IT评测·应用市场-qidao123.com
标题:
Llama 3.2 900亿参数视觉多模态大模子本地部署及案例展示
[打印本页]
作者:
卖不甜枣
时间:
2025-1-22 01:36
标题:
Llama 3.2 900亿参数视觉多模态大模子本地部署及案例展示
Llama 3.2 900亿参数视觉多模态大模子本地部署及案例展示
本文将先容怎样在本地部署Llama 3.2 90B(900亿参数)视觉多模态大模子,并开发一些Use Case,展示其强大的视觉明白能力。
Llama 3.2 先容
今年9月,Meta公司发布了 Llama 3.2版本,包罗11B 和 90B的中小型视觉大语言模子,适用于边缘盘算和移动装备的1B 和 3B轻量级文本模子,,均预训练底子版和指令微调版,除此之外,还发布了一个安全模子Llama Guard 3。
Llama 3.2 Vision 是 Meta 发布的最强大的开源多模态模子。它具有出色的视觉明白和推理能力,可以用于完成各种任务,包罗视觉推理与定位、文档问答和图像 - 文本检索,思维链 (Chain of Thought, CoT) 答案通常非常好,这使得视觉推理特殊强大。
Llama 2于2023年7月发布,包含7B、13B和70B参数的模子。之后Meta在2024年4月推出了Llama 3,并在2024年7月敏捷发布了Llama 3.1版本,更新了8B和70B的模子,最重要的是推出了一个拥有405B参数的底子级模子。这些模子支持8种语言,具备工具调用功能,并且拥有128K的上下文窗口。
2024年9月份刚刚发布了Llama 3.2模子,增强了Llama 3.1的8B和70B模子,构建出11B和90B多模态模子,使其具备了视觉能力。
Llama 3.2 系列中最大的两个模子 11B 和 90B 支持图像推理使用案例,例如文档级明白(包罗图表和图形)、图像字幕和视觉接地任务(例如根据自然语言描述定向准确定位图像中的对象)。例如,可以问他们公司在上一年的哪个月贩卖额最好,然后 Llama 3.2 可以根据可用图表举行推理并快速提供答案。还可以使用地图举行推理并资助回答诸如徒步旅行何时会碰到陡峭的地形,或在地图上标志蹊径的隔断等标题。11B 和 90B 型号还可以通过从图像中提取细节、明白场景,然后生成一两个可用作图像标题的句子来资助报告故事,从而弥合视觉和语言之间的差距。
别的,Meta还发布了两个轻量级的模子:1B和3B模子,这些将资助支持装备端的AI应用。
在本地运行这些模子有两个主要上风。起首,提示和响应大概会让人感觉是即时的,由于处理是在本地完成的。其次,在本地运行模子不会将消息和日历信息等数据发送到云中,从而掩护隐私,从而使整个应用程序更加私密。由于处理是在本地处理的,因此应用程序可以清楚地控制哪些查询保留在装备上,哪些查询大概必要由云中的更大模子处理。
Llama Guard 3也是3.2版本的一部门,这是一种视觉安全模子,可以标志和过滤用户输入的有标题标图像和文本提示词。
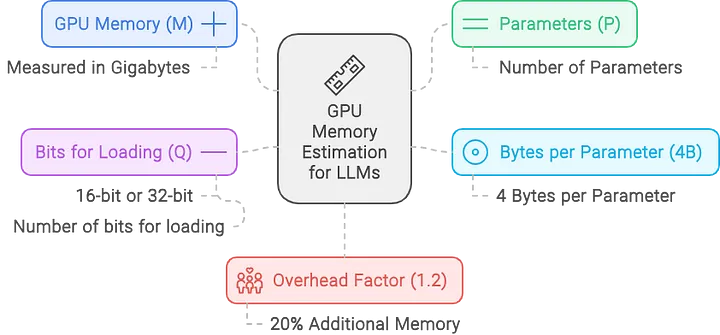
GPU显卡内存估算
怎样盘算大模子到底必要多少显存,是常常被问起的标题,相识怎样估算所需的 GPU 内存、精确调解硬件大小以服务这些模子至关重要。这是衡量你对这些大模子在生产中的部署和可扩展性的明白程度的关键指标。
要估算服务大型语言模子所需的 GPU 内存,可以使用以下公式:
KaTeX parse error: Undefined control sequence: \* at position 13: M=\\frac{(P \̲*̲ 4 B)}{(32 / Q)…
M是所需的 GPU 显卡内存(单位:GB千兆字节)。
P是模子中的参数数目,表示模子的大小。例如,这里使用的 Llama 90B模子有 900 亿个参数,则该值将为 90。
4B表示每个参数使用 4 个字节。每个参数通常必要 4 个字节的内存。这是由于浮点精度通常占用 4 个字节(32 位)。但是,假如使用半精度(16 位),则盘算将相应调解。
Q是加载模子的位数(例如,16 位或 32 位)。根据以 16 位还是 32 位精度加载模子,此值将会发生变化。16 位精度在很多大模子部署中很常见,由于它可以减少内存使用量,同时保持充足的准确性。
1.2 乘数增加了 20% 的开销,以解决推理期间使用的额外内存标题。这不仅仅是一个安全缓冲区;它对于覆盖模子实行期间激活和其他中间结果所需的内存至关重要。
这里想要估算为具有 90B(900 亿)个参数、以 16 位精度加载的 Llama 3.2 90B 视觉大模子提供服务所需的内存:
KaTeX parse error: Undefined control sequence: \* at position 14: M=\\frac{(90 \̲*̲ 4)}{(32 / 16)}…
这个盘算告诉我们,必要约莫216 GB 的 GPU 内存来为 16 位模式下具有 900 亿个参数的 Llama 3.2 90B 大模子提供服务。
因此,单个具有 80 GB 内存的 NVIDIA A100 GPU 大概 H00 GPU 不足以满足此模子的需求,必要至少3张具有 80 GB 内存的 A100 GPU 才能有效处理内存负载。
别的,仅加载 CUDA 内核就会斲丧 1-2GB 的内存。实际上,无法仅使用参数填满整个 GPU 内存作为估算依据。
假如是训练大模子环境(下一篇文章会先容),则必要更多的 GPU 内存,由于优化器状态、梯度和前向激活每个参数都必要额外的内存。
但博主囊中羞涩,为了完成这篇文章,选择 unsloth/Llama-3.2-90B-Vision-Instruct-bnb-4bit 的Llama 3.2 90B 视觉大模子的4bit量化模子,根据上面的估算公式,仅使用1张具有 80 GB 内存的 GPU 就可以运行完成本文案例所需的模子推理任务。
环境搭建
云服务器
找一台带一张H800 GPU 显卡的服务器(博主租用了一台服务器,耗费大概50元左右就能跑完本文案例use case,固然还必要一些降低费用的小本领,好比提前租用配置的服务器把模子文件下载到服务器,这样就可以节省很多费用
欢迎光临 IT评测·应用市场-qidao123.com (https://dis.qidao123.com/)
Powered by Discuz! X3.4