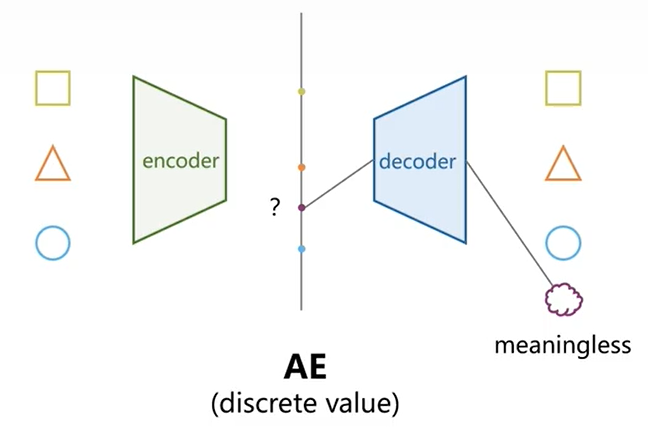
AE是一个特征提取模型,通过编解码的形式重构输入,完成低维特征表示工作推导
VAE与AE最大的不同在于,提出潜变量z的概念,将潜变量z由离散的分布->连续的分布,这使得生成模型得以实现,由于z可以从连续分布中恣意采样,大大的增大了作为生成模型的性能。1. 加点噪声吧
[!NOTE]上述形貌与真实的VAE还存在一些不同:
现实上,这是CVAE的特征分布示意图,每种类图像(以MNIST为例)的\(z_i\)潜变量分布都对应有一个\(\mu_Y\)均值、1为方差的高斯分布
[!question] 为什么AE中也可以采样,但是VAE采样可以生成有意义图形?现在还存在一个问题,就是\(z\)和\(x\)不匹配,如果\([\mu, \sigma] \sim [\mu(X),\sigma(X)]\),那么我采样出来的\(z\)到底是对应了哪个\(x\)呢?我解码后的\(\hat{x}\)又该和哪个\(x\)去做对比呢?以是我们提出\(z \sim q(z|x)\):
- AE的\(z\)与\(x\)之间是一一对应的,没有经过训练的\(z_i\)没有对应的物理寄义;
- VAE中每次训练都强制性把\(q(z|x)\)后验分布约束为一个\(N(0,I)\)分布,这样每次训练都经历这一步,后续我从\(N(0,I)\)分布中就算采样得到的\(Z\)并没有在训练中出现过,也能实现保存部分特征的效果;
- 从数学的角度而言,每次训练过程中是从如下分布取到的,而正则化项迫使\(\mu(x)->0\)、\(\sigma(x)->1\)形成一个标准的正态分布;然而重构损失项也会为了尽可能高的精度去抹平噪声项\(\sigma(x)\),并且使得\(\mu(x)\)还原回原先AE中离散的位置。这种天然的对抗其实也含有GAN中对抗的哲学,并且终极形态也可知\(q(z|x)\)一定不是一个标准正态分布,而是保存了其趋向于表征其特征的\(\mu(x)\)的趋势,因此这也可以解释为什么VAE的潜变量空间会呈现一定的分块或者说聚类性。
\[z \sim q(z|x) = N(\mu(x);\sigma(x)I)\]
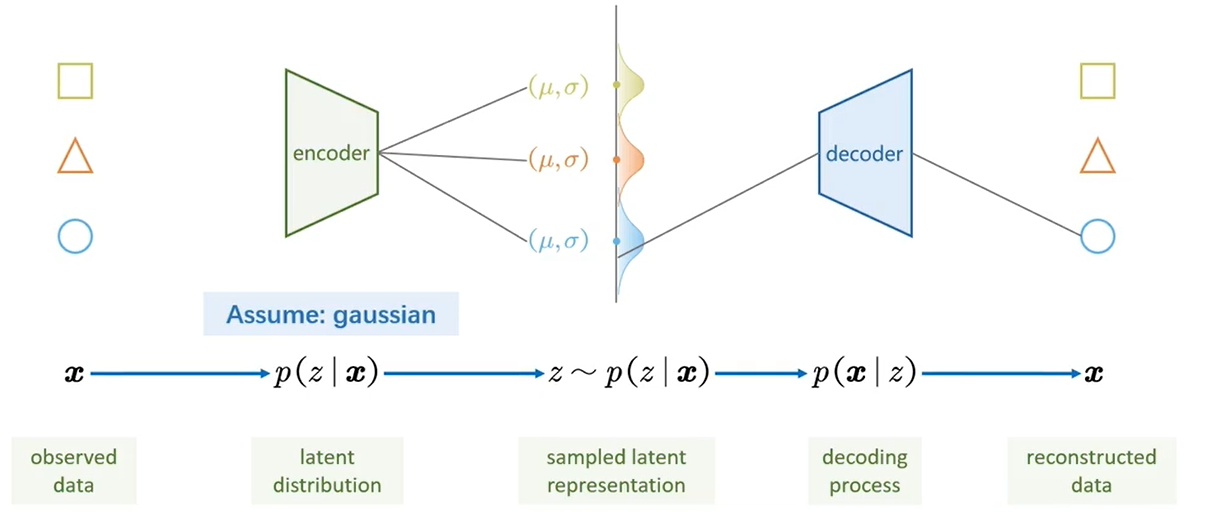
[!NOTE]那么转换一下思路,不能求解\(p(z|x)\),我还不能拟合一个和\(p(z|x)\)近似的分布吗?答案是当然可以,不妨假设一个分布\(q(z|x)\)。让这二者逼近的同时,保存\(q(z|x)\)的高斯分布特性,那么届时也可完成\(z\)的采样、解码等后续操作。
主要是在分母中涉及到对z求边缘积分,我的理解是z是没有边际的很难求解
现有生成服从均匀分布的一个随机数生成程序,那怎样据此去做一个生成符合正态分布的随机数据呢?即,怎样从均匀分布XU[0,1]转化为正态分布YN(0,1)?
[!NOTE]其中\(\Phi(y)\)是指标准正态分布的累计分布函数(Cumulative Distribution Function)
为什么说[x, x+dx]区间的概率和[y, y+dy]区间的概率雷同?
- 上面的区间概率现实上只是连续概率密度函数中,盘算一个点对应的概率值,针对\(X\)的样本记作\(\rho(x)\),针对\(Y\)的样本记作\(\phi(y)\);
- 倒推来说,我们盼望最后服从均匀分布的随机数程序生成一个数,例如0.7,我们盼望它能经过映射关系f后转化到对应的正态分布数据0.5244(现实上我们盼望一个服从正态分布的随机数程序可以直接生成这个数),以是换言之,我们盼望均匀分布随机数程序生成0.7的概率和正态分布随机数程序生成0.5244的概率是雷同的,是一种一一对应的映射关系;
给我一个支点,我就可以翘起一个地球的豪迈,基本上一个显式或隐式的函数都可以通过神经网络拟合得到。
[!NOTE]通常来说,两个分布的接近程度我们可以使用
重点留意这里,X和Y都大写表示分布,如上文所述是分布到分布的映射。
[!NOTE] Example留意到\(y\)是由\(G(X;\theta)\)生成的,以是应该使用\(p_y(I_i;\theta)\)表示,那么我们可以通过构建:
我现在有\(\{1.2, 1.5, 2.3, 3.1, 3.6, 4.0, 4.2, 5.7, 6.1, 6.8\}\)这些数据,我必要评估这些数据背后的分布,使用上述公式整体步骤如下:
- 划分区间,\(I_1=[1,3)、I_2=[3,5)、I_3=[5,7)\);
- 统计落在每个区间内的个数,\(C(I_1)=3、C(I_2)=4、C(I_3)=3\);
- 盘算\(p(I_1)=\frac{3}{10}=0.3、p(I_2)=\frac{4}{10}=0.4、p(I_3)=\frac{3}{10}=0.3\);
[!NOTE]但是这种算法,我应该保障:输入顺序的改变(shuffle)不改变数据的分布,以是必要举行一步无序化的操作,这类操作在盘算离散的样本之间的分布隔断(尤其是在聚类使命中)经常用到:
GAN的高明之处就在于,连隔断都是暴力求解的,相比VAE使用KL散度去衡量\(q_\phi(z|x)\)和\(p_\theta(z|x)\)之间的隔断,VAE简直太文艺了。尤其留意一点,我这里也不使用\(p_y(I_i)\)频率去估计给出样本的分布了,把这步变更直接放着迷经网络自己算去吧。
[!NOTE] 感性认知证明到此结束,我想说的是,在数据量够多的情况下,直接使用
一、\(-logq_{\Theta}(y_i)\)表示样本在理论分布\(Q\)下的不匹配程度或者说不符合预期程度,具体来说:
二、交叉熵\(H(P,Q)=-\int P_{emp}logQ_{\Theta}=-\mathbb{E}_{y \sim P_{emp}}[logq_{\Theta}(y)]\approx\frac{1}{M}\sum_{i=1}^Mlog-q_{\Theta}(y_i)\),其实表征了全部样本的负对数似然的平均值,表示用分布Q编码真实分布P的样本所必要的平均信息量;
- 如果\(q_{\Theta}(y_i)\)越大,表示\(y_i\)满足这个分布的可能性越高,但是\(-logq_{\Theta}(y_i)\)会越小, 表示符合预期,表示意外程度低;
- 反之,如果\(q_{\Theta}(y_i)\)越小,表示\(y_i\)满足这个分布的可能性越低,但是\(-logq_{\Theta}(y_i)\)会越大, 表示不符合预期,表示`意外程度高;
三、KL散度\(KL(P||Q)=H(P,Q)-H(P)\),本质上是,去除P本身的不确定性(熵的定义)后,Q对于P的额外信息损失,是衡量分布差异的度量(因此也可以理解\(KL(P||Q)\)和\(KL(Q||P)\)不一样啦~)
[!NOTE]根据GAN中生成器G、鉴别器D的概念,G盼望生成得到的样本足够真实,即生成得到的\(y_i\)输入D中的分数\(\mathcal{L}\)足够小(当等于0时,完全是真的);而D则盼望生成得到的\(y_i\)输入后得到的分数\(\mathcal{L}\)足够大(当等于1时,完全可以区分),并且盼望真实样本\(z_i\)输入得到的分数\(\mathcal{L}\)足够小(盼望真的可以被识别为真的)。因此这里就存在了GAN中Adversarial对抗的寄义。
值得留意的是,1和0并不总代表着真和假,它的寄义是人为赋予的。这点在代码中的损失函数构建中也可见一斑(无论是否加负号,都是成立的)。
[!NOTE]2.固定鉴别器\(D(Y;\Theta)\),通过训练\(\theta\)使得生成样本越加逼真:
这里的B指的是批次数batchsize,个人理解这是大数定理影响下的无奈妥协之举。
[!NOTE]5. 正则约束—WGAN
- \(L_1\)是真伪样本分布差(的最大值),那么\(L_1\)越小表示”伪造“样本质量越好,以是\(L_1\)是表征训练程度的指标,\(L_1\)越小表示训练的越好;
- 将\(L_1\)作为核心指标的缘故原由也和训练过程有关,由于首先必要生成一批样本,以是如果生成器太弱\(L_1\)过大的话,\(L_2\)会被要求快速的降落来使得惩罚尽可能的小,但是这也可能会导致生成器生成一些重复、保底的图片,对于训练不是很友好;以是一定程度上要求生成器强一些,\(L_1\)一开始就比较小,这样才能倒逼\(L_2\)不大且往更精致(更小)的方向去;
隔断是为了表明两个对象的差距,而如果对象产生微小的变革,那么隔断的颠簸也不能太大。
[!NOTE]至此,由VAE->GAN->WGAN的序言就结束了。
对\(y_i\)和\(z_i\)中心举行插值生成,也是思量到真实样本和生成样本之间的连接地域是最有可能违背利普西茨约束,也是最有意义对其举行约束的一个范围。
| 欢迎光临 qidao123.com技术社区-IT企服评测·应用市场 (https://dis.qidao123.com/) | Powered by Discuz! X3.4 |