Garden,
red flower,
blue flower,
yellow flower,
Garden,
red flower,
blue flower,
(yellow flower)
Garden,
red flower,
blue flower,
((yellow flower))
Garden,
red flower,
blue flower,
(((yellow flower))) 2、大括号 { }
大括号也是增加权重的,但相比小括号更稍微,是增加1.05倍,三层大括号权重为1.15倍 3、中括号 [ ]
这个是减小权重值的,它会把权重变为原来的0.9倍,三层就是0.729倍 案例:同样是花园利用中括号减重红色花朵:
best quality, masterpiece,
Garden, red flower, blue flower, yellow flower
best quality, masterpiece,
Garden,[[[ red flower]]], blue flower, yellow flower 4、自界说权重
自界说权重只可利用小括号控制,格式为(x:0.5)
0.5为权重值,权重取值范围 0.4-1.6,权重太小容易被忽视,太大容易拟合图像出错 案例:利用自界说权重蓝色花朵对比:
best quality, masterpiece,
Garden, red flower,
(blue flower:0.4), yellow flower
best quality, masterpiece,
Garden, red flower,
(blue flower:1.6), yellow flower 5、利用尖括号 <>调用lora
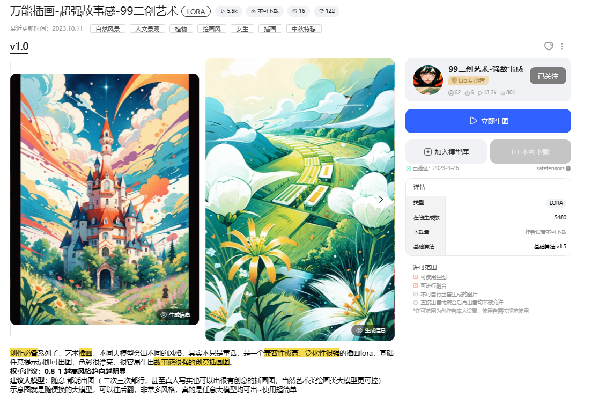
lora简单来说就是风格化模型,可以生成我们想要的特定风格大概人物。
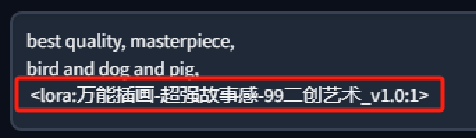
我们可以在提示词中利用 lora:lora名称:权重来调用lora
例如:
样例:利用lora让图片特定风格
利用lora前
利用lora后
样例:你可以通过权重来调解lora对画面的影响(0.1-1)
best quality, masterpiece,
Garden, red flower, blue flower, yellow flower
lora:万能插画-超强故事感-99二创艺术\_v1.0:0.5
best quality, masterpiece,
Garden, red flower, blue flower, yellow flower
lora:万能插画-超强故事感-99二创艺术\_v1.0:0.3 6、利用下划线和and毗连提示词
下划线_起到毗连的作用,让词与词更紧密毗连到一起/防止歧义。
例如我想让AI生成一个咖啡蛋糕,假如不加下划线它很大概明白不了会出现单独的咖啡喝蛋糕,但是加了下划线后它就明白的更好了。
best quality, masterpiece,
a girl,
green hair:1.3 and red hari:1.5 and yellow hair:1.2 三、提示词进阶语法 1、控制提示词的生效时间 [提示词:0-1数值]:意思是采样值达到X(数值)以后才开始计算这个提示词的采样
例如:
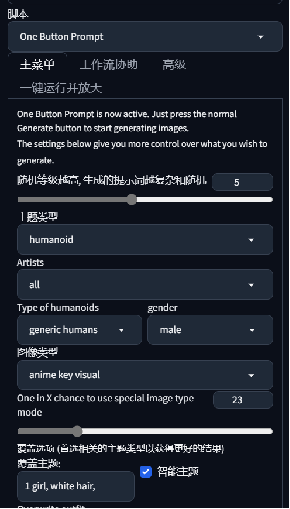
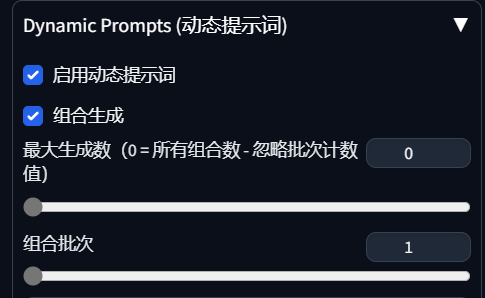
**最大生成数:**0就是全部的方式都生成一次
**组合批次:**就是每一个范例生成几张 主动批次组合生成
开启动态提示词插件后可以利用全新语法进行提示词搭配:
A {boy | girl} in {school | street | forest},
上面这串语法的意思是:生成一个老师大概学生分别在学校、街道和森林的6种组合:
生成组合的结果
丰富提示词功能
打开邪术提示词功能可以丰富提示词,例如我们输入一个提示词:a girl 长度就是词的数量创意越高AI发挥的越多 推荐利用模型:succinctly/text2image-prompt-generator
这是一个在简便/中途提示数据集上微调的 GPT-2 模型,其中包含用户在一个月内向 Midjourney 文本到图像服务发出的 250k
文本提示。有关怎样抓取此数据集的更多详细信息,请参阅中途用户提示和生成的图像 (250k)。
该提示生成器可用于主动完成任何文本到图像模型的提示(包括 DALL·E家属)。
强力推荐,各种扩展都好用,词穷抽卡必备。 AUTOMATIC/promptgen-lexart
这个模型是从 lexica.art 艺术网站上 进行训练的抓取的134819提示微调了 100 个
epoch,这个模型适合艺术风格画的邪术扩展,推荐画艺术风格提示词邪术扩展。 Gustavosta/MagicPrompt-Stable-Diffusion
邪术提示词第一个模型,这是 MagicPrompt 系列模型中的一个模型,这些模型是 GPT-2 模型,旨在生成用于成像 AI 的提示文本。该模型经过
150,000 个步骤和一组约莫 80,000
个数据进行训练,这些数据从图像查找器中过滤并提取出来,以实现稳固扩散:“Lexica.art”。提取数据有点困难,由于搜刮引擎仍然没有公共API,这个特殊通用、实用,适用各种场景提示词扩展,结果卓越。 模型安装: 注意:需要科学上网 ,第一次利用模型会主动下载需要等候一下,并且关闭启动器的国内Pipy镜像、Git镜像、链接等。否则下载失败,会报错误:Error
while generating prompt: ‘NoneType’ object cannot be interpreted as an
integer。