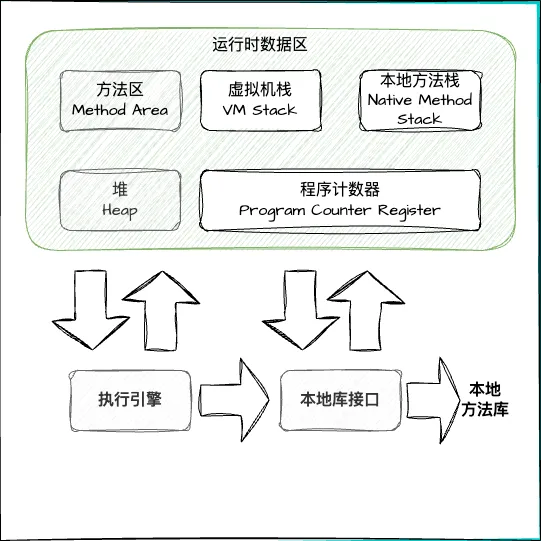
by emanjusaka from https://www.emanjusaka.com/archives/java-heap-stack-distribution-feature经常有人把 Java 内存区域笼统地划分为堆内存(Heap)和栈内存(Stack),这种划分方式直接继续自传统的 C、C++程序的内存布局结构,在 Java 语言就显得有些粗糙了,实际的内存区域划分是要更复杂一下。如下所示:
本文为原创文章,可能会更新知识点以及修正文中的一些错误,全文转载请生存原文地点,避免产生因未即时修正导致的误导。

谦学于心,谷纳万物,静思致远,共筑收获之旅!
原文地点: https://www.emanjusaka.com/archives/java-heap-stack-distribution-feature
微信公众号:emanjusaka的编程栈
| 欢迎光临 qidao123.com技术社区-IT企服评测·应用市场 (https://dis.qidao123.com/) | Powered by Discuz! X3.4 |