IT评测·应用市场-qidao123.com技术社区
标题:
踩坑完毕:手把手带你使用Flink尝鲜Paimon入门案例(强烈建议收藏)
[打印本页]
作者:
用户国营
时间:
2025-3-26 10:26
标题:
踩坑完毕:手把手带你使用Flink尝鲜Paimon入门案例(强烈建议收藏)
本文为大家讲授如何使用Flink完成Paimon官方的入门案例,建议大家收藏(对英文文档有恐惧感)。
本文会用到Flink情况,还不清晰如何摆设Flink的同砚可以检察:
《基于Flink CDC实现Mysql实时同步到Doris系列教程一:Flink情况的摆设》
本文演示使用的Ubuntu情况。
下载并解压Flink
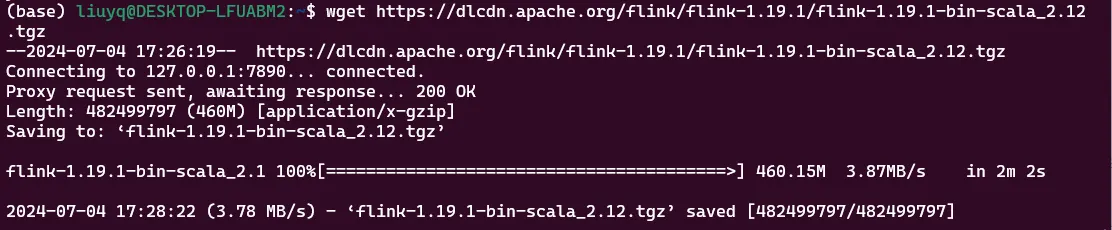
下载最新版本的Flink
wget https://dlcdn.apache.org/flink/flink-1.19.1/flink-1.19.1-bin-scala_2.12.tgz
复制代码
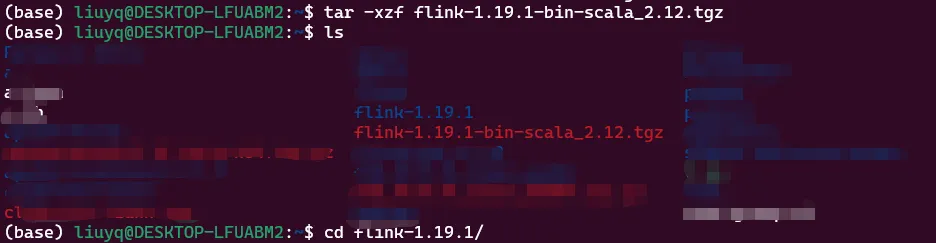
解压后会得到flink-1.19.1文件夹,并cd进入该目录。后续全部的操纵都是在该目录下执行。
tar -xzf flink-1.19.1-bin-scala_2.12.tgz
cd flink-1.19.1
复制代码
下载Paimon的jar包
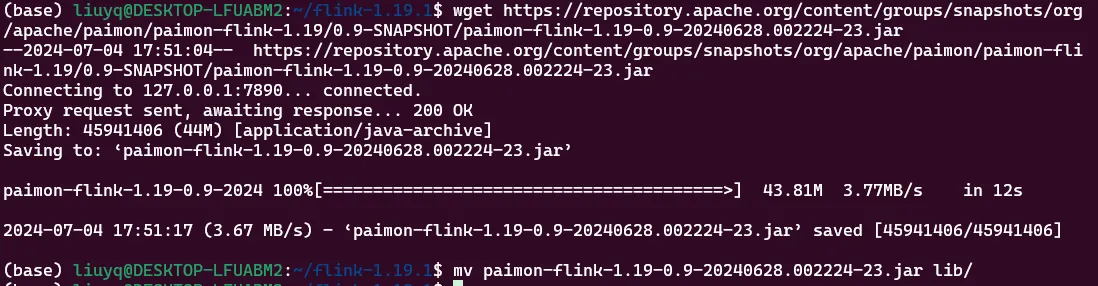
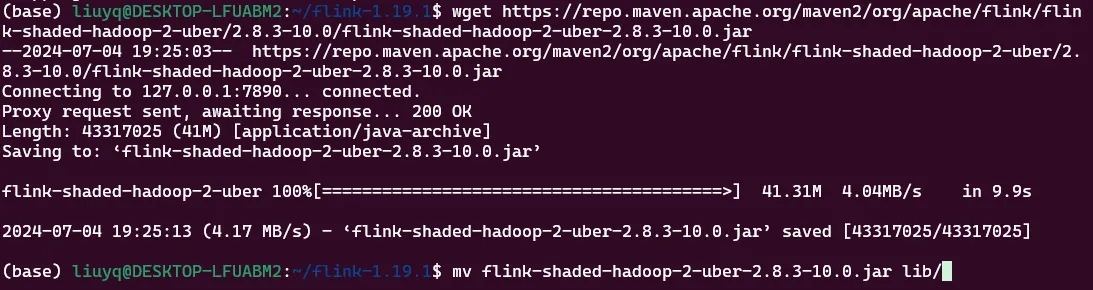
使用Paimon必要用到paimon-flink.jar和flink-shaded-hadoop-2-uber-2.8.3-10.0.jarjar包,下载与Flink相对应的版本,并复制到flink-1.19.1/lib目录下。
wget https://repository.apache.org/content/groups/snapshots/org/apache/paimon/paimon-flink-1.19/0.9-SNAPSHOT/paimon-flink-1.19-0.9-20240628.002224-23.jar
mv paimon-flink-1.19-0.9-20240628.002224-23.jar lib/
wget https://repo.maven.apache.org/maven2/org/apache/flink/flink-shaded-hadoop-2-uber/2.8.3-10.0/flink-shaded-hadoop-2-uber-2.8.3-10.0.jar
mv flink-shaded-hadoop-2-uber-2.8.3-10.0.jar lib/
复制代码
启动Flink
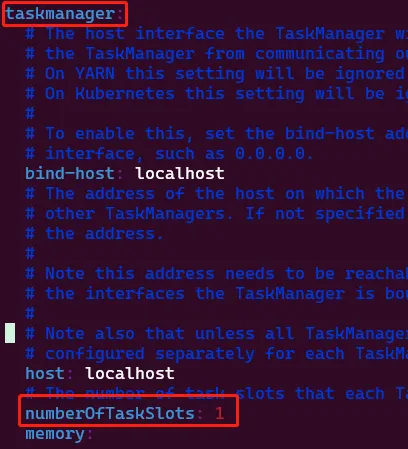
在启动Flink之前,一定要注意,必要修改一个设置,否则后续会报错(非常打击士气)。
在flink-1.19.1/conf/conf.yaml中找到taskmanager,修改numberOfTaskSlots设置为2,numberOfTaskSlots表示可以同时运行的使命数,也可以修改的更大一点。
启动Flink情况
./bin/start-cluster.sh
复制代码
访问Flink Web UIhttp://localhost:8081。
启动Flink Sql客户端
./bin/sql-client.sh
复制代码
出现上图则代表成功了。
创建Catalog和表
create catalog my_catalog with (
'type'='paimon',
'warehouse'='file:/home/liuyq/paimon'
);
复制代码
注意,此处file:/home/liuyq/paimon为本地的一个绝对路径,会主动创建paimon文件夹。
可以看到,paimon文件夹下会有default.db,代表我们创建的my_catalog下有一个默认的default数据库。
切换到我们要使用的my_catalog下
use catalog my_catalog;
复制代码
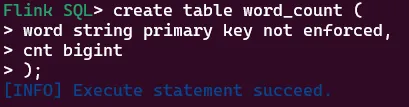
创建word_count表
create table word_count (
word string primary key not enforced,
cnt bigint
);
复制代码
此时,我们观察一下文件夹,发现多出来word_count文件夹,对应的正好就是我们刚刚创建好的表。
我们再看一下文件夹内的文件
写入数据
创建一个暂时表,用于模仿天生单词
create temporary table word_table (
word string
) with (
'connector' = 'datagen',
'fields.word.length' = '1'
);
复制代码
datagen连接器用于模仿天生数据,该表中只有一个字符串字段word,而且使用fields.word.length指定天生的数据长度为1,注意此处1要带引号,否则会报错。天生的值如:a、b、c、1、2等。
设置checkpoint时长并写入数据
set 'execution.checkpointing.interval' = '10 s';
insert into word_count select word, count(*) from word_table group by word;
复制代码
insert into操纵相称于给flink中提交了一个实时计算的使命。该使命会把10s内word_table新产生的word数据聚合计算个数后把效果存入到word_count表中。
OLAP查询
设置查询效果的样式为tableau
set 'sql-client.execution.result-mode' = 'tableau';
复制代码
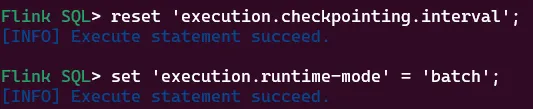
从流处理模式切换到批处理模式
reset 'execution.checkpointing.interval';
set 'execution.runtime-mode' = 'batch';
复制代码
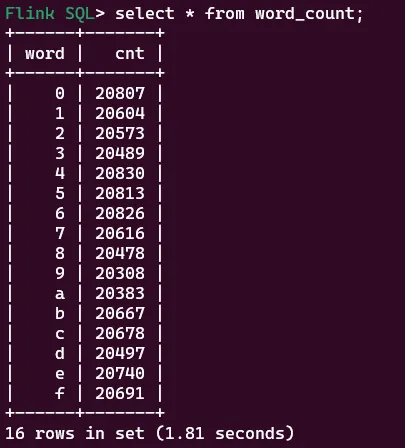
查询word_count表中的数据
select * from word_count;
复制代码
如何你卡在这里没有任何反应,说明你忘记修改numberOfTaskSlots设置了,只必要退出后修改,再重复上面的操纵即可。
批处理模式下的一次查询,也相称于给Flink中提交了一个使命,只不外该使命执行一次完成后就竣事了。
流式查询
切换到流模式下
set 'execution.runtime-mode' = 'streaming';
复制代码
实时查询
select `interval`, count(*) as interval_cnt from (select cnt / 10000 as `interval` from word_count) group by `interval`;
复制代码
拉到最下面,仔细观察,你会发现数据每个约莫10s会有变更。
此时,也相称于在Flink中提交了一个使命
在界面上取消使命,就会看到刚才的实时查询也中断了。
退出
退出SQL客户端
exit;
复制代码
停止Flink情况
./bin/stop-cluster.sh
复制代码
至此,一个我们完整体验了在Flink中使用Paimon。
进阶
现在,如果问你Paimon是什么?你心中会有怎样的答案呢。我们再看一下/paimon/default.db/word_count下面有什么
这时我们是不是可以说Paimon是具有严格布局的一组文件夹和文件的组合,这些文件会描述出数据库、数据表、数据等,用这种方式表达数据库也正是数据湖。
有一点点绕,希望大家可以体会到。想要学习更多Paimon干系的内容,可以关注:遇码,复兴
Paimon
获取官方文档。
免责声明:如果侵犯了您的权益,请联系站长,我们会及时删除侵权内容,谢谢合作!更多信息从访问主页:qidao123.com:ToB企服之家,中国第一个企服评测及商务社交产业平台。
欢迎光临 IT评测·应用市场-qidao123.com技术社区 (https://dis.qidao123.com/)
Powered by Discuz! X3.4