IT评测·应用市场-qidao123.com
标题:
ASR强力模型「Whisper」:解密Whisper:AI驱动的语音识别新时代 -
[打印本页]
作者:
金歌
时间:
2025-3-22 14:22
标题:
ASR强力模型「Whisper」:解密Whisper:AI驱动的语音识别新时代 -
解密Whisper:AI驱动的语音识别新时代
原创 AI小信 别慌G个PT
2024年10月18日 17:54
北京
❝ 前两天禀享了两个TTS模型,本日分享个ASR强力模型
「Whisper」
。Whisper是OpenAI开发的一个
「ASR」
(AutomatedSpeechRecognition,主动语音识别)开源模型,用于将语音转录成文本。它是一个强盛的模型,能够处理多种语言的语音输入,支持实时转录、语音翻译等功能,并且在差别的音频质量和语境下都有精良的表现。
❞
Whisper 功能点
「多语言支持」
:能够处理多种语言的输入,并且可以举行多语言之间的翻译。
「强盛的抗噪能力」
:对嘈杂环境中的语音有很好的转录效果。
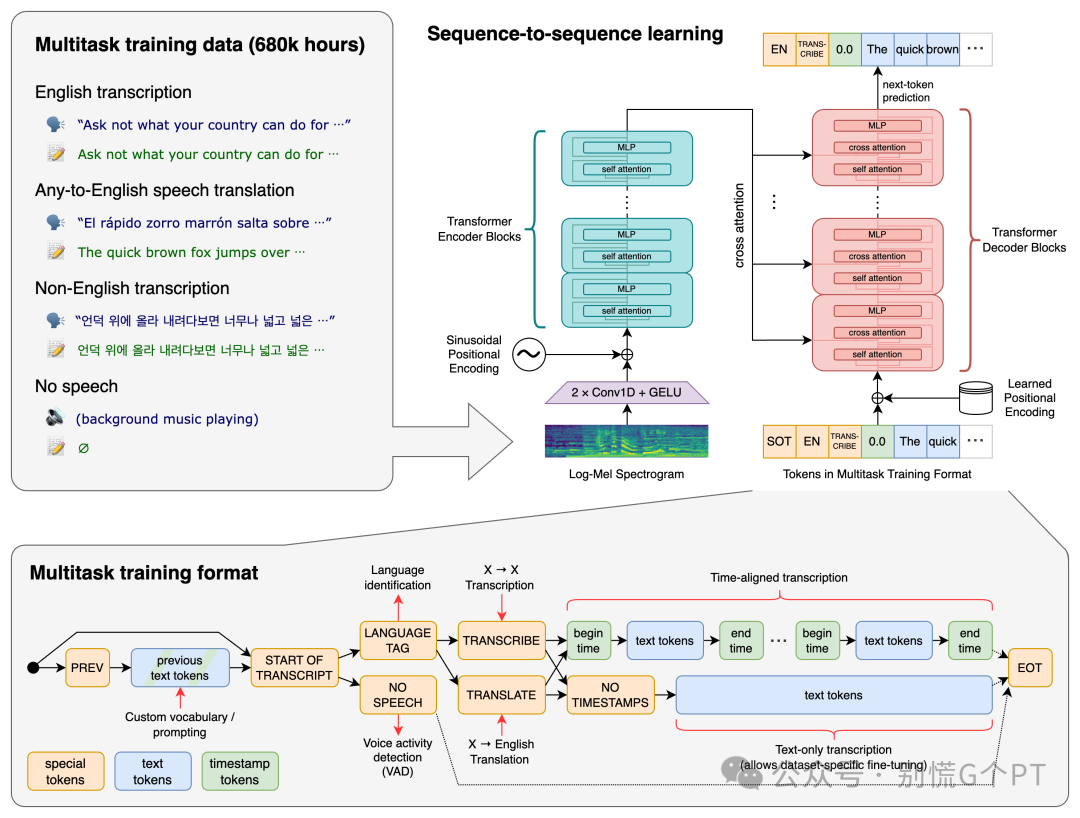
「端到端的模型架构」
:Whisper 利用 Transformer 模型,输入语音信号,输出文本。
「开源和易用性」
:Whisper 是
「开源」
的,答应开发者将其轻松集成到自己的项目中。
Whisper 应用场景
Whisper 的多功能性使得它在许多范畴都有广泛的应用:
「会议记录」
:实时转录会议或讲座的内容,方便整理记录。
「内容创建」
:播客、视频博主可以将语音内容快速转成文字稿。
「语音助手」
:集成到智能语音助手中,提升对多语言的识别和响应能力。
「教诲」
:用于生成课堂、研讨会的文字记录,方便学生回首学习内容。
Whisper 安装和利用教程
环境准备
要利用 Whisper,首先需要设置 Python 环境,并确保以下库和工具可用:
「Python 3.7+」
「PyTorch」
:Whisper 依靠 PyTorch 举行深度学习推理。
「ffmpeg」
:Whisper 需要 ffmpeg 来处理音频文件。
安装 PyTorch 和 ffmpeg
你可以按照以下步调安装:
# 安装 PyTorch
pip install torch
# 安装 ffmpeg(如果你使用 MacOS 或 Linux)
sudo apt update && sudo apt install ffmpeg
# 对于 Windows 系统,可以通过下载[ffmpeg](https://ffmpeg.org/download.html)并手动安装。
复制代码
安装 Whisper
在安装了 PyTorch 和 ffmpeg 后,可以利用 pip 来安装 Whisper:
pip install git+https://github.com/openai/whisper.git
复制代码
Whisper利用方法1(下令行)
Whisper 提供了一个简单的下令行工具来举行语音转录。你可以直接利用该工具来转录音频文件。
运行 Whisper 下令行工具
whisper audio_file.wav --model small
复制代码
此中 audio_file.wav 是你想转录的音频文件。--model small 指定了你要利用的模型大小,Whisper 支持以下几种模型:
tiny
base
small
medium
large
模型越大,精度越高,但需要更多的计算资源。你可以根据自己的需求选择符合的模型。
转录结果生存为文本文件
你可以将转录结果生存到文件中:
whisper audio_file.wav --model small
--output_format txt
复制代码
这将生成一个与音频文件同名的 .txt 文件,里面包罗转录的文本。
Whisper利用方法2(Python脚本)
除了下令行工具,Whisper 还可以直接在 Python 中利用,你可以将它集成到自己的项目中。
Python 利用示例
import whisper
# 加载模型
model = whisper.load_model("small")
# 转录音频
result = model.transcribe("audio_file.wav")
# 打印转录结果
print(result["text"])
复制代码
Whisper 的 transcribe 方法可以处理多种格式的音频文件,如 wav, mp3, ogg 等。
模型参数配置
在利用 transcribe 方法时,你可以通过传递额外的参数来更改模型活动:
result = model.transcribe("audio_file.wav", language="zh", task="translate")
复制代码
Whisper 模型提供了一些重要参数用于音频转文本的过程,资助开发者根据差别需求调整模型的活动。以下是一些关键参数:
「model_size」
:模型的大小有多种选择,分别为 tiny, base, small, medium, large,模型越大,准确率越高,但计算资源要求也越高。模型的选择通常取决于性能与速率之间的平衡。
「language」
:用于指定音频的目标语言。如果设置为 'auto',Whisper 会主动检测语言。你也可以指定具体的语言,例如 'en' 表现英语,'zh' 表现中文等。
「task」
:可以是 transcribe 或 translate。transcribe 用于将音频直接转录为文本,translate 用于将非英语音频翻译成英语文本。
「temperature」
:控制模型的随机性。较高的温度会让模型生成更多样化的结果,但准确度可能降落。默认设置通常是 0。
「beam_size」
:在解码过程中利用的搜索范围。值越大,解码过程越慢,但通常生成的文本更准确。
「best_of」
:该参数界说了模型在生成差别转录结果时保留最佳结果的计谋。较高的值可能会提高准确性,但也会增加处理时间。
「fp16」
:如果设置为 True,Whisper 将利用 16 位浮点数举行计算,从而加速推理过程并淘汰内存占用,得当在有 GPU 的环境下利用。
「verbose」
:控制是否打印转录的具体信息。设置为 True 时,将输出更多调试信息。
「temperature_increment_on_fallback」
:当首次推理失败时,增加的温度值,资助模型在不确定的环境下生成更好的结果。
「initial_prompt」
:可以为转录任务提供一个初始提示,资助模型生成更符合上下文的结果。
这些参数在利用 Whisper 模型时可根据实际场景灵活调整,以满意精度、速率和计算资源等方面的差别需求。
Whisper 模型的选择
Whisper 提供了多种差别大小的模型,选择符合的模型可以根据你的硬件条件和实际需求来决定。
模型参数数目大小速率精度tiny39 M~75 MB非常快底子base74 M~140 MB快普通small244 M~450 MB中等高medium769 M~1.5 GB较慢非常高large1550 M~3 GB慢极高 对于低计算能力的设备(如条记本电脑或轻量级服务器),small 或 medium 模型是较为保举的选择。如果你拥有高性能 GPU,可以选择 large 模型来得到最佳的转录效果。
常见问题与解答
Whisper 得当实时转录吗?
Whisper 可以用于实时转录,但性能依靠于利用的模型大小和硬件条件。tiny 和 base 模型得当实时应用,而较大的模型如 large 则可能会有较高的延迟。
Whisper 如那边理多语言音频?
Whisper 能够主动检测输入音频的语言,并输出相应语言的转录文本。你也可以通过 language 参数指定特定的语言。
Whisper 是否支持音频的分段转录?
是的,Whisper 会主动处理长音频文件,并将其分成多个段落举行转录,最终合并为完整的转录文本。
更多内容
「Github」
https://github.com/openai/whisper
「Blog」
https://openai.com/index/whisper/
「Paper」
https://arxiv.org/abs/2212.04356
「Model Card」
https://github.com/openai/whisper/blob/main/model-card.md
「Colab Example」
https://github.com/openai/whisper/blob/main/model-card.md
免责声明:如果侵犯了您的权益,请联系站长,我们会及时删除侵权内容,谢谢合作!更多信息从访问主页:qidao123.com:ToB企服之家,中国第一个企服评测及商务社交产业平台。
欢迎光临 IT评测·应用市场-qidao123.com (https://dis.qidao123.com/)
Powered by Discuz! X3.4