ToB企服应用市场:ToB评测及商务社交产业平台
标题:
浅谈:向量数据库、向量搜索库和向量搜索插件
[打印本页]
作者:
慢吞云雾缓吐愁
时间:
8 小时前
标题:
浅谈:向量数据库、向量搜索库和向量搜索插件
自从ChatGPT和那些大型语言模子(LLMs)火起来之后,向量搜索技术也跟着火了一把。现在有了像Milvus这样的专业向量数据库,还有FAISS(Facebook AI Similarity Search)这样的库,以及那些可以在传统数据库里集成的向量搜索插件。
咱们这篇文章就是要深挖一下向量数据库到底是啥,还要聊聊向量搜索的复杂性,比较一下向量数据库、向量搜索插件和向量搜索库有啥差别。
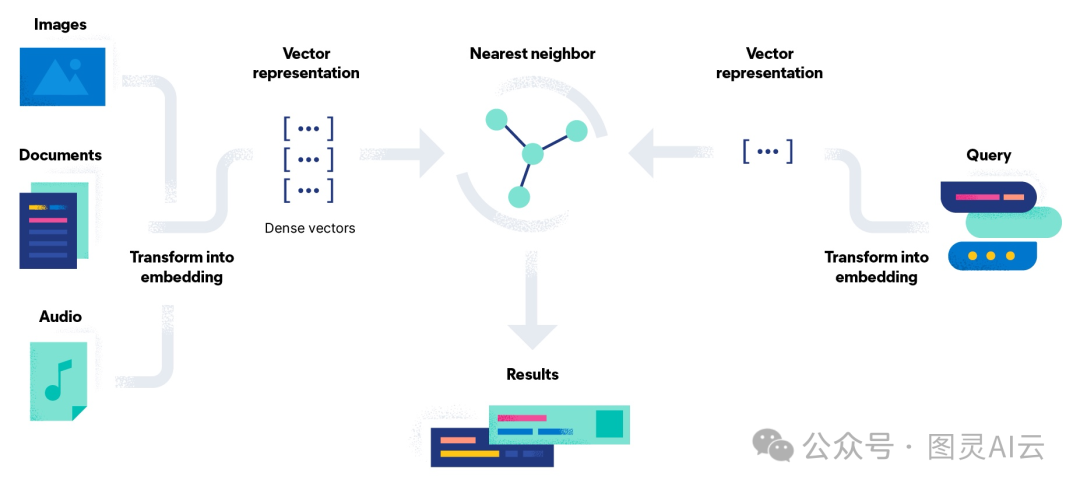
向量搜索,大概说向量相似性搜索,就是那种能在一大堆麋集向量数据里头找出和给定查询向量最相似的那几个结果的技术。在开始搜索之前,我们得用神经网络把那些非结构化的数据,比如文本、图像、视频和音频,转换成高维数值向量,也就是嵌入向量(embedding vectors)。一旦有了这些嵌入向量,向量搜索引擎就会计算它们和查询向量之间的空间距离,距离越小,相似度就越高。
现在市面上有好多向量搜索技术,不光有Python的NumPy这种机器学习库,还有FAISS这样的向量搜索库,还有基于传统数据库构建的向量搜索插件,以及Milvus这样的专业向量数据库。
不过,专业向量数据库可不是做相似性搜索的唯一选择。在向量数据库出现之前,像FAISS、ScaNN(Scalable Nearest Neighbors)和HNSW(Hierarchical Navigable Small Worlds)这样的向量搜索库就已经被广泛用于向量检索了。
这些向量搜索库能帮我们快速搭建起一个高性能的原型向量搜索系统。就拿FAISS来说,它是Meta开发的开源库,专门用来做高效的相似性搜索和麋集向量聚类。FAISS能处置惩罚任何大小的向量聚集,哪怕是那些大到不能完全装进内存里的聚集。而且,FAISS还提供了评估和参数调解的工具。虽然FAISS是用C++写的,但它提供了Python/NumPy接口。
但是,这些向量搜索库只是轻量级的近似近来邻(Approximate Nearest Neighbor,ANN)库,不是那种全托管的解决方案,功能上还是有点限制。对于小规模且有限的数据集,这些库可能充足用了,哪怕是在生产环境中。不过,一旦数据集变大,用户变多,处置惩罚规模问题就变得越来越棘手。而且,它们不答应对索引数据进行任何修改,也不能在数据导入的时间进行查询。
相比之下,向量数据库就是处置惩罚非结构化数据存储和检索的更优解决方案。它们能存储和查询数百万甚至数十亿个向量,同时还能提供实时响应;它们非常灵活,能够适应用户不断增长的业务需求。
而且,像Milvus这样的向量数据库对于结构化/半结构化数据还有很多用户友好的特性,比如云原生、多租户、可扩展性等等。
向量数据库和向量搜索库在运作的抽象层次上是完全差别的——向量数据库是完整的服务,而ANN库则必要集成到你正在开发的应用程序中。在这个意义上,ANN库只是构建向量数据库的浩繁组件之一,就像Elasticsearch是建立在Apache Lucene之上的那样。
当我们评论把一些新的非结构化数据加到向量数据库里,Milvus这个工具简直太方便了。你看,就这么几行代码:
from pymilvus import Collection
collection = Collection('book')
mr = collection.insert(data)
复制代码
三行代码,搞定!但是,假如你用的是FAISS大概ScaNN这些库,就没这么简单了。你得在关键时间手动重新建整个索引,这可麻烦多了。就算能做到,这些库在可扩展性和支持多用户方面还是不够给力,这可是向量数据库的两大杀手锏啊。
现在咱们已经搞清楚了向量搜索库和向量数据库的差别,再来看看向量数据库和向量搜索插件有啥区别。
你看,现在很多传统的关系数据库和搜索系统,比如Clickhouse和Elasticsearch,都开始内置向量搜索插件了。就拿Elasticsearch 8.0来说吧,它可以通过RESTful API端点来插入向量和做ANN搜索。但是,这些向量搜索插件的局限性还是挺明显的——它们没有全面管理嵌入和向量搜索的方法。它们更像是给现有架构打补丁,功能有限,也没那么优化。在传统数据库上搞非结构化数据应用,就像你非要在燃油车里装锂电池和电动机,这事儿听着就不对路!
为啥这么说呢?因为这些向量搜索插件缺少两个关键的东西——可调性和好用的API/SDK。我还是拿Elasticsearch的ANN引擎来举例子吧,其他的插件也差不多,我就不多说了。Elasticsearch支持通过dense_vector这种数据字段范例来存储向量,还能通过knnsearch端点来查询:
PUT index
{
"mappings": {
"properties": {
"image-vector": {
"type": "dense_vector",
"dims": 128,
"index": true,
"similarity": "l2_norm"
}
}
}
}
PUT index/_doc
{
"image-vector": [0.12, 1.34, ...]
}
复制代码
GET index/_knn_search
{
"knn": {
"field": "image-vector",
"query_vector": [-0.5, 9.4, ...],
"k": 10,
"num_candidates": 100
}
}
复制代码
Elasticsearch的ANN插件,它只能用一种索引算法,就是Hierarchical Navigable Small Worlds,简称HNSW。而且,它只用L2/欧几里得距离,来权衡向量之间的相似度。这虽然是个不错的开始,但是跟Milvus这种完整的向量数据库比起来,还是差了点意思。用pymilvus来操作Milvus,看起来是这样的:
>>> field1 = FieldSchema(name='id', dtype=DataType.INT64, description='int64', is_primary=True)
>>> field2 = FieldSchema(name='embedding', dtype=DataType.FLOAT_VECTOR, description='embedding', dim=128, is_primary=False)
>>> schema = CollectionSchema(fields=[field1, field2], description='hello world collection')
>>> collection = Collection(name='my_collection', data=None, schema=schema)
>>> index_params = {
'index_type': 'IVF_FLAT',
'params': {'nlist': 1024},
"metric_type": 'L2'}
>>> collection.create_index('embedding', index_params)
复制代码
>>> search_param = {
'data': vector,
'anns_field': 'embedding',
'param': {'metric_type': 'L2', 'params': {'nprobe': 16}},
'limit': 10,
'expr': 'id_field > 0'
}
>>> results = collection.search(**search_param)
复制代码
你看《Milvus vs. Elastic》,虽然Elasticsearch和Milvus都能创建索引、插入向量和做近来邻搜索,但Milvus的API更直观,支持的索引和距离度量方式也更多,可调性更好。Milvus以后还会支持更多范例的向量索引,甚至可以用雷同SQL的语句来查询,这让它的可调性和易用性更上一层楼。
简单来说,Milvus比那些向量搜索插件强多了,因为它本来就是为了做向量数据库而设计的,功能更丰富,架构也更适合处置惩罚非结构化数据。
也不是说所有的向量数据库都一样,每个都有它独特的地方,适合差别的场景。对于那些只必要处置惩罚几百万向量的小规模生产环境,向量搜索库和插件还是挺友好的,假如你的数据量不大,只必要根本的向量搜索功能,这些技术就够用了。
但是,假如你的业务必要处置惩罚上亿的向量,还得要求实时响应,那专业的向量数据库,比如Milvus,就是我们的首选了。
免责声明:如果侵犯了您的权益,请联系站长,我们会及时删除侵权内容,谢谢合作!更多信息从访问主页:qidao123.com:ToB企服之家,中国第一个企服评测及商务社交产业平台。
欢迎光临 ToB企服应用市场:ToB评测及商务社交产业平台 (https://dis.qidao123.com/)
Powered by Discuz! X3.4