IT评测·应用市场-qidao123.com
标题:
广告行业中那些趣事系列84:基于LLaMA Factory做一个AI版听泉鉴宝
[打印本页]
作者:
徐锦洪
时间:
2025-3-7 22:40
标题:
广告行业中那些趣事系列84:基于LLaMA Factory做一个AI版听泉鉴宝
导读:本文是“数据拾光者”专栏的第八十四篇文章,这个系列将先容在广告行业中天然语言处理和推荐体系实践。本文重要调研LLaMA Factory框架以及如何利用该框架来构建一个AI版听泉鉴宝。
欢迎转载,转载请注明出处以及链接,更多关于天然语言处理、推荐体系优质内容请关注如下频道。
知乎专栏:数据拾光者
公众号:数据拾光者
01 背景先容
前一段时间有个叫"听泉鉴宝"(现在叫"听泉赏宝")的火起来了,半年多涨粉2000万。现在粉丝凌驾3100万,网友点评段子:“直播间十万人,三万盗墓的,三万便衣警察,三万同行,剩下一万是观众。”这个主播用搞笑、浮夸和隐晦的方式帮大家鉴宝,风格独特,轻松娱乐的同时还能学点赏宝知识,照旧挺好玩的。下面是大V听泉赏宝的抖V:
那么问题来了,自从以Chatgpt为代表的大模型火了之后,我们能不能用大模型来做一个AI版的"听泉鉴宝"呢?答案是肯定的。可以考虑使用Qwen2-VL多模态学习模型微调一下,我们就有可能做一个AI版"听泉鉴宝"。微调框架可以考虑用当前很火的LLaMA Factory,简单,易用,甚至可以做到零代码微调大模型。
02 LLaMA Factory先容
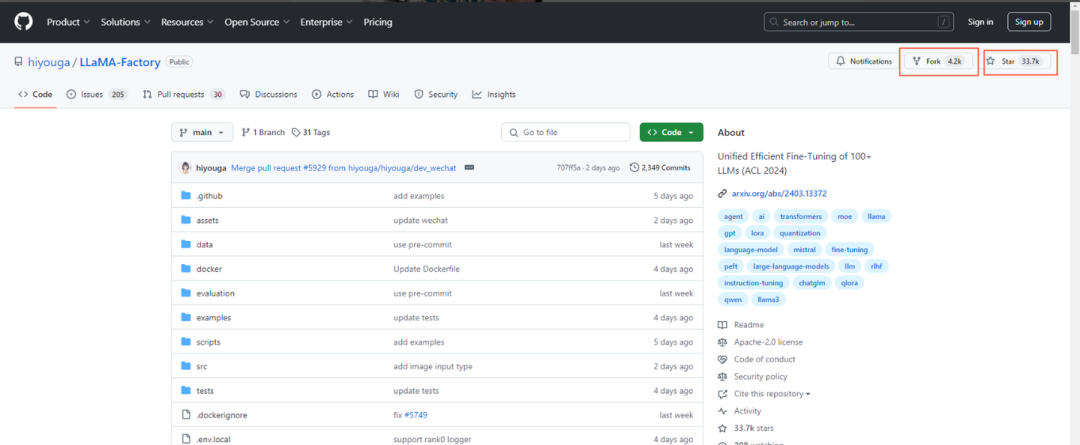
LLaMA Factory是一个开源低代码用来微调大模型的框架,集成了当前业界广泛使用的微调技能。我们甚至可以通过Web UI界面实现零代码微调大模型。现在github项目有4.2K的fork和33.7K的star(停止20241107),名副其实的明星项目。LLaMA Factory的github地址如下:
https://github.com/hiyouga/LLaMA-Factory
项目特色显着,支持多种模型,同时集成多种方法等,可谓功能齐备,简单好用。下面是引用官网的项目特色先容:
多种模型:LLaMA、LLaVA、Mistral、Mixtral-MoE、Qwen、Qwen2-VL、Yi、Gemma、Baichuan、ChatGLM、Phi 等等。
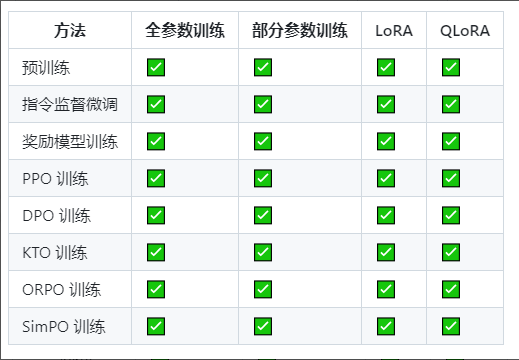
集成方法:(增量)预训练、(多模态)指令监督微调、奖励模型训练、PPO 训练、DPO 训练、KTO 训练、ORPO 训练等等。
多种精度:16 比特全参数微调、冻结微调、LoRA 微调和基于 AQLM/AWQ/GPTQ/LLM.int8/HQQ/EETQ 的 2/3/4/5/6/8 比特 QLoRA 微调。
先进算法:GaLore、BAdam、Adam-mini、DoRA、LongLoRA、LLaMA Pro、Mixture-of-Depths、LoRA+、LoftQ、PiSSA 和 Agent 微调。
实用技巧:FlashAttention-2、Unsloth、Liger Kernel、RoPE scaling、NEFTune 和 rsLoRA。
实行监控:LlamaBoard、TensorBoard、Wandb、MLflow 等等。
极速推理:基于 vLLM 的 OpenAI 风格 API、欣赏器界面和下令行接口。
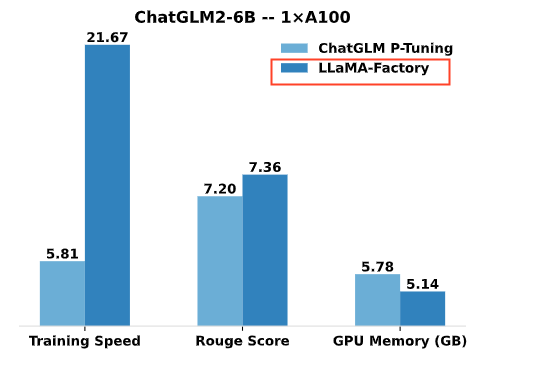
性能方面也不错,与 ChatGLM 官方的 P-Tuning 微调相比,LLaMA Factory 的 LoRA 微调提供了 3.7 倍的加快比,同时在广告文案天生任务上取得了更高的 Rouge 分数。结合 4 比特量化技能,LLaMA Factory 的 QLoRA 微调进一步降低了 GPU 显存消耗。
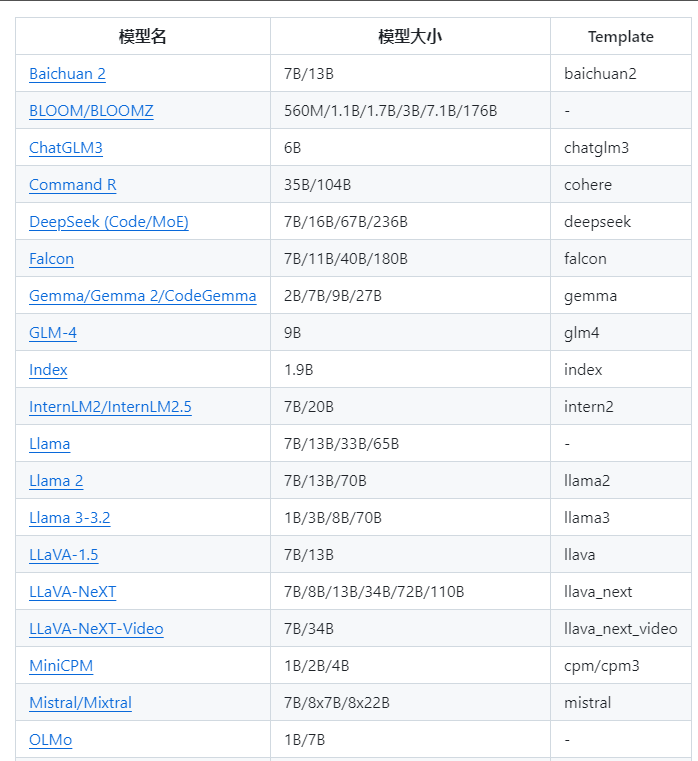
支持很多大语言模型,下面是部分截图:
训练方法也很全面:
安装LLaMA Factory指令:
cd /home/notebook/data/Fine-tune/
# 下载项目和解压
!git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
cd /home/notebook/data/Fine-tune/LLaMA-Factory
# 激活虚拟环境 必须设置,否则报错
conda activate llama_factory
# 安装依赖
pip install -r requirements.txt
复制代码
启动 LLaMA Factory 的 WebUI 页面来微调,执行下令如下:
CUDA_VISIBLE_DEVICES=0 python src/train_web.py
复制代码
输入上面启动web页面之后假如出现如下页面则启动乐成:
在欣赏器输入如下url即可使用UI界面微调LLM。
LLaMA Board页面url:https://f6e72ebb5113af707a.gradio.live/
03 使用LLaMA Factory实现文旅模型示例
3.1 使用的数据集及示例
使用如下下令下载多轮对话数据集:
!wget https://atp-modelzoo-sh.oss-cn-shanghai.aliyuncs.com/release/llama_factory/Qwen2-VL-History.zip
复制代码
数据集中有261条样本,每条样本由一条体系提示、用户指令和模型答复组成。通过微调多模态学习模型Qwen2-VL不停学习样本中的答复风格,从而达到学习文旅知识的目的。数据示比方下:
基于LLaMA Factory微调一个Qwen2-VL 多模态学习模型,收集听泉鉴宝相关的古玩图片数据以及对应的文本数据拿来微调,就可以实现一个AI版本的听泉鉴宝了。
3.2 模型微调相关设置设置
3.2.1 模型选择以及微调方法
模型选择以及微调方法设置如下:
这里使用的是Qwen2VL-2B-Chat模型,微调方法是full。
微调方式重要有以下三种,可以根据必要进行选择:
full:将整个模型都进行微调。
freeze:将模型的大部分参数冻结,只对部分参数进行微调。
lora:将模型的部分参数冻结,只对部分参数进行微调,但只在特定的层上进行微调。
对于特别大的模型一般使用lora方式,只微调部分参数,在特定层上进行微调。假如模型比较小,可以选择full方式。
3.2.2 设置数据集和训练方式
设置数据集和训练方式如下:
训练方式有如下几种:
预训练Pre-Training:模型在大型数据集上进行预训练,以学习基本的语义和概念。
有监督微调Supervised Fine-Tuning:模型在标记数据集上进行微调,以进步特定任务的精确性。
奖励建模Reward Modeling:模型学习如何从环境中获得奖励,以做出更好的未来决议。
PPO训练:使用策略梯度方法训练模型,以进步环境中的性能。
DPO训练:该模型使用深度强化学习方法进行训练,以进步在环境中的性能。
3.2.3 设置学习率
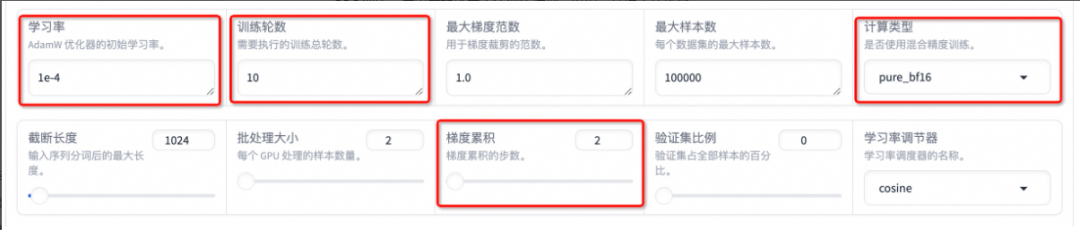
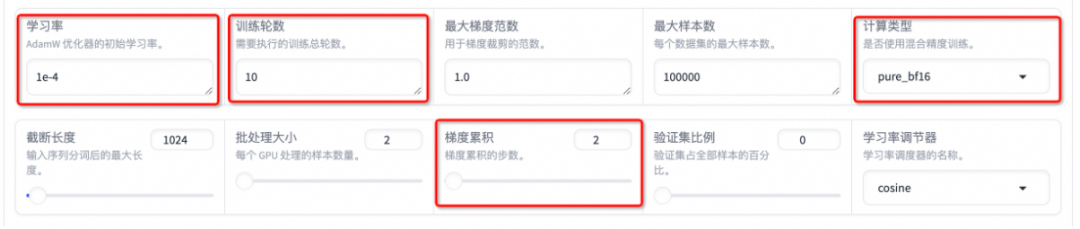
设置学习率为 1e-4,训练轮数为 10,更改计算范例为 pure_bf16,梯度累积为 2,有利于模型拟合。
关于学习率这块,AdamW优化器中的学习率(learning rate)是指控制模型参数更新步长的超参数。学习率决定了在每次参数更新时权重应该调整的幅度,从而影响模型在训练过程中的收敛速度和最终性能。在AdamW优化器中,学习率是一个重要的超参数,通常初始化为一个较小的值,它可以随着训练的进行而动态调整。选择符合的学习率有助于制止模型陷入局部最优解或发散,同时还可以进步模型的泛化能力。调整学习率的过程通常会在训练过程中进行,可能会使用学习率衰减策略(比方指数衰减、余弦退火等)来渐渐减小学习率,以便模型更好地探索损失函数的空间并获得更好的收敛性能。下面是几种常用的学习率选择:
5e-5:这个学习率得当于相对较大的数据集或复杂的模型,由于较大的学习率可以更快地收敛,尤其是当训练数据为大规模数据集时。
1e-6:较小的学习率适用于数据集较小或相对简单的模型,可以资助模型更稳固地学习数据的模式,制止过分拟合。
1e-3:适用于快速收敛,通常用于较大的深度神经网络和大型数据集。
1e−4:适用于中等巨细的数据集和相对简单的模型。
5e−4:类似于1e-3和1e-4之间的学习率,适用于中等巨细的网络和数据集。
1e−5:适用于相对小型的数据集或简单的模型,有助于制止快速过拟合。
1e−7:适用于非常小的数据集或非常简单的模型,有助于更细致地调整参数。
3.2.4 最大梯度范数
关于最大梯度范数,最大梯度范数用于对梯度进行裁剪,限制梯度的巨细,以防止梯度爆炸(梯度过大)的问题。选择符合的最大梯度范数取决于您的模型、数据集以及训练过程中碰到的情况。一般来说,常见的最大梯度范数取值在1到5之间,但具体取值要根据您的模型结构和训练数据的情况进行调整。以下是一些常见的最大梯度范数取值建议:
1到5之间:这是一般情况下常见的范围。假如您的模型较深或者碰到梯度爆炸的情况,可以考虑选择较小的范围。
1:通常用于对梯度进行相对较小的裁剪,以制止梯度更新过大,特别适用于训练稳固性较差的模型。
3到5:用于对梯度进行中等程度的裁剪,适用于一般深度学习模型的训练。
更大值:对于某些情况,比方对抗训练(Adversarial Training),可能必要更大的最大梯度范数来维持梯度的稳固性。
选择最大梯度范数时,建议根据实际情况进行试验和调整,在训练过程中观察模型的体现并根据必要进行调整。但通常情况下,一个合理的初始范围在1到5之间可以作为起点进行尝试。
3.2.5 设置计算范例
关于计算范例的选择:
FP16 (Half Precision):FP16是指使用16位浮点数进行计算,也称为半精度计算。在FP16精度下,模型参数和梯度都以16位浮点数进行存储和计算。
BF16 (BFloat16):BF16是指使用十六位Brain Floating Point格式,与FP16不同之处在于BF16在指数部分有8位(与FP32相同),而FP16只有5位。BF16通常用于呆板学习任务中,尤其是在加快器中更为常见。
FP32 (Single Precision):FP32是指使用32位浮点数进行计算,也称为单精度计算。在FP32精度下,模型参数和梯度以32位浮点数进行存储和计算,是最常见的精度。
Pure BF16:这是指纯粹使用BF16进行计算的模式。
在深度学习训练中,使用更低精度(比方FP16或BF16)可以降低模型的内存和计算需求,加快训练速度,尤其对于大规模模型和大数据集是有益的。然而,较低精度也可能带来数值稳固性问题,特别是在训练过程中必要小心处理梯度的表达范围,制止梯度消散或爆炸的问题。
3.2.6 设置学习率调治器
学习率调治器重要有以下几种:
Linear:线性衰减学习率,即学习率随着训练步数线性减小。
Cosine:余弦退火学习率,学习率按照余弦函数的曲线进行调整,渐渐降低而非直接线性减小。
Cosine with restarts:带重启的余弦退火,学习率的衰减出现周期性变化,适用于训练过程中渐渐放宽约束然后再次加快训练的情况。
Polynomial:多项式衰减学习率,通过多项式函数来调整学习率,可以是二次、三次等。
Constant:固定学习率,不随训练步数变化而保持稳固。
Constant with warmup:具有热身阶段的固定学习率,初始阶段固定学习率较大,随后在训练一段时间后降低。
Inverse Square Root:学习率按照步数的倒数的平方根进行衰减,可以平滑地调整学习率。
Reduce Learning Rate on Plateau:当验证集上的损失不再淘汰时,减小学习率,以更细致地优化模型性能。
在其他参数设置区域修改保存间隔为 1000,节省硬盘空间。
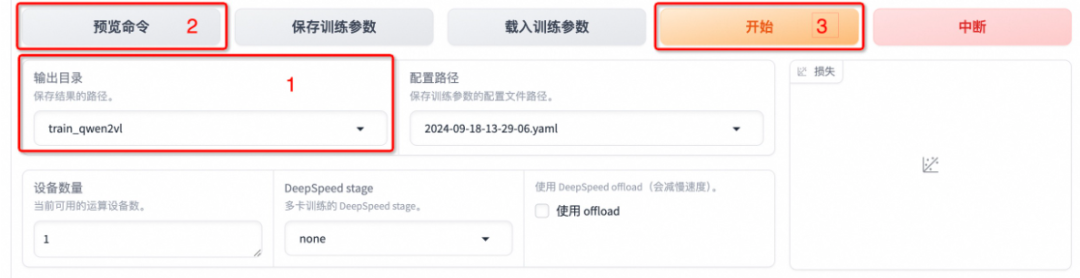
3.3 开始微调
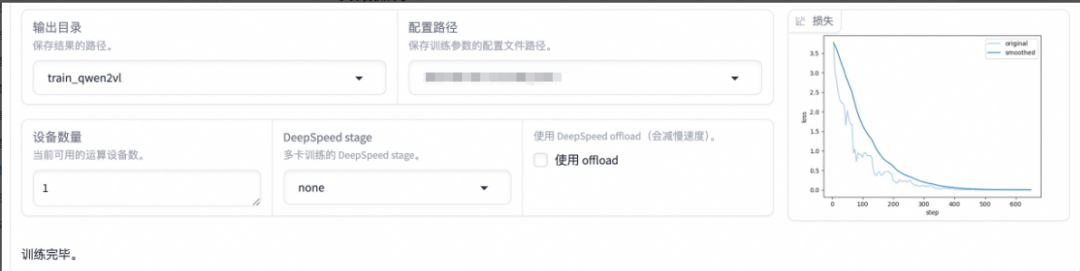
将输出目次修改为 train_qwen2vl,训练后的模型权重将会保存在此目次中。点击「预览下令」可展示所有已设置的参数,点击「开始」启动模型微调。
启动微调后必要等待一段时间,待模型下载完毕后可在界面观察到训练进度和损失曲线。模型微调大约必要 14 分钟,表现“训练完毕”代表微调乐成。
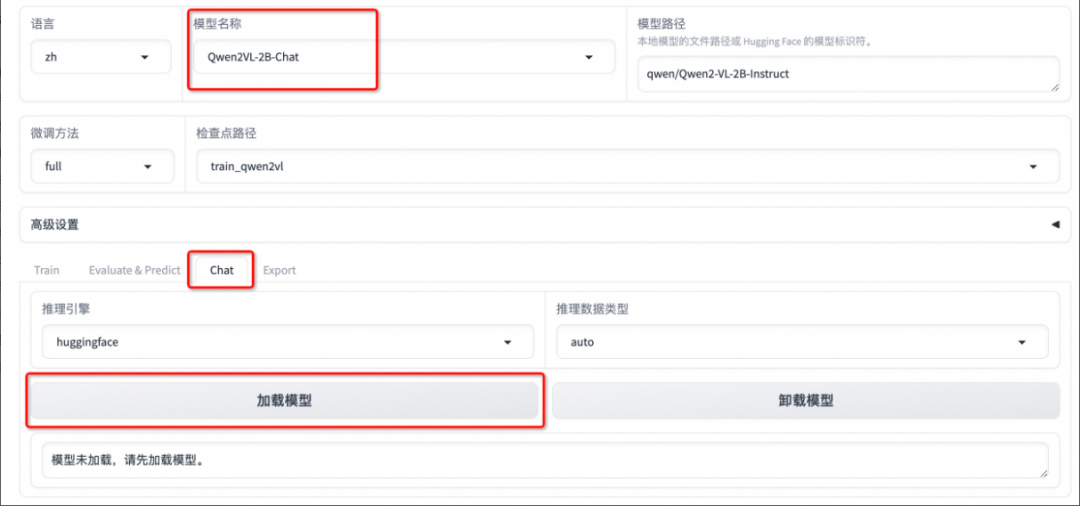
3.4 模型对话
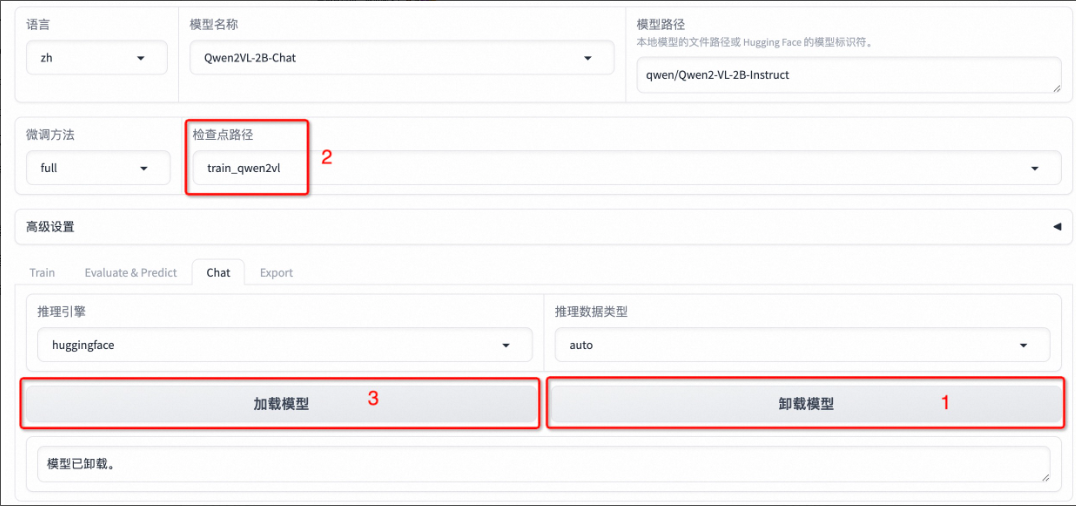
选择「Chat」栏,将检查点路径改为 train_qwen2vl,点击「加载模型」即可在 Web UI 中和微调后的模型进行对话。
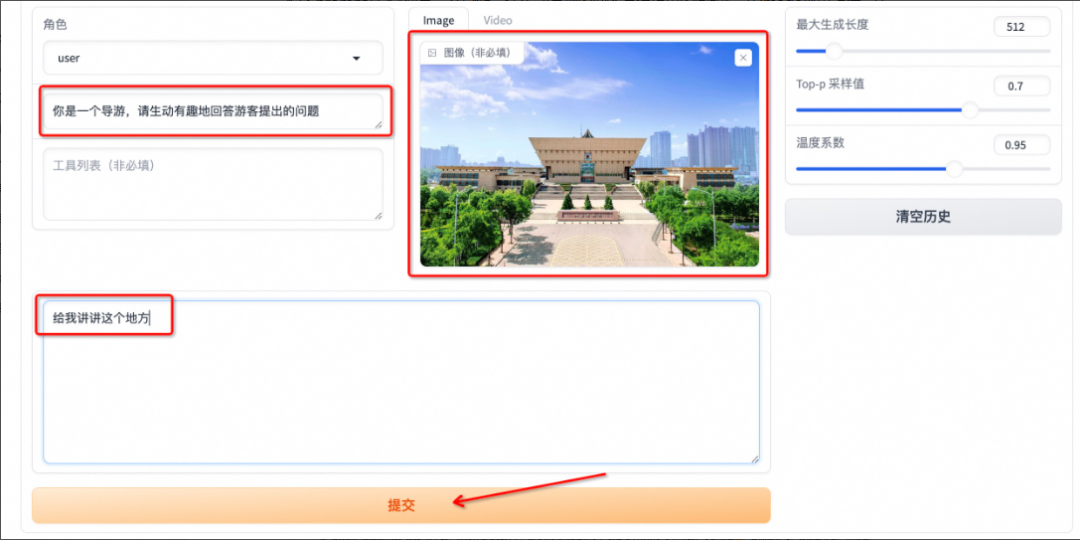
输入prompt文本"你是一个导游,请生动有趣的答复有课提出的问题",在image那里上传一张图片,然后输入文本“给我讲讲这个地方”,点击提交即可。
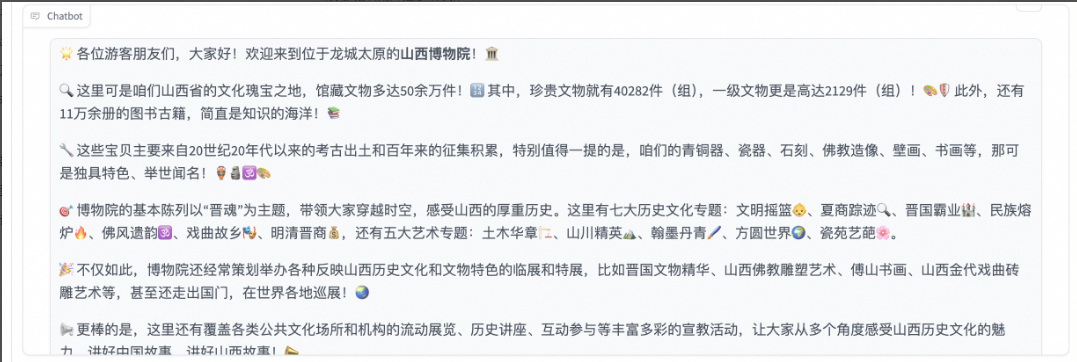
下面是模型输出的答案,可以发现模型学习到了数据集中的内容,可以或许适当地模拟导游的语气先容图中的山西博物院。
假如想对比下微调模型前后的效果差异,可以先卸载模型,然后点击检查点路径输入框取消勾选检查点路径,再次点击「加载模型」,即可与微调前的原始模型谈天。
卸载之后的模型输出如下:
04 小结
上面使用LLaMA Factory框架,基于full方式微调了 Qwen2-VL-2B 模型,构建了文旅范畴多模态大模型。假如想做一个AI版的听泉鉴宝,可以参考上面的方式,收集听泉直播间里的各种古玩照片以及听泉的笔墨数据进行整理,使用多模态学习模型进行微调就可以针对实际的业务场景构建本地范畴的大模型应用了。
参考资料
[1]https://github.com/hiyouga/LLaMA-Factory/
[2]https://gallery.pai-ml.com/#/preview/deepLearning/nlp/llama_factory_qwen2vl
最新最全的文章请关注我的微信公众号或者知乎专栏:数据拾光者。
码字不易,欢迎小同伴们关注和分享。
免责声明:如果侵犯了您的权益,请联系站长,我们会及时删除侵权内容,谢谢合作!更多信息从访问主页:qidao123.com:ToB企服之家,中国第一个企服评测及商务社交产业平台。
欢迎光临 IT评测·应用市场-qidao123.com (https://dis.qidao123.com/)
Powered by Discuz! X3.4