IT评测·应用市场-qidao123.com技术社区
标题:
HadoopMapReduce和Spark毕竟存在什么差异
[打印本页]
作者:
万有斥力
时间:
2025-2-20 14:29
标题:
HadoopMapReduce和Spark毕竟存在什么差异
起首是架构对比:
Hadoop MapReduce是一个两阶段模子,它强制分为Map和Reduce阶段:
1.在Map阶段中,它实行的操纵是:读取HDFS数据 ----->当地盘算------>写当地磁盘
2.在Shuffle阶段:通过网络传输排序数据
3.在Reduce阶段:拉取数据 ---->聚合盘算------>写HDFS
注:HDFS全程Hadoop Distributed File System,它是专门为大数据存储设计的分布式文件系统,它设计的目标是有三个,1是超大规模存储,它的单个集群可扩展到PB级 2.具有高容错性,硬件的故障视为常态而非异常,3.流式数据访问:优化数据吞吐量而非低延长(适合批量处理而非及时访问)
它有一个数据流缺陷的问题,即每个阶段竣事后数据必须落盘(磁盘IO成为瓶颈)
接下来来了解一下HadoopMapReduce的内部结构:
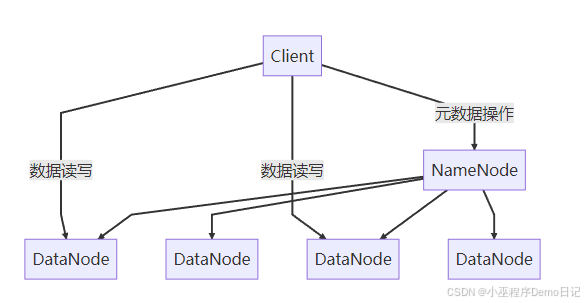
NameNode是主节点,它管理文件系统命名空间(文件名,目录结构,权限),它还会记录文件块的映射(Block到DataNodde的映射)
DataNode是工作节点,它实际存储数据块(默认128MB/块),定期向NameNode发送心跳(默认3秒)和块报告,而且数据块会主动复制
数据存储机制:
从客户端的视角出发,文件写入的过程是:
1.客户端联系NameNode获取可写DataNode列表
2.建立数据通道:Client -> DataNode1 ->DataNode2 ->DataNode3(默认3副本)
3.数据以包(Packet,默认64KB)为单位传输
4.确认信息通过反向管道返回客户端
高可用方案(HA)
双NameNode架构
Active NameNode:处理客户端哀求
Standby NameNode:同步EditLog,准备故障接管
利用ZooKeeper实现主动故障转移(Failover时间<30秒)
它支持与Spark的集成 :
典范的数据流
<img alt="" height="86" src="https://i-blog.csdnimg.cn/direct/480d30db5b6e45ddbd527f2e30ecee70.png" width="588" />
复制代码
在企业中,我们都会利用Parquet/ORC列式存储格式,避免利用TextFile文件格式,可以节省50%的存储空间,然后HDFS块大小和Spark分区数的关系最好是1:1
Spark核心部门:DAG引擎构建的过程:
[/code] [align=center][img=436,606]https://i-blog.csdnimg.cn/direct/1a3d019425f1459a97c535531588b127.png[/img][/align]
[list]
[*] 阶段划分规则
[list]
[*] 窄依靠
(Narrow Dependency):父RDD的每个分区最多被子RDD的一个分区利用
[list]
[*] 示例:map、filter、flatMap等转换操纵
[*] 优化时机:多个窄依靠操纵合并为单个Stage
[/list]
[*] 宽依靠
(Wide Dependency):父RDD的分区被多个子RDD分区利用(Shuffle产生)
[list]
[*] 示例:reduceByKey、join、repartition等操纵
[*] 触发Stage边界划分
[/list]
[/list]
[/list] DAG内存管理架构:
[code]<img alt="" height="467" src="https://i-blog.csdnimg.cn/direct/317da9c13d7748f290013fb1dad0b99d.png" width="598" />
复制代码
参数表明:
ExecutorMemory(实行器内存)
:
Spark 实行器进程的总内存
默认由 spark.executor.memory 设置指定
StorageMemory(存储内存)- 60%
:
用于缓存 RDD、广播变量和数据帧
当内存不敷时利用 LRU(最近最少利用)策略淘汰数据
可通过 spark.memory.storageFraction 调解比例
ExecutionMemory(实行内存)- 40%
:
用于存储 Shuffle、Join、Sort 等盘算过程中的临时数据
在多个使命之间共享
剩余比例 = 1 - storageFraction
DiskSpill(磁盘溢出)
:
当 StorageMemory 空间不敷时
利用 LRU 策略将最近最少利用的数据块溢写到磁盘
ShuffleBuffer(Shuffle缓冲区)
:
在 Task 之间共享的实行内存空间
用于 Shuffle 操纵的数据缓存
当缓冲区满时会触发溢写到磁盘
3. 与MapReduce的对比优势
实行模子对比
阶段MapReduceSpark使命调度每个Task独立JVM进程线程池复用(毫秒级启动)数据转达必须颠末磁盘内存优先,可选磁盘中间效果多轮磁盘IO内存缓存复用容错机制重新实行整个Task基于RDD血统局部重算 什么是RDD:
RDD(Resilient Distributed Dataset)是Spark的核心抽象,代表一个
不可变、可分区的分布式数据集合
:
1. RDD设计哲学
产生背景
MapReduce的缺陷
:
中间数据必须写磁盘(迭代算法效率低下)
缺乏高效的数据复用机制
编程模子不够机动
RDD创新点
:
内存盘算:中间效果可缓存
血统(Lineage)机制:通过记录转换历史实现容错
丰富的操纵API:支持超过20种转换操纵
2. RDD核心特性
五大核心特征
分区列表
(Partitions):
val partitions: Array[Partition] = rdd.partitions
复制代码
数据被划分为多个分区(Partition)
每个分区对应一个Task
可通过repartition()调解分区数
依靠关系
(Dependencies):
val deps: Seq[Dependency[_]] = rdd.dependencies
复制代码
窄依靠(Narrow):父RDD的每个分区最多被一个子分区利用
宽依靠(Wide):父RDD的分区被多个子分区利用(触发Shuffle)
盘算函数
(Compute Function):
def compute(split: Partition, context: TaskContext): Iterator[T]
复制代码
界说怎样从父RDD盘算当前分区的数据
支持链式转换操纵(如map(transformA).map(transformB))
分区器
(Partitioner):
val partitioner: Option[Partitioner] = rdd.partitioner
复制代码
决定数据怎样分布(HashPartitioner、RangePartitioner)
影响Shuffle效率的关键因素
首选位置
(Preferred Locations):
def getPreferredLocations(split: Partition): Seq[String]
复制代码
实现数据当地性(Data Locality)
比方HDFS块的位置信息
3. RDD生命周期
创建到实行流程
<img alt="" height="534" src="https://i-blog.csdnimg.cn/direct/bb364e598c8e49868b1b9083295cbd5d.png" width="595" />
复制代码
容错机制
血统(Lineage)恢复
:
val rdd = sc.textFile("hdfs://data")
.map(parse) // Lineage记录1
.filter(_.isValid) // Lineage记录2
.cache()
复制代码
丢失缓存数据时,根据血统重新盘算
通过checkpoint()切断过长血统链
4. RDD操纵类型
转换(Transformations)
操纵类型示例特点窄依靠转换map(), filter()不触发Shuffle宽依靠转换reduceByKey(), join()触发Shuffle重分区repartition(), coalesce()改变分区数
动作(Actions)
操纵类型示例输出形式数据收集collect(), take(N)返回Driver步伐数据存储saveAsTextFile()写入外部存储聚合盘算count(), reduce()返回标量值
5. 企业级应用模式
缓存策略选择
// 根据数据使用频率选择存储级别
if (rdd会被多次使用) {
rdd.persist(StorageLevel.MEMORY_ONLY_SER)
} else if (rdd太大无法完全放入内存) {
rdd.persist(StorageLevel.MEMORY_AND_DISK)
}
复制代码
性能调优技巧
分区数优化
:
// 合理设置分区数(建议每个分区128MB)
val optimalPartitions = (dataSize / 128MB).toInt
rdd.repartition(optimalPartitions)
复制代码
避免数据倾斜
:
// 对倾斜Key添加随机前缀
val skewedRdd = rdd.map(k => (s"${Random.nextInt(10)}_$k", v))
复制代码
广播变量优化Shuffle
:
val smallTable = sc.broadcast(lookupData)
largeRdd.map { case (k, v) =>
(smallTable.value.getOrElse(k, default), v)
}
复制代码
6. RDD与DataFrame对比
特性RDDDataFrame数据类型恣意对象结构化数据(Row类型)优化方式开发者手动优化Catalyst主动优化内存利用较高(Java对象开销)较低(Tungsten二进制格式)API类型函数式编程SQL风格序列化Java序列化高效编码
7. 实用场景
推荐利用RDD的场景
:
非结构化数据处理(如文本、图像)
需要精细控制分区的场景
实现自界说的复杂算法
推荐利用DataFrame的场景
:
结构化数据分析(雷同SQL查询)
需要主动优化的场景
与其他大数据组件集成(如Hive)
2. Spark和Hadoop的MapReduce的性能差异:
基准测试对比
使命类型MapReduce耗时Spark耗时优势倍数迭代算法(PageRank)120分钟8分钟15x日志分析(TB级)45分钟6分钟7.5x呆板学习(K-means)90分钟11分钟8x
性能差异根源
磁盘IO
:MapReduce每个阶段写磁盘 vs Spark内存盘算
使命启动
:MapReduce每个Task启动JVM(秒级) vs Spark复用线程池(毫秒级)
数据交换
:MapReduce必须Shuffle vs Spark可优化窄依靠操纵
4. 生态系统对比
组件Hadoop MapReduceSparkSQL引擎需依靠Hive(启动MR使命)原生Spark SQL(直接实行)呆板学习需Mahout库(效率低)原生MLlib(内存盘算)流处理无(需Storm等外部系统)结构化流(微批/连续模式)图盘算无(需Giraph)GraphX(集成RDD)
5. 容错机制对比
MapReduce
Task失败时重新调度(数据从HDFS重新读取)
可靠性高但恢复速率慢(需重新盘算整个Task)
Spark
基于RDD血统(Lineage)的弹性恢复
丢失RDD分区时,只需根据DAG重新盘算父分区
Checkpoint机制可切断过长血统链
免责声明:如果侵犯了您的权益,请联系站长,我们会及时删除侵权内容,谢谢合作!更多信息从访问主页:qidao123.com:ToB企服之家,中国第一个企服评测及商务社交产业平台。
欢迎光临 IT评测·应用市场-qidao123.com技术社区 (https://dis.qidao123.com/)
Powered by Discuz! X3.4