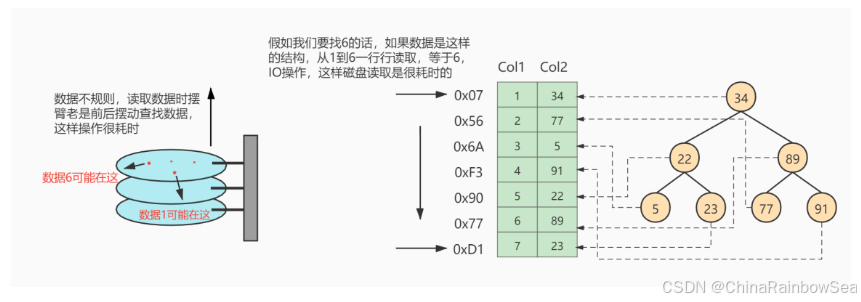
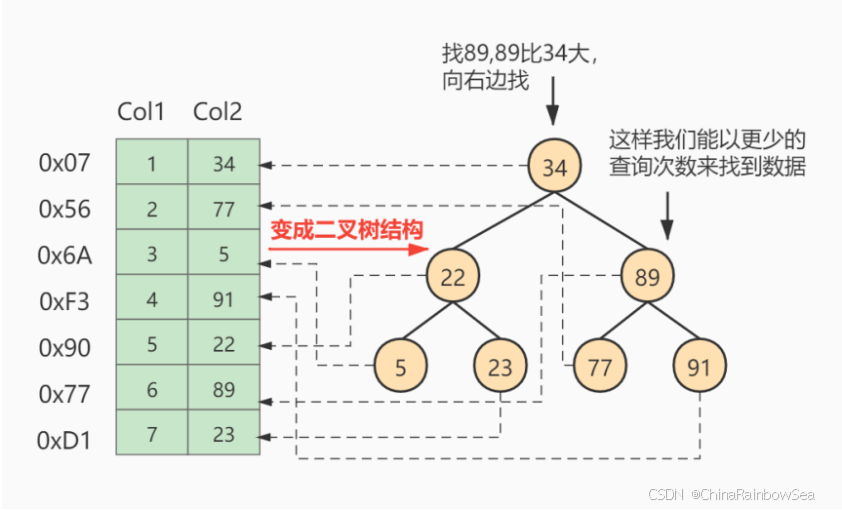
提示:3. InnoDB中索引的推演
索引可以提高查询的速率,但是会影响插入记载的速率。这种情况下,最好的办法是先删除表中的索引,然后插入数据,插入完成后再创建索引。
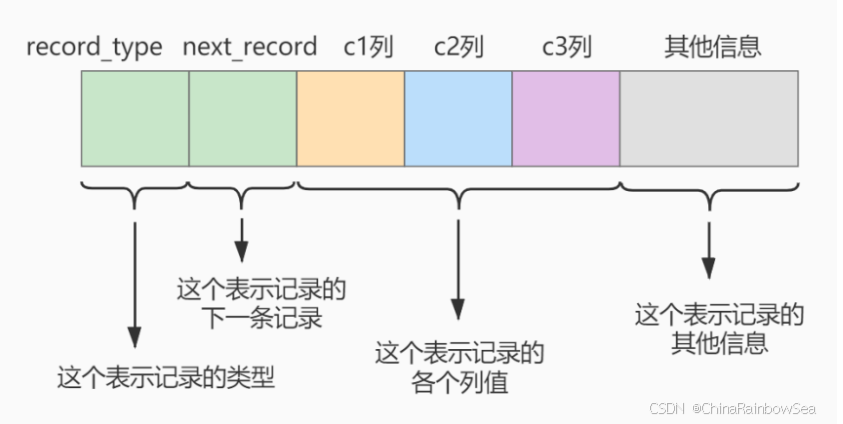
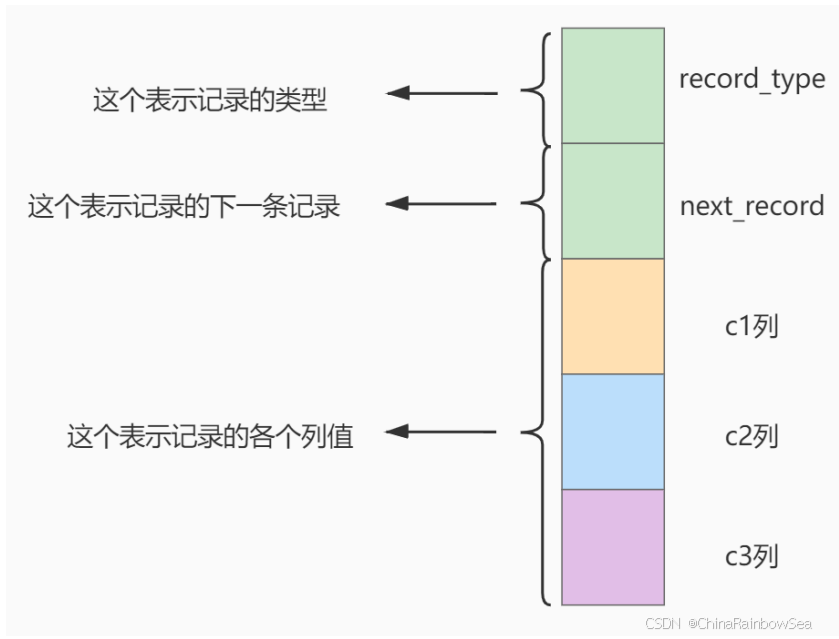

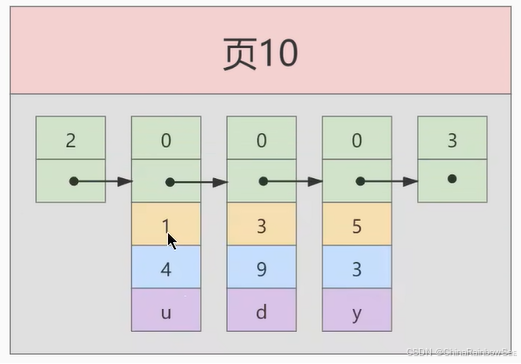
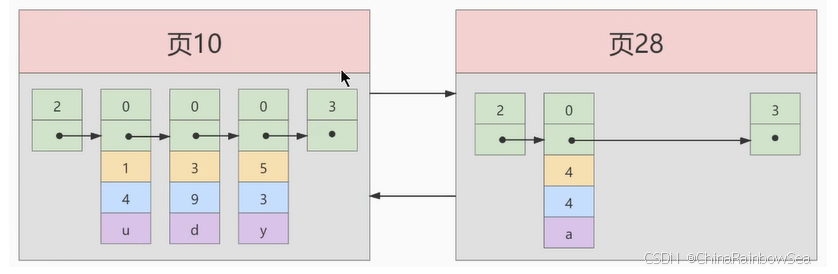
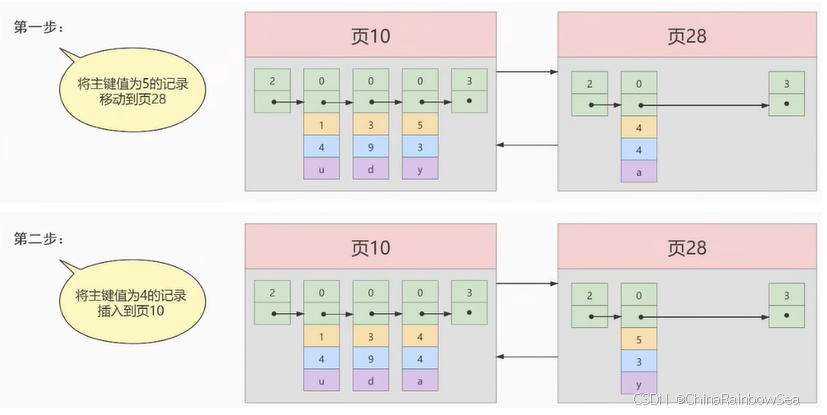

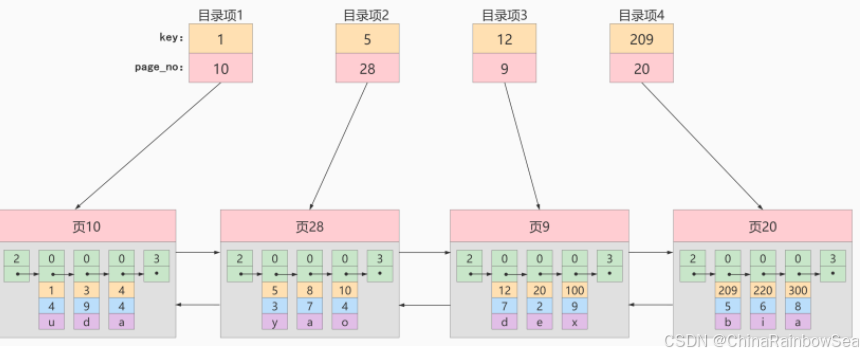
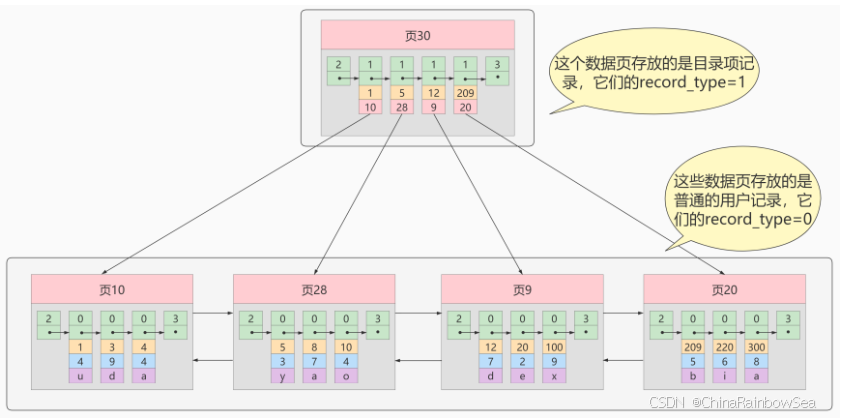
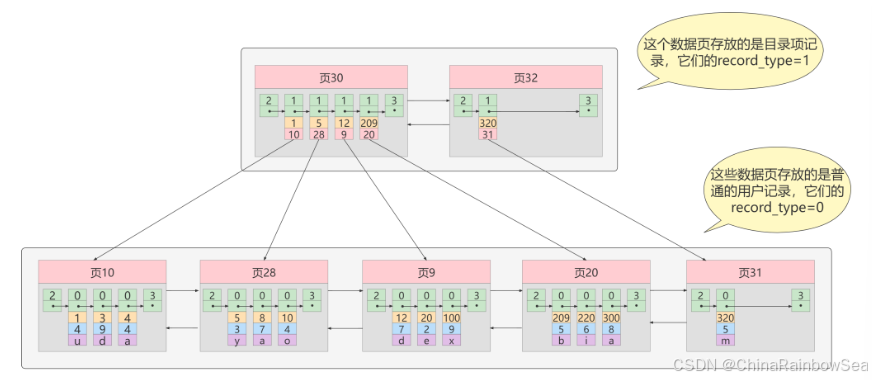

术语"聚簇"表示当前数据行和相邻的键值聚簇的存储在一起特点:
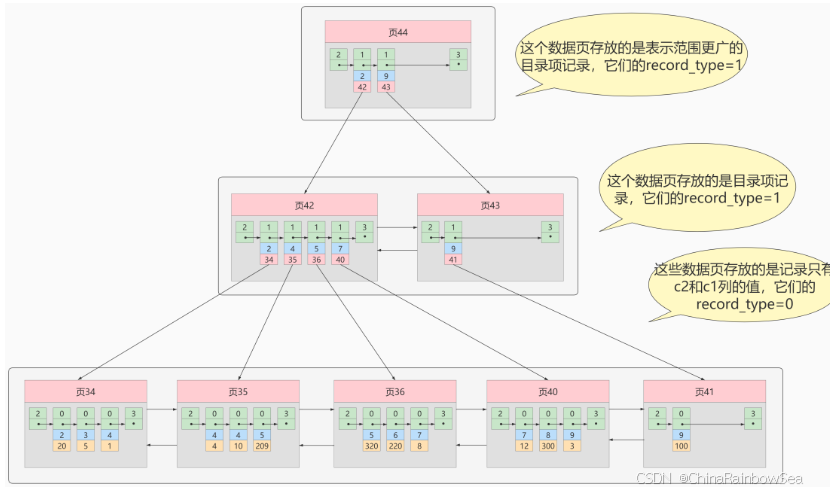

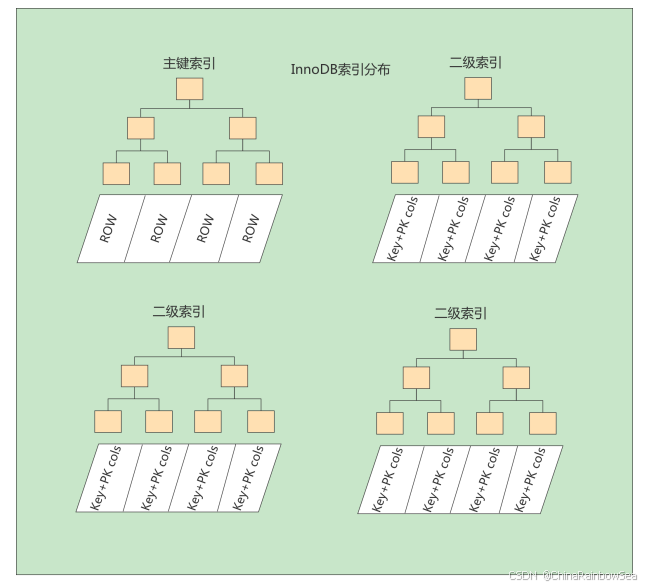
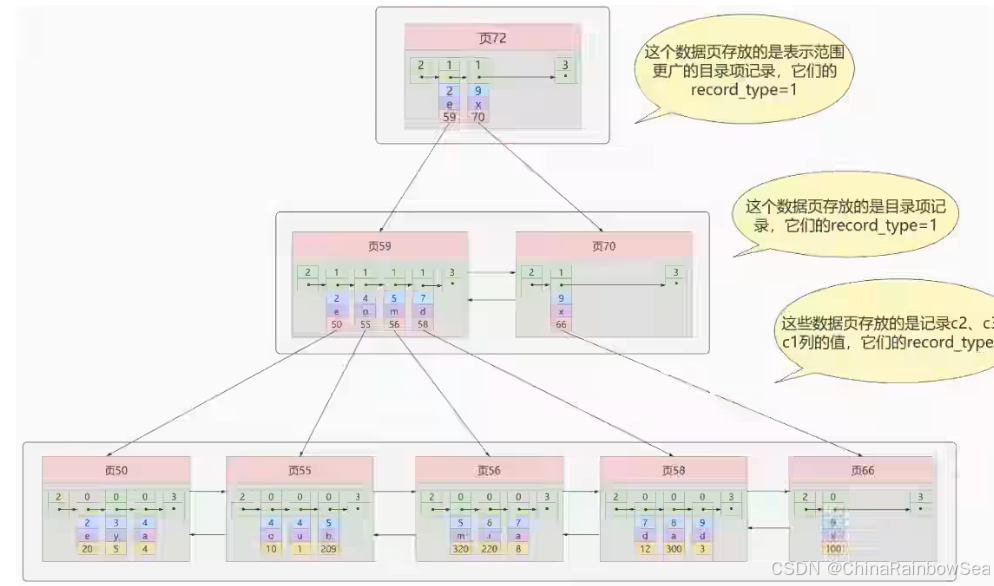
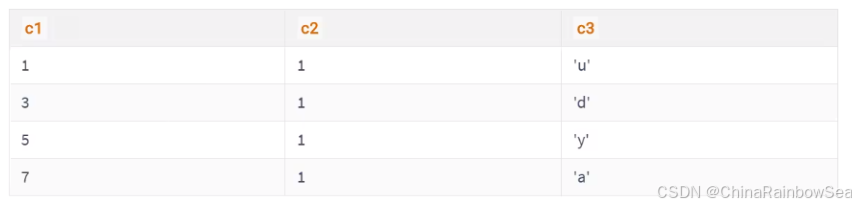
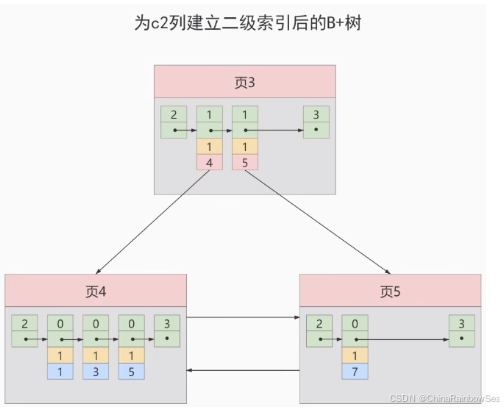
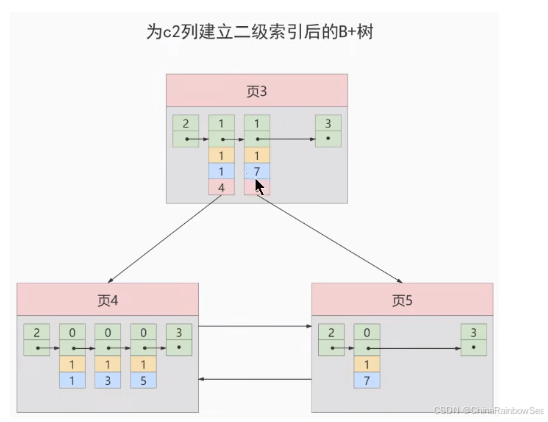

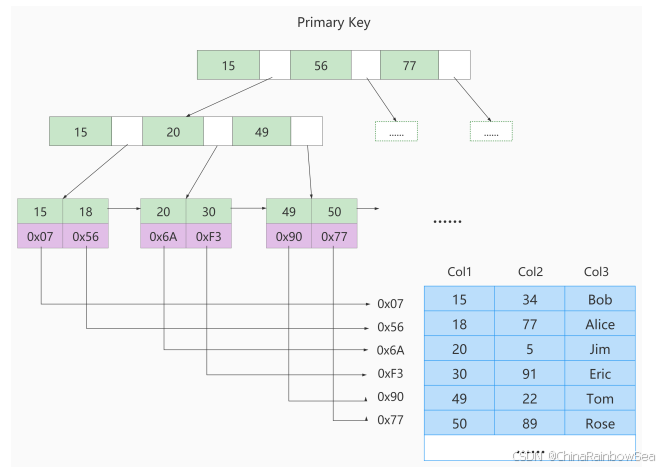
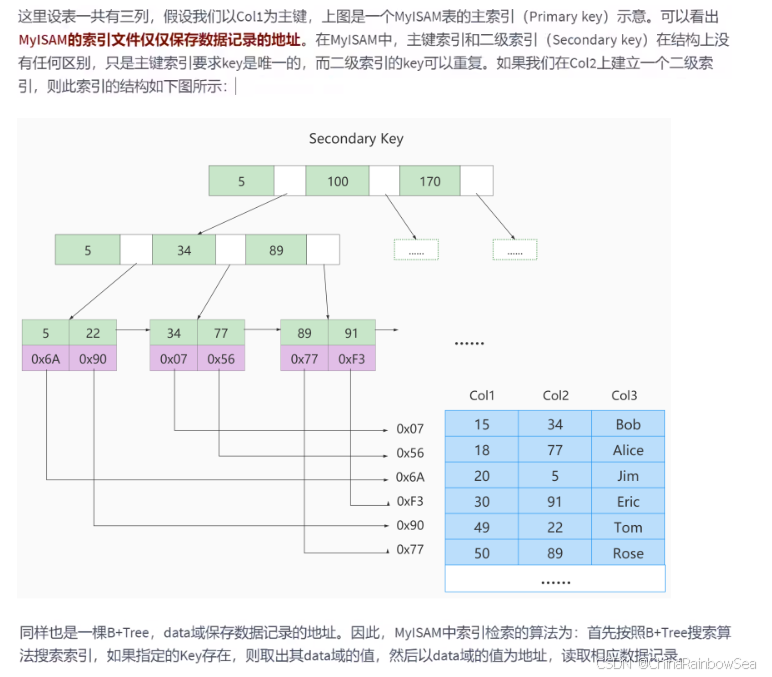


一个表上索引建的越多,就会占用越多的存储空间,在增删改记载的时候性能就越差。为了能建立又好又少的索引,我们得学学这些索引在哪些条件下起作用的。6. 最后:
“在这个最后的篇章中,我要表达我对每一位读者的感激之情。你们的关注和回复是我创作的动力源泉,我从你们身上罗致了无尽的灵感与勇气。我会将你们的鼓励留在心底,继续在其他的领域奋斗。感谢你们,我们总会在某个时刻再次相遇。”
| 欢迎光临 IT评测·应用市场-qidao123.com (https://dis.qidao123.com/) | Powered by Discuz! X3.4 |
