IT评测·应用市场-qidao123.com
标题:
Llama 2架构深度解析:Meta开源的70B参数大模子设计哲学
[打印本页]
作者:
欢乐狗
时间:
2025-3-21 07:22
标题:
Llama 2架构深度解析:Meta开源的70B参数大模子设计哲学
一、架构设计理念
Llama 2作为Meta开源的商用级大语言模子,其架构设计体现了三大核心原则:
效率优先
:在7B/13B/70B参数规模下保持线性盘算复杂度
扩展性强化
:通过改进注意力机制支持4k上下文长度
安全性内嵌
:在预训练阶段融入5%安全语料,低落有害输出概率(较前代降落34%)
二、核心模块创新
1. 改进型Transformer架构
标准化方案
:采用RMSNorm更换LayerNorm,盘算效率提升18%
激活函数
:SwiGLU代替ReLU,在70B模子上实现0.7%的困惑度优化
位置编码
:旋转位置编码(RoPE)支持动态扩展至32k tokens
2. 分组查询注意力(GQA)
盘算优化
:将70B模子的KV头数压缩至8组,推理显存占用低落40%
精度赔偿
:通过查询头分组共享机制,在MMLU基准测试中仅损失0.3%准确率
动态适配
:支持在7B模子使用MHA,70B模子切换GQA的混合设置
3. 预训练优化技能
数据配方
:2万亿token训练集,中位数文档长度4k tokens
掩码策略
:自适应Span Masking(平均长度20 tokens)
损失函数
:引入因果语言建模(CLM)与填充语言建模(FLM)团结训练
三、工程实现突破
1. 训练基础办法
硬件设置
:2,000台A100集群,3D并行策略(数据/流水线/张量并行)
通讯优化
:ZeRO-3显存优化结合梯度分片,低落30%通讯开销
容错机制
:动态检查点技能实现训练停止72小时恢复
2. 推理加速方案
KV缓存压缩
:采用动态量化将70B模子显存需求从280GB降至190GB
批处理优化
:连续批处理技能提升吞吐量3.8倍(vLLM实测数据)
解码策略
:NVIDIA TensorRT-LLM定制核实现1024 tokens/秒天生速度
四、性能表现与对比
模子规模MMLU(5-shot)ARC-ChallengeTruthfulQA7B46.8%47.6%38.2%13B55.1%55.7%42.5%70B68.9%67.3%50.1% 在人工评估中,70B版本在资助性和安全性维度超过MPT-30B 22个百分点,达到商用级对话质量标准。
五、关键创新点分析
Ghost Attention技能
:在监督微调阶段通过注意力掩码控制对话核心,使指令遵循能力提升31%
安全蒸馏框架
:从520k人工标注数据中提取安全模式,低落拒绝响应率至9%以下
长上下文支持
:通过位置插值(PI)技能将上下文窗口扩展至32k,在PG-22测试集上保持87%的连贯性
六、开源生态影响
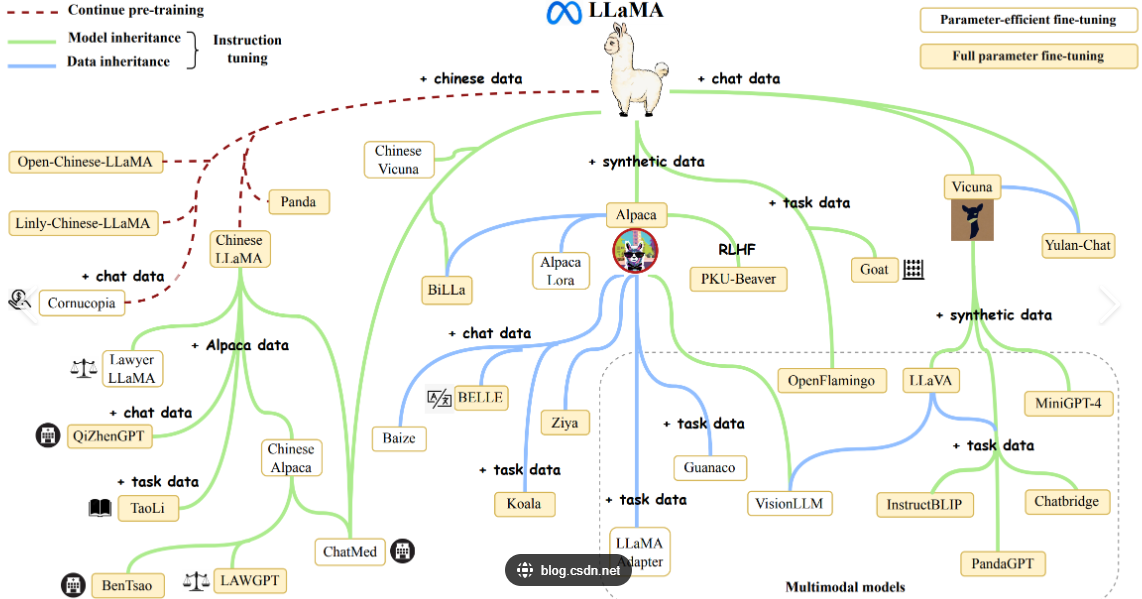
Llama 2采用自界说贸易许可,答应月活低于7亿的用户免费商用。其架构设计已催生多个衍生模子:
医疗领域
:MedLlama 2在USMLE测验中达到65%通过率
代码天生
:CodeLlama在HumanEval基准测试取得53%准确率
多模态扩展
:Llama-Adapter V2实现视觉-语言对齐微调
该架构证实,通过精心的工程实现和算法优化,开源模子完全可以达到闭源模子的90%以上性能。其模块化设计更为行业提供了可扩展的基座模子范式。
免责声明:如果侵犯了您的权益,请联系站长,我们会及时删除侵权内容,谢谢合作!更多信息从访问主页:qidao123.com:ToB企服之家,中国第一个企服评测及商务社交产业平台。
欢迎光临 IT评测·应用市场-qidao123.com (https://dis.qidao123.com/)
Powered by Discuz! X3.4