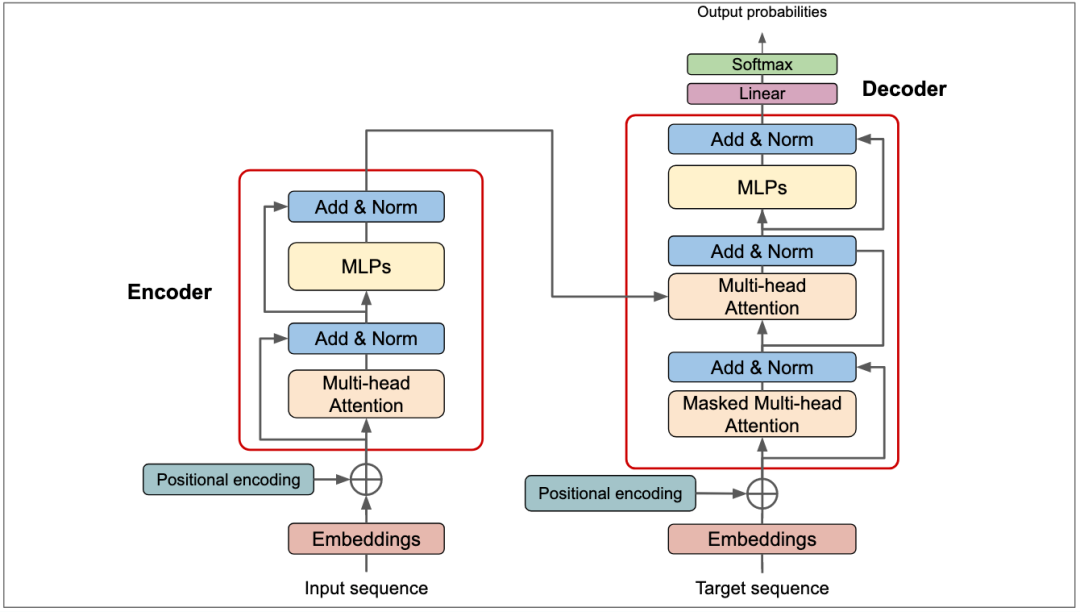
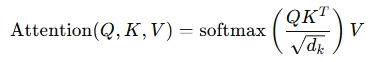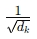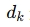近年来,人工智能(AI)已从传统机器学习迈向大模子(Large Language Models, LLM)的时代,无论是在自然语言处理(NLP),还是在多模态(如图像、语音、视频)领域,Transformer架构主导的大模子都展现出强大的泛化本领和跨任务迁移性能,对于想要在企业或研究中使用这些模子的人来说,明白大模子的内部原理、训练方式与推理过程并非可有可无,而是能在现实摆设与优化中带来关键的指导意义。
因此,作为一个体系架构筹划师而言,当我们审视当代AI大模子时,怎样从整体体系筹划的角度明白这些大模子的内部机制、训练流程以及推理过程,就显得尤为关键。
对环球大模子从性能、吞吐量、资本等方面有一定的认知,可以在云端和本地等多种环境下摆设大模子,找到恰当自己的项目/创业方向,做一名被 AI 武装的产品司理。
硬件选型
带你了解环球大模子
使用国产大模子服务
搭建 OpenAI 代理
热身:基于阿里云 PAI 摆设 Stable Diffusion
在本地计算机运行大模子
大模子的私有化摆设
基于 vLLM 摆设大模子
案例:怎样优雅地在阿里云私有摆设开源大模子
摆设一套开源 LLM 项目
内容安全
互联网信息服务算法存案
…
学习是一个过程,只要学习就会有挑战。天道酬勤,你越积极,就会成为越优秀的自己。
假如你能在15天内完成所有的任务,那你堪称天才。然而,假如你能完成 60-70% 的内容,你就已经开始具备成为一名大模子 AI 的正确特征了。
这份完备版的大模子 AI 学习资料已经上传CSDN,朋侪们假如必要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】