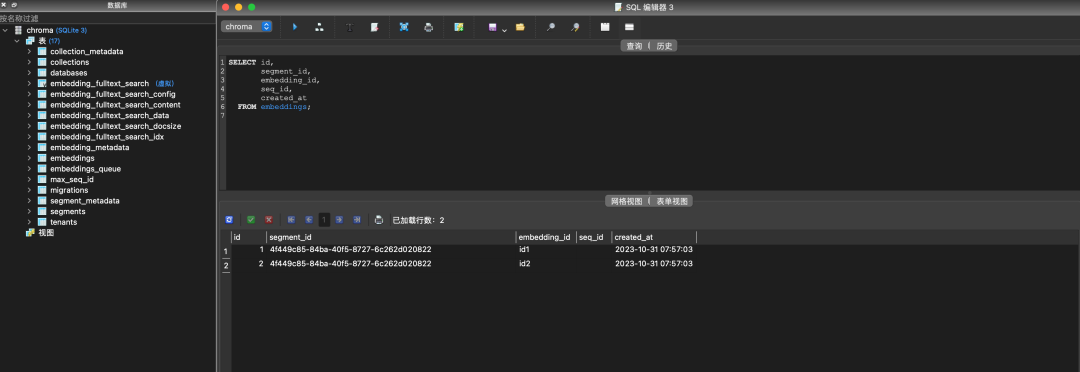
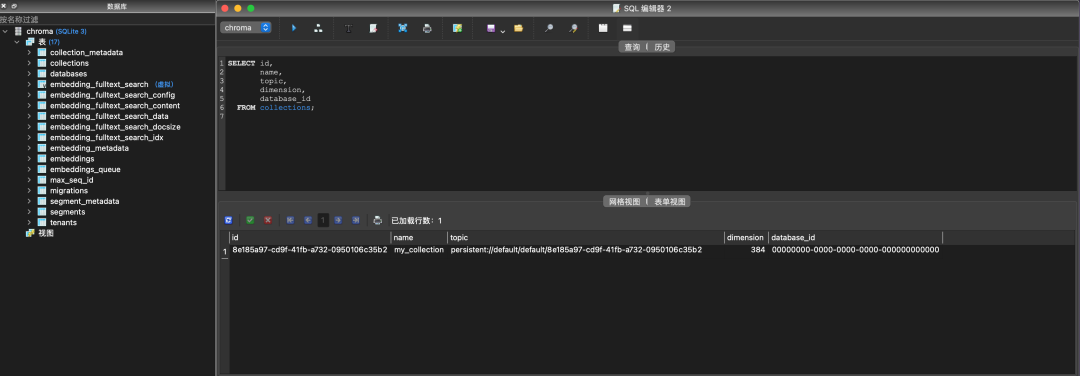
上面的代码中,我们向Chroma提交了两个文档(简单起见,是两个字符串),一个是This is a document about engineer,一个是This is a document about steak。若在add方法没有传入embedding参数,则会使用Chroma默认的all-MiniLM-L6-v2 方式进行embedding。随后,我们对数据集进行query,要求返回两个最干系的效果。提问内容为:Which food is the best?
返回效果:
{
'ids': [
['id2', 'id1']
],
'distances': [
[1.5835548639297485, 2.1740970611572266]
],
'metadatas': [
[{
'source': 'doc2'
}, {
'source': 'doc1'
}]
],
'embeddings': None,
'documents': [
['This is a document about steak', 'This is a document about engineer']
collection = client.get_collection(name="test") # Get a collection object from an existing collection, by name. Will raise an exception if it's not found.
collection = client.get_or_create_collection(name="test") # Get a collection object from an existing collection, by name. If it doesn't exist, create it.
client.delete_collection(name="my_collection") # Delete a collection and all associated embeddings, documents, and metadata. ⚠️ This is destructive and not reversible
collection.peek() # returns a list of the first 10 items in the collection
collection.count() # returns the number of items in the collection
collection.modify(name="new_name") # Rename the collection
复制代码
collection支持传入一些自身的元数据metadata:
collection = client.create_collection(
name="collection_name",
metadata={"hnsw:space": "cosine"} # l2 is the default
支持下列操纵操纵符:
$eq - equal to (string, int, float)
$ne - not equal to (string, int, float)
$gt - greater than (int, float)
$gte - greater than or equal to (int, float)
$lt - less than (int, float)
$lte - less than or equal to (int, float)
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('model_name')
复制代码
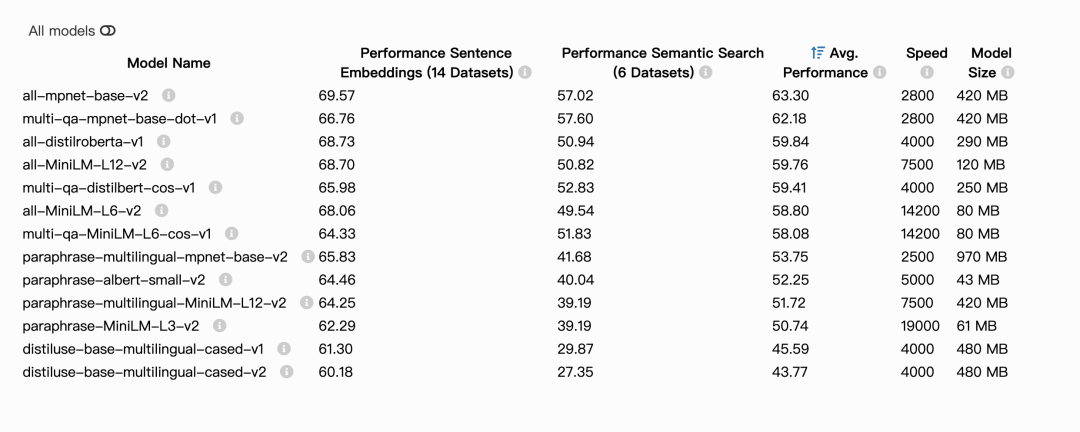
The all-* models where trained on all available training data (more than 1 billion training pairs) and are designed as general purpose models. The all-mpnet-base-v2 model provides the best quality, while all-MiniLM-L6-v2 is 5 times faster and still offers good quality. Toggle All models to see all evaluated models or visit HuggingFace Model Hub to view all existing sentence-transformers models.
选择非常多,你可以点击官网查看每种预训练模型的详细信息。
https://www.sbert.net/docs/pretrained_models.html