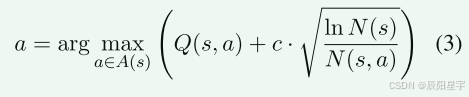
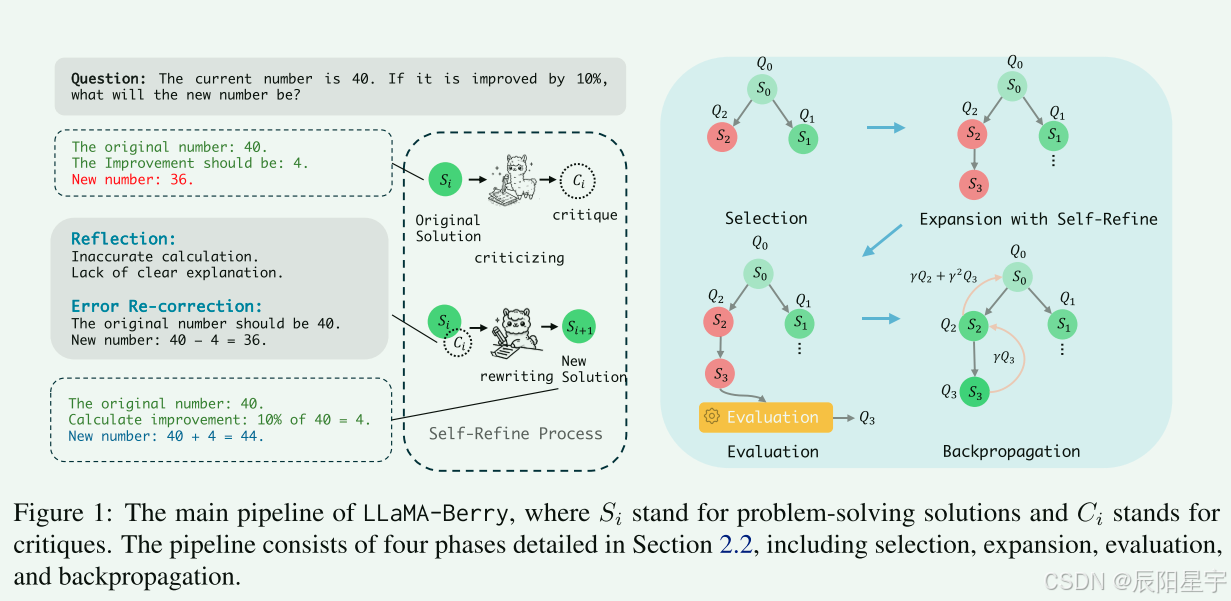
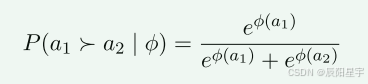
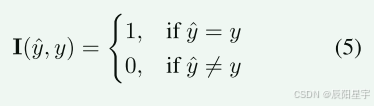
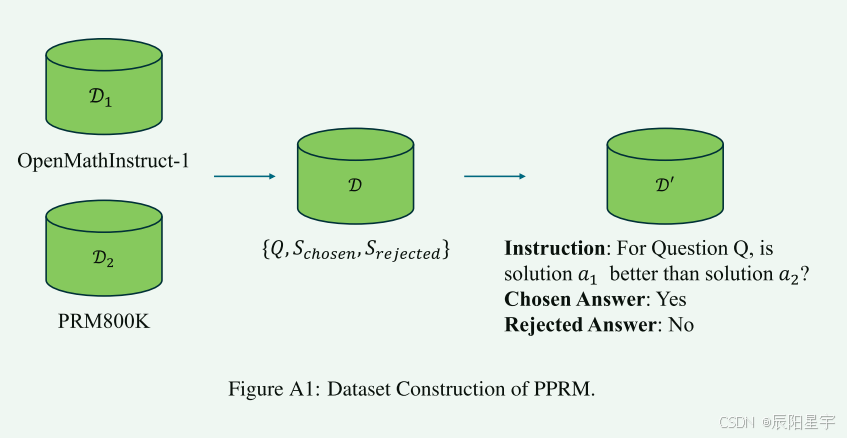
 RM800K 和OpenMathInstruct-1。从MATH数据集网络的PRM800K数据集包含大量分步解决问题的答案,每个步调都有手动注释。主要利用该数据集生成基于逐步过程质量的比较分析的成对答案。OpenMathInstruct-1数据聚集并了来自GSM8K和MATH数据集的数据,这些数据集已被手动注释以确保结果的精确性。我们使用该数据聚集成基于结果质量的比较分析对。最终,文中形成了一个包含7,780,951个条目的数据集,采用DPO方式举行训练,用于训练PPRM模子。
RM800K 和OpenMathInstruct-1。从MATH数据集网络的PRM800K数据集包含大量分步解决问题的答案,每个步调都有手动注释。主要利用该数据集生成基于逐步过程质量的比较分析的成对答案。OpenMathInstruct-1数据聚集并了来自GSM8K和MATH数据集的数据,这些数据集已被手动注释以确保结果的精确性。我们使用该数据聚集成基于结果质量的比较分析对。最终,文中形成了一个包含7,780,951个条目的数据集,采用DPO方式举行训练,用于训练PPRM模子。
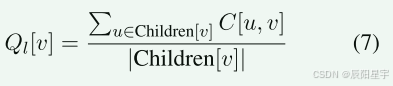

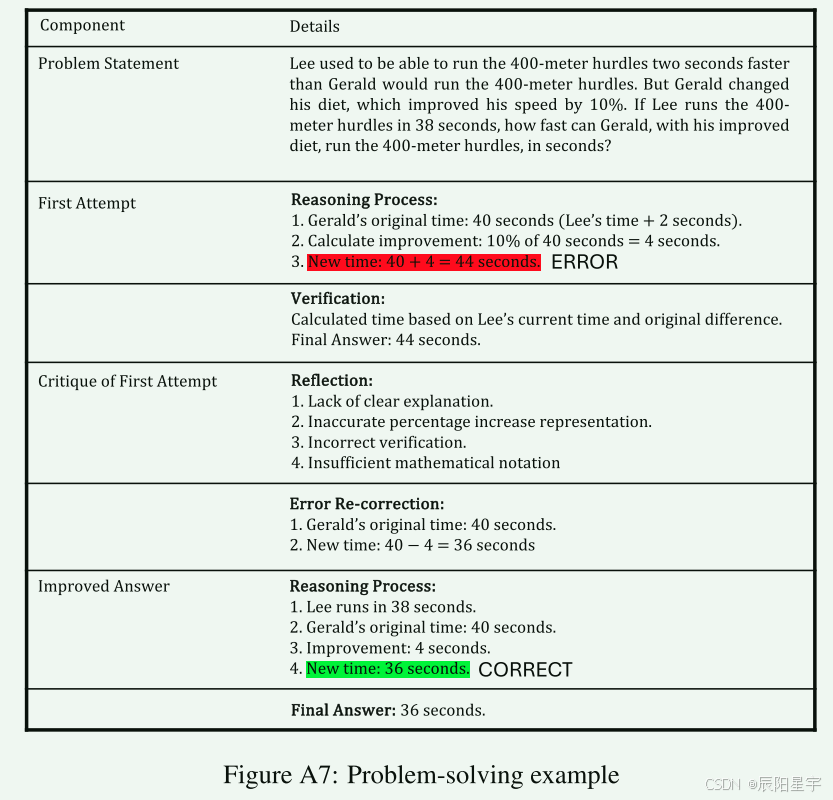
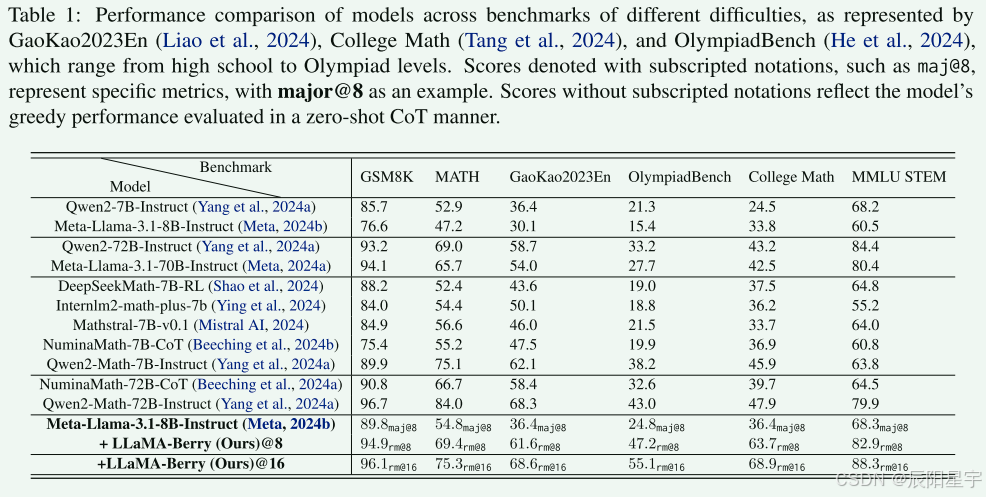
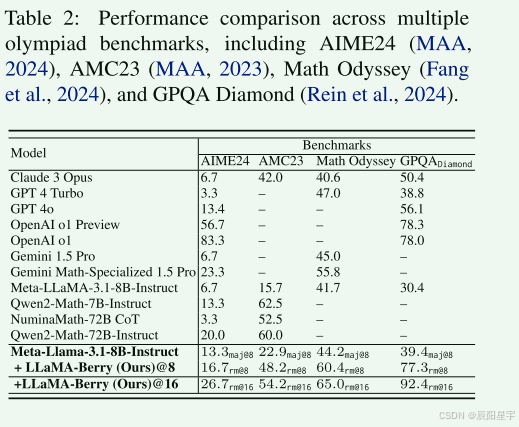
| 欢迎光临 IT评测·应用市场-qidao123.com (https://dis.qidao123.com/) | Powered by Discuz! X3.4 |