qidao123.com技术社区-IT企服评测·应用市场
标题:
『Python底层原理』--Python字典的实现机制
[打印本页]
作者:
去皮卡多
时间:
2025-3-3 08:40
标题:
『Python底层原理』--Python字典的实现机制
在Python中,
字典
(dict)是一种极为强大且常用的内置数据结构,它以键值对的情势存储数据,并提供了高效的查找、插入和删除操作。
接下来,我们将深入探究 Python 字典背后的实现机制,特别是其与哈希表的关系,以及在 CPython 中的详细实现。
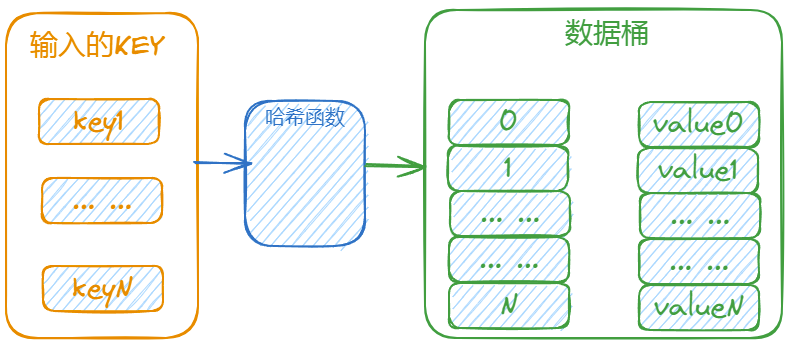
1. 哈希表
字典
用于存储 Python 中的键值对,为我们提供了快速访问和存储数据的方法。
哈希表
(Hash Table)则是实现字典功能的核心技能之一。
本质上,
哈希表
是基于
哈希函数
的数据结构,通过将键映射到特定索引位置,实现快速数据访问。
Python 字典正是利用
哈希表
这一特性,把键值对存储在哈希表中,让我们能通过键迅速获取对应的值。
2. 实现原理
在Python中,字典通过哈希表实现其功能。
详细来说,字典的键被传递给一个哈希函数,该函数盘算出一个哈希值。
然后,这个哈希值被用来确定键值对在内存中的存储位置。
当需要查找某个键对应的值时,字典会再次盘算该键的哈希值,并直接定位到存储位置,从而快速返回对应的值。
2.1. 存储方式
Python字典的存储方式基于一个
动态数组
,其中每个元素是一个键值对的引用。
这个数组的大小会根据字典的
负载因
子(Load Factor)动态调整。
负载因子
是字典中存储的键值对数目与哈希表大小的比值,当
负载因子
超过一定阈值(如0.66)时,哈希表会扩容,以制止过多的哈希辩论,从而保持高效的查找性能。
2.2. 哈希辩论
哈希辩论
是哈希表中不可制止的问题。
在Python字典中,哈希辩论通过
“开放寻址法”
解决。
当两个键的哈希值映射到同一个存储位置时,字典会寻找下一个空闲的位置来存储辩论的键值对。
这种方法称为
“线性探测”
,如果连续的位置都被占用,字典会继续寻找,直到找到一个空闲位置。
这种策略虽然简朴,但在某些情况下可能会导致性能下降,尤其是在哈希表靠近满载时。
2.3. 字典性能
字典的性能主要取决于
哈希函数
的质量和哈希表的
负载因子
。
在理想情况下,字典的查找、插入和删除操作的匀称时间复杂度为O(1)。
然而,在最坏情况下(如大量哈希辩论),时间复杂度可能会退化到O(n)。
为了制止这种情况,Python字典会动态调整哈希表的大小,以保持较低的负载因子。
3. CPython中的字典实现
在CPython的源代码中,字典的实现位于Objects/dictobject.c文件中。
这个文件包含了字典的所有核心操作,如初始化、查找、插入和删除等。
好比字典创建的代码:
static PyObject *
dict_new(PyTypeObject *type, PyObject *args, PyObject *kwds)
{
assert(type != NULL);
assert(type->tp_alloc != NULL);
// dict subclasses must implement the GC protocol
assert(_PyType_IS_GC(type));
PyObject *self = type->tp_alloc(type, 0);
if (self == NULL) {
return NULL;
}
PyDictObject *d = (PyDictObject *)self;
d->ma_used = 0;
d->_ma_watcher_tag = 0;
dictkeys_incref(Py_EMPTY_KEYS);
d->ma_keys = Py_EMPTY_KEYS;
d->ma_values = NULL;
ASSERT_CONSISTENT(d);
if (!_PyObject_GC_IS_TRACKED(d)) {
_PyObject_GC_TRACK(d);
}
return self;
}
复制代码
字典对象由PyDictObject结构体定义(Include/cpython/dictobject.h):
typedef struct {
PyObject_HEAD
// 省略...
PyDictKeysObject *ma_keys;
/* If ma_values is NULL, the table is "combined": keys and values
are stored in ma_keys.
If ma_values is not NULL, the table is split:
keys are stored in ma_keys and values are stored in ma_values */
PyDictValues *ma_values;
} PyDictObject;
复制代码
其中,PyDictKeysObject是一个存储键值对的数组。
// 位于文件:Include/cpython/dictobject.h
typedef struct _dictkeysobject PyDictKeysObject;
// 位于文件:Include/internal/pycore_dict.h
struct _dictkeysobject {
Py_ssize_t dk_refcnt;
// 省略...
};
复制代码
在CPython中,字典的实现接纳了
紧凑的内存布局
,以淘汰内存浪费。
每个键值对都被存储在一个结构体中,而这些结构体则被存储在一个动态数组中。
当需要
扩容
时,字典会重新分配一个更大的数组,并将所有键值对重新哈希到新的数组中。
这种实现方式虽然在扩容时会带来一定的性能开销,但通过合理的
负载因子
控制,可以有用制止频繁的扩容操作。
4. 字典的应用场景
Python字典作为一种高效的数据结构,在实际开发中有着广泛的应用。
下面列举一些从实际项目中摘取的一些利用字典的代码片段。
4.1. 存储配置信息
字典是存储配置信息的理想选择,由于它允许通过键快速访问对应的值。
好比,在一个Web应用程序中,我们经常利用字典来存储数据库配置、API密钥或其他运行时参数:
config = {
"database": {
"host": "localhost",
"port": 3306,
"user": "root",
"password": "password"
},
"api_keys": {
"google_maps": "YOUR_GOOGLE_MAPS_API_KEY",
"weather": "YOUR_WEATHER_API_KEY"
}
}
# 访问配置
db_host = config["database"]["host"]
api_key = config["api_keys"]["google_maps"]
复制代码
这种方式不仅清楚易懂,还便于后续的修改和扩展。
4.2. 缓存数据
字典的高效查找特性使其非常得当用作缓存机制。通过将盘算结果存储在字典中,可以制止重复盘算,从而显著进步程序的性能。
例如,以下代码展示了如何利用字典缓存斐波那契数列的盘算结果:
[code]cache = {}def fibonacci(n): if n in cache: return cache[n] if n
欢迎光临 qidao123.com技术社区-IT企服评测·应用市场 (https://dis.qidao123.com/)
Powered by Discuz! X3.4