KEGG是一个包含生物信息学数据库和相关工具的综合性资源,旨在资助我们明白生物系统的功能和组成。KEGG数据库包含了多种生物信息学数据,包括基因组、代谢途径、疾病和药物等信息。数据库分为三个级别,第一级分为七个大类:代谢途径(Metabolic Pathways)、遗传信息处理(Genetic Information Processing)、情况信息处理(Environmental Information Processing)、细胞过程(Cellular Processes)、有机系统(Organismal Systems)、人类疾病(Human Diseases)和药物开发(Drugs Development),富集分析结果中我们常见的**pathway属于第三级描述。
数据库还提供了一系列工具和资源,如KEGG Pathway,KEGG BRITE,KEGG Orthology等,资助我们进行生物信息学分析和研究。
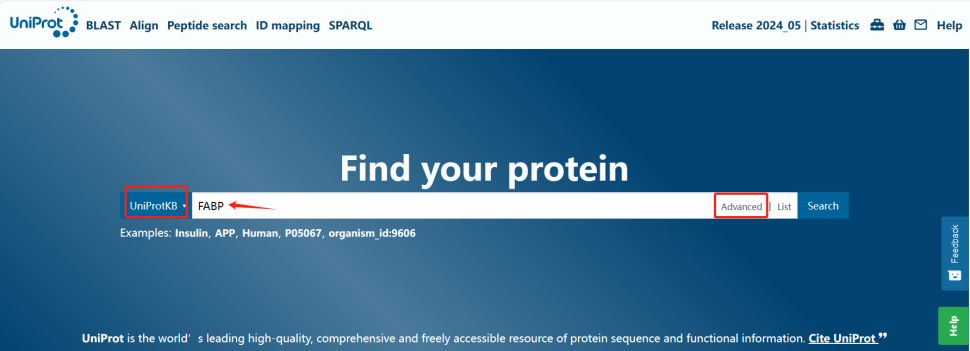
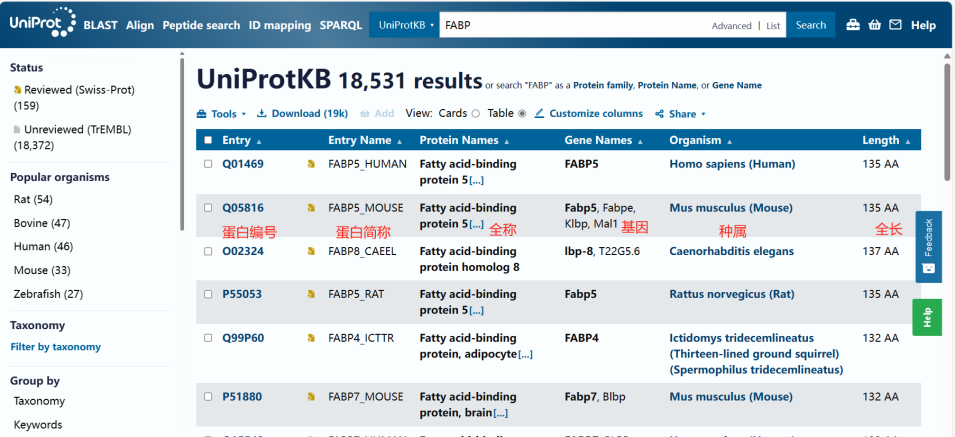
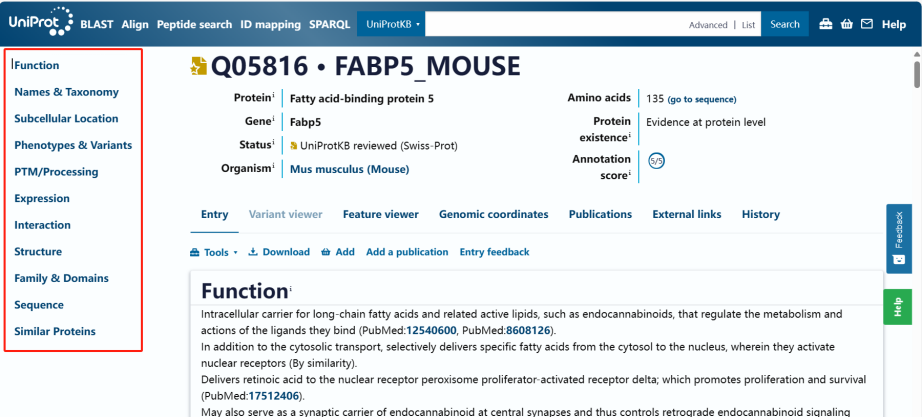
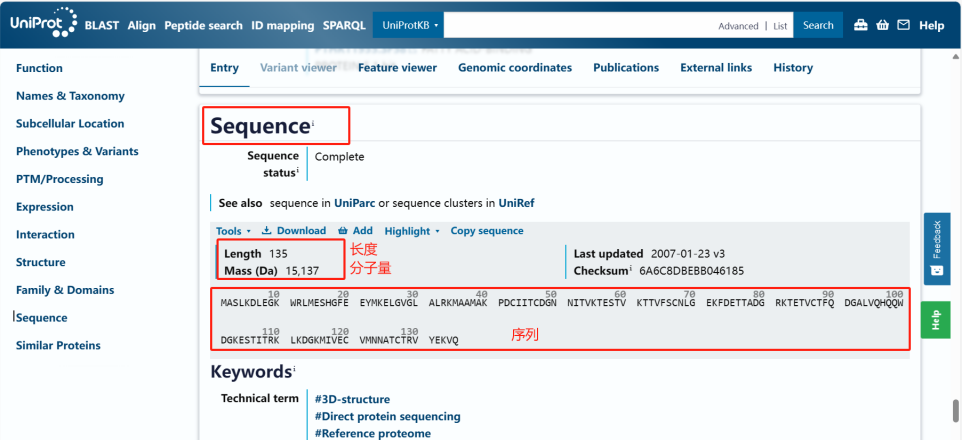
常见KEGG数据库比对结果解读:善用KEGG数据库挖掘目的基因
NR
NR全称为Non-Redundant Protein Database,是一个非冗余的卵白质数据库,由NCBI创建并维护,内容比较全面,涵盖了广泛的生物物种,包括细菌、真菌、植物、动物等。同时表明结果中会包含有物种信息,可作物种分类用。
使用Diamond软件,把目标物种的氨基酸序列,与NR数据库进行比对,把目标物种的基因和其相对应的功能表明信息结合起来,得到表明结果。该数据库可从NCBI上直接下载使用,下载地址为:ftp://ftp.ncbi.nlm.nih.gov/blast/db/fasta/nr.gz。
TrEMBL是UniProt(Universal Protein Resource,通用卵白质资源)数据库的一部门。
TrEMBL数据库包含了大量的卵白质序列,这些序列紧张是通过计算机预测或从核酸序列翻译而来,其表明信息相对较少。它的作用是补充Swissprot中未包含的卵白质序列,以增长卵白质数据的覆盖范围。下载地址:ftp://ftp.uniprot.org/pub/databases/uniprot/current_release/knowledgebase/complete/uniprot_trembl.fasta.gz