qidao123.com技术社区-IT企服评测·应用市场
标题:
冲破迷思:为什么资深C++开发者几乎总是选择vector而非list
[打印本页]
作者:
饭宝
时间:
2025-3-9 21:03
标题:
冲破迷思:为什么资深C++开发者几乎总是选择vector而非list
大家好,我是小康。
前言:冲破你对容器选择的固有认知
嘿,C++小伙伴们!面临这段代码,你会怎么选?
// 存储用户信息,需要频繁查找、偶尔在中间插入删除
// 选择哪个容器实现?
std::vector<UserInfo> users; // 还是
std::list<UserInfo> users; // ?
复制代码
如果你刚学习C++,可能会想:"数据会变动,肯定用list啊!课本上说链表插入删除快嘛!"
然后有一天,你看到一位经验丰富的同事把所有list都改成了vector,并且代码性能提升了,你一脸懵逼: "这跟我学的不一样啊!"
是的,传统教科书告诉我们
:
数组(vector):随机访问快,插入删除慢
链表(list):插入删除快,随机访问慢
但实际工作中,大多数资深C++开发者却几乎总是使用vector。为什么会这样?是课本错了,照旧大佬们有什么不可告人的秘密?
今天,我要带你进入真实的C++江湖,揭开vector和list性能的真相,帮你彻底搞懂这个看似简朴却被无数程序员误解的选择题。
深入阅读后,你会发现:这个选择背后,涉及当代盘算机体系结构、内存模型和真实世界的性能考量,而不仅仅是算法复杂度的简朴对比。
微信搜索 【
跟着小康学编程
】,关注我,定期分享盘算机编程硬核技术文章。
一、理论上:vector和list各是什么?
先来个直观的比喻
:
vector就像一排连续的座位
:大家坐在一起,找人超快,但中心插入一个人就需要背面的人都今后挪。
list就像一群手拉手的人
:每个人只知道自己左右邻居是谁,找到第n个人必须从头数,但中心插入一个人只需要改变双方人的"指向"。
技术上讲
:
vector
:连续内存,支持随机访问(可以直接访问恣意位置),内存结构紧凑
list
:双向链表,只支持顺序访问(必须从头/尾遍历),内存结构分散
vector和list的内部结构对比
vector的内部结构
:
[元素0][元素1][元素2][元素3][元素4][...]
↑ ↑
begin() end()
复制代码
vector内部实在就是一个动态扩展的数组,它有三个紧张指针:
指向数组开始位置的指针start
指向最后一个元素背面位置的指针end
指向已分配内存末尾的指针(容量capacity)
当空间不够时,vector会重新分配一块更大的内存(通常是当前大小的1.5或2倍),然后把所有元素搬过去,就像搬家一样。
list的内部结构
:
┌──────┐ ┌──────┐ ┌──────┐
│ prev │◄───┤ prev │◄───┤ prev │
┌──┤ data │ │ data │ │ data │
│ │ next │───►│ next │───►│ next │
│ └──────┘ └──────┘ └──────┘
│ 节点0 节点1 节点2
↓
nullptr
复制代码
list是由一个个独立的节点组成,每个节点包含三部分:
存储的数据
指向前一个节点的指针
指向后一个节点的指针
这就像一个手拉手的圆圈游戏,每个人只能看到左右两个人,要找到第五个人,必须从第一个开始数。
这两种容器结构上的差异,决定了它们在差别操作上的性能体现。vector因为内存连续,以是可以通过简朴的指针算术直接跳到恣意位置;而list必须一个节点一个节点地遍历才气到达指定位置。
按照传统教科书,它们的复杂度对比是这样的
:
操作vectorlist随机访问O(1)O(n)头部插入/删除O(n)O(1)尾部插入/删除均摊 O(1)O(1)中心插入/删除O(n)O(1)**
留意
:list 的中心插入/删除是O(1),但前提是你已经有了指向该位置的迭代器,找到这个位置通常需要O(n)时间。
看上去 list 在插入删除方面优势明显,但为什么那么多经验丰富的程序员却发起"几乎总是用vector"呢?
二、实际很残酷:理论≠实践
老铁,上面的理论分析忽略了一个超级紧张的当代盘算机特性:
缓存友爱性
。
什么是缓存友爱性?
想象你去图书馆看书:
vector就像是把一整本书借出来放在你桌上(数据连续存储)
list就像是每看一页就得去书架上找下一页(数据分散存储)
当代CPU都有缓存机制,当访问一块内存时,会把附近的数据也一并加载到缓存。对于连续存储的vector,这意味着一次加载多个元素;而对于分散存储的list,每次可能只能有效加载一个节点。
实际性能测试
我做了一个简朴测试,分别用vector和list存储100万个整数,然后遍历求和:
// Vector遍历测试 - 使用微秒计时更精确
auto start = chrono::high_resolution_clock::now();
int sum_vec = 0;
for (auto& num : vec) {
sum_vec += num;
}
auto end = chrono::high_resolution_clock::now();
auto vector_time = chrono::duration_cast<chrono::microseconds>(end - start).count();
// List遍历测试 - 使用微秒计时更精确
start = chrono::high_resolution_clock::now();
int sum_list = 0;
for (auto& num : lst) {
sum_list += num;
}
end = chrono::high_resolution_clock::now();
auto list_time = chrono::duration_cast<chrono::microseconds>(end - start).count();
// 输出结果 - 微秒显示,并转换为毫秒显示
....
复制代码
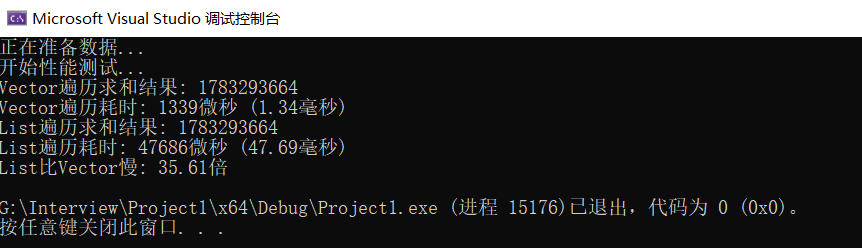
效果震动了我
:
这是30几倍的差距!为啥?就是因为缓存友爱性!
三、list的"快速插入"真的快吗?
我们再来测试一下在容器中心位置插入元素的性能:
[code] cout
欢迎光临 qidao123.com技术社区-IT企服评测·应用市场 (https://dis.qidao123.com/)
Powered by Discuz! X3.4