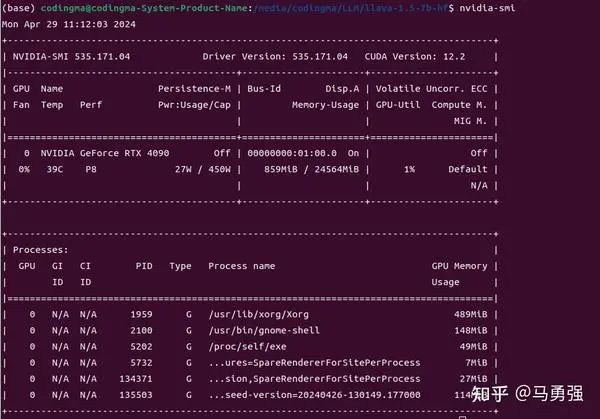
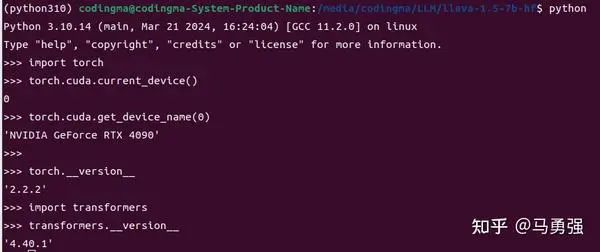
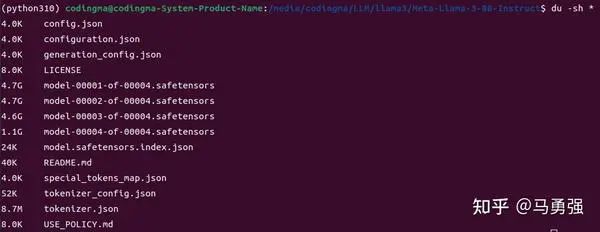
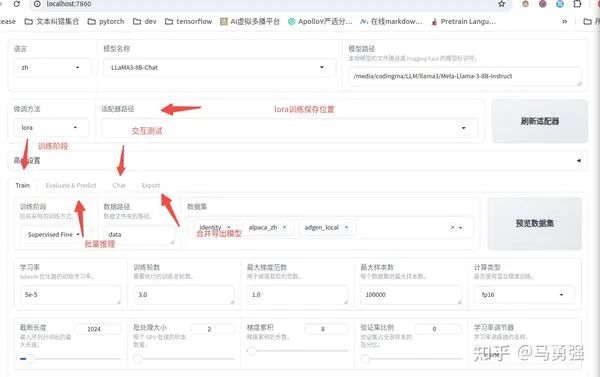
在进行后续的环节之前,我们先使用推理模式,先验证一下LLaMA-Factory的推理部分是否正常。LLaMA-Factory 带了基于gradio开辟的ChatBot推理页面, 帮助做模型效果的人工测试。在LLaMA-Factory 目录下实行以下下令
本脚本参数参考自LLaMA-Factory/examples/inference/llama3.yaml at main · hiyouga/LLaMA-Factory [3]
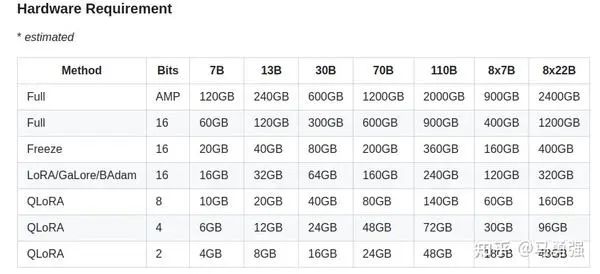
在预备好数据集之后,我们就可以开始预备训练了,我们的目标就是让原来的LLaMA3模型可以或许学会我们定义的“你是谁”,同时学会我们盼望的商品文案的一些天生。
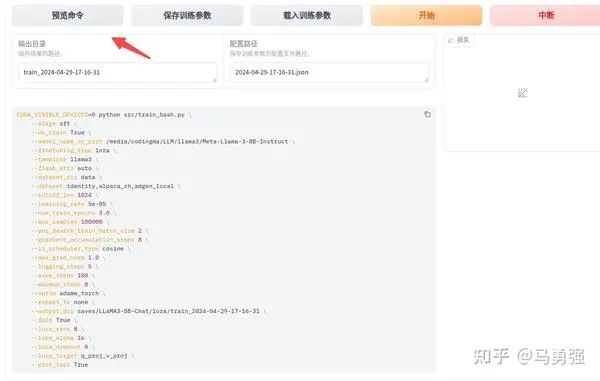
这里我们先使用下令行版本来做训练,从下令行更容易学习相关的原理。
本脚本参数改编自
LLaMA-Factory/examples/train_lora/llama3_lora_sft.yaml at main · hiyouga/LLaMA-Factory[8]
本脚本参数改编自
LLaMA-Factory/examples/inference/llama3_lora_sft.yaml at main · hiyouga/LLaMA-Factory[9]
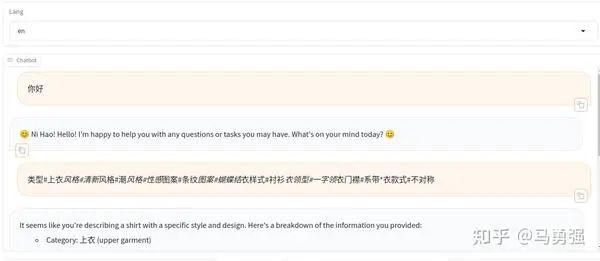
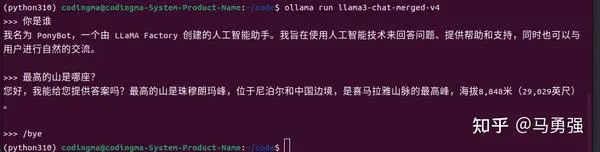
当基于LoRA的训练进程结束后,我们如果想做一下动态验证,在网页端里与新模型对话,与步调4的原始模型直接推理相比,唯一的区别是必要通过finetuning_type参数告诉系统,我们使用了LoRA训练,然后将LoRA的模型位置通过 adapter_name_or_path参数即可。
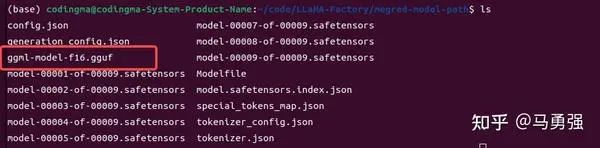
如果想把训练的LoRA和原始的大模型进行融合,输出一个完备的模型文件的话,可以使用如下下令。归并后的模型可以自由地像使用原始的模型一样应用到其他卑鄙环节,固然也可以递归地继承用于训练。
本脚本改编自
LLaMA-Factory/examples/inference/llama3_lora_sft.yaml at main · hiyouga/LLaMA-Factory[12]
`import os from openai import OpenAI from transformers.utils.versions import require_version require_version("openai>=1.5.0", "To fix: pip install openai>=1.5.0") if __name__ == '__main__': # change to your custom port port = 8000 client = OpenAI( api_key="0", base_url="http://localhost:{}/v1".format(os.environ.get("API_PORT", 8000)), ) messages = [] messages.append({"role": "user", "content": "hello, where is USA"}) result = client.chat.completions.create(messages=messages, model="test") print(result.choices[0].message)`