print("Chat with the model! Type 'exit' to end the conversation.")
prompt = "You are an Intelligent Traffic Rules Q&A Assistant, and when user ask you questions, you will provide me with traffic knowledge.Next, user will ask you questions, please answer them.\n"
# once_input = input("User1:")
#
# if once_input.lower() == 'exit':
# print("Assistant: Goodbye! Stay safe on the roads!")
(1) μ ^ = 1 d ∑ x i ∈ X x i \hat{\mu} = \frac{1}{d} \sum_{x^i\in X}x^i μ^=d1xi∈X∑xi
(2) σ ^ 2 = 1 d ∑ x i ∈ X ( x i − μ ) 2 + ϵ \hat{\sigma}^2 = \frac{1}{d} \sum_{x^i\in X}(x^i - \mu)^2 + \epsilon σ^2=d1xi∈X∑(xi−μ)2+ϵ
(3) L N ( X ) = γ ⨀ X − μ ^ σ ^ + β LN(X) = \gamma \bigodot \frac{X - \hat{\mu}}{\hat{\sigma}} + \beta LN(X)=γ⨀σ^X−μ^+β
1) x x x是输入的特征向量。
2) μ \mu μ是输入的均值。
3) σ 2 \sigma^2 σ2是输入的方差。
4) ϵ \epsilon ϵ是一个很小的正数,用于避免去零题目。
5) γ \gamma γ和 β \beta β是可学习的缩放和偏移参数。
6) ⨂ \bigotimes ⨂ 体现逐元素乘法。
2.RMSNorm
(1) R M S ( x ) 2 = 1 d ∑ x i ∈ X x i 2 + ϵ RMS(x)^2 = \frac{1}{d} \sum_{x^i\in X}x_i^2 + \epsilon RMS(x)2=d1xi∈X∑xi2+ϵ
(2) R M S N o r m ( x ) = γ ⨀ x R M S ( x ) RMSNorm(x) = \gamma \bigodot \frac{x}{RMS(x)} RMSNorm(x)=γ⨀RMS(x)x
1) x x x是输入的特征向量。
2) R M S ( X ) RMS(X) RMS(X)是输入的均方根。
3) ϵ \epsilon ϵ是一个很小的正数,用于避免去零题目。
4) γ \gamma γ是可学习的缩放参数。
5) ⨂ \bigotimes ⨂ 体现逐元素乘法。
比力总结:
计算复杂度:RMSNorm减少了均值的计算,低落了整体计算量。
数值稳定性:RMSNorm避免了方差靠近零的环境,提升了数值稳定性。
体现性能:在某些任务中,RMSNorm可以达到或凌驾LayerNorm的性能。
4、激活函数
Linear函数是一种仿射变更(线性变更 + 平移),在深度学习中也称为“线性函数”,神经网络中的全毗连层(Dense Layer)、卷积层(Convolution Layer)等,本质都是通过线性变更(( Wx + b ))将输入映射到新的空间。
L i n e a r ( x ) = x W + b Linear(x) = xW+b Linear(x)=xW+b
1)x是输入的特征向量。
2)W是权重,b是偏置,是可学习的参数。
单独线性函数无法办理复杂题目(多层线性叠加仍是线性的)。因此,线性层后通常接激活函数(如 ReLU、Sigmoid),引入非线性,使网络能拟合任意复杂函数。
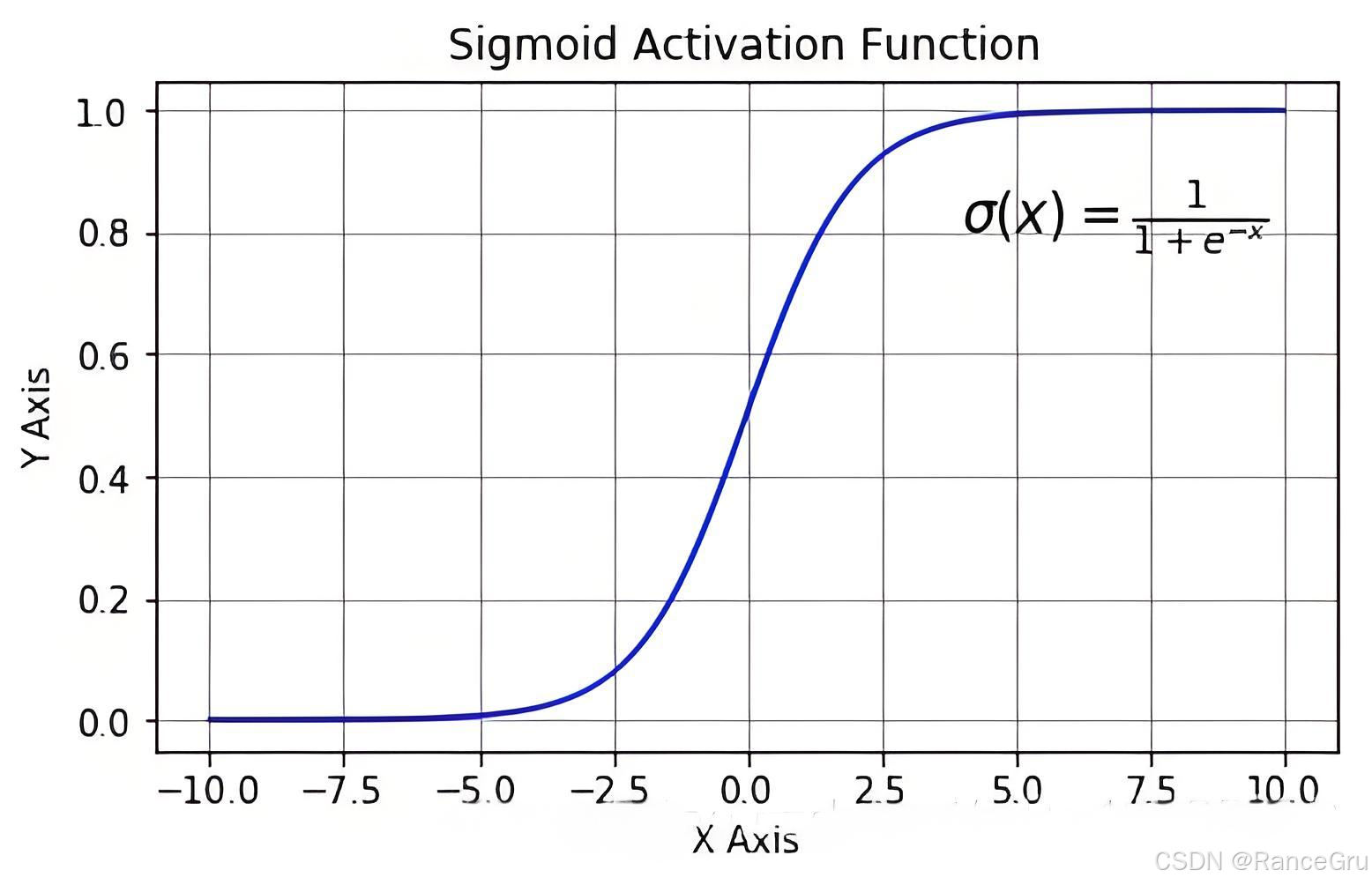
2.Sigmoid激活函数
Sigmoid激活函数应该是深度神经网络开始使用的激活函数,它的函数图形是一个S形的曲线,也被称为S曲线(S-curve),它具有以下特性:
输出界限:由于Sigmoid函数的输出范围在0到1之间,它可以被用于将任何值映射到概率空间。这使得Sigmoid函数非常适合于二分类任务的最后输出,比如在二分类题目中预测一个变乱发生的概率。
非线性特性:Sigmoid函数是一个非线性函数,这意味着当我们使用它作为激活函数时,可以资助神经网络学习到输入数据中的非线性复杂关系。如果没有非线性激活函数,无论神经网络有多少层,终极都只能学习到输入数据的线性组合。
平滑梯度:Sigmoid函数的梯度在其定义域内处处存在,这保证了在使用基于梯度的优化算法(如梯度下降)时,每一步都能够找到方向。它的平滑性子也使得模子的训练更加稳定。
σ ( x ) = 1 1 + e − x \sigma(x) = \frac{1}{1 + e^{-x}} σ(x)=1+e−x1
1) x x x是输入的特征向量。
2)e 是自然对数的底数。
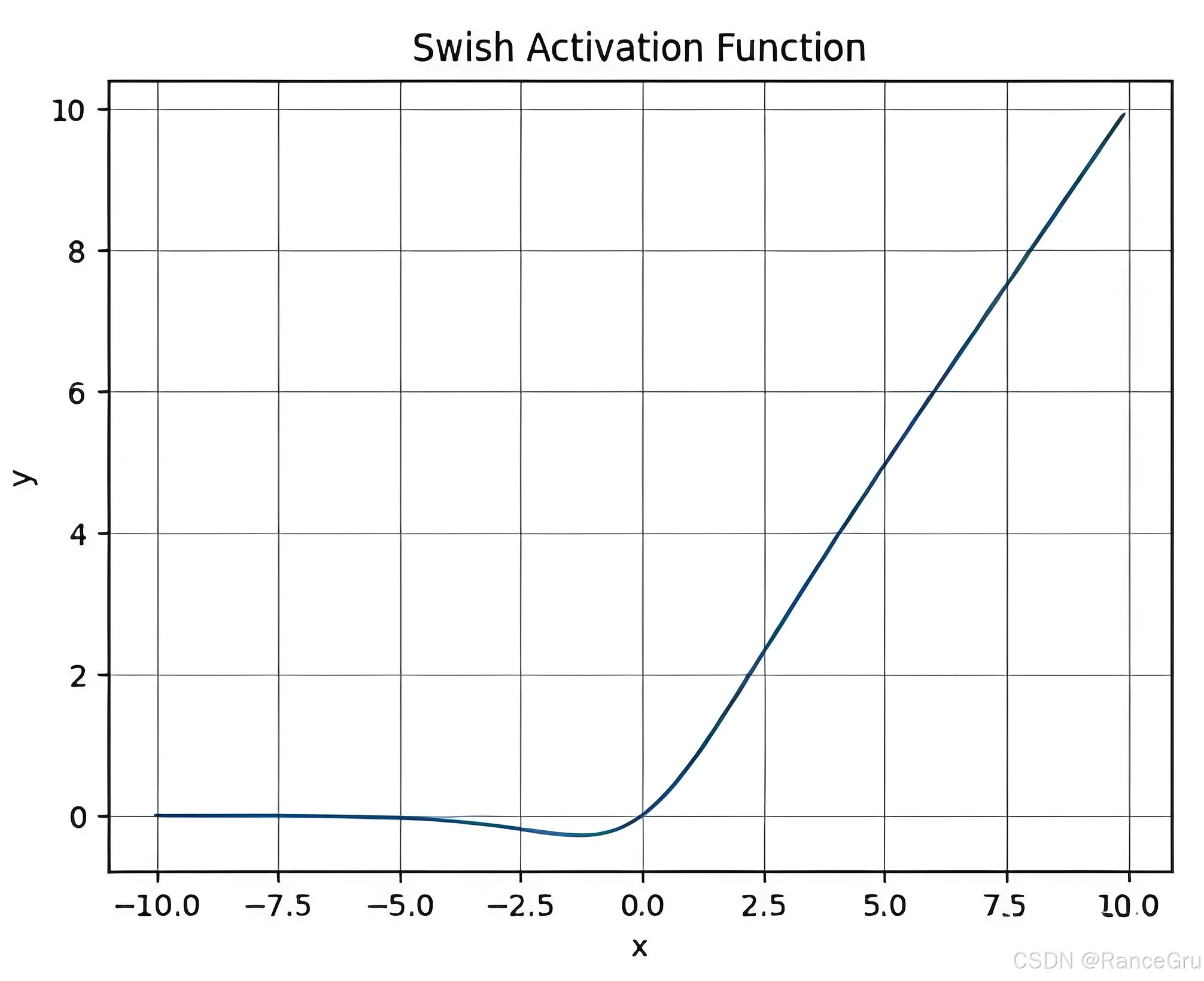
3.Swish激活函数
Swish激活函数 是一种由 Google Research 提出的非线性激活函数,Swish 激活函数的特点:
平滑且连续:Swish 是一个平滑的激活函数, 可以更平滑地引导梯度活动,从而可能减少梯度消失题目,并且对神经网络的优化更有利。
非单调函数:与 ReLU 或 Sigmoid 等激活函数差别,Swish 不是严酷单调的,这意味着它在某些环境下可能更加灵活地适应数据和任务的需求。
梯度信息较好:在正区间和负区间都有较为稳定的梯度,这有助于避免梯度爆炸或梯度消失题目。
平滑梯度:Swish 能提供比 ReLU 更加平滑的梯度。
无饱和区:即使输入为负值,Swish函数也能产生非零梯度,避免了ReLU的“神经元殒命”题目。
S w i s h β ( x ) = x ⋅ σ ( β x ) Swish_\beta(x) = x\cdot\sigma(\beta x) Swishβ(x)=x⋅σ(βx)
S w i s h ( x ) = x ⋅ S i g m o i d ( x ) Swish(x) = x\cdot Sigmoid(x) Swish(x)=x⋅Sigmoid(x)
1) x x x是输入的特征向量。
2) σ ( x ) \sigma(x) σ(x) 是 Sigmoid 激活函数。
3)当β趋近于0时,Swish函数趋近于线性函数 y = x 2 y = x^2 y=x2。
4)当β趋近于无穷大时,Swish函数趋近于ReLU函数。
5)当β取值为1时,Swish函数是光滑且非单调的,等价于SiLU激活函数。
4.GLU激活函数
SwiGLU激活函数联合了Swish和GLU两者的特点,它是GLU门控线性单元的一个变种。
了解SwiGLU必须从GLU入手,GLU提出于2016年发表的论文《nguage modeling with gated convolutional networks》中,是一种类似LSTM带有门机制的网络结构,相比于LSTM,GLU不需要复杂的门机制,不需要遗忘门,仅有一个输入门。同时它类似Transformer一样具有可堆叠性和残差毗连,它的作用是完成对输入文本的表征,通过门机制控制信息通过的比例,来让模子自适应地选择哪些单词和特征对预测下一个词有资助,通过堆叠来发掘高阶语义,通过残差毗连来缓解堆叠的梯度消失和爆炸。
G L U ( x , W , V , b , c ) = σ ( x W + b ) ⨂ ( x V + c ) GLU(x,W,V,b,c) = \sigma(xW+b)\bigotimes(xV+c) GLU(x,W,V,b,c)=σ(xW+b)⨂(xV+c)
G L U ( x ) = S i g m o i d ( L i n e a r ( x ) ) ⨂ L i n e a r ( x ) GLU ( x ) = Sigmoid(Linear (x))\bigotimes Linear (x) GLU(x)=Sigmoid(Linear(x))⨂Linear(x)
1) x x x是输入的特征向量。
2) σ ( x ) \sigma(x) σ(x) 是 Sigmoid 激活函数。
3)W、V以及b、c分别是这两个线形层的两个参数。
4) ⨂ \bigotimes ⨂ 体现逐元素乘法。
5.SwiGLU激活函数
在2020年发表的论文《GLU Variants Improve Transformer》中,提出使用GLU的变种来改进Transformer的FFN层,就是将GLU中原始的Sigmoid激活函数替换为其他的激活函数,作者枚举了替换为ReLU,GELU和SwiGLU的三种变体。
门控特性:可以根据输入的环境决定哪些信息应该通过、哪些信息应该被过滤,增强模子对重要特征的关注,有助于提高模子的泛化本领。在大语言模子中,这对于处理长序列、长距离依赖的文本特别有效。
提高性能:在许多基准测试中,swiGLU 已被证明比 GLU、ReLU 及其他激活函数提供更好的体现。
平滑梯度:Swish 函数的平滑性使得反向流传的梯度更新更稳定,减轻梯度消失的题目。
计算服从:尽管引入了额外的非线性激活函数,swiGLU 的计算开销相对较小,适合大型模子。
S w i G L U ( x , W , V , b , c , β ) = S w i s h β ( x W + b ) ⨂ ( x V + c ) SwiGLU(x, W, V, b, c, \beta) = Swish_\beta(xW+b)\bigotimes(xV+c) SwiGLU(x,W,V,b,c,β)=Swishβ(xW+b)⨂(xV+c)
S w i G L U ( x ) = S w i s h ( L i n e a r ( x ) ) ⨂ L i n e a r ( x ) SwiGLU(x) = Swish(Linear(x))\bigotimes Linear(x) SwiGLU(x)=Swish(Linear(x))⨂Linear(x)
1) x x x是输入的特征向量。
2)W, V是线性变更的权重矩阵,将输入投影到差别空间。
3)b, c是偏置项,调解线性变更的偏移。
4) β \beta β是Swish 的外形参数,通常设为1或可学习。
5、位置编码
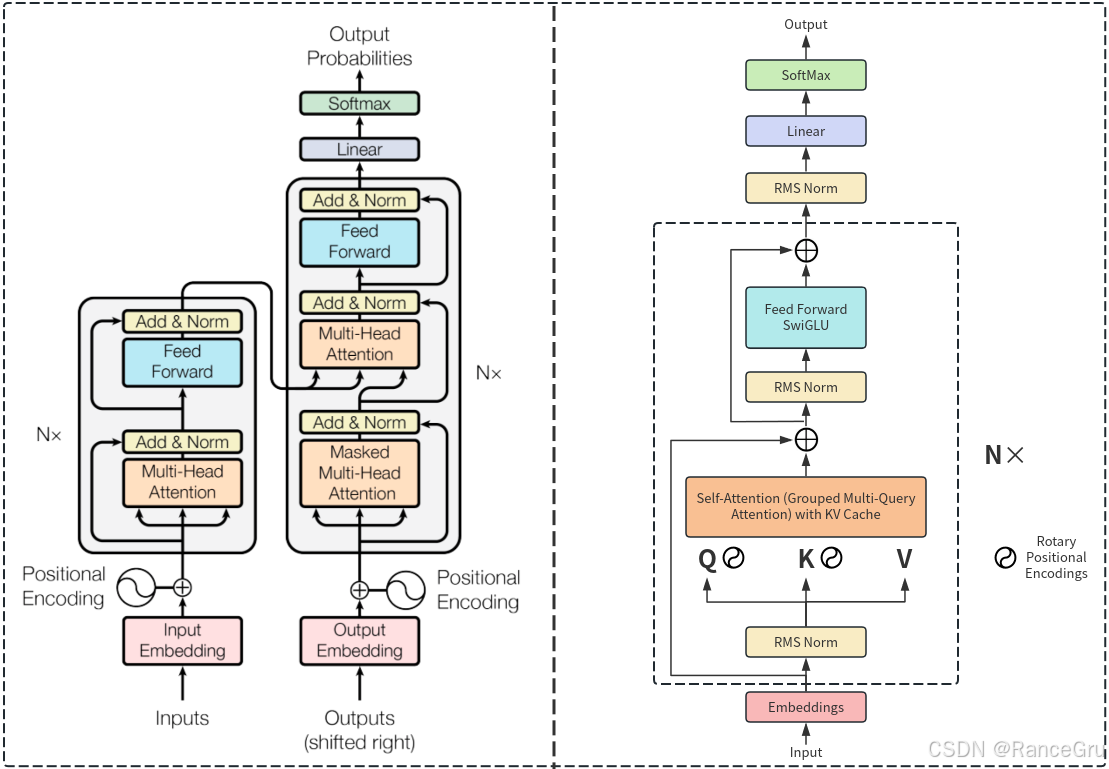
位置嵌入:LLaMa删除了绝对位置嵌入,而是使用了旋转位置嵌入(RoPE),这种改进有助于模子在处理语言任务时更加灵活。
在Transformer出现从前,NLP任务大多是以RNN、LSTM为代表的循环处理方式,即一个token一个token的输入到模子当中。模子自己是一种次序结构,天生就包含了token在序列中的位置信息。但是这种模子有很多天生的缺陷,比如:
1.会出现“遗忘”的征象,无法支持长时间序列,固然LSTM在一定程度上缓解了这种征象,但是这种缺陷仍然存在;
2.句子越靠后的token对效果的影响越大;
3.只能利用上文信息,不能获取下文信息;
4.计算的时间复杂度比力高,循环网络是一个token一个token的输入的,也就是句子有多长就要循环多少遍;
Transformer模子中,位置编码(Positional Encoding) 是为了办理自留意力机制(Self-Attention)无法直接感知输入序列中词的位置次序的题目而引入的技术。由于自留意力机制是“无序的”(它对输入词的位置不敏感),模子需要通过位置编码来显式地注入序列的位置信息。
自留意力通过计算词与词之间的关系来捕捉上下文,但它默认将全部词视为“无序集合”,无法区分像“猫吃鱼”和“鱼吃猫”如许的位置差别。但是自然语言中词的次序对语义至关重要,所以需要位置编码资助模子理解词在序列中的相对或绝对位置,如果没有位置编码的信息,模子会丧失序列的次序信息,导致模子退化成一个简单的“词袋模子”(Bag of Words model)。
1.绝对位置编码
“Attention is All You Need”论文
即将每个位置编号,从而每个编号对应一个向量,用来标志token的前后次序,终极通过联合位置向量和词向量,作为输入embedding,就给每个词都引入了一定的位置信息,如许Attention就可以分辨出差别位置的词了。
绝对位置编码就是为序列中的每个位置分配一个唯一的编码,这种编码直接反映了元素在序列中的绝对位置。最简单的想法就是从1开始向后分列,但是这种方式存在很大的题目,句子越长token越多,后面的值越大,而且如许的方式也无法凸显每个位置的真实的权重,所以这种方式基本没有人用。
**基于正弦和余弦函数的编码:**由Transformer模子提出,使用正弦和余弦函数的差别频率来为序列中的每个位置生成唯一的编码。这种方法的优点是能够支持到任意长度的序列,并且模子可以从编码中推断出位置信息。通过sin函数和cos函数瓜代来创建 positional encoding。
P E ( p o s , 2 i ) = s i n ( p o s 1000 0 2 i d m o d e l ) PE_{(pos,2i)} = sin\left(\frac{pos}{10000^{\frac{2i}{d_model}}} \right) PE(pos,2i)=sin(10000dmodel2ipos)
P E ( p o s , 2 i + 1 ) = c o s ( p o s 1000 0 2 i d m o d e l ) PE_{(pos,2i+1)} = cos\left(\frac{pos}{10000^{\frac{2i}{d_model}}} \right) PE(pos,2i+1)=cos(10000dmodel2ipos)
1)pos(位置索引):体现序列中某个词的位置(从0开始计数)。差别位置的词通过差别的 pos 值生成唯一的位置编码。比如对于句子 “I love you”,“I” 的 pos=0,“love” 的 pos=1,“you” 的 pos=2。
2)i(维度索引):体现位置编码向量的维度(从0开始计数)。控制位置编码的频率衰减模式。偶数维度( 2i)使用正弦函数,奇数维度( 2i+1)使用余弦函数,瓜代生成编码。取值范围是i ∈ [0, d_model/2 - 1](比方,若 d_model=512,则 i 从0到255)。
3)d_model(模子维度):Transformer模子的隐藏层维度,即位置编码向量的长度。决定位置编码的总维度数,需与词嵌入(Token Embedding)的维度一致。BERT-base的 d_model=768,原始Transformer论文中 d_model=512。
4)10000(频率基数):一个预设的超参数,控制位置编码的频率衰减速度决定最大波长(即最低频率)当 i=0 时,波长最大为 1000 0 0 10000^{0} 100000 = 1,对应高频;当 i=d_model/2-1 时,波长最小为 1000 0 ( d m o d e l − 2 ) / d m o d e l 10000^{(d_model-2)/d_model} 10000(dmodel−2)/dmodel,对应低频。通过指数衰减覆盖差别标准的位置信息(局部细节和全局结构)。
维度瓜代:偶数维用正弦,奇数维用余弦,确保每个位置编码唯一且差别位置的编码可通过线性变更对齐。
波长控制: 1000 0 2 i d m o d e l 10000^{\frac{2i}{d_model}} 10000dmodel2i使波长随维度增长呈指数增长,高频(小波长)编码局部信息,低频(大波长)编码全局信息。
绝对位置编码的优势在于其简单且具有良好的可表明性。 它能够有效地为序列中的每个位置分配独特的编码,从而资助模子捕捉序列的次序信息。然而它也有一定的局限性,尤其是在处理变长序列或长距离依赖时,绝对位置编码可能无法充实表达复杂的位置信息。
“Self-Attention with Relative Position Representations”论文
与绝对位置编码差别,相对位置编码(Relative Positional Encoding)并不直接为每个位置分配一个唯一的编码,而是关注序列中各元素之间的相对位置。 相对位置编码的核心思想是通过计算序列中元素之间的距离,来体现它们之间的相对关系。这种方法尤其适合处理需要捕捉长距离依赖关系的任务,因为它能够更加灵活地体现序列中的结构信息。
相对位置编码可以通过多种方式实现,此中最常用的方法之一是将位置差值与留意力权重相联合,即在计算自留意力时,不仅思量内容,还思量位置差别。如许模子能够根据元素之间的距离调解它们之间的交互强度。
其核心思想是:将相对位置信息作为可学习的偏置项,直接融入留意力权重和值的计算中,而非像绝对位置编码那样直接添加到输入嵌入。
标准留意力机制公式:
Attention ( Q , K , V ) = softmax ( Q K T d k ) V \text{Attention}(Q, K, V) = \text{softmax}\left( \frac{QK^T}{\sqrt{d_k}} \right)V Attention(Q,K,V)=softmax(dk QKT)V
1)Query(Q):体现当前需要计算留意力的目的位置(比方当前处理的词)。
2)Key(K):体现输入序列中全部位置的“标识符”,用于与 Query 匹配相似度。
3)Value(V):体现每个位置现实携带的信息,终极通过留意力权重加权聚合。通过 Query 与 Key 的匹配程度,决定从哪些 Value 中提取信息。
4) d k d_k dk体现Key 向量的维度(通常与 Query 的维度雷同)。对点积 Q K T {QK^T} QKT进行缩放,缩放后使梯度更稳定,训练更高效。
5) Q = x W q , K = x W k , V = x W v Q = xW_q, K = xW_k, V = xW_v Q=xWq,K=xWk,V=xWv,W为可学习的权重矩阵。
6)T体现转置矩阵。
S o f t m a x = e x i Σ i = 1 n e x i = e x p ( x i ) Σ i = 1 n e x p ( x i ) ∈ ( 0 , 1 ) Softmax = \frac{e^{x_i}}{{\Sigma_{i=1}^n}e^{x_i}} = \frac{exp(x_i)}{{\Sigma_{i=1}^n}exp(x_i)}\in(0,1) Softmax=Σi=1nexiexi=Σi=1nexp(xi)exp(xi)∈(0,1)
标准留意力机制公式转换后的留意力机制公式:
e i j = ( x i W Q ) ( x j W K ) T d z = Q K T d k e_{ij} = \frac{(x_iW^Q)(x_jW^K)^T}{\sqrt{d_z}} = \frac{QK^T}{\sqrt{d_k}} eij=dz (xiWQ)(xjWK)T=dk QKT
1) e i j e_{ij} eij是留意力分数的具体计算,缩放因子 d k \sqrt{d_k} dk 用于防止点积值过大导致 softmax 梯度消失。
2) Q = x W Q , K = x W K , V = x W V Q = xW^Q, K = xW^K, V = xW^V Q=xWQ,K=xWK,V=xWV三者分别是输入x通过差别权重矩阵变更得到的查询、键、值矩阵。
α i j = e x p ( e i j ) Σ k = 1 n e x p ( e i k ) \alpha_{ij} = \frac{exp(e_{ij})}{{\Sigma_{k=1}^n}exp(e_{ik})} αij=Σk=1nexp(eik)exp(eij)
z i = ∑ j = 1 n α i j ( x j W V ) z_i = \sum_{j=1}^n \alpha_{ij}(x_jW^V) zi=j=1∑nαij(xjWV)
1) x j W V x_jW^V xjWV是输入 x j x_j xj通过值权重矩阵 W V W^V WV变更后的值向量(即 V j V_j Vj)。
2) α i j \alpha_{ij} αij是位置i对位置j的留意力权重。
3) Q = x W Q , K = x W K , V = x W V Q = xW^Q, K = xW^K, V = xW^V Q=xWQ,K=xWK,V=xWV三者分别是输入x通过差别权重矩阵变更得到的查询、键、值矩阵。
4) α i j = s o f t m a x ( e i j ) \alpha_{ij} = softmax(e_{ij}) αij=softmax(eij),对全部的 e i j e_{ij} eij进行 softmax \text{softmax} softmax,就会得到留意力权重矩阵 α i j \alpha_{ij} αij,softmax 输出就是 α i j \alpha_{ij} αij,由查询向量Q和键向量K的点积计算得出。
5) x j W V = V j x_jW^V = V_j xjWV=Vj, x j W V x_jW^V xjWV就是 V j V_j Vj,就是值向量V。
相对位置与留意力权重相联合后的留意力机制公式:
a i j K = w c l i p ( j − i , k ) K a_{ij}^K = w_{clip(j-i,k)}^K aijK=wclip(j−i,k)K
a i j V = w c l i p ( j − i , k ) V a_{ij}^V = w_{clip(j-i,k)}^V aijV=wclip(j−i,k)V
c l i p ( x , k ) = m a x ( − k , m i n ( k , x ) ) clip(x,k) = max(-k,min(k,x)) clip(x,k)=max(−k,min(k,x))
1) a i j K a_{ij}^K aijK在位置 i 和 j 之间,键(Key)的留意力权重由相对位置差 j-i 决定,但该差值会被截断(clip)到范围 [-k, k]。 w K w^K wK 是一个可学习的参数,根据截断后的差值索引对应的权重。
2) a i j V a_{ij}^V aijV在位置 i 和 j 之间,值(Value)的留意力权重由相对位置差 j-i 决定,但该差值会被截断(clip)到范围 [-k, k]。 w V w^V wV 是一个可学习的参数,根据截断后的差值索引对应的权重。
3)clip将任意实数 x 限定在区间 [-k, k] 内。长距离的词汇关联可能较弱,截断到 [-k, k] 可以减少参数量,只需学习 2k+1 种位置编码(从 -k 到 k),而非全部可能的位置差,还能增强泛化,避免模子对非常位置差过拟合。
4)键(Key)和值(Value)在留意力机制中功能差别(Key 用于计算留意力权重,Value 用于生成输出),因此允许它们使用独立的相对位置编码参数 w K w^K wK 和 w V w^V wV。
通过截断的相对位置差,为留意力机制中的键和值引入了轻量化的位置感知本领,平衡了长距离依赖建模与计算服从。
e i j = x i W Q ( x j W K + a i j K ) T d z = x i W Q ( x j W K ) T + x i W Q ( a i j K ) T d z e_{ij} = \frac{x_iW^Q(x_jW^K + a_{ij}^K)^T}{\sqrt{d_z}} = \frac{x_iW^Q(x_jW^K)^T + x_iW^Q(a_{ij}^K)^T}{\sqrt{d_z}} eij=dz xiWQ(xjWK+aijK)T=dz xiWQ(xjWK)T+xiWQ(aijK)T
1) Q = x W Q , K = x W K , V = x W V Q = xW^Q, K = xW^K, V = xW^V Q=xWQ,K=xWK,V=xWV三者分别是输入x通过差别权重矩阵变更得到的查询、键、值矩阵,是对应向量的投影。
2) a i j K a_{ij}^K aijK在位置 i 和 j 之间,键(Key)的留意力权重由相对位置差 j-i 决定,但该差值会被截断(clip)到范围 [-k, k]。 w K w^K wK 是一个可学习的参数,根据截断后的差值索引对应的权重,用于在键向量中引入相对位置信息。
z i = ∑ j = 1 n α i j ( x j W V + a i j V ) z_i = \sum_{j=1}^n \alpha_{ij}(x_jW^V + a_{ij}^V) zi=j=1∑nαij(xjWV+aijV)
1) α i j = s o f t m a x ( e i j ) \alpha_{ij} = softmax(e_{ij}) αij=softmax(eij),对全部的 e i j e_{ij} eij进行 softmax \text{softmax} softmax,就会得到留意力权重矩阵 α i j \alpha_{ij} αij,softmax 输出就是 α i j \alpha_{ij} αij,由查询向量Q和键向量K的点积计算得出。
2) a i j V a_{ij}^V aijV在位置 i 和 j 之间,值(Value)的留意力权重由相对位置差 j-i 决定,但该差值会被截断(clip)到范围 [-k, k]。 w V w^V wV 是一个可学习的参数,根据截断后的差值索引对应的权重,用于在值向量中引入相对位置信息。
两者的区别在于:
a i j K a_{ij}^K aijK是键(Key)部分的相对位置编码,用于调解留意力得分 e i j e_{ij} eij,直接影响留意力权重 α i j \alpha_{ij} αij。
a i j V a_{ij}^V aijV则是值(Value)部分的相对位置编码,直接影响聚合后的输出 z i z_i zi。
a i j K a_{ij}^K aijK影响“哪些位置需要关注”(留意力权重),
a i j V a_{ij}^V aijV影响“怎样利用被关注的位置信息”(值向量的调解)。
Transformer-XL
“Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context”论文
Transformer-XL提出了片断级循环机制和相对位置编码新机制,此中它将长文天职割为固定长度的片断(segments)后,引入了循环机制,在训练时缓存前一片断的隐藏状态(hidden states),并在处理当前片断时将其作为额外输入。通过这种方式,模子能够跨片断传递信息,理论上可建模的依赖长度随层数线性增长(如层数为N,依赖长度可达N倍片断长度)。突破了固定上下文的限定,显著提升长程依赖建模本领。推理时也无需重复计算历史信息,提升服从。
对于片断级循环机制,这里就不展开了,重要了解Transformer-XL的相对位置编码机制。
Transformer绝对位置编码的留意力得分公式:
Q = W q ( E + U ) Q = W_q(E + U) Q=Wq(E+U)
K = W k ( E + U ) K = W_k(E + U) K=Wk(E+U)
在原始 Transformer 中,位置信息通过绝对位置编码直接添加到输入词嵌入中,即: E x i + U i E_{x_i} + U_i Exi+Ui,此中 ( E x i ) (E_{x_i}) (Exi) 是词嵌入, ( U i ) (U_i) (Ui) 是位置嵌入。此时留意力得分隐含了绝对位置信息。
A i , j a b s = Q K T = ( W q ( E + U ) ) ( W k ( E + U ) T ) = E x i T W q T W k E x j ⏟ ( a ) + E x i T W q T W k U j ⏟ ( b ) + U i T W q T W k E x j ⏟ ( c ) + U i T W q T W k U j ⏟ ( d ) . A_{i,j}^{abs} = QK^T = (W_q(E + U))(W_k(E + U)^T) = \underbrace{E_{x_i}^TW_q^TW_kE_{x_j}}_{(a)} + \underbrace{E_{x_i}^TW_q^TW_kU_j}_{(b)} + \underbrace{U_i^TW_q^TW_kE_{x_j}}_{(c)} + \underbrace{U_i^TW_q^TW_kU_j}_{(d)}. Ai,jabs=QKT=(Wq(E+U))(Wk(E+U)T)=(a) ExiTWqTWkExj+(b) ExiTWqTWkUj+(c) UiTWqTWkExj+(d) UiTWqTWkUj.
1) E x i , E x j E_{x_i}, E_{x_j} Exi,Exj词嵌入向量(内容嵌入)。
2) U i , U j U_i, U_j Ui,Uj绝对位置编码向量。
3) W q , W k W_q, W_k Wq,Wk查询(Query)和键(Key)的权重矩阵。
4)a 内容-内容交互,纯粹的词嵌入之间的相关性,反映两个词自己的内容关联性。
5)b 内容-位置交互,当前词的内容与目的位置编码的交互,捕捉位置对内容的影响。
6)c 位置-内容交互,当前位置编码与目的词内容的交互,类似(b)但方向相反。
7)d 位置-位置交互,位置编码之间的相关性,反映位置自己的相对关系。
Transformer-XL相对位置编码的留意力得分公式:
A i , j r e l = E x i T W q T W k , E E x j ⏟ ( a ) + E x i T W q T W k , R R i − j ⏟ ( b ) + u T W k , E E x j ⏟ ( c ) + v T W k , R R i − j ⏟ ( d ) . A_{i,j}^{rel} = \underbrace{E_{x_i}^TW_q^TW_{k,E}E_{x_j}}_{(a)} + \underbrace{E_{x_i}^TW_q^TW_{k,R}R_{i-j}}_{(b)} + \underbrace{u^TW_{k,E}E_{x_j}}_{(c)} + \underbrace{v^TW_{k,R}R_{i-j}}_{(d)}. Ai,jrel=(a) ExiTWqTWk,EExj+(b) ExiTWqTWk,RRi−j+(c) uTWk,EExj+(d) vTWk,RRi−j.
1) R i − j R_{i-j} Ri−j相对位置编码(如位置差为 (i-j) 的向量)。
2) W k , E , W k , R W_{k,E}, W_{k,R} Wk,E,Wk,R键矩阵拆分为内容相关((E))和位置相关(®)的两部分。
3) u , v u, v u,v可学习的全局偏置向量。
4)a 内容-内容交互,词嵌入之间的直接相关性,与绝对位置编码的(a)类似。
5)b 内容-相对位置交互,当前词内容与相对位置的交互,捕捉内容怎样随相对位置变革。
6)c 全局内容偏置,通过向量 (u) 为目的词内容添加全局偏置,独立于当前位置。
7)d 相对位置偏置,通过向量 (v) 为相对位置添加全局偏置,独立于具体内容。
3.RoPE旋转位置嵌入
“RoFormer: Enhanced Transformer with Rotary Position Embedding论文”
公式推理:
假设有一个长度为N的输入,比如“大模子”,可以将这个输入记作以下序列公式:
S N = { w i } i = 1 N S_N = \lbrace w_i\rbrace _{i=1}^N SN={wi}i=1N
这段文字序列也不是直接就可以作为输入传入模子的,模子无法直接理解文字这种高维数据。需要使用Embedding将这种离散的、非结构化的数据(如文字、图像、音频等)转换映射为连续的、低维的数值向量(即一组数字),可以根据以上公式表达为:
E N = { w i } i = 1 N E_N = \lbrace w_i\rbrace _{i=1}^N EN={wi}i=1N
假设 f f f是一个位置函数,那么可以对 E N E_N EN表达为:
E N = { f ( x i , i ) } i = 1 N E_N = \lbrace f(x_i,i)\rbrace _{i=1}^N EN={f(xi,i)}i=1N
根据 E N E_N EN来表达QKV公式:
q m = f q ( x m , m ) q_m = f_q(x_m,m) qm=fq(xm,m)
k n = f k ( x n , n ) k_n = f_k(x_n,n) kn=fk(xn,n)
v n = f v ( x n , n ) v_n = f_v(x_n,n) vn=fv(xn,n)
1) q m q_m qm体现的是目的位置m上的Q,用于计算与全部源位置n上的KV的相关性,类似你提出的第m个题目。
2) k n , v n k_n,v_n kn,vn体现源位置n上的KV,用于与目的位置m上的Q计算留意力分数和相关内容,类似答案会合的第n个答案与这第n个答案中的现实内容。
联合上述的标准留意力机制公式转换后的留意力机制公式,可以得到:
a m , n = e x p ( q m T k n d ) Σ j = 1 N e x p ( q m T k j d ) a_{m,n} = \frac{exp(\frac{q_m^Tk_n}{\sqrt{d}})}{{\Sigma_{j=1}^N}exp(\frac{q_m^Tk_j}{\sqrt{d}})} am,n=Σj=1Nexp(d qmTkj)exp(d qmTkn)
o m = Σ n = 1 N a m , n v n o_m = \Sigma_{n=1}^N a_{m,n}v_n om=Σn=1Nam,nvn
为了包含相对位置信息,假设有一个函数g,用来体现Q q m q_m qmK k n k_n kn的内积,且该函数g只将词嵌入 x m , x n x_m,x_n xm,xn及其相对位置m−n作为输入变量:
q m k n = ⟨ f q ( x m , m ) , f k ( x n , n ) ⟩ = g ( x m , x n , m − n ) q_mk_n = \left\langle f_q(x_m,m),f_k(x_n,n) \right\rangle = g(x_m,x_n,m-n) qmkn=⟨fq(xm,m),fk(xn,n)⟩=g(xm,xn,m−n)
Attention公式中的QKV可以表达为输入的x与W矩阵的映射值:
Q = x W q , K = x W k , V = x W v Q = xW_q, K = xW_k, V = xW_v Q=xWq,K=xWk,V=xWv
根据以上内容实现查询Q和键K的旋转函数:
f q ( x m , m ) = ( W q x m ) e i m θ f_q(x_m,m) = (W_qx_m)e^{im\theta} fq(xm,m)=(Wqxm)eimθ
f k ( x n , n ) = ( W k x n ) e i n θ f_k(x_n,n) = (W_kx_n)e^{in\theta} fk(xn,n)=(Wkxn)einθ
g ( x m , x n , m − n ) = R e [ ( W q x m ) ( W k x n ) ∗ e i ( m − n ) θ ] = R e [ q m k n ∗ e i ( m − n ) θ ] g(x_m,x_n,m-n) = Re[(W_qx_m)(W_kx_n)^*e^{i(m-n)\theta}] = Re[q_mk_n^*e^{i(m-n)\theta}] g(xm,xn,m−n)=Re[(Wqxm)(Wkxn)∗ei(m−n)θ]=Re[qmkn∗ei(m−n)θ]
1) x m , x n x_m,xn xm,xn体现序列中位置m和n的向量
2) m , n m,n m,n体现绝对位置索引。
3) θ \theta θ体现预设的非零常数,体现角度参数,用于控制旋转频率,与维度相关。
4) e i m θ , e i n θ e^{im\theta},e^{in\theta} eimθ,einθ复数域旋转,将绝对位置信息编码到QK中。
5)旋转操作保证向量模长不变,仅改变方向。
6)Re体现内积转换为复数乘法,然后只取实部。
7)留意力分数仅依赖相对位置差m-n,而不是绝对位置m或n。
8) e i ( m − n ) θ e^{i(m-n)\theta} ei(m−n)θ编码相对位置关系。
9) ( W k x n ) ∗ (W_kx_n)^* (Wkxn)∗是 ( W k x n ) (W_kx_n) (Wkxn)的共轭复数
联合共轭复数公式:
z = a + b i , z ∗ = a − b i z = a + bi, z^* = a - bi z=a+bi,z∗=a−bi
q m = q m 1 + i q m 2 , k n ∗ = k n 1 − i k n 2 q_m = q_m^1 + i q_m^2, k_n^* = k_n^1 - i k_n^2 qm=qm1+iqm2,kn∗=kn1−ikn2
联合傅里叶变更中的欧拉公式:
e i θ = c o s θ + i ∗ s i n θ e^{i\theta} = cos\theta + i*sin\theta eiθ=cosθ+i∗sinθ
e i ( m − n ) θ = c o s ( ( m − n ) θ ) + i s i n ( ( m − n ) θ ) e^{i(m-n)\theta} = cos((m-n)\theta) + isin((m-n)\theta) ei(m−n)θ=cos((m−n)θ)+isin((m−n)θ)
联合以上公式,整理可得:
g ( x m , x n , m − n ) = R e [ ( q m 1 + i q m 2 ) ( k n 1 − i k n 2 ) ( c o s ( ( m − n ) θ ) + i s i n ( ( m − n ) θ ) ) ] g(x_m,x_n,m-n) = Re[(q_m^1 + i q_m^2)(k_n^1 - i k_n^2)(cos((m-n)\theta) + isin((m-n)\theta))] g(xm,xn,m−n)=Re[(qm1+iqm2)(kn1−ikn2)(cos((m−n)θ)+isin((m−n)θ))]
展开计算公式,然后根据Re只取实部的特点(去除带有i的公式),可整理得到以下公式:
g ( x m , x n , m − n ) = ( q m 1 k n 1 + q m 2 k n 2 ) c o s ( ( m − n ) θ ) − ( q m 2 k n 1 − q m 1 k n 2 ) s i n ( ( m − n ) θ ) g(x_m,x_n,m-n) = (q_m^1k_n^1 + q_m^2k_n^2)cos((m-n)\theta) - (q_m^2k_n^1 - q_m^1k_n^2)sin((m-n)\theta) g(xm,xn,m−n)=(qm1kn1+qm2kn2)cos((m−n)θ)−(qm2kn1−qm1kn2)sin((m−n)θ)
颠末转换可得:
g ( x m , x n , m − n ) = ( q m 1 q m 2 ) ( c o s ( ( m − n ) θ ) − s i n ( ( m − n ) θ ) s i n ( ( m − n ) θ ) c o s ( ( m − n ) θ ) ) ( k n 1 k n 2 ) g(x_m,x_n,m-n) = (q_m^1q_m^2)\begin{pmatrix} cos((m-n)\theta) & -sin((m-n)\theta) \\ sin((m-n)\theta) & cos((m-n)\theta) \\ \end{pmatrix} \begin{pmatrix} k_n^1 \\ k_n^2 \\ \end{pmatrix} g(xm,xn,m−n)=(qm1qm2)(cos((m−n)θ)sin((m−n)θ)−sin((m−n)θ)cos((m−n)θ))(kn1kn2)
f q ( x m , m ) = ( c o s ( m θ ) − s i n ( m θ ) s i n ( m θ ) c o s ( m θ ) ) ( q m 1 q m 2 ) f_q(x_m,m) = \begin{pmatrix} cos(m\theta) & -sin(m\theta) \\ sin(m\theta) & cos(m\theta) \\ \end{pmatrix} \begin{pmatrix} q_m^1 \\ q_m^2 \\ \end{pmatrix} fq(xm,m)=(cos(mθ)sin(mθ)−sin(mθ)cos(mθ))(qm1qm2)
f k ( x n , n ) = ( q m 1 q m 2 ) ( c o s ( n θ ) − s i n ( n θ ) s i n ( n θ ) c o s ( n θ ) ) ( k n 1 k n 2 ) f_k(x_n,n) = (q_m^1q_m^2)\begin{pmatrix} cos(n\theta) & -sin(n\theta) \\ sin(n\theta) & cos(n\theta) \\ \end{pmatrix} \begin{pmatrix} k_n^1 \\ k_n^2 \\ \end{pmatrix} fk(xn,n)=(qm1qm2)(cos(nθ)sin(nθ)−sin(nθ)cos(nθ))(kn1kn2)
将RoPE应用于自我留意,可得:
q m T k n = ( R Θ , m d W q x m ) T ( R Θ , n d W k x n ) = x T W q R Θ , ( n − m ) d W k x n q_m^Tk_n = (R_{\Theta,m}^dW_qx_m)^T(R_{\Theta,n}^dW_kx_n) = x^TW_qR_{\Theta,(n-m)}^dW_kx_n qmTkn=(RΘ,mdWqxm)T(RΘ,ndWkxn)=xTWqRΘ,(n−m)dWkxn
1) R Θ , ( n − m ) d W k x n = ( R Θ , m d ) T R Θ , n d R_{\Theta,(n-m)}^dW_kx_n = (R_{\Theta,m}^d)^TR_{\Theta,n}^d RΘ,(n−m)dWkxn=(RΘ,md)TRΘ,nd
2) R Θ d R_\Theta^d RΘd体现一个正交矩阵,用于保证编码位置信息过程中的稳定性,但是具有希奇性。
留意力公式:
Attention ( Q , K , V ) = softmax ( Q K T d k ) V = Σ n = 1 N e x p ( q m T k n d ) v n Σ n = 1 N e x p ( q m T k j d ) \text{Attention}(Q, K, V) = \text{softmax}\left( \frac{QK^T}{\sqrt{d_k}} \right)V = \frac{{\Sigma_{n=1}^N}exp(\frac{q_m^Tk_n}{\sqrt{d}})v_n}{{\Sigma_{n=1}^N}exp(\frac{q_m^Tk_j}{\sqrt{d}})} Attention(Q,K,V)=softmax(dk QKT)V=Σn=1Nexp(d qmTkj)Σn=1Nexp(d qmTkn)vn
ϕ ( q m ) = e x p ( q m d ) , φ ( k n ) = e x p ( k n d ) \phi(q_m) = exp(\frac{q_m}{\sqrt{d}}),\varphi(k_n) = exp(\frac{k_n}{\sqrt{d}}) ϕ(qm)=exp(d qm),φ(kn)=exp(d kn)
联合以上正交矩阵公式,可得:
Attention ( Q , K , V ) m = ∑ n = 1 m ( R Θ , m d ϕ ( q m ) ) T ( R Θ , n d φ ( k n ) ) v n ∑ n = 1 N ϕ ( q m ) T φ ( k n ) \text{Attention}(Q, K, V)_m = \frac{\sum_{n=1}^m(R_{\Theta,m}^d\phi(q_m))^T(R_{\Theta,n}^d\varphi(k_n))v_n}{\sum_{n=1}^N \phi(q_m)^T\varphi(k_n)} Attention(Q,K,V)m=∑n=1Nϕ(qm)Tφ(kn)∑n=1m(RΘ,mdϕ(qm))T(RΘ,ndφ(kn))vn
从二维扩展到多维:
( c o s ( m θ 0 ) − s i n ( m θ 0 ) 0 0 . . . 0 0 s i n ( m θ 0 ) c o s ( m θ 0 ) 0 0 . . . 0 0 0 0 c o s ( m θ 1 ) − s i n ( m θ 1 ) . . . 0 0 0 0 s i n ( m θ 1 ) c o s ( m θ 1 ) . . . 0 0 ⋮ ⋮ ⋮ ⋮ ⋱ ⋮ ⋮ 0 0 . . . 0 0 c o s ( m θ d − 1 ) − s i n ( m θ d − 1 ) 0 0 . . . 0 0 s i n ( m θ d − 1 ) c o s ( m θ d − 1 ) ) ( q 0 q 1 ⋮ ⋮ ⋮ q d − 1 ) \begin{pmatrix} cos(m\theta_0) & -sin(m\theta_0) & 0 & 0 & ... & 0 & 0 \\ sin(m\theta_0) & cos(m\theta_0) & 0 & 0 & ... & 0 & 0 \\ 0 & 0 & cos(m\theta_1) & -sin(m\theta_1) & ... & 0 & 0 \\ 0 & 0 & sin(m\theta_1) & cos(m\theta_1) & ... & 0 & 0 \\ \vdots & \vdots & \vdots & \vdots & \ddots & \vdots & \vdots \\ 0 & 0 & ... & 0 & 0 & cos(m\theta_{d-1}) & -sin(m\theta_{d-1}) \\ 0 & 0 & ... & 0 & 0 & sin(m\theta_{d-1}) & cos(m\theta_{d-1}) \\ \end{pmatrix} \begin{pmatrix} q_0 \\ q_1 \\ \vdots \\ \vdots \\ \vdots \\ q_{d-1} \end{pmatrix} cos(mθ0)sin(mθ0)00⋮00−sin(mθ0)cos(mθ0)00⋮0000cos(mθ1)sin(mθ1)⋮......00−sin(mθ1)cos(mθ1)⋮00............⋱000000⋮cos(mθd−1)sin(mθd−1)0000⋮−sin(mθd−1)cos(mθd−1) q0q1⋮⋮⋮qd−1
参考
实现计算高效旋转矩阵乘法:
R Θ , m d x = ( x 1 x 2 x 3 x 4 ⋮ x d − 1 x d ) ⨂ ( c o s m θ 1 c o s m θ 1 c o s m θ 2 c o s m θ 2 ⋮ c o s m θ d / 2 c o s m θ d / 2 ) + ( − x 2 x 1 − x 4 x 3 ⋮ − x d x d − 1 ) ⨂ ( s i n m θ 1 s i n m θ 1 s i n m θ 2 s i n m θ 2 ⋮ s i n m θ d / 2 s i n m θ d / 2 ) R_{\Theta,m}^dx = \begin{pmatrix} x_1 \\ x_2 \\ x_3 \\ x_4 \\ \vdots \\ x_{d-1} \\ x_d \end{pmatrix} \bigotimes \begin{pmatrix} cos \text{ } m\theta_1 \\ cos \text{ } m\theta_1 \\ cos \text{ } m\theta_2 \\ cos \text{ } m\theta_2 \\ \vdots \\ cos \text{ } m\theta_{d/2} \\ cos \text{ } m\theta_{d/2} \end{pmatrix} + \begin{pmatrix} -x_2 \\ x_1 \\ -x_4 \\ x_3 \\ \vdots \\ -x_d \\ x_{d-1} \end{pmatrix} \bigotimes \begin{pmatrix} sin \text{ } m\theta_1 \\ sin \text{ } m\theta_1 \\ sin \text{ } m\theta_2 \\ sin \text{ } m\theta_2 \\ \vdots \\ sin \text{ } m\theta_{d/2} \\ sin \text{ } m\theta_{d/2} \end{pmatrix} RΘ,mdx= x1x2x3x4⋮xd−1xd ⨂ cos mθ1cos mθ1cos mθ2cos mθ2⋮cos mθd/2cos mθd/2 + −x2x1−x4x3⋮−xdxd−1 ⨂ sin mθ1sin mθ1sin mθ2sin mθ2⋮sin mθd/2sin mθd/2
6、Attention留意力机制
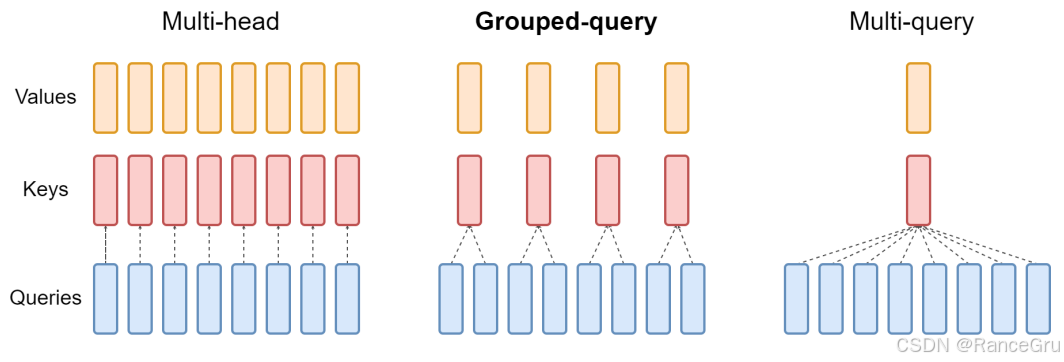
“GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints”论文
1.多头留意力Multi-Head Attention(MHA)