IT评测·应用市场-qidao123.com
标题: 端到端SOTA!上交提出DriveTransformer:以Decoder为焦点的大一统架构(ICL [打印本页]
作者: 前进之路 时间: 2025-3-17 15:57
标题: 端到端SOTA!上交提出DriveTransformer:以Decoder为焦点的大一统架构(ICL
点击下方卡片,关注“主动驾驶之心”公众号
戳我-> 领取主动驾驶近15个方向学习路线
今天主动驾驶之心为大家分享上海交通大学严骏驰组中稿ICLR 2025的最新工作—DriveTransformer!以Decoder为焦点的类GPTScalable大一统端到端主动驾驶架构。假如您有相关工作必要分享,请在文末接洽我们!
主动驾驶课程学习与技术交流群事宜,也接待添加小助理微信AIDriver004做进一步咨询
>>点击进入→主动驾驶之心『端到端主动驾驶』技术交流群
论文作者 | Xiaosong Jia等
编辑 | 主动驾驶之心
写在前面 & 笔者的个人理解
当前端到端主动驾驶架构的串行设计导致训练稳定性标题,而且高度依靠于BEV,严重限定了其Scale Up潜力。在我们ICLR2025工作DriveTransformer中,不同于以往算法Scale Up Vision Backbone,我们设计了一套以Decoder为焦点的无需BEV的大一统架构。在Scale Up提出的类GPT式并行架构后,我们发现训练稳定性大幅进步,并且增长参数量对于决议的收益优于Scale Up Encoder。在大规模的闭环实行中,通过Scale Up新架构到0.6B,我们实现了SOTA效果。本篇论文三位共一中的游浚琦和张致远在参与本项目时分别为大二、大三的本科生。
端到端主动驾驶(E2E-AD)已成为主动驾驶领域的一种趋势,有望为系统设计提供一种数据驱动且可扩展的方法。然而现有的端到端主动驾驶方法通常采用感知 - 预测 - 规划的序次范式,这会导致累积毛病和训练不稳定性。使命的手动排序也限定了系统利用使命间协同效应的能力(比方,具有规划感知的感知以及基于博弈论的交互式预测和规划)。此外现有方法采用的dense BEV表示在大范围感知和长时序融合方面带来了计算挑战。为应对这些挑战,我们提出了DriveTransformer,这是一种简化的易于扩展的端到端主动驾驶框架,具有三个关键特性:使命并行(全部Agent、舆图和规划查询在每个模块中直接相互交互)、希罕表示(使命查询直接与原始传感器特性交互)和流处理(使命查询作为历史信息存储和通报)。因此,新框架由三个统一操作组成:使命自注意力、传感器交错注意力和时序交错注意力,这明显降低了系统的复杂性,并带来了更好的训练稳定性。DriveTransformer在模拟闭环基准测试Bench2Drive和现实世界开环基准测试nuScenes中均实现了开始进的性能,且帧率较高。
简介
比年来,主动驾驶不停是备受关注的话题,该领域也取得了明显希望。此中最令人兴奋的方法之一是端到端主动驾驶(E2E-AD),其目标是将感知、预测和规划集成到一个框架中。端到端主动驾驶因其数据驱动和可扩展的特性而极具吸引力,可以或许通过更多数据实现持续改进。
只管具有这些优势,但现有的端到端主动驾驶方法大多采用感知 - 预测 - 规划的序次流程,此中鄙俚使命严重依靠于上游查询。这种序次设计可能导致累积毛病,进而导致训练不稳定。比方,UniAD的训练过程必要采用多阶段方法:首先,预训练BEVFormer编码器;然后,训练TrackFormer和MapFormer;最后,训练MotionFormer和规划器。这种分段式的训练方法增长了在工业环境中摆设和扩展系统的复杂性和难度。此外,使命的手动排序可能会限定系统利用协同效应的能力,比方具有规划感知的感知以及基于博弈论的交互式预测和规划。
现有方法面临的另一个挑战是现实世界的时空复杂性。基于鸟瞰图(BEV)的表示由于BEV网格的密集性,在更大范围上的检测方面遇到计算挑战。此外,由于梯度信号较弱,基于BEV方法的图像骨干网络未得到充分优化,这阻碍了它们的扩展能力。在时序融合方面,基于BEV的方法通常存储历史BEV特性举行融合,这在计算上也非常耗时。总之,基于BEV的方法忽略了3D空间的希罕性,丢弃了每一帧的使命查询,这导致了大量的计算浪费,从而影响了服从。
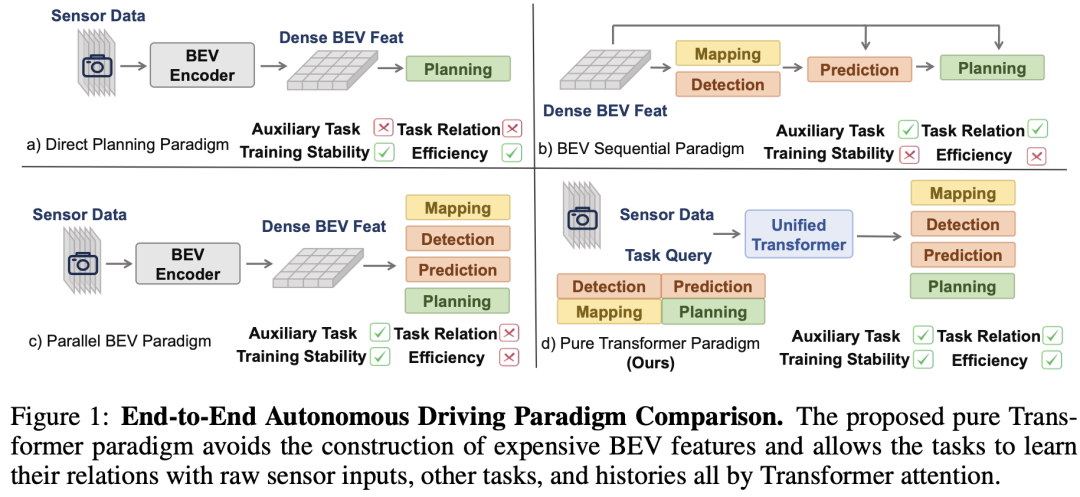
最新的工作ParaDrive试图通过堵截全部使命之间的毗连来缓解不稳定性标题。然而,它仍旧受到昂贵的BEV表示的困扰,并且其实行仅限于开环,无法反映实际的规划能力。为办理这些不足,我们引入了DriveTransformer,这是一个高效且可扩展的端到端主动驾驶框架,具有图2所示的三个关键属性:
- 使命并行:全部使命查询在每个模块中直接相互交互,促进跨使命知识转移,同时在没有明确层次结构的环境下保持系统稳定。
- 希罕表示:使命查询直接与原始传感器特性交互,提供了一种高效直接的信息提取方式,符合端到端优化范式。
- 流处理:时序融合通过先进先出队列实现,该队列存储历史使命查询,并通过时序交错注意力举行融合,确保服从和特性重用。
DriveTransformer为端到端主动驾驶提供了一种统一、并行和协同的方法,便于训练和扩展。因此,DriveTransformer在CARLA模拟下的Bench2Drive中实现了开始进的闭环性能,在nuScenes数据集上实现了开始进的开环规划性能。
相关工作回顾
端到端主动驾驶(E2E-AD)的概念可以追溯到20世纪80年代。CIL训练了一个简单的卷积神经网络(CNN),将前视相机图像直接映射到控制下令。CILRS对其举行了改进,引入了一个辅助使命来预测主动驾驶车辆的速率,办理了与惯性相关的标题。PlanT方法发起在教师模型中利用Transformer架构,而LBC则专注于利用特权输入对教师模型举行初始训练。今后,Zhang等人等研究开始探索强化学习以创建驾驶策略。在这些希望的底子上,学生模型得以开辟。在随后的研究中,多传感器的利用变得广泛,提升了模型的能力。Transfuser利用Transformer来融合相机和激光雷达数据。LAV采用了PointPainting技术,Interfuser将安全增强规则纳入决议过程。进一步的创新包罗MMFN利用VectorNet举行舆图编码,以及ThinkTwice为学生模型引入类似DETR的可扩展解码器范式。ReasonNet提出了专门的模块来改进对时序和全局信息的利用,而Jaeger等人则提出了一种基于分类的方法来处理学生模型的输出,以减轻均匀化标题。
在另一个明确举行主动驾驶子使命的分支中,ST-P3将检测、预测和规划使命集成到一个统一的鸟瞰图(BEV)分割框架中。此外,UniAD利用Transformer毗连不同使命,VAD提出了矢量化表示空间。ParaDrive去除了全部使命之间的毗连,而BEVPlanner则去除了全部中心使命。与我们的工作同期,还有基于希罕查询的方法。然而,它们仍旧遵照序次流程,而本文提出的DriveTransformer将全部使命统一到并行Transformer范式中。
详解DriveTransformer
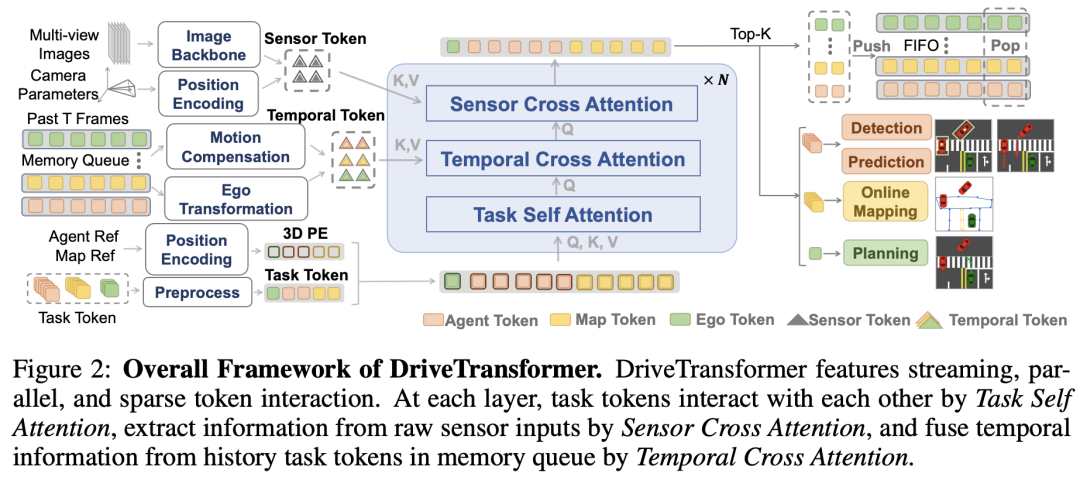
给定原始传感器输入(比方多视图图像),DriveTransformer旨在输出多个使命的效果,包罗目标检测、运动预测、在线舆图构建和路径规划。每个使命由其相应的查询处理,这些查询直接相互交互,从原始传感器输入中提取信息,并整合历史信息。算法框架如图2所示。
初始化与标记化
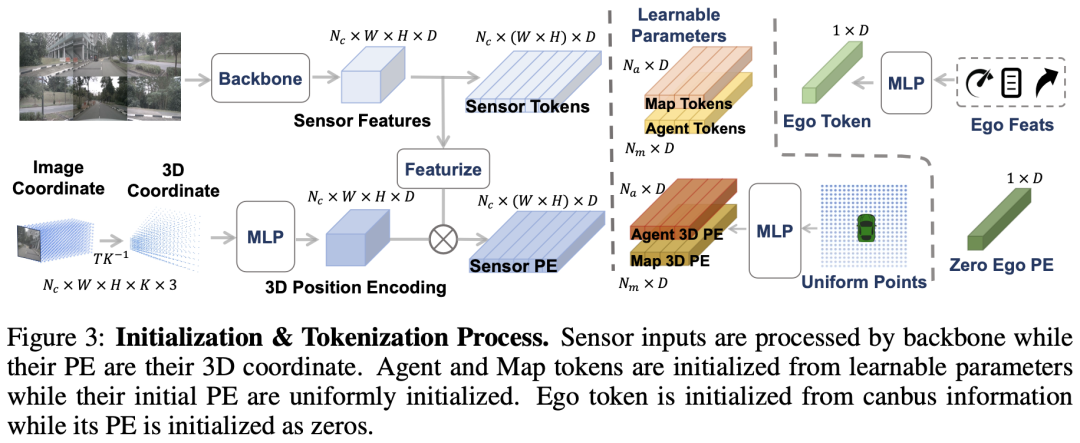
在DriveTransformer举行信息交换之前,全部输入都被转换为统一的表示形式——标记(token)。受DAB-DETR的启发,全部标记由两部门组成:用于语义信息的语义嵌入和用于空间定位的位置编码。在图3中,我们展示了该过程,并在下面具体说明。
- 传感器标记:来自周围相机的多视图图像由诸如ResNet的骨干网络分别编码为的语义嵌入,此中是相机的数量,和是分块后特性图的高度和宽度,是隐藏维度。为了编码传感器特性的位置信息,我们采用中的3D位置编码。具体来说,对于每个像素坐标为的图像块,其在3D空间中的对应光线可以用个等间距的3D点表示:,此中和分别是相机的外参矩阵和内参矩阵,是第个3D点的深度值。然后,将同一光线中各点的坐标毗连起来,并输入到多层感知器(MLP)中,以得到每个图像块的位置编码,全部图像块的3D位置编码表示为。
- 使命标记:为了对异构驾驶场景举行建模,初始化了三种范例的使命查询以提取不同信息:(I)Agent查询代表动态对象(车辆、行人等),将用于举行目标检测和运动预测。(II)舆图查询代表静态元素(车道、交通标记等),将用于举行在线舆图构建。(III)自车查询代表车辆的潜在行为,将用于举行路径规划。遵照DAB-DETR,Agent查询和舆图查询的语义嵌入均随机初始化为可学习参数和,此中和是Agent查询和舆图查询的数量,为预定义超参数。它们的位置编码和在预定义的感知范围内均匀初始化。对于规划查询,其语义嵌入类似于BEVFormer,通过MLP对车载总线信息举行编码得到,而其位置编码初始化为零。
标记交互
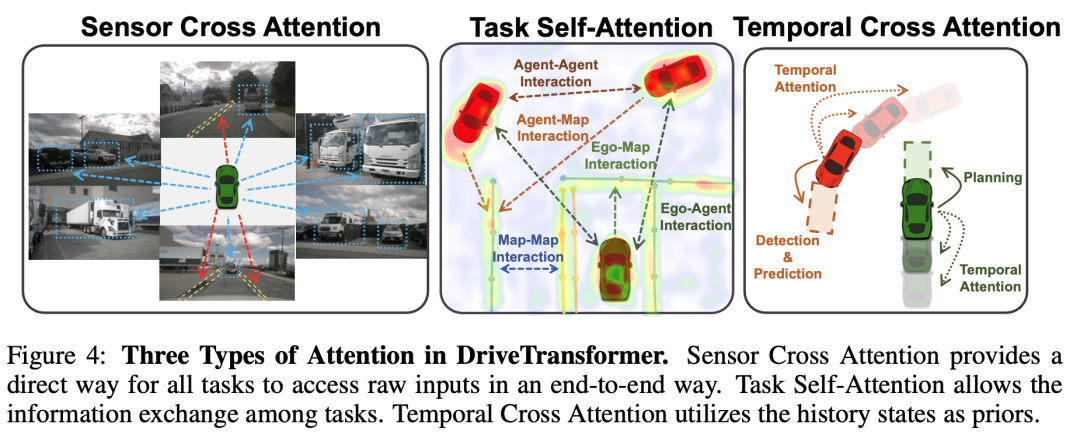
DriveTransformer中的全部信息交换均由标准注意力机制建立,确保了可扩展性和易于摆设。因此,该模型可以在一个阶段内举行训练,并体现出强盛的可扩展性,这将在实行部门展示。在以下小节中,我们描述DriveTransformer每一层采用的三种信息交换范例,如图4所示。
- 传感器交错注意力(SCA):在使命和原始传感器输入之间建立了直接路径,实现了端到端学习且无信息损失。SCA的计算方式为:
此中表示更新后的查询。通过这种方式,原始传感器标记根据语义和空间关系与使命查询举行匹配,以端到端的方式提取特定使命信息,且无信息损失。值得注意的是,通过采用3D位置编码,DriveTransformer避免了构建BEV特性,这种方式高效且梯度消失标题较少,有利于模型扩展。
- 使命自注意力(TSA):实现了任意使命之间的直接交互,没有明确的束缚,促进了诸如具有规划感知的感知和基于博弈论的交互式预测和规划等协同效应。TSA的计算方式为: [] 通过消除手动设计的使命依靠关系,使命之间的交错关系可以通过注意力以数据驱动的方式灵活学习,这有助于模型扩展。相比之下,UniAD由于训练早期阶段的不划一性,不得不采用多阶段训练策略,因为不准确的上游模块会影响鄙俚模块,最终导致整个训练瓦解。
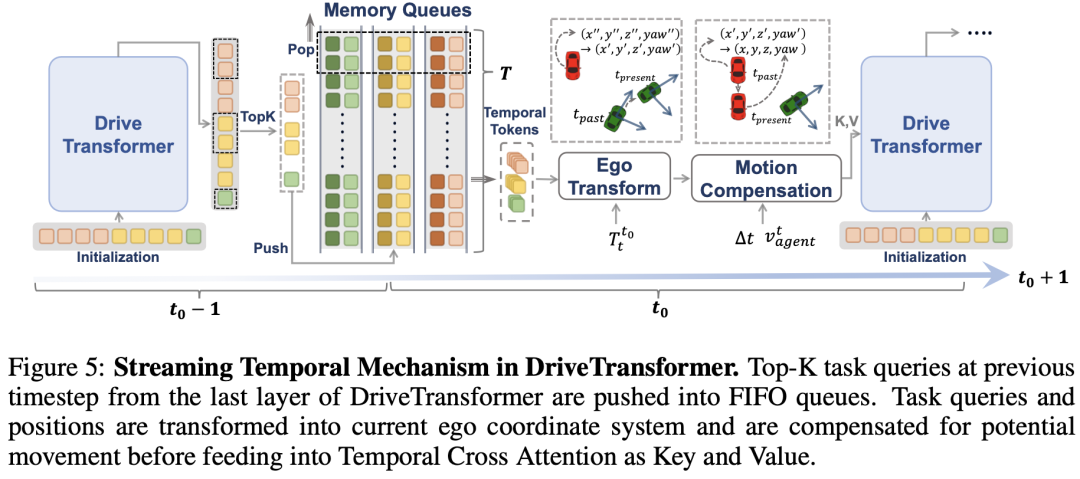
- 时序交错注意力:整合了先前观察到的历史信息。现有范式利用历史BEV特性来通报时序信息,这带来了两个缺点:(a)维护恒久BEV特性资本高昂;(b)先前携带强先验语义和空间信息的使命查询被浪费性地丢弃。受StreamPETR的启发,DriveTransformer分别为每个使命维护先进先出(FIFO)查询队列,并在每一层对队列中的历史查询举行交错注意力计算,以融合时序信息,如图5所示。
具体来说,将、、及其相应的位置编码、、表示为DriveTransformer在时序步时最后一层的自车查询、Agent查询和舆图查询。假设当前时序步为,我们维护FIFO队列、和,此中是一个预设超参数,用于控制时序队列的长度。在每个时序步之后,当前最后一层的使命查询被推送到队列中,而时刻的使命查询被弹出。此外,由于DETR风格的方法中存在冗余查询,对于Agent和舆图查询,只保留那些置信度得分在前的查询,此中是一个超参数。时序交错注意力将历史查询作为键(Key)和值(Value)。由于不同时序步的自车参考点可能不同,历史查询的位置编码(PE)被转换到当前坐标系(自车转换):
此中
此中是转换后的位置编码,是从时序步到的坐标转换矩阵。此外,由于其他Agent可能有本身的运动,我们举行DiT风格的自适应层归一化(ada-LN)用于运动赔偿:
此中
此中层归一化的权重和毛病由时序步时Agent的预测速率和时序步与当前时序步之间的时序隔断控制。此外,我们还将相对时序嵌入设置为以表示不同的时序步,时序交错注意力的计算方式为:
此中
- 纯注意力架构:总之,DriveTransformer是由多个模块堆叠而成,每个模块包含上述三种注意力机制和一个前馈神经网络(FFN):
此中和是层索引,FFN指Transformer中的MLP,为简洁起见,我们省略了位置编码、残差毗连和预层归一化。请注意,原始传感器标记和历史信息、、在全部模块中共享。
基于DETR的使命头设计
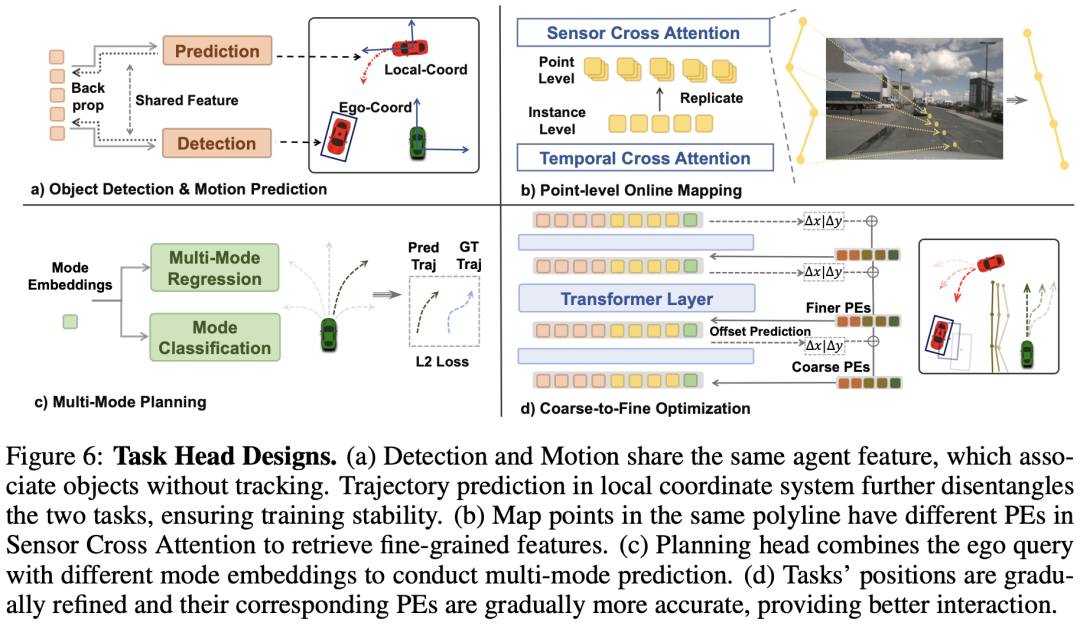
受DETR启发,在每个模块后设置使命头,逐步优化预测效果,同时位置编码(PE)也会相应更新。接下来的部门将先容各使命的具体设计和PE的更新策略,如图6所示。
- 目标检测与运动预测:现有的端到端方法仍采用经典的检测 - 关联 - 预测流程,由于关联过程本身的复杂性,这种流程会给训练带来不稳定性。比方在UniAD中,必须先对用于3D目标检测的BEVFormer举行预训练,以避免TrackFormer训练发散,并且在对MotionFormer和规划头举行端到端训练之前,必须先训练MapFormer和TrackFormer,这就导致其必要采用多阶段训练策略,从而限定了模型的扩展性。
为办理这一标题,DriveTransformer采用了更端到端的方法:不举行跟踪,而是将相同的Agent查询输入到不同的使命头中,以此举行目标检测和运动预测。同一Agent的相同特性会天然地在检测和预测使命之间建立关联。在时序关联方面,由于时序交错注意力机制是在当前标记和全部历史标记之间举行计算的,因此避免了显式的关联操作,取而代之的是基于学习的注意力机制。为进一步进步训练稳定性并镌汰这两个使命之间的干扰,运动预测的标签会被转换到每个Agent的局部坐标系中,这样其损失就完全不受检测效果的影响。只有在推理时,才会根据检测效果将预测的路径点转换到全局坐标系中,用于计算与运动预测相关的指标。
- 在线舆图构建:该领域近期的研究希望表明,由于舆图折线分布的不规则性和多样性,点级特性检索比实例级特性检索更为重要。因此,在举行传感器交错注意力计算时,我们将每个舆图查询复制次,并为每个单点分配相应的位置编码。这样,对于较长的折线,每个点都能更好地检索原始传感器信息。为了将单独的点级舆图查询整合为实例级查询,供其他模块利用,我们采用了带有最大池化层和多层感知器(MLP)的轻量级PointNet。
- 路径规划:我们将主动驾驶车辆的未来运动建模为高斯混合模型,以避免模式均匀标题,这在运动预测领域是一种常用的方法。具体来说,我们根据轨迹的方向和距离,将全部训练轨迹分为六类:直行、停车、左转、急左转、右转、急右转。为生成这些模式的轨迹,我们通过将正弦和余弦编码的位置输入到MLP中,生成六个模式嵌入,然后将它们添加到车辆自身特性中,以预测六种特定模式下的车辆轨迹。在训练过程中,只有与真实模式对应的轨迹才会用于计算回归损失,即采用赢家通吃的策略,同时我们还训练一个分类头来预测当前模式。在推理时,具有最高置信度得分的模式所对应的轨迹将用于计算指标或执行。
- 从粗到精优化:DETR系列的成功证实了从粗到精的端到端学习优化方法的有效性。在DriveTransformer中,全部使命查询的位置编码(PE)会在每个模块后根据当前预测效果举行更新。具体而言,舆图和Agent的位置编码会通过MLP,根据其预测位置和语义类别举行编码,以捕获元素之间的空间和语义关系。车辆自身的位置编码则通过MLP,根据预测的规划轨迹举行编码,以捕获车辆的意图,便于后续可能的交互。与DETR类似,在训练过程中,全部模块的使命头都会计算损失,而在推理时,我们只利用最后一个模块的输出效果。
损失函数与优化
DriveTransformer采用单阶段训练方式,在这种方式下,各个使命可以在使命自注意力机制中逐渐学习相互之间的关系,同时在传感器交错注意力和时序交错注意力机制的作用下,不会影响彼此的根本收敛。模型包含检测损失(基于DETR的匈牙利匹配损失)、预测损失(赢家通吃式损失)、在线舆图构建损失(基于MapTR的匈牙利匹配损失)以及路径规划损失(赢家通吃式损失)。我们通过调整权重,确保全部损失项的量级都在1左右,整体损失函数如下:
实行效果分析
数据集与基准测试
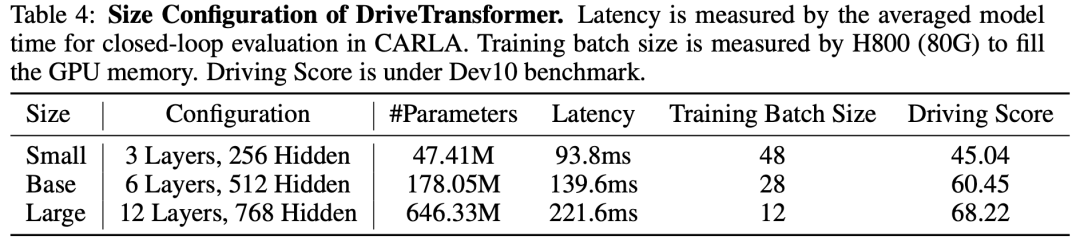
我们利用Bench2Drive,这是一种基于CARLA Leaderboard 2.0的端到端主动驾驶闭环评估协议。它提供了一个官方训练集,为了与全部其他基线方法举行公平比较,我们利用其底子集(1000个片段)。我们利用官方的220条路线举行评估。此外,我们还在nuScenes开环评估中,将我们的方法与其他开始进的基线方法举行比较。DriveTransformer有三种不同规模的模型:
在与开始进的方法举行比较时,我们报告DriveTransformer-Large的效果。在举行溶解研究时,由于在Bench2Drive的220条路线上举行评估可能必要数天时序,我们选择10个具有代表性的场景(即Dev10),这些场景均衡了不同的行为、天气和城镇环境,并报告DriveTransformer-Base在这些场景上的效果,以便快速验证。
与SOTA对比
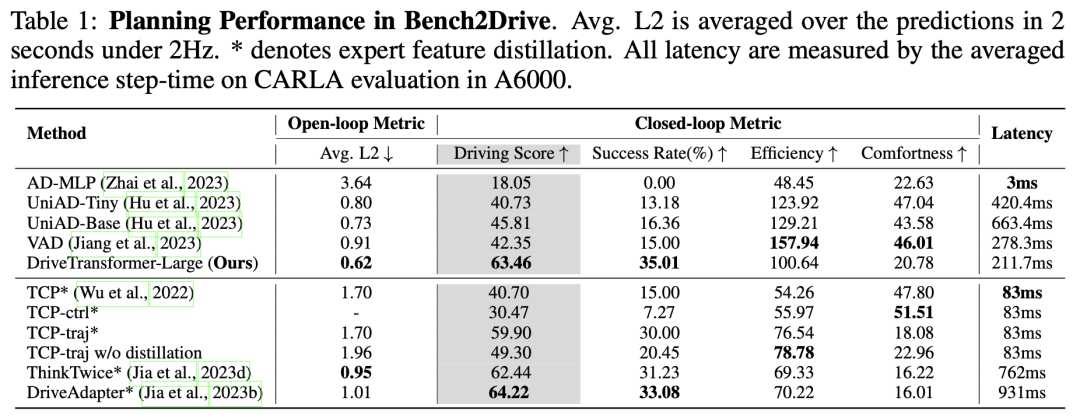
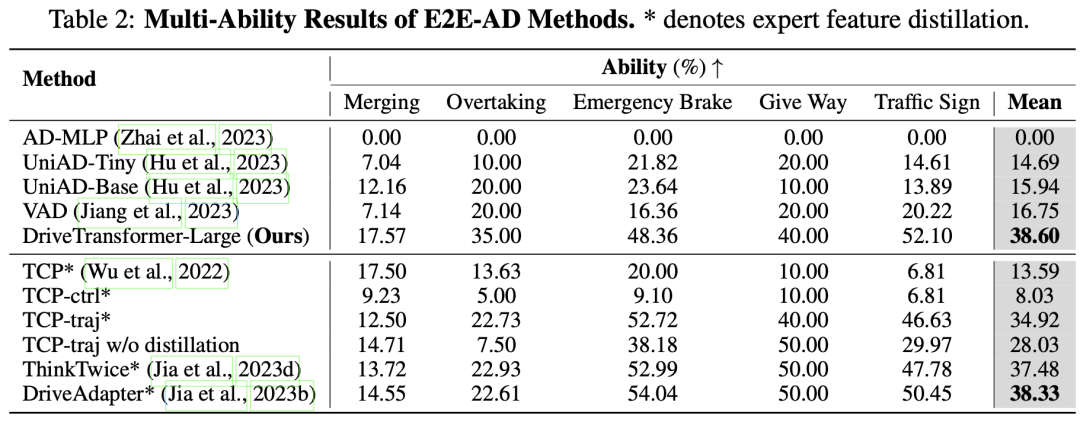
我们在表1、表2和表3中将DriveTransformer与开始进的端到端主动驾驶方法举行比较。可以观察到,DriveTransformer始终优于其他开始进的方法。从表1中可以看出,与UniAD和VAD相比,DriveTransformer的推理延迟更低。值得注意的是,由于采用了统一、希罕和流式的Transformer设计,DriveTransformer在H800(80G)上训练时的批次巨细可以达到12,而UniAD的批次巨细为1,VAD的批次巨细为4。
溶解研究
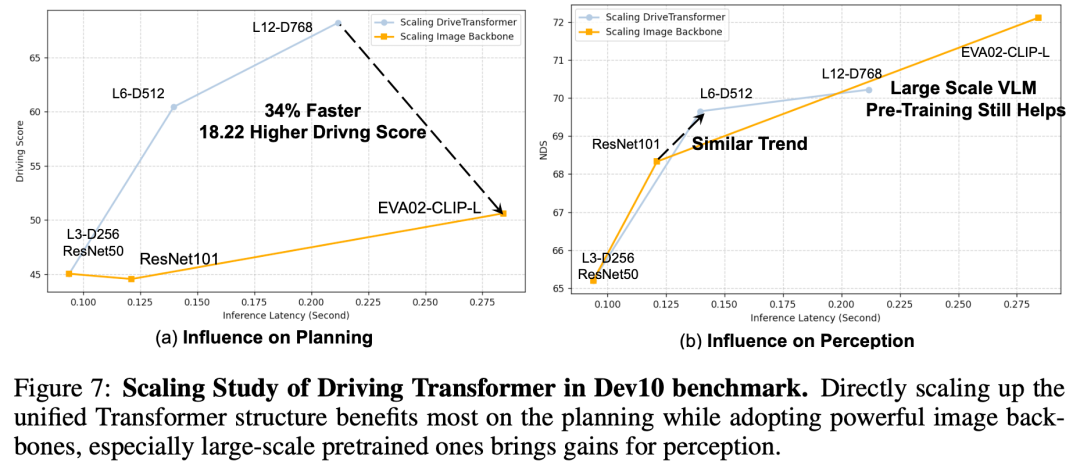
- 缩放研究:基于Transformer的范式具有极强的可扩展性。由于DriveTransformer由Transformer构成,我们研究了同时增长层数和隐藏层维度时的缩放行为,并将该策略与类似中缩放图像骨干网络的策略举行比较,效果如图7所示。可以观察到,与缩放图像骨干网络相比,扩大解码器部门(即三种注意力机制的层数和宽度)能带来更多收益。这很天然,因为前者直接为规划使命增长了更多计算量。另一方面,对于感知使命,扩大解码器与扩大图像骨干网络的效果趋势相似,这证实了DriveTransformer的泛化能力。然而,它仍掉队于大规模视觉语言预训练的图像骨干网络——EVA02-CLIP-L,这与中的发现划一。研究如何将视觉语言模型(VLLM)与主动驾驶相结合,可能是一个重要的研究方向。
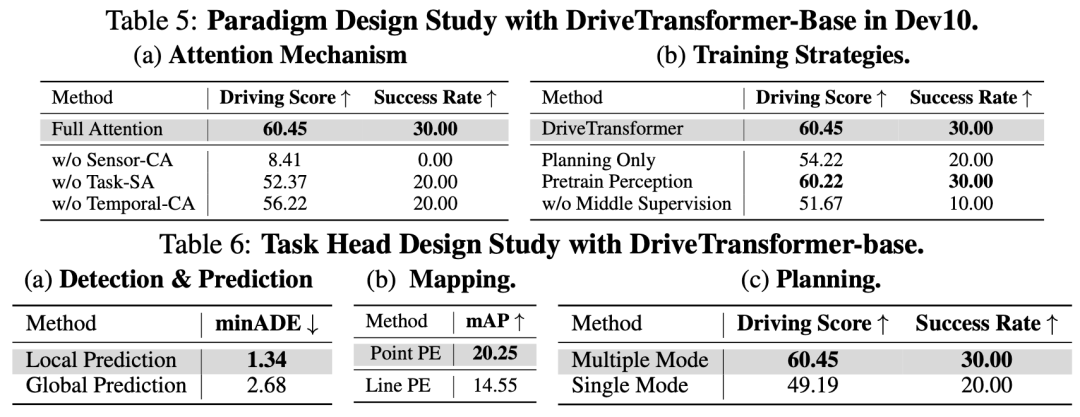
- 范式设计研究:在表5中,我们对DriveTransformer的设计举行了溶解研究。可以得出以下结论:❶基于表5a,三种注意力机制都有帮助。❷传感器交错注意力尤为重要,因为没有传感器信息,模型就会盲目驾驶。❸时序信息的影响最。❹使命自注意力可以进步驾驶得分,因为自车查询可以利用检测到的物体和舆图元素举行规划。❺基于表5b,我们发现丢弃辅助使命会导致性能下降,这可能是因为用高维输入(周围相机图像)去拟合单一的规划输出相称困难。实际上,在端到端主动驾驶领域,采用辅助使命来规范学习到的表示是一种常见做法。❻单阶段训练足以使模型收敛,而感知预训练(即两阶段训练)并没有优势。这源于使命之间没有手动设定的依靠关系,因此全部使命都可以首先从原始传感器输入和历史信息中学习,而不会相互影响收敛。❼作为一个复杂的基于Transformer的框架,我们发现去除中心层的监督会导致训练瓦解。可能必要进一步探索如何仅依靠最终监督来扩展模型结构。
- 使命设计研究:在表6中,我们对使命头的设计举行了溶解研究,得出以下结论:❶对于表6a,在局部坐标系中制定预测输出,解耦了目标检测和运动预测。效果,这两个使命可以分别优化各自的目标,而共享的输入Agent特性天然地关联了同一Agent。杰出的性能证实了避免直接在全局坐标系中举行预测的有效性。❷对于表6b,传感器交错注意力中的点级位置编码在在线舆图构建中能带来显着更好的效果,这表明扩展车道检测的潜在感知范围是有效的。❸对于表6c,多模式规划显着优于单模式规划。通过可视化,我们观察到多模式规划在必要微调转向的场景中能实现更好的控制。这是因为利用L2损失的单模预测将输出空间建模为单一的高斯分布,因此会受到模式均匀的影响。

主动驾驶作为一项户外使命,常常会遇到各种事件和故障,因此观察系统的鲁棒性是一个重要的研究方向。为此,我们采用了中的4种设置:❶相机故障:将两个相机遮罩为全黑。❷标定错误:在相机外参中添加旋转和平移噪声。❸运动含糊:对图像应用运动含糊。❹高斯噪声:对图像添加高斯噪声。从表7和表8可以看出,与VAD相比,DriveTransformer体现出明显更好的鲁棒性。这可能是因为VAD必要构建鸟瞰图(BEV)特性,而该特性对感知输入较为敏感。另一方面,DriveTransformer直接与原始传感器特性交互,因此可以或许忽略那些故障或有噪声的输入,从而体现出更好的鲁棒性。
结论
在本研究中,我们提出了DriveTransformer,这是一种基于统一Transformer架构的端到端主动驾驶范式,具有使命并行、流处理和希罕表示的特点。它在CARLA闭环评估的Bench2Drive和nuScenes开环评估中均达到了开始进的性能,且帧率较高,证实了这些设计的有效性。然而,与现有的端到端主动驾驶系统类似,DriveTransformer将全部子使命的更新交错在一起,给整个系统的维护带来了挑战。一个重要的未来研究方向是降低它们之间的耦合度,使其更易于分别调试和维护。
① 主动驾驶论文辅导来啦
② 国内首个主动驾驶学习社区
『主动驾驶之心知识星球』近4000人的交流社区,已得到大多数主动驾驶公司的认可!涉及30+主动驾驶技术栈学习路线,从0到一带你入门主动驾驶感知(端到端主动驾驶、世界模型、仿真闭环、2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、主动驾驶定位建图(SLAM、高精舆图、局部在线舆图)、主动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!接待扫描加入
③全网独家视频课程
端到端主动驾驶、仿真测试、主动驾驶C++、BEV感知、BEV模型摆设、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精舆图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型摆设、大模型与主动驾驶、NeRF、语义分割、主动驾驶仿真、传感器摆设、决议规划、轨迹预测等多个方向学习视频(扫码即可学习)
网页端官网:www.zdjszx.com ④【主动驾驶之心】全平台矩阵
免责声明:如果侵犯了您的权益,请联系站长,我们会及时删除侵权内容,谢谢合作!更多信息从访问主页:qidao123.com:ToB企服之家,中国第一个企服评测及商务社交产业平台。
| 欢迎光临 IT评测·应用市场-qidao123.com (https://dis.qidao123.com/) |
Powered by Discuz! X3.4 |