
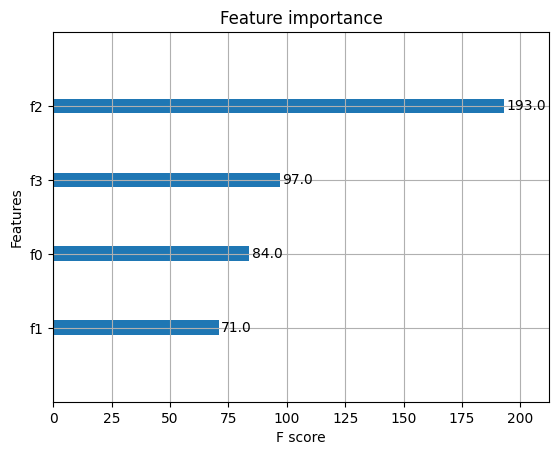
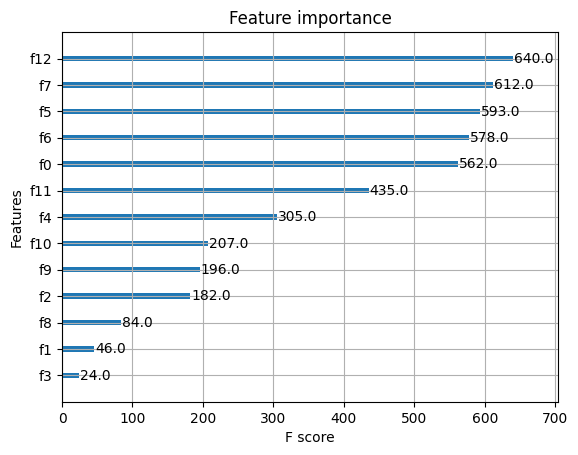
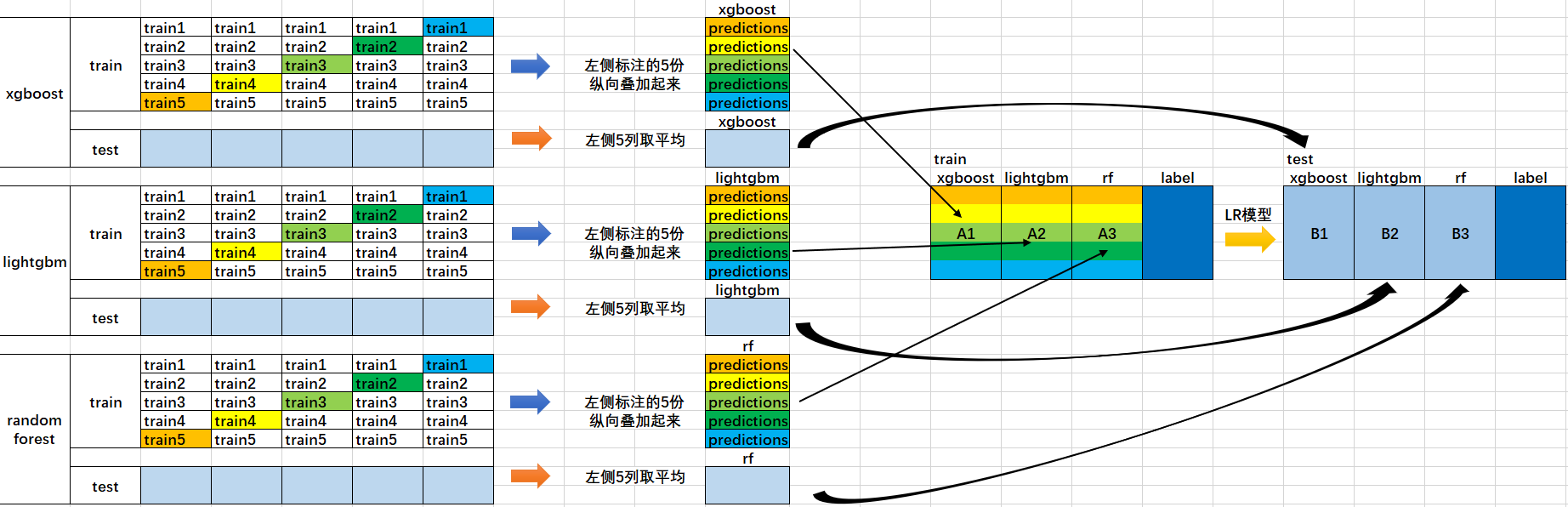
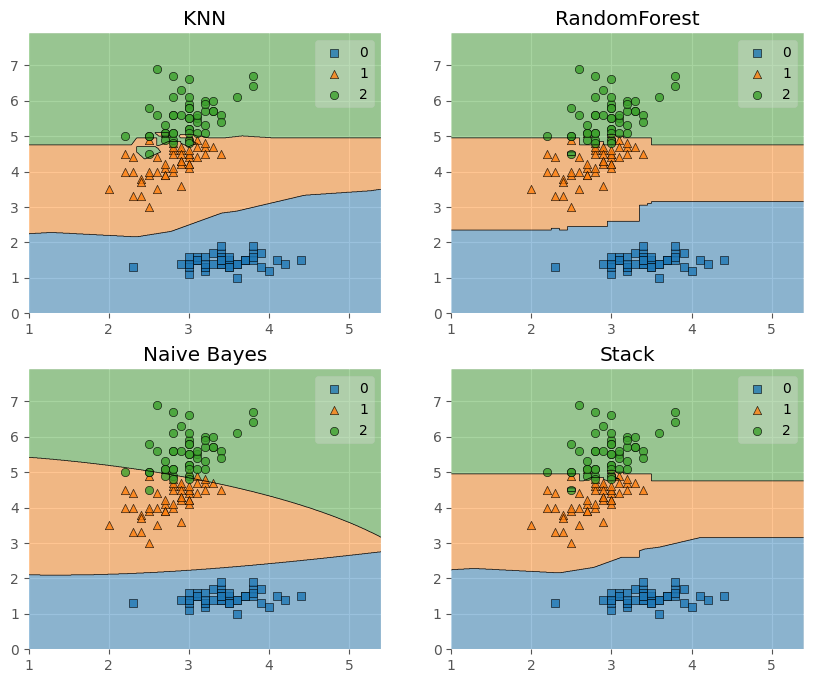
- (0, 0, 0)
- (0, 0, 1)
- (0, 1, 0)
- (0, 1, 1)
- (1, 0, 0)
- (1, 0, 1)
- (1, 1, 0)
- (1, 1, 1)
- plt.figure()
- gs=gridspec.GridSpec(3,3)#分为3行3列
- ax1=plt.subplot(gs[0,:])
- ax1=plt.subplot(gs[1,:2])
- ax1=plt.subplot(gs[1:,2])
- ax1=plt.subplot(gs[-1,0])
- ax1=plt.subplot(gs[-1,-2])