IT评测·应用市场-qidao123.com技术社区
标题:
(1-2)DeepSeek概述:DeepSeek的架构概览
[打印本页]
作者:
温锦文欧普厨电及净水器总代理
时间:
2025-2-23 21:09
标题:
(1-2)DeepSeek概述:DeepSeek的架构概览
1.2 DeepSeek的架构概览
DeepSeek模型是基于经典的Transformer模型架构的,并举行了深度优化。采用了混淆专家(Mixture-of-Experts, MoE)架构,通过稀疏激活提升模型效率。别的,DeepSeek引入了动态路由网络,智能地调配计算资源,以高效处理长文本和复杂逻辑任务。
1.2.1 DeepSeek的团体架构计划
DeepSeek的团体架构计划以高效处理长文本和提升推理效率为核心目的,主要包含如下所示的几个关键组成部分。
1. Multi-head Latent Attention (MLA)
低秩团结压缩:MLA通过将Key与Value分解为低秩矩阵并举行团结压缩,减少了必要存储和访问的数据量,从而降低了推理阶段的显存与时间开销。
显式位置编码融合:团结位置编码,使得模型可以或许在压缩后仍旧保存序列顺序信息。
并行化计算优化:对压缩后的Key-Value举行并行操纵,兼顾了留意力的机动性与推理速率的提升。
2. DeepSeekMoE 架构
专家混淆体系:DeepSeekMoE架构融合了专家混淆体系(MoE)、多头潜在留意力机制(MLA)和RMSNorm三个核心组件。通过专家共享机制、动态路由算法和潜在变量缓存技术,该模型在保持性能程度的同时,实现了相较传统MoE模型40%的计算开销降低。
动态路由机制:针对输入令牌嵌入,路由器通过门控网络从多个专家中选择最相关的专家。这种机制确保了计算的高效性和模型性能的稳定性。
无辅助损失的负载平衡计谋:DeepSeek-V3通过动态调整专家偏置,实现了负载平衡,制止了传统方法中因强制负载平衡而导致的模型性能下降。
3. 多Token预测训练目的(MTP)
同时预测多个Token:在训练过程中,模型不但预测下一个Token,还预测后续多个位置的Token。这种机制增长了训练信号密度,有助于模型学习长期依赖关系,提高天生质量。
4. 层级计谋优化
混淆专家体系(MoE):内置多个专家子网络,通过精细的门控机制按需激活,加强模型容量,同时保持计算成本可控。
分阶段训练:包括预训练阶段、对齐阶段和范畴微调阶段,确保模型在差别任务和范畴的体现。
5. 其他优化
FP8混淆精度:大幅加速训练速率,在支持硬件条件下可实现更高吞吐量。
多语言与多范畴数据:模型具备一定的跨语言能力,可在通用场景下保持较佳体现。
总之,DeepSeek的团体架构计划通过这些创新和优化,实现了在超大规模参数与现实推理效率之间的平衡,明显提升了模型的性能和应用代价。
1.2.2 DeepSeek的模块分别
DeepSeek 模型采用了多条理的模块化计划,以提升其性能和效率。
1.输入嵌入模块
功能:将输入文本转化为模型可处理的向量体现。
细节:通过词嵌入和位置嵌入的组合,为每个输入Token天生一个固定维度的向量体现。
2.Transformer模块
(1)多头潜在留意力机制(MLA)
功能:高效处理序列信息,降低计算和存储需求。
细节:通过低秩压缩技术,将Token的特性压缩到较小的潜在空间,再通过上投影矩阵恢复到Key、Value空间。
(2)专家混淆体系(MoE)
功能:通过多个专家子网络提高模型容量和计算效率。
细节:每个MoE层包含1个共享专家和256个路由专家,每个Token选择8个专家举行处理。
(3)RMSNorm归一化层
功能:稳定训练过程,加速模型收敛。
细节:在每个Transformer模块中使用RMSNorm归一化层,对输入数据举行归一化处理。
3.优化计谋模块
(1)多Token预测训练目的(MTP)
功能:增长训练信号密度,提高天生质量。
细节:在训练过程中,模型不但预测下一个Token,还预测后续多个位置的Token。
(2)负载平衡计谋
功能:确保专家负载平衡,提高模型性能。
细节:通过动态调整专家偏置项,实现负载平衡,无需额外的辅助损失函数。
4.输出层
功能:将Transformer模块的输出转化为终极的预测效果。
细节:通过一个线性层将Transformer的输出映射到词汇表巨细的维度,得到每个Token的预测概率分布。
5.其他辅助模块
(1)FP8混淆精度训练模块
功能:降低训练时的GPU内存占用和计算开销。
细节:通过精细的量化计谋和高精度累加,实现FP8混淆精度训练。
(2)残差流分形解码架构
功能:提高推理效率。
细节:通过主次双Token预测和动态损失融合,提升单次前向传播的学习效率。
1.2.3 DeepSeek与其他模型的技术对比
DeepSeek 模型在人工智能范畴引起了广泛关注,其性能和特点与其他大型语言模型(LLM)相比,展现出独特的上风和差别。
1. 与GPT系列对比
技术架构:DeepSeek采用混淆架构,团结了深度学习与强化学习技术,注重高效性和机动性,支持快速迭代和定制化开发;GPT系列基于Transformer架构,以其强盛的语言天生能力和上下文理解能力著称。
性能体现:DeepSeek在语言天生任务中体现出色,尤其在中文语境下的体现优于GPT系列,天生的文本更加符合中文表达风俗,且在多轮对话中可以或许保持较高的连贯性;GPT-4在英文任务中体现优异,但在处理中文时偶尔会出现语义偏差或文化背景理解不敷的问题。
计算效率与资源斲丧:DeepSeek在计算效率上体现优异,其模型计划优化了资源斲丧,适合在资源有限的环境中部署;GPT-4和Gemini由于模型规模较大,对计算资源的需求较高,部署成本较高。
应用场景:DeepSeek实用于多种场景,包括智能客服、内容创作、教诲辅助和数据分析等,其高效性和机动性使其在企业级应用中具有较大上风;GPT系列在内容创作、代码天生和学术研究等范畴体现优异,但其高昂的部署成本限制了其在中小企业中的应用。
2. 与Claude对比
技术架构:DeepSeek采用混淆架构,注重高效性和机动性;Claude以“对齐性”为核心计划理念,注重模型的道德和安全性能。
性能体现:DeepSeek在语言天生任务中体现出色,尤其在中文语境下的体现优于Claude;Claude在天生内容的安全性上体现优异,但在复杂语言任务上的机动性和创造力稍显不敷。
计算效率与资源斲丧:DeepSeek在计算效率上体现优异,适合在资源有限的环境中部署;Claude在计算效率上体现较好,但其天生速率略慢于DeepSeek。
应用场景:DeepSeek实用于多种场景,包括智能客服、内容创作、教诲辅助和数据分析等;Claude在必要高安全性和道德标准的场景(如法律咨询、医疗辅助)中体现优异,但其应用范围相对较窄。
3. 与Gemini对比
技术架构:DeepSeek采用混淆架构,注重高效性和机动性;Gemini是多模态AI模型,可以或许同时处理文本、图像和音频等多种数据类型,其架构计划注重多模态融合。
性能体现:DeepSeek在语言天生任务中体现出色,尤其在中文语境下的体现优于Gemini;Gemini在多模态任务中体现突出,但在纯文本天生任务上略逊一筹。
计算效率与资源斲丧:DeepSeek在计算效率上体现优异,适合在资源有限的环境中部署;Gemini由于模型规模较大,对计算资源的需求较高,部署成本较高。
应用场景:DeepSeek实用于多种场景,包括智能客服、内容创作、教诲辅助和数据分析等;Gemini在多模态任务(如图像形貌、视频分析)中体现突出,适合用于多媒体内容天生和分析。
4. 与Switch Transformer对比
参数效率:在设置64个专家(其中8个共享)的环境下,DeepSeekMoE较Switch Transformer(64个专家)实现了1.8倍的吞吐量提升,同时参数量降低30%。
训练效率:相比参数规模相当(13B)的密集Transformer,DeepSeekMoE训练速率提升2.1倍。
推理性能:MLA缓存机制使自回归任务的延迟降低35%。
模型性能:在WikiText-103测试集上,DeepSeekMoE的困惑度达到12.3,优于Switch Transformer的14.1;在WMT'14 EN-DE测试集上,DeepSeekMoE的BLEU得分达44.7,较Transformer++提升2.1分。
5. 与Llama对比
训练成本:DeepSeek-V3的训练费用相比GPT-4等大模型要少得多,据外媒估计,Meta的大模型Llama-3.1的训练投资凌驾了5亿美元。
性能体现:DeepSeek-V3在多项评测中体现优异,甚至直逼天下顶尖的闭源模型GPT-4o和Claude-3.5-Sonnet。
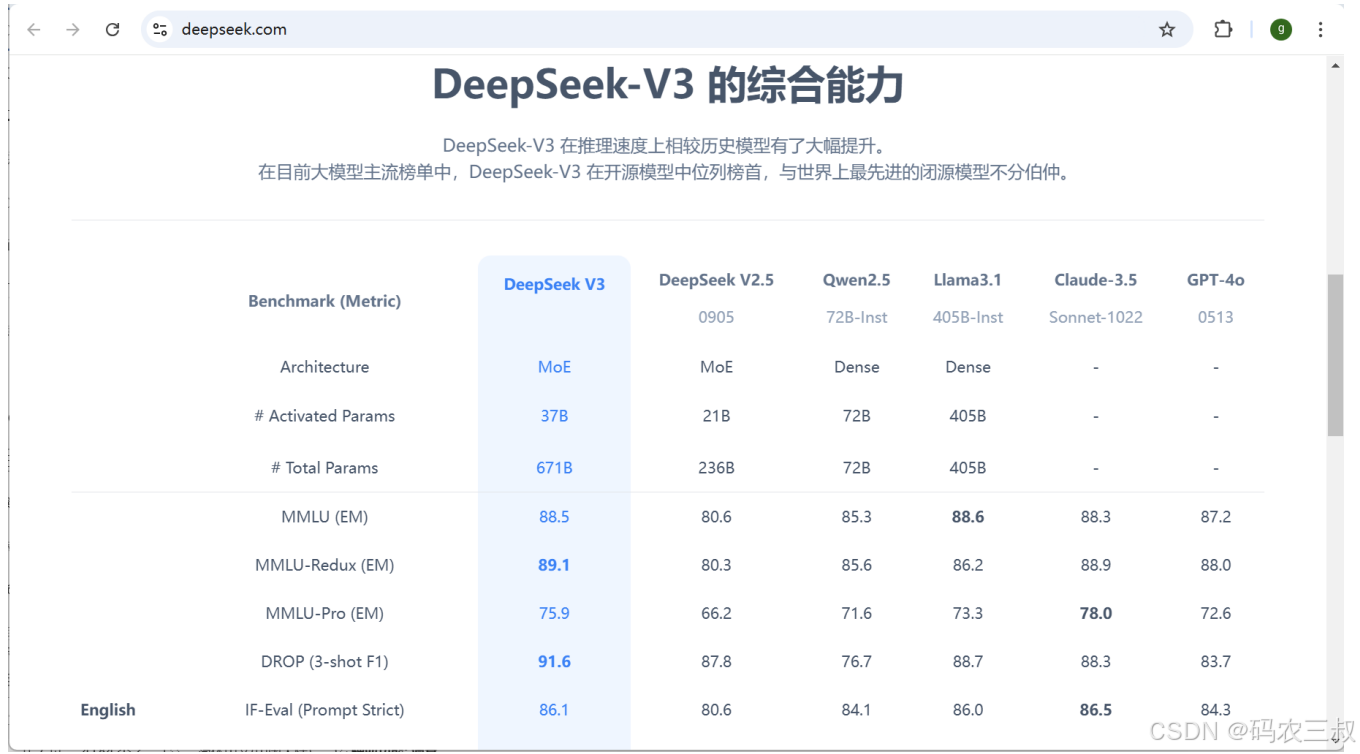
总体而言,DeepSeek 模型在性能、成本效益、开源计谋、技术架构和应用范畴等方面,与其他大型语言模型相比,展现出独特的上风和差别。在DeepSeek官网展示了与其他大模型的对比数据,如图2-1所示。
图2-1 DeepSeek与其他大模型的对比数据
根据图2-1中的对比数据,可以总结出以下对比信息。
1. 综合性能与推理能力
推理速率和效率提升明显:DeepSeek-V3 相较于汗青模型(如 DeepSeek-V2.5、Qwen2.5 和 Llama3.1)在推理速率上有大幅提升,这体现在 DROP、IF-Eval、LiveCodeBench 等多项指标上,其 3-shot F1 分数、Prompt Strict 模式下的体现以及代码天生任务均领先于其他开源模型。
综合能力出众:在 MMLU(包括标准版、Redux 及 Pro 版本)的英语评测中,DeepSeek-V3 的体现处于高程度,甚至与部分闭源模型(如 Claude-3.5 和 GPT-4o)相当。中文评测(CLUEWSC、C-Eval 和 C-SimpleQA)上,DeepSeek-V3 同样取得了最高分数,体现出其跨语言综合能力的平衡性。
2. 参数架构与效率
MoE 架构上风:DeepSeek-V3 采用混淆专家(MoE)架构,使得其在总参数量(671B)远高于某些密集模型(如 Qwen2.5 的 72B、Llama3.1 的 405B)的同时,通过仅激活部分参数(37B)实现高效计算。这种计划不但提升了模型容量,也保证了推理时的高效能。
3. 代码(Code)与数学(Math)能力
代码天生任务:在 HumanEval-Mul、LiveCodeBench 以及 Codeforces 等代码任务上,DeepSeek-V3 均体现优于同类开源模型,体现出其在复杂编程和逻辑推理任务上的能力。
数学题解能力: 表中 AIME 2024、MATH-500 和 CNMO 2024 等数学评测数据表明,DeepSeek-V3 在数学推理和问题解决上有明显上风,其 Pass@1 及 EM 分数均高于其他模型,体现了更强的逻辑和数学处理能力。
4. 与闭源模型的对比:与闭源模型半斤八两
虽然部分指标如 GPQA-Diamond 和 SimpleQA 上,闭源模型(如 Claude-3.5 和 GPT-4o)仍有一定上风,但团体来看,DeepSeek-V3 在大多数评测中都处于领先地位或与顶尖闭源模型不相上下,成为开源模型中的佼佼者。
5. 对比结论
DeepSeek-V3在多个范畴和任务中体现出色,尤其是在English、Code和Math等范畴的任务中,其体现与天下上开始进的闭源模型不分伯仲。
DeepSeek-V3在开源模型中位列榜首,体现出其在综合能力上的强盛竞争力。
DeepSeek-V3在多个指标上体现优异,体现出其在技术架构和训练方法上的优化效果。
综上所述,DeepSeek-V3 在推理速率、综合语言理解、代码天生以及数学推理等多个维度上均展现出明显的上风。其采用的 MoE 架构和高效的参数激活机制使其在保持大规模模型容量的同时,实现了高效计算和优异体现,已成为目前大模型主流榜单中开源模型的领跑者,并与天下上开始进的闭源模型比肩。
免责声明:如果侵犯了您的权益,请联系站长,我们会及时删除侵权内容,谢谢合作!更多信息从访问主页:qidao123.com:ToB企服之家,中国第一个企服评测及商务社交产业平台。
欢迎光临 IT评测·应用市场-qidao123.com技术社区 (https://dis.qidao123.com/)
Powered by Discuz! X3.4