
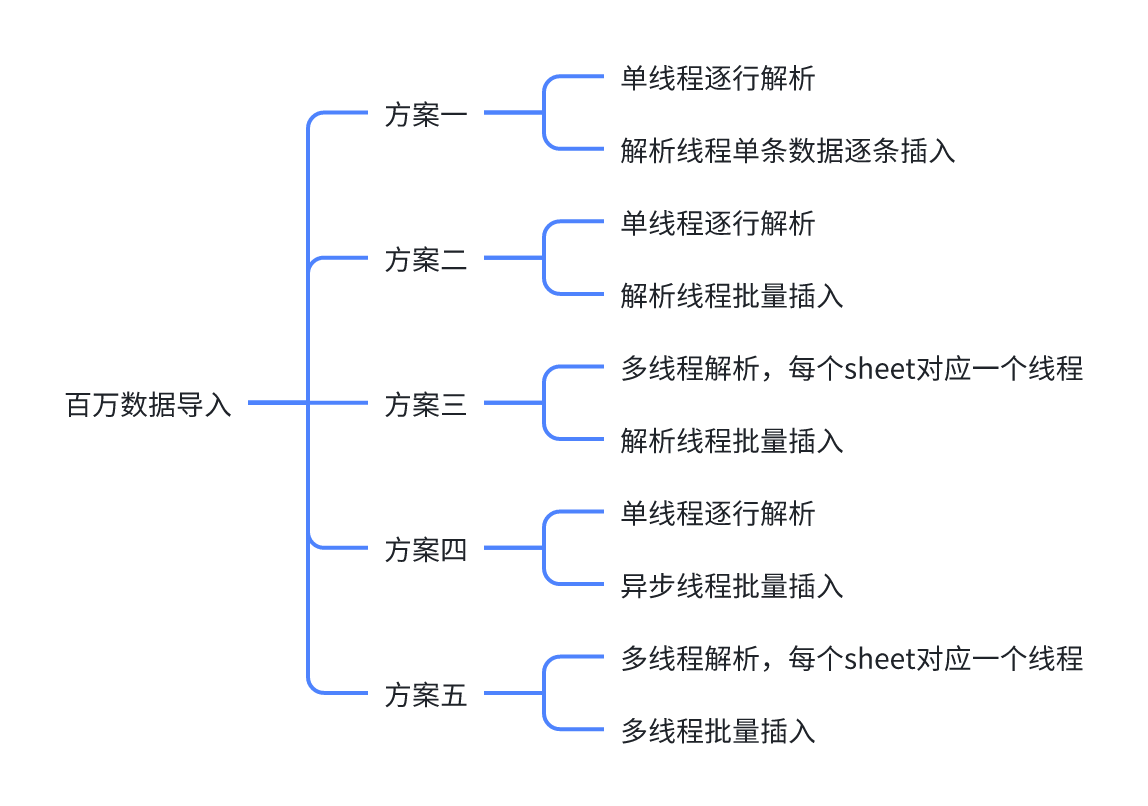
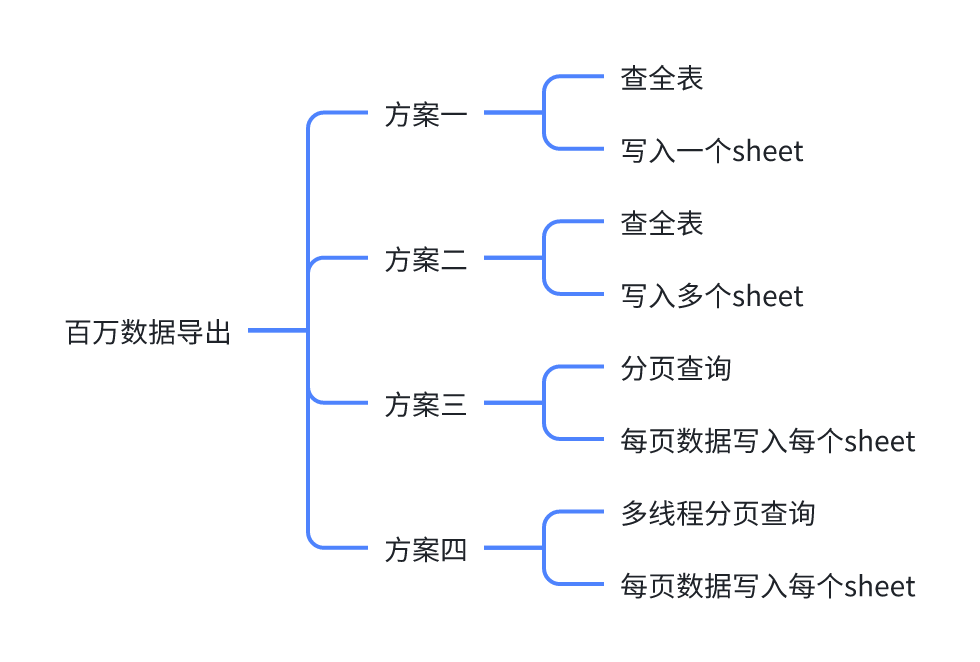
额外说一点:easyexcel 是不支持并发写入多个sheet,只能一个sheet一个sheet的写。因此尽管是多线程分页查询了,也只能单线程写入同一个excel

EasyExcel 的监听器类 Listener 已经定义了每一步会做什么,如通过 invokeHead 方法一行一行读取表头数据,通过invoke 方法一行一行读取真实数据。代码详情如下:
也就是说,我们已经知道了 Listener 类所需的关键步调,即一行一行读取数据,而且确定了这些步调的实行顺序,但表头数据的校验和处理,真实数据的校验和处理还无法确定;并且这些是由导入的具体数据决定的,差别的表会有差别的校验 和 处理方式。基于此,我们就可以想到用 模板方法模式!
| 欢迎光临 IT评测·应用市场-qidao123.com (https://dis.qidao123.com/) | Powered by Discuz! X3.4 |