather_16bit_weights_on_model_save": true
}
}
复制代码
错误日记
[rank0]: Input should be a valid integer, got a number with a fractional part [type=int_from_float, input_value=15099494.4, input_type=float]
复制代码
要任意改成整数
{
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
"gradient_accumulation_steps": "auto",
"gradient_clipping": "auto",
"zero_allow_untested_optimizer": true,
"fp16": {
"enabled": "auto",
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
},
"bf16": {
"enabled": "auto"
},
"zero_optimization": {
"stage": 3,
"overlap_comm": true,
"contiguous_gradients": true,
"sub_group_size": 1000000000,
"reduce_bucket_size": 500000000,
"stage3_prefetch_bucket_size": 500000000,
"stage3_param_persistence_threshold": 1000000,
"stage3_max_live_parameters": 1000000000,
"stage3_max_reuse_distance": 1000000000,
"stage3_gather_16bit_weights_on_model_save": true
}
}
}
复制代码
增补offload是干嘛的:
DeepSpeed Offload
是一种技术,用于在训练大规模深度学习模子时,将部分盘算任务或数据从 GPU
卸载
到 CPU 或 NVMe 存储装备,从而缓解显存压力,优化资源使用。它主要包含两种范例:
Optimizer Offload
和
Parameters Offload
。
以下是具体阐明:
1. 为什么需要 Offload?
训练大型模子(如 GPT-3 或其他数十亿参数的模子)时,显存可能成为瓶颈。即使使用分布式计谋,显存需求仍可能超出硬件的限制。
Offload 技术通过将部分模子的状态或盘算从显存转移到更大的主机内存(CPU RAM)或高速存储装备(NVMe),有效降低 GPU 显存占用,同时兼顾性能。
2. DeepSpeed Offload 的两种范例
(1) Optimizer Offload
功能
:将优化器的状态(如动量、二阶动量等)和梯度盘算任务从 GPU 卸载到 CPU。
优点
:
明显减少 GPU 显存占用。
实用于需要训练超大模子但 GPU 显存不足的环境。
缺点
:
由于 CPU 的内存带宽和盘算本领低于 GPU,性能可能受到影响,尤其是在高算力需求的任务中。
实用场景
:显存有限但有足够的 CPU 盘算本领和内存。
(2) Parameters Offload
功能
:将模子的参数从 GPU 显存卸载到 CPU 或 NVMe。
优点
:
大幅减少显存占用,使得更大的模子可以被加载和训练。
在 NVMe 的支持下,理论上可以训练任意巨细的模子。
缺点
:
依赖 CPU 内存或 NVMe 的访问速率,可能会增加训练的延长。
需要高性能 NVMe 和 I/O 操持,才能确保不会明显降低训练服从。
实用场景
:极大模子(如 100B+ 参数模子)训练,GPU 显存远远不足。
3. DeepSpeed Offload 的现实工作原理
数据转移
优化器状态或参数被拆分后,根据设置,在 GPU 和 CPU 或 NVMe 之间举行动态转移。
I/O 操作和盘算任务通过异步方式举行,以减少训练过程中的等待时间。
性能优化
DeepSpeed 使用高效的通讯技术和内存管理计谋(如 pipelining 和分块处理)来最小化数据传输的开销。
4. 设置示例
以下是典型的 DeepSpeed Offload 设置文件:
Optimizer Offload 示例
"zero_optimization": {
"stage": 2,
"offload_optimizer": {
"device": "cpu", // 将优化器状态卸载到 CPU
"pin_memory": true // 启用内存锁定以提高效率
},
"overlap_comm": true,
"reduce_bucket_size": 5e8
}
复制代码
Parameters Offload 示例
"zero_optimization": {
"stage": 3,
"offload_param": {
"device": "nvme", // 将模型参数卸载到 NVMe
"pin_memory": true,
"buffer_count": 4, // 用于缓冲的内存块数
"buffer_size": 1e8 // 每个缓冲区的大小
},
"stage3_param_persistence_threshold": 1e6
}
复制代码
5. 优缺点总结
功能
优点
缺点
Optimizer Offload
减少显存占用,适合较大的模子训练增加 CPU 盘算负载,I/O 速率可能成为瓶颈
Parameters Offload
能训练超大模子,突破显存限制NVMe 的访问速率较 GPU 慢,可能增加训练延长
6. 典型应用场景
研究机构或公司
:需要训练超大规模模子,但硬件预算有限。
超大模子训练
:例如 GPT-3、BLOOM 等需要数十或上百亿参数的模子。
多用户环境
:在资源共享场景下优化显存使用服从。
总结来说,
DeepSpeed Offload
是一种机动、高效的显存优化技术,通过卸载盘算任务和数据到 CPU 或 NVMe,可以或许支持更大的模子训练,顺应不同的硬件条件和需求。
免责声明:如果侵犯了您的权益,请联系站长,我们会及时删除侵权内容,谢谢合作!更多信息从访问主页:qidao123.com:ToB企服之家,中国第一个企服评测及商务社交产业平台。
欢迎光临 qidao123.com技术社区-IT企服评测·应用市场 (https://dis.qidao123.com/)
Powered by Discuz! X3.4