IT评测·应用市场-qidao123.com技术社区
标题:
基于Hadoop+Spark的音乐推荐体系【附源码+数据库+分布式假造机】
[打印本页]
作者:
海哥
时间:
2025-3-15 07:34
标题:
基于Hadoop+Spark的音乐推荐体系【附源码+数据库+分布式假造机】
目次
摘要
功能介绍
开发环境
界面展示
编辑Hadoop简介
核心组件
HDFS
MapReduce
YARN
重要模块展示
代码结构
设置文件
开源代码
摘要
在互联网与数字音乐发达发展的时代,音乐平台积聚了海量的用户举动数据与音乐内容数据,这些数据中潜藏着用户偏好和音乐盛行趋势等关键信息,如何发掘并使用这些数据来优化推荐体系、提升用户体验,成为音乐平台发展的关键问题。Hadoop 和 Spark 作为大数据处理范畴的核心技能,为处理和分析这些大规模数据提供了有力支持。本研究致力于构建一个基于 Hadoop 和 Spark 的音乐推荐体系,同时融入预测模子与可视化技能。研究内容包罗使用 Hadoop 和 Spark 技能采集并预处理音乐平台的用户举动(如播放、收藏、评论等)与音乐内容(如歌曲、歌手信息等)数据;基于这些数据设计并实现融合协同过滤、内容推荐等策略的混淆推荐算法,以提高推荐的精确性和多样性;运用呆板学习算法构建用户举动预测模子,预测用户未来音乐偏好和听歌举动;设计并实现用于展示推荐结果、用户举动分析以及预测模子输出的可视化界面。研究旨在打造一个可以或许高效处理和分析海量音乐数据的推荐体系,实现个性化音乐推荐,提升用户满足度和平台活跃度,构建用户举动预测模子为音乐平台运营决议提供依据,同时设计直观易用的可视化界面来增强用户体验。研究过程中着重办理大数据处理服从、推荐算法优化、预测模子构建以及可视化界面设计等关键问题,本研究在结合多技能构建音乐推荐体系方面具有创新性和实用价值。
功能介绍
数据采集与预处理
:运用 Hadoop 和 Spark 技能,从音乐平台广泛采集用户播放、收藏、评论等举动数据,以及歌曲、歌手等音乐内容数据。随后对这些数据进行洗濯,去除噪声、重复数据,填补缺失值,规范化数据格式。
个性化音乐推荐
:基于预处理后的用户举动和音乐内容数据,设计并实现融合协同过滤(依据用户相似听歌举动推荐音乐)、内容推荐(根据音乐特征与用户历史偏好匹配推荐)等策略的混淆推荐算法。
用户举动预测
:借助呆板学习算法构建用户举动预测模子,通太过析用户过往举动,对用户未来音乐偏好、听歌时段、听歌频率等举动进行预测。
可视化展示
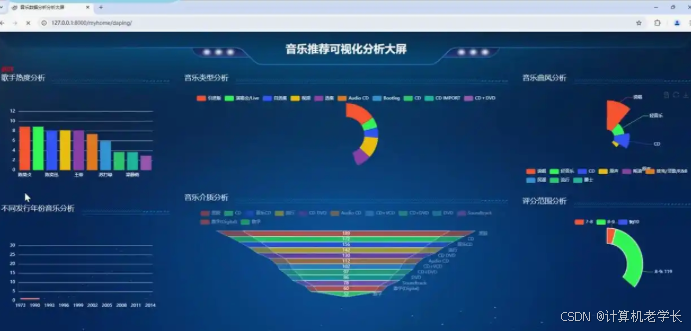
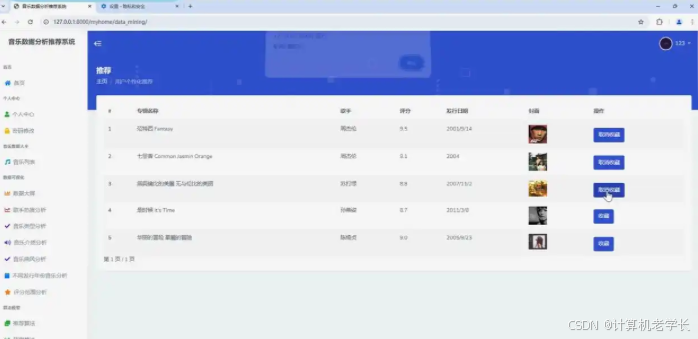
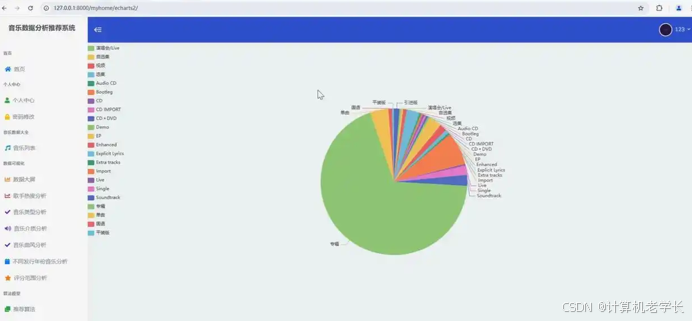
:精心设计并实现可视化界面,以直观图表(如柱状图、折线图、饼图等)、列表形式展示个性化推荐结果,让用户一览无余。同时,呈现用户举动分析数据,如听歌时长趋势、音乐类型偏好占比等,帮助用户了解自身音乐喜好特征。此外,展示预测模子输出结果,如预测的热门音乐趋势、用户下一首可能播放的歌曲等。
开发环境
Windows程序:Python 3.7,MySql 5.6,Redis 5.0.7
Linux程序:Java 1.8、Spark 3.1.1、Hadoop 2.7
数据库:MySQL 5.6,Redis
开发平台:Pycharm+Vscode
运行环境:Windows 10,Linux
界面展示
Hadoop简介
核心组件
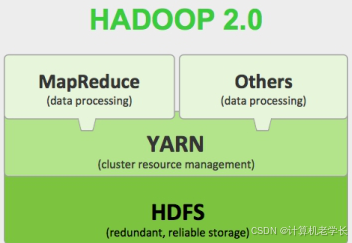
Hadoop的核心组件包罗以下 4个:
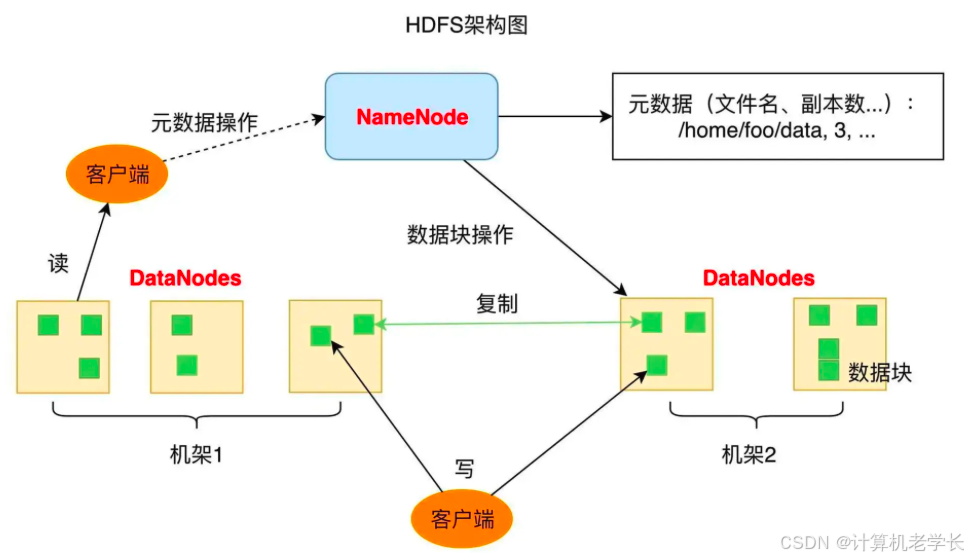
HDFS:HDFS是 Hadoop的数据存储层,它负责将大量数据分块存储到集群中的不同节点上,从而实现分布式保存和冗余备份。数据被切分成小块,并复制到多个节点,以防硬件故障。
MapReduce:MapReduce是 Hadoop的分布式盘算模子,它将处理大规模数据集的任务分发到多个节点,答应并行处理。MapReduce由两个阶段组成:Map阶段负责将任务分解为多个小任务;Reduce阶段负责对小任务的结果进行汇总。
YARN:YARN 是 Hadoop的资源管理层,它负责管理和调度集群中的盘算资源。YARN答应多个作业在同一 Hadoop集群上并行实行,这大大提高了 Hadoop集群的使用率和扩展能力。
Hadoop Common:Hadoop Common是 Hadoop的核心库,提供必要的工具和实用程序,用于支持其他 Hadoop模块。
它们的关系如下:
HDFS
HDFS(Hadoop Distributed File System,分布式文件体系)作为 Hadoop 核心组件,重要用于办理海量数据存储问题。它采用主从结构,由 NameNode(主节点)和 DataNode(数据节点)两类节点构成。NameNode 负责管理文件体系元数据,如文件和目次结构、文件块位置、用户权限等,但不直接存储数据,仅记录数据所在的 DataNode;DataNode 则是实际存储数据的节点,并定期向 NameNode 汇报存储块信息与健康状态。此外,另有可选组件 Secondary NameNode,用于辅助 NameNode 进行元数据备份和日志合并,保障文件体系的高可用性。
HDFS 的数据存储机制是文件分块存储,大文件按固定大小(默认 128MB,早期版本 64MB)被分别为多个数据块,每个文件块存储在集群中不同的 DataNode 上。为防止数据因节点故障丢失,HDFS 采用数据冗余与容错机制,默认每个数据块有 3 个副本,一个副本存于与客户端近来节点,第二个副本存于不同机架节点以防止机架故障,第三个副本存于第二个副本所在机架的其他节点,以此确保部分 DataNode 失效时数据仍可通过其他副本节点恢复。
HDFS 的读写操作流程如下:写入时,客户端先与 NameNode 交互,发送写哀求,NameNode 返回存储文件每个块的 DataNode 节点位置;接着客户端将数据块发送至其中一个 DataNode,该 DataNode 依次通报给下一个 DataNode,直至全部节点都保存副本;上传完成后,涉及的 DataNode 将存储状态关照 NameNode 并提交流程竣事。读取时,客户端先向 NameNode 哀求文件位置信息,NameNode 返回文件块及其所在 DataNode 的位置;然后客户端依据这些位置从相关 DataNode 直接读取文件不同数据块并组装回文件;若某个 DataNode 失效,客户端无法从该节点获取块信息时,会尝试从存储副本的其他 DataNode 读取。
MapReduce
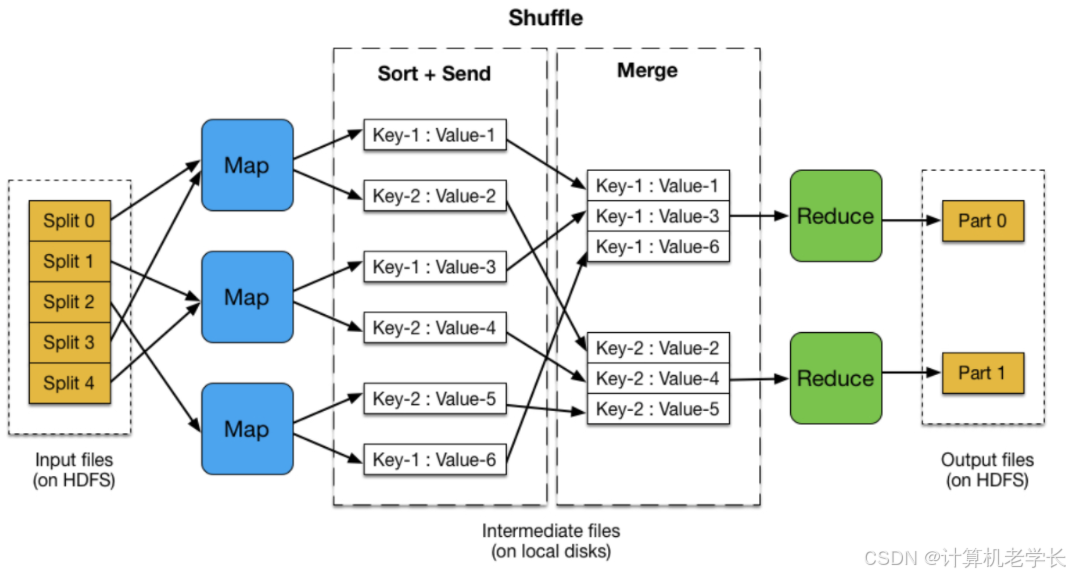
MapReduce 是 Hadoop 的分布式盘算框架,通过把复杂任务分解为多个简单任务实现并行盘算,核心思想包含 “Map” 和 “Reduce” 两个阶段。Map 阶段将原始数据映射为键值对,Reduce 阶段对相同键的数值进行聚合。实行流程如下:
Job 分别
:一个完备的 MapReduce 任务即一个 Job,由多个 Task 组成,包罗 Map Task 和 Reduce Task。
Input Splitting(输入分片)
:处理数据时,先将大文件切分成较小的 Splits,Map Task 数目通常与输入分片数目相同,每个 Map Task 处理一个分片的数据。
Map 阶段
:每个 Map Task 获取一份 Input Split 数据,通过 RecordReader 转化为键值对 <key, value> ((K1, V1) 依业务需求构造)。Map 函数处理这些键值对,输出新键值对 < K2, V2> ,输出前会进行 Sort(排序)和 Partition(分区)操作,Partition 用于将相同键(K2)的键值对分发到相同 Reducer 实行。
Shuffle and Sort(分发与排序)
:发生在 Map 与 Reduce 阶段之间。排序时,每个 Map Task 输出的 <K2, V2> 按键(K2)排序,让同一键的值(V2)聚集;分区时,Map Task 输出根据 Partition 函数哈希值发送到不同 Reduce 任务;最后 Reducer 拉取所需分区文件并聚合。
Reduce 阶段
:每个 Reduce Task 吸收 Shuffle 后的键值对聚集(<K2, List<V2>> ),用户自定义的 Reduce 函数对每个 K2 进行聚合盘算,输出新键值对 <K3, V3> ,终极结果通过 RecordWriter 写入 HDFS 或其他存储体系。
YARN
YARN(Yet Another Resource Negotiator,另一种资源调度器)是Hadoop 2.x版本中引入的一个集群资源管理框架,它的设计初衷是办理 Hadoop 1.x中 MapReduce盘算框架的资源调度和管理范围性,可以支持各种应用程序调度的需求。
重要模块展示
代码结构
├─BiShe
│ ├─admin.py (Django后端管理系统主要配置)
│ ├─views.py (各个页面访问调用)
│ └─urls.py (各个页面访问地址)
│
├─BiSheServer
│ ├─settings.py (Django主要配置文件)
│ └─urls.py (一级地址处理地址)
│
├─config (配置文件存放目录)
│ └─conf.ini (本系统主要配置文件)
│
├─spark
│ ├─jars (MySQL连接jar包)
│ └─spark.py (Spark处理用户画像,可独立)
│
├─movie
│ ├─models.py (电影模型配置,对应数据库表)
│ ├─views.py (电影的api接口)
│ └─urls.py (二级movie地址配置)
│
├─user
│ ├─models.py (用户模型配置,对应数据库表)
│ ├─views.py (用户的api接口)
│ └─urls.py (二级user地址配置)
│
├─api (api文件夹)
│ ├─api.py (其他API)
│ ├─movie_api.py (电影操作api)
│ ├─user_api.py (用户操作api)
│ ├─crontab.py (配置包)
│ ├─captcha.py (生成验证码api)
│ ├─delay_work.py (使用线程修改标签)
│ ├─districts.py (查询区域地址api)
│ ├─email.py (邮箱发送邮件api)
│ ├─email_vail.py (邮件发送前的验证)
│ ├─middleware_log.py (自定义日志中间件)
│ ├─MidnightRotatingFileHandler.py (线程安全日志切割配置)
│ ├─model_json.py (数据库查询结果转换)
│ ├─redis_pool.py (Redis连接池)
│ ├─models.py (中国省市地区表、首页轮播图表)
│ ├─response.py (api统一格式化响应)
│ ├─set_var.py (模板配置set变量操作符)
│ ├─upload_log.py (上传系统日志文件)
│ ├─urls.py (api响应地址配置)
│ └─views.py (404、500错误页面配置)
│
├─log (日志文件存放临时目录)
├─static (静态文件存放目录)
├─templates (页面模板文件存放目录)
└─requirements.txt (依赖安装需求库文件)
复制代码
设置文件
;系统配置 必需配置
[DEFAULT]
;是否启用调试服务
DEBUG = True
;是否启用日志系统
USE_LOG = False
;允许访问的地址
ALLOWED_HOSTS = [*]
;静态文件目录
STATIC_HOME = static
;日志目录
LOG_HOME = log/
;模板目录
TEMPLATES_HOME = templates
; 设置允许上传的文件格式
ALLOW_EXTENSIONS = ['png', 'jpg', 'jpeg']
; 设置允许上传的文件大小,B字节为单位
ALLOW_MAXSIZE = 5242880
;头像文件存放地址
AVATARS_UPLOAD_FOLDER = static/images/avatars/
;MySql数据库配置 必需配置
[DATEBASE]
;数据库引擎驱动
DATABASES_ENGINE = django.db.backends.mysql
;数据库名称
DATABASES_NAME = sql_bs_sju_site
;数据库链接地址
DATABASES_HOST = 127.0.0.1
;数据库端口
DATABASES_PORT = 3306
;数据库用户名
DATABASES_USER = sql_bs_sju_site
;数据库密码
DATABASES_PASSWORD = xzDPV7JL79w3Epg
;Redis数据库配置 必需配置
[REDIS]
;数据库地址
REDIS_HOST = 127.0.0.1
;数据库端口号
REDIS_PORT = 6379
;数据库连接密码
REDIS_PASSWORD = 123456
;数据库存放的库号
REDIS_DB = 2
;邮件验证系统配置 可选配置
[EMAIL]
;是否使用邮箱验证服务,False为关闭时将不会真实发送邮件验证,True为启用
EMAIL_USE = False
;邮件服务器地址
EMAIL_HOST = smtpdm.aliyun.com
;邮件服务登录账号
EMAIL_USER = admin@bishe.com
;邮件服务账号密码
EMAIL_PASSWORD = 123456
;Hadoop配置 可选配置
[HADOOP_LOG]
;Hadoop链接地址
HADOOP_HOST = 172.17.183.81
; 客户端连接的目录
ROOT_PATH = /sys_data_log
; HDFS上的路径,注意,需要先在hdfs手动创建此目录
REMOTE_PATH = /sys_data_log
; 本地路径,建议写绝对路径,例如:E:\my_work\测试目录 "D:/tmp/output"
LOCAL_PATH = log/
;日志后缀格式,同时也会根据其进行切片
;按日切%Y-%m-%d 按月切%Y-%m 按小时切%Y-%m-%d_%H
LOG_SUFFIX = %Y-%m-%d
复制代码
开源代码
链接: https://pan.baidu.com/s/1-3maTK6vTHw-v_HZ8swqpw?pwd=yi4b
提取码: yi4b
免责声明:如果侵犯了您的权益,请联系站长,我们会及时删除侵权内容,谢谢合作!更多信息从访问主页:qidao123.com:ToB企服之家,中国第一个企服评测及商务社交产业平台。
欢迎光临 IT评测·应用市场-qidao123.com技术社区 (https://dis.qidao123.com/)
Powered by Discuz! X3.4