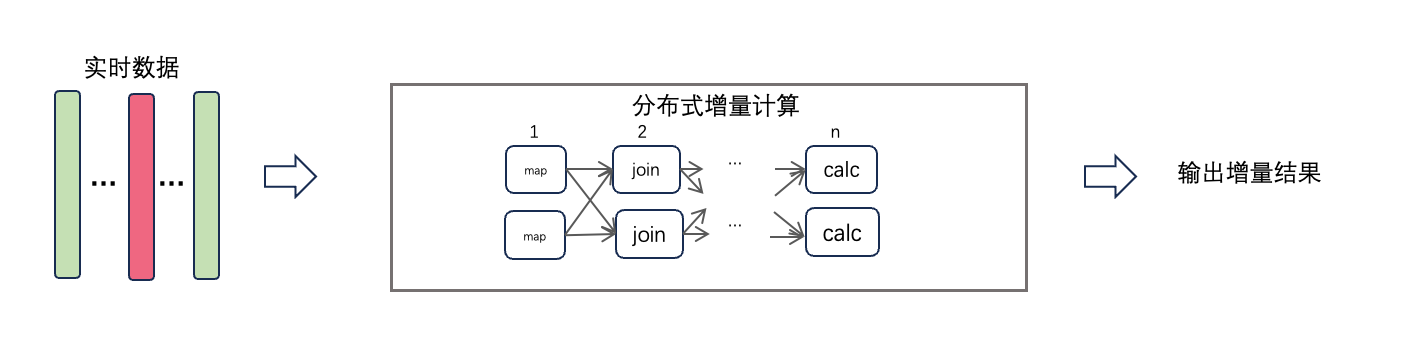
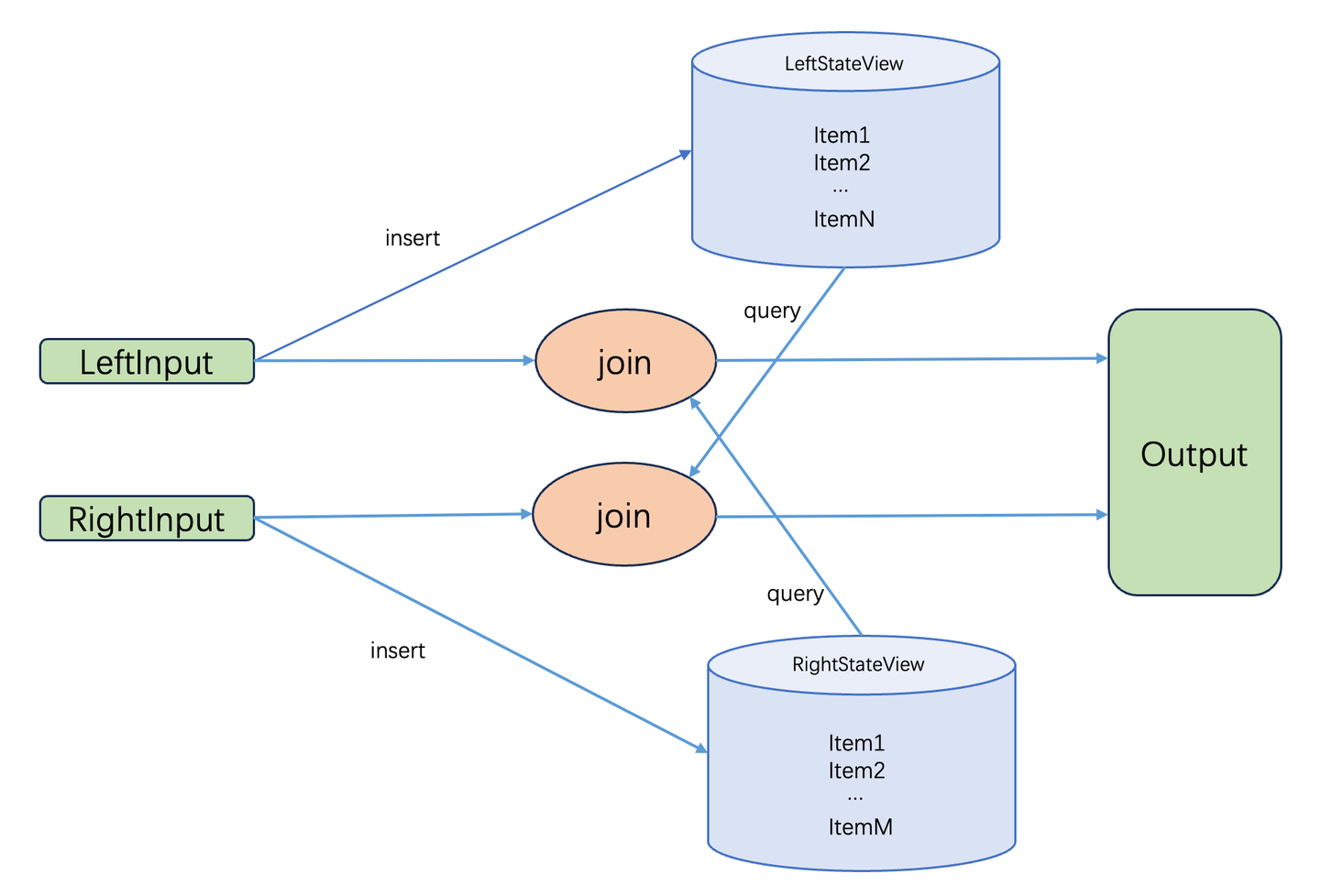
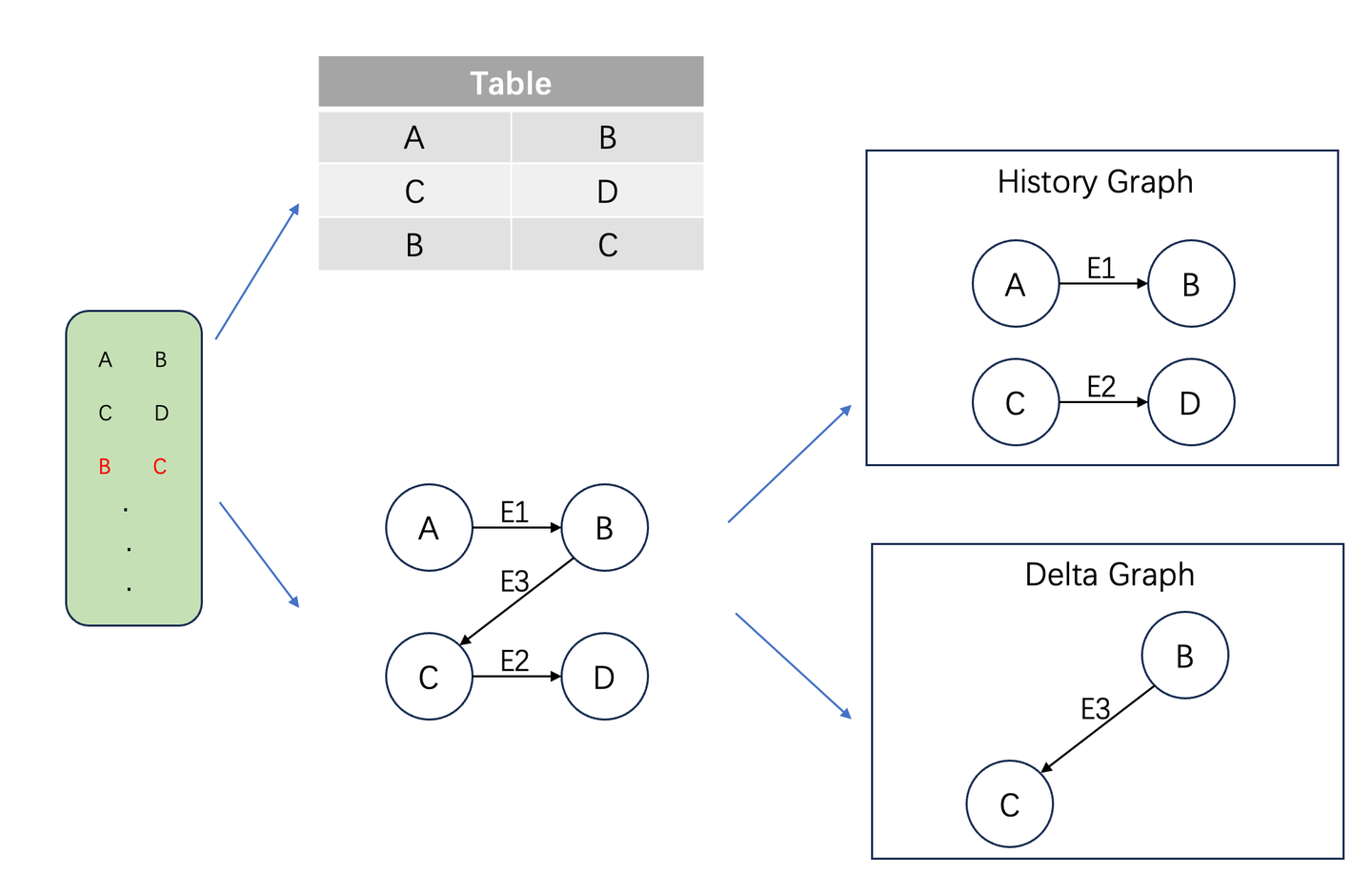
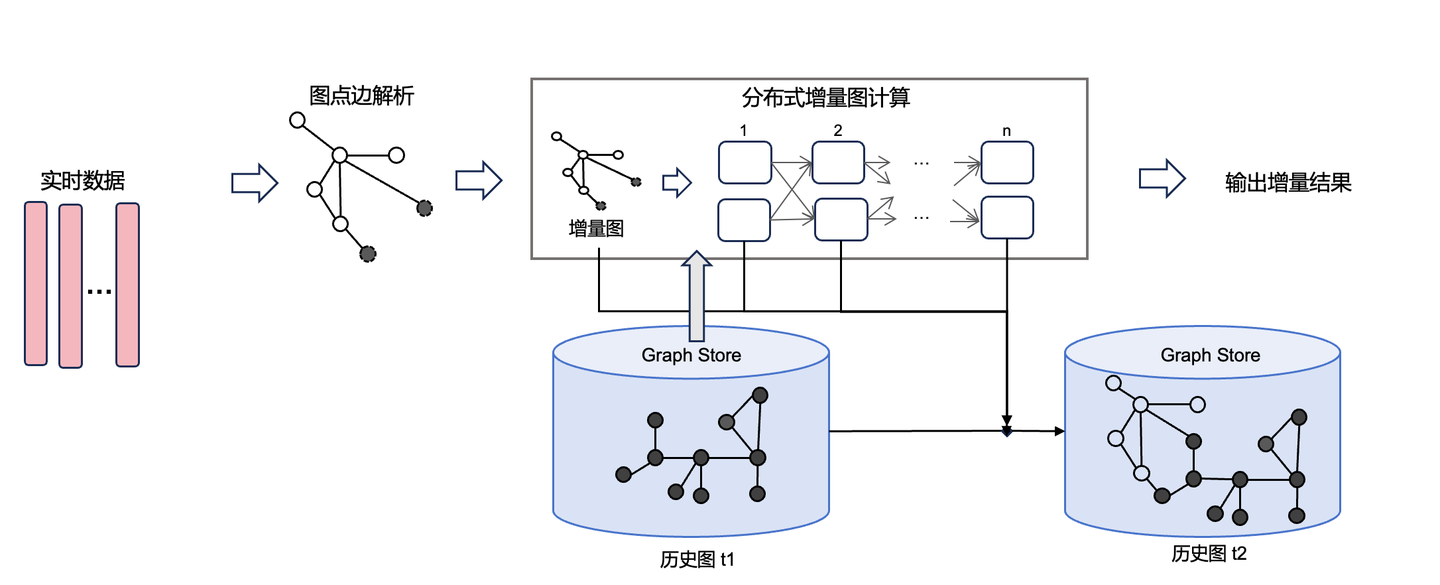
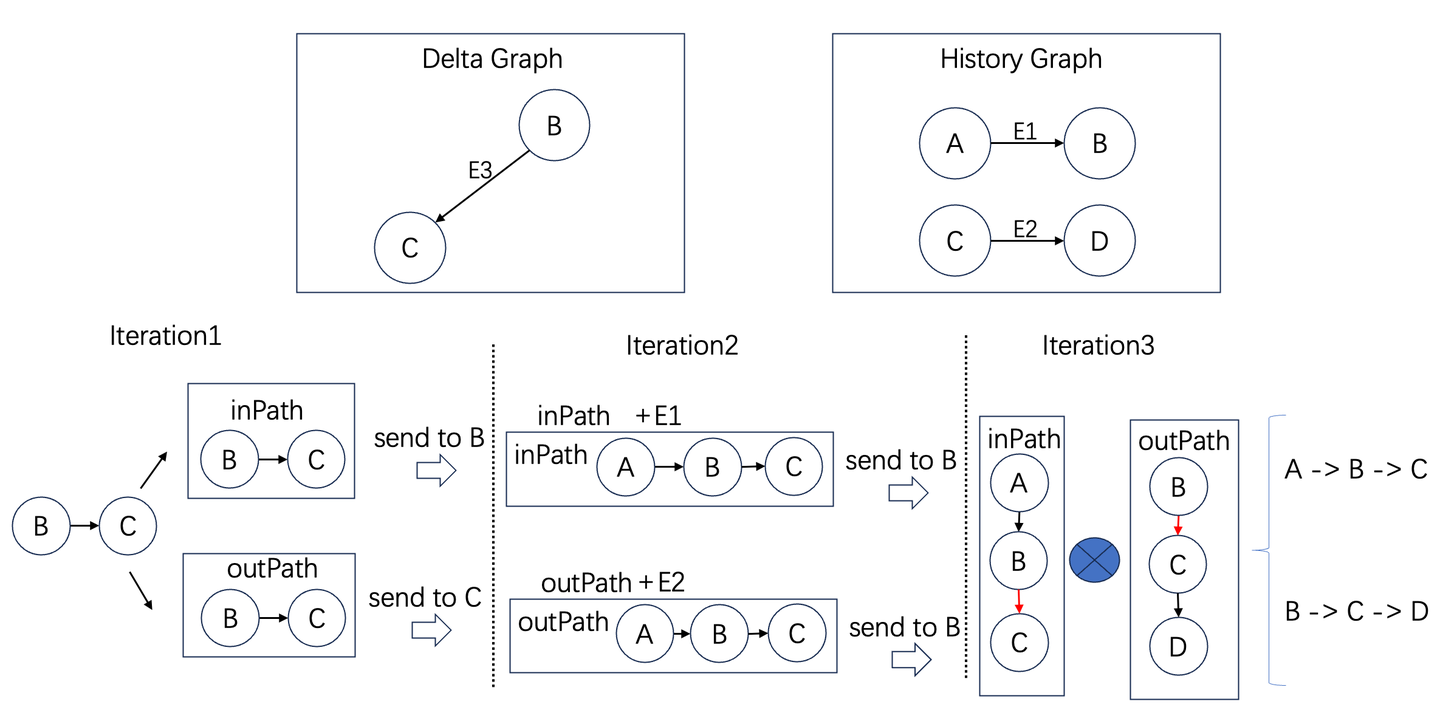
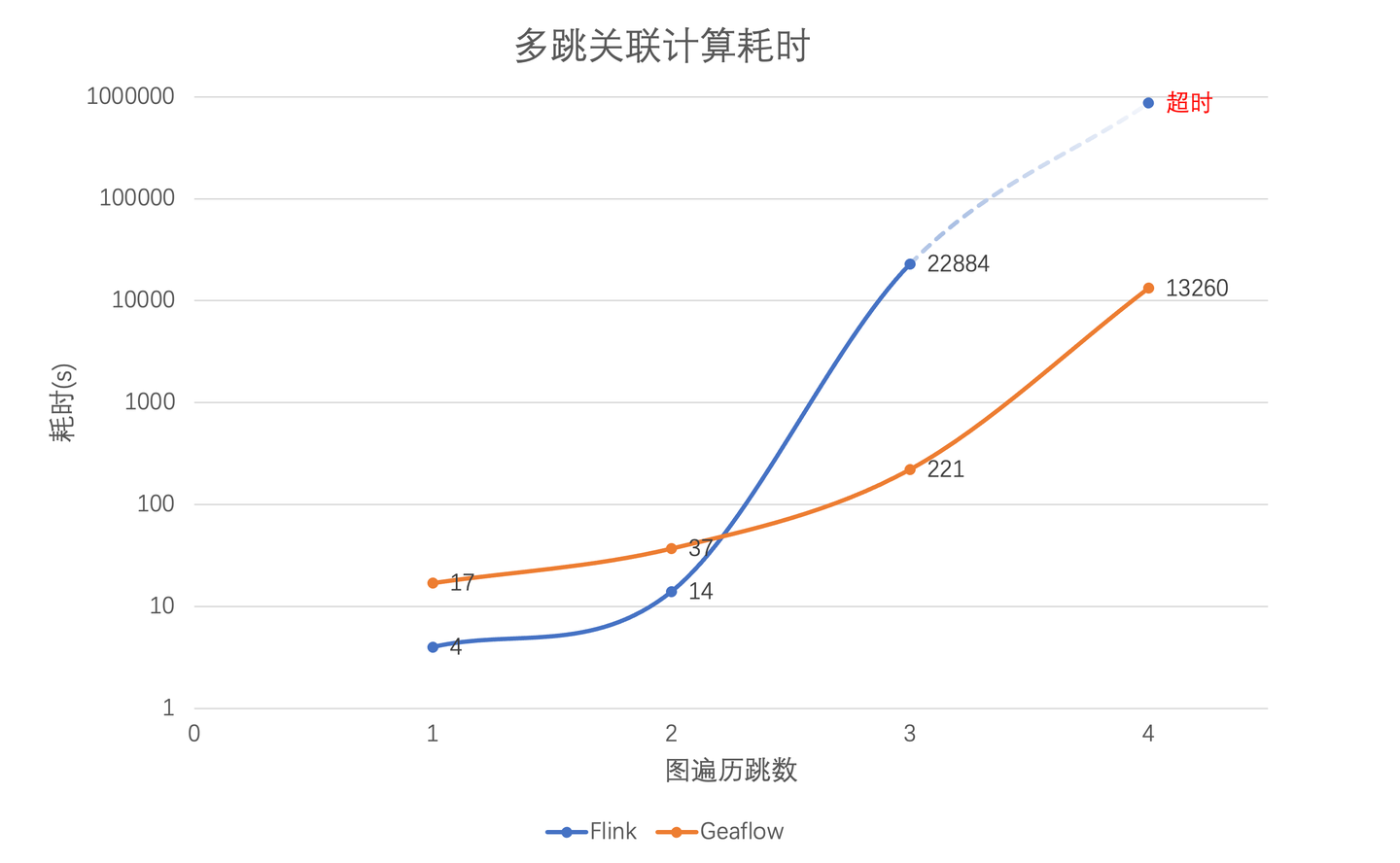
传统的Flink等流计算引擎在计算关联关系时需要用到join算子,join算子需要遍历全量的历史数据,这使得他们在大数据关联计算场景中性能不佳。GeaFlow引擎通过支持流图计算框架,将图计算引入到流计算中,采用增量图计算的方法大大提升了实时数据的处理惩罚系性能。
目前GeaFlow项目代码已经开源,我们希望基于GeaFlow构建面向图数据的统一湖仓处理惩罚引擎,以解决多样化的大数据关联性分析诉求。同时我们也在积极筹备加入Apache基金会,丰富大数据开源生态,因此非常接待对图技能有浓厚爱好同学加入社区共建。
社区中有诸多有趣的工作尚待完成,你可以从如下简朴的「Good First Issue」开始,等候你加入偕行。