通过对执行周期进行计数和分类,自上而下模型指出了应用程序当前的限定因素。英特尔公司最初形貌了这一模型[A Top-Down method for performance analysis and counters architecture],后来将其建立为英特尔TMAM方法。该模型的结构是一棵度量树,根据所花费的资源(如计算资源、内存资源、因停滞而丧失的资源等)对周期进行组织。对于英特尔 CPU 来说,每个层次结构都有一个官方定义。层次结构越深,微体系结构的特定性就越强。这大概会导致难以比较不同 CPU 之间的效果。
与英特尔 CPU 相比,AMD 没有官方定义的自顶向下模型。已往曾有人试图将英特尔的模型映射到 AMD 15h、Opteron 和 R 系列处理惩罚器上。由于微体系结构和可用硬件计数器的不同,这项工作凸显了映射的局限性。其他架构也有树状层次结构,但未标注为 “自上而下”。每个供应商都有本身的定义,大概与 TMAM 的定义不一致。
读者应注意,“自顶向下 ”模型始终以周期为单元进行定义。这意味着 CPU(和内存)时钟频率未被考虑在内。
我们利用以前使用名为 Alya的生产 CFD 代码的经验,探索自顶向下模型所能提供的洞察力。我们在英特尔原始模型的基础上,为 AMD Zen 2 CPU 定义了一个自顶向下模型,并实施了一个工作流程,以测量和计算所研究的每个体系的指标。我们还分析了模型在不同 CPU 架构中的适用性,以及模型层次结构是否具有可比性。
1.2. 贡献
在 AMD Zen 中定义自顶向下模型 2.
在英特尔 Skylake、AMD Zen 2、A64FX、Power9 和鲲鹏 920 CPU 中实现自顶向下模型。
应用自顶向下模型,研究不同 CPU 架构下生产型 HPC 代码中的代码修改效果。
在不同 CPU 架构的体系中比较自顶向下模型。
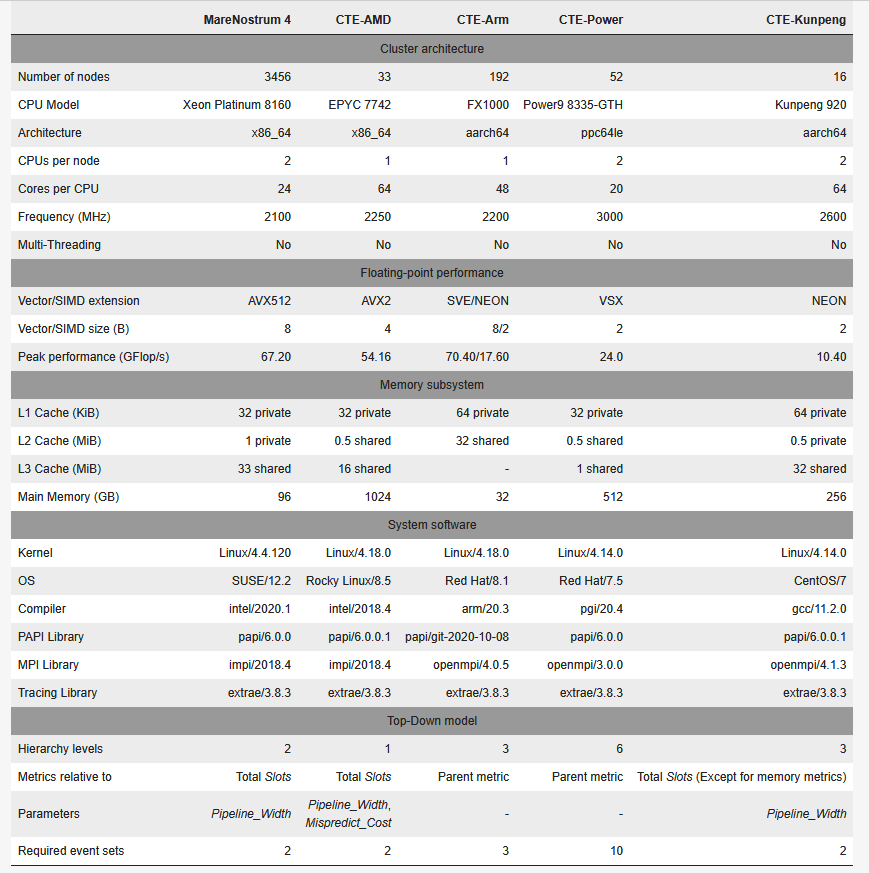
我们在五个不同的集群上使用了三种不同的架构:x86、aarch64 和 ppc64le。其中一个集群(基于英特尔 Skylake CPU 的集群)已经定义了自顶向下模型。对于其中两个集群,由于没有模型,因此我们必须定义自顶向下模型;(i) 对于 AMD Zen 2,我们基于上一代 CPU ;(ii) 对于 Kunpeng 920,我们利用了 CPU 制造商提供的模型(据我们所知到目前为止尚未公开)。对于集群 A64FX 和 Power9,有一些与自顶向下模型类似的模型定义,我们必须对其进行调整才能与之相比较。
2 高性能计算体系及其自顶向下模型