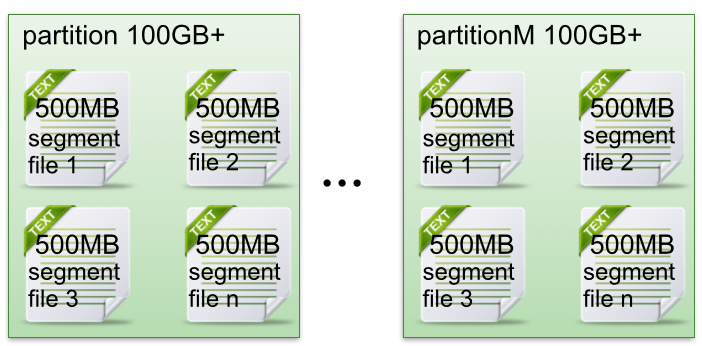
上述图3中索引文件存储大量元数据,数据文件存储大量消息,索引文件中元数据指向对应数据文件中message的物理偏移地址。 其中以索引文件中元数据3,497为例,依次在数据文件中表示第3个message(在全局partiton表示第368772个message)、以及该消息的物理偏移地址为497。
从上述图3相识到segment data file由许多message组成,下面详细说明message物理结构如下:
从上述图3可知这样做的优点,segment index file采取稀疏索引存储方式,它减少索引文件大小,通过mmap可以直接内存操作,稀疏索引为数据文件的每个对应message设置一个元数据指针,它比稠密索引节流了更多的存储空间,但查找起来需要斲丧更多的时间。
3 Kafka文件存储机制–现实运行效果