qidao123.com技术社区-IT企服评测·应用市场
标题:
(2024|JAMIA|上交,知识注入,指令微调,数据集构建,LLaMA)PMC-LLaMA:
[打印本页]
作者:
用户国营
时间:
2025-3-17 03:48
标题:
(2024|JAMIA|上交,知识注入,指令微调,数据集构建,LLaMA)PMC-LLaMA:
PMC-LLaMA: Towards Building Open-source Language Models for Medicine
目录
1. 择要
2. 相关工作
2.1 大型语言模型(LLM)
2.2 指令微调
2.3 医学基础语言模型
3. 数据集构建
3.1 基础医学知识数据集(MedC-K)
3.2 医学指令数据集(MedC-I)
4. 练习
5. 实行与评估
5.1 评测基准
5.2 结果分析
1. 择要
近年来,大型语言模型(LLMs)在自然语言理解方面表现出色。然而,在医学范畴,由于缺乏专业知识,现有模型容易产生看似正确但实则错误的结论,这大概会导致严峻结果。
别的,LLMs(如 ChatGPT 和 GPT-4)已广泛应用于各种任务,但其练习细节和架构未公开,限制了在医学范畴的适用性。开源LLMs(如 LLaMA 系列)在通用任务上表现良好,但在医学范畴仍存在以下挑战:
缺乏医学专业知识
:现有模型未经过医学范畴的深度练习,容易天生错误答案。
推理本领不足
:难以在临床场景下举行精准推理。
缺乏指令对齐
:无法灵活适应医学任务的多样性。
本文提出了
PMC-LLaMA
,一个专门针对医学范畴的开源语言模型。研究贡献包罗:
医学知识注入(Med-K)
:整合 480 万篇生物医学论文和 3 万本医学讲义,以加强医学专业知识的理解本领。
医学指令微调(Med-I)
:构建了一个包罗 202M tokens 的医学指令数据集,涵盖医学问答、推理和对话。
性能验证
:在多个医学问答基准测试中,PMC-LLaMA(13B 参数)表现优于 ChatGPT。
2. 相关工作
2.1 大型语言模型(LLM)
近年来,LLM 在自然语言处理范畴取得突破,如 ChatGPT、GPT-4 和 LLaMA。然而,现有 LLM 在医学范畴仍存在知识整合不足、推理本领有限等问题。
2.2 指令微调
指令微调(Instruction Tuning):使用通过指令形貌的任务集合对模型微调,以有用提高 LLM 的零样本和少样本泛化本领。
雷同的医学范畴模型(如 Med-Alpaca、Chat-Doctor、MedPaLM-2)已经举行了一些探索,但数据和练习细节仍不透明。
2.3 医学基础语言模型
已有的医学专用模型(如 BioBERT、BioMedGPT)重要基于 BERT 架构,规模较小,无法高效支持大规模医学任务。
本文的 PMC-LLaMA 采用更先辈的 LLM 架构,联合医学知识注入和指令微调,填补了这一空缺。
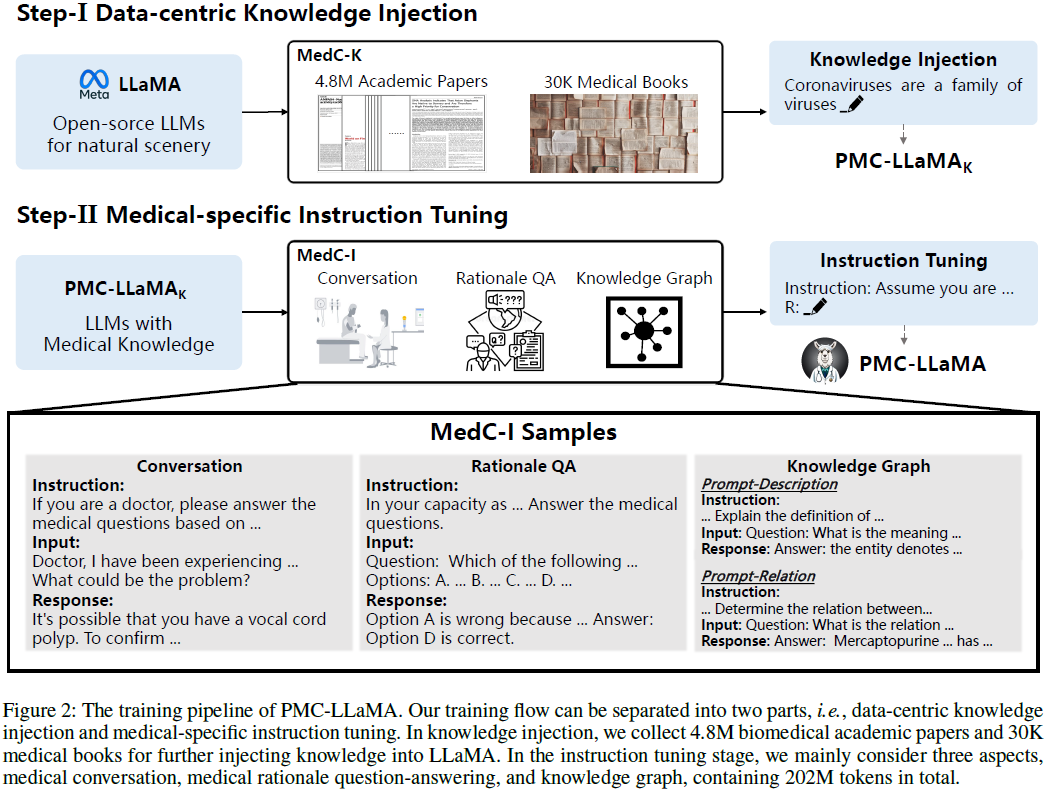
3. 数据集构建
3.1 基础医学知识数据集(MedC-K)
PMC-LLaMA 的知识注入依赖两大数据来源:
学术论文
:基于 PubMed Central (PMC) 选取了
480万篇
生物医学论文,共计
75B tokens
。
医学讲义
:收集了
3万本医学讲义
,涵盖
解剖学、药理学、病理学、肿瘤学
等多个范畴,共计
4B tokens
。
数据混合策略
:练习过程中,以
册本15: 论文4: 通用语料1
的比例举行混合,以包管医学基础知识的全面性。
3.2 医学指令数据集(MedC-I)
在知识注入后,进一步举行指令微调。数据来源包罗:
医学问答(QA)
:基于 MedMCQA、PubMedQA 等数据集,加强推理本领。
医学对话
:收罗医生-患者对话数据,提升模型对话本领。
医学知识图谱
:使用 UMLS 医学知识图谱,加强模型的实体识别和关系推理本领。
终极,构建了一个包罗
202M tokens
的医学指令数据集。
4. 练习
PMC-LLaMA 的练习分为两个阶段
:
1)知识注入阶段(Data-centric Knowledge Injection)
:
使用医学文献构建医学知识库,使模型掌握基础医学知识。
在
MedC-K
数据集上采用
自回归损失
举行练习,练习
5轮
,批量大小 3200,使用 32 张 A100 GPU。
2)医学指令微调(Medical-specific Instruction Tuning)
:
使用医学指令集微调模型,以适应临床对话、医学推理和问答任务。
在
MedC-I
数据集上举行
3轮练习
,批量大小 256,使用 8 张 A100 GPU。
采用全分片数据并行(Fully Sharded Data Parallel,FSDP)和 bf16 数据格式,优化练习服从。
5. 实行与评估
5.1 评测基准
采用 3 个医学问答数据集:
PubMedQA
(基于生物医学论文)
MedMCQA
(印度医学考试题库)
USMLE
(美国医学执照考试题库)
5.2 结果分析
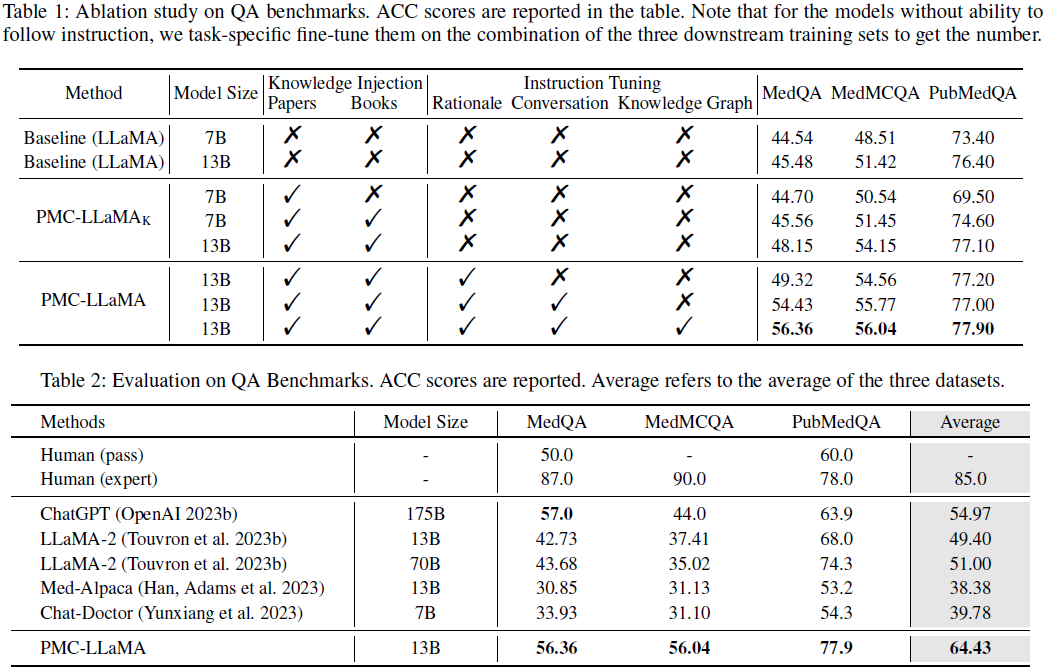
1)消融实行
仅使用 LLaMA 基础模型,MedQA 准确率:
45.48
举行
知识注入
后,MedQA 准确率提升至
48.15
加入
指令微调
后,MedQA 准确率进一步提升至
49.32
联合
医学对话和知识图谱
后,终极达到
56.36
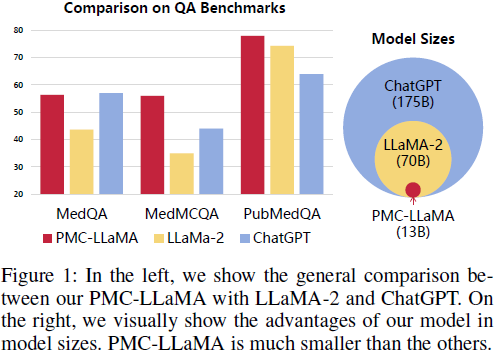
2)模型对比
PMC-LLaMA 在多个医学 QA 数据集上
超越ChatGPT
,且模型体积更小(13B vs 175B)。
论文地点:
https://arxiv.org/abs/2304.14454
项目页面:
https://github.com/chaoyi-wu/PMC-LLaMA
进 Q 学术交流群:922230617 或加 V:CV_EDPJ 进 V 交流群
免责声明:如果侵犯了您的权益,请联系站长,我们会及时删除侵权内容,谢谢合作!更多信息从访问主页:qidao123.com:ToB企服之家,中国第一个企服评测及商务社交产业平台。
欢迎光临 qidao123.com技术社区-IT企服评测·应用市场 (https://dis.qidao123.com/)
Powered by Discuz! X3.4