CAS:Compare and swap,字面意思:“比力并交换”,是一个特殊的 CPU 指令(严格的说,和 Java 无关)(JVM 中 关于 CAS 的 API 都是放在 unsafe 包里的,unsafe 即不安全的)
一个 CAS 就会涉及到一下操作:我们假设内存中的原数据为 V,寄存器中的值是 A,需要修改的是新值 B,会有三个操作:
1. 比力原数据 V 和寄存器中的值 A 是否相等 (比力)
2. 假如比力相等,把 B 写入 V。(交换)
3. 返回操作是否成功
CAS 伪代码
此中,address 是内存地点中的值 expectValue 是寄存器中的旧值,swapValue 是寄存器中的新值。 if 语句中判断条件是,比力 address 内存地点中的值,是否和 expected 寄存器中的值相同,假如相同,就把 swap 寄存器的值和 address 内存中的值,进行交换,返回 ture;假如不相同,则啥都不敢,返回 false。(说是交换,也可以明白为“赋值”,我们往往只关注内存里最终的值,寄存器用完就不需要了~~) CAS 一条 CPU 指令 就可以完成我们上述的功能 ==》单个 CPU 指令,自己就是原子的 CAS 的线程安全题目
基于 CAS 指令,就给线程安全题目的代码,打开了一个新世界的大门!!!我们之前为了实现线程安全,往往都是依靠加锁来保证的,但一旦有了加锁,就会导致阻塞,从而就会引起性能降低。
使用 CAS,不涉及加锁,就不会导致阻塞,公道使用也是可以保证线程安全的 ==》 无所编程(是多线程编程中的一个特殊技巧)
CAS 自己的 CPU 指令,操作系统又对指令进行了封装,JVM 又对操作系统提供的 API 封装了一层,有的 CPU 可能会不支持 CAS (但我们 x86 这种主流 CPU 都是没题目的)
Java 中的 CAS 的 API 放到了 unsafe 包内里(这内里的操作, 涉及到一些系统底层的内容,使用不妥的话可能会带来一些风险,一样平常不建议直接使用 CAS)
Java 的标准库,对于 CAS 又进行了进一步的封装,提供了一些工具类,供程序员们使用。
最主要的一个工具,叫做 “原子类”
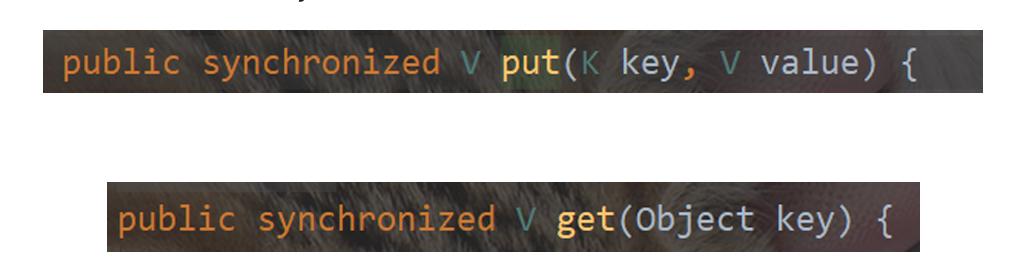
这个代码就是我们之前典范的多线程可能不安全的代码,假如定义 count 的时候,是使用 private static int count = 0,然后在线程中均使用 count++的话,就是线程不安全的!!!
但是,假如是用 AtomicInteger 定义 count(此时是一个对象了),初始值传入参数为 0,然后再线程中,使用 getAndIncrement 方法,取代了 后置++,此时这个方法,就是通过 CAS 的方式实现的,这里的代码,就没有加锁,但也能保证线程的安全!!(并且这个代码要更为高效,没有锁,也就没有阻塞,也就不会消耗效率)
之前的 count++ 是三个指令(多线程的三个指令,会相互的穿插实行,引起线程不安全,之前加锁,就是为了能让三个指令称为原子的)此处,这里的 getAndIncrement 对变量的修改,是 CAS 指令,CAS 指令自己就只是一条 CPU 指令,天然就是原子的
原子类自增的源代码:
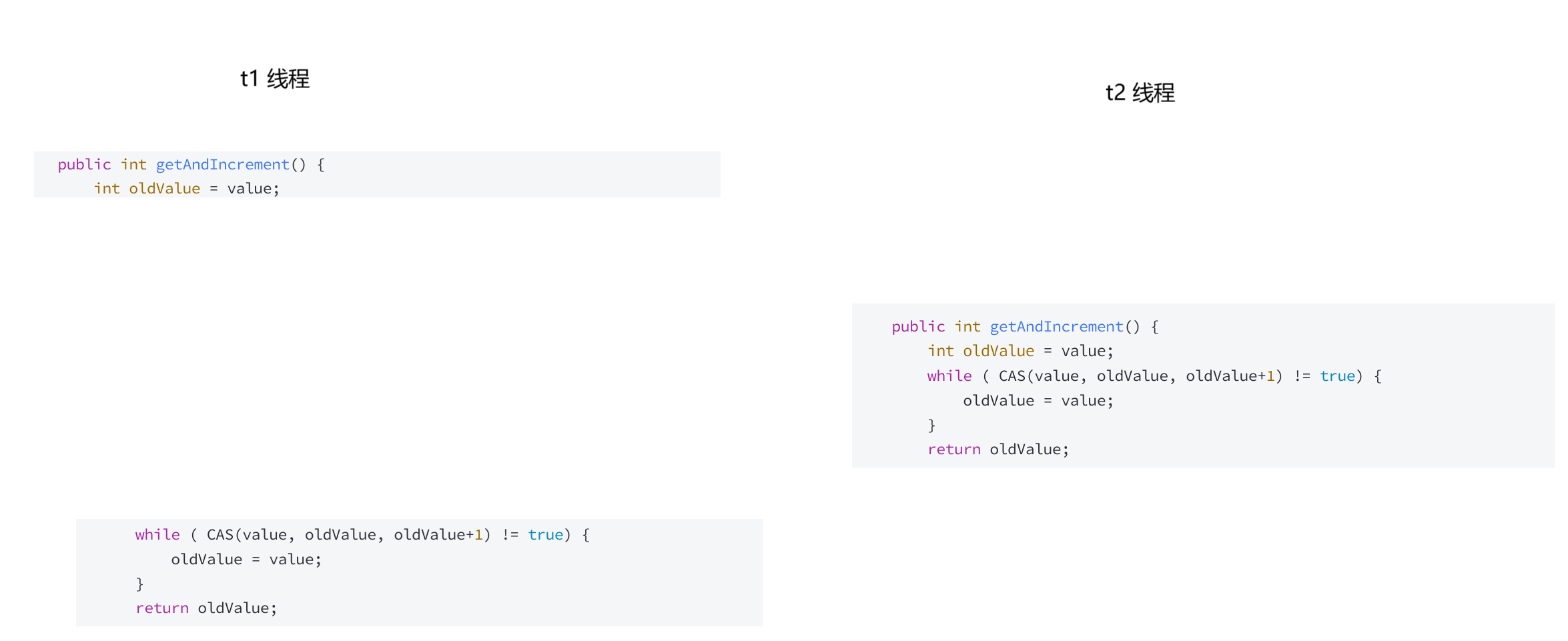
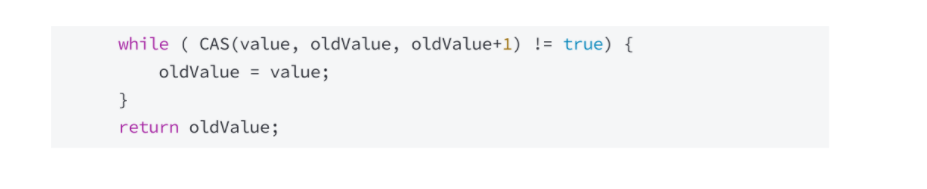
标准库中的代码,看起来有点复杂,我们可以用一段伪代码来明白:
再这段伪代码中,oldValue 渴望是一个放在寄存器内里的值,这个值就是初始化成 AtomicInteger 内里保存的整数值 value,假如内存地点的值 value 和 寄存器内里的值 oldValue 比力相同,则可以交换,oldValue + 1 和 value 交换,然后循环竣事,此时 value 已经更新成 value + 1了,假如没成功,就再来一次,直到成功为止
画图讲解:
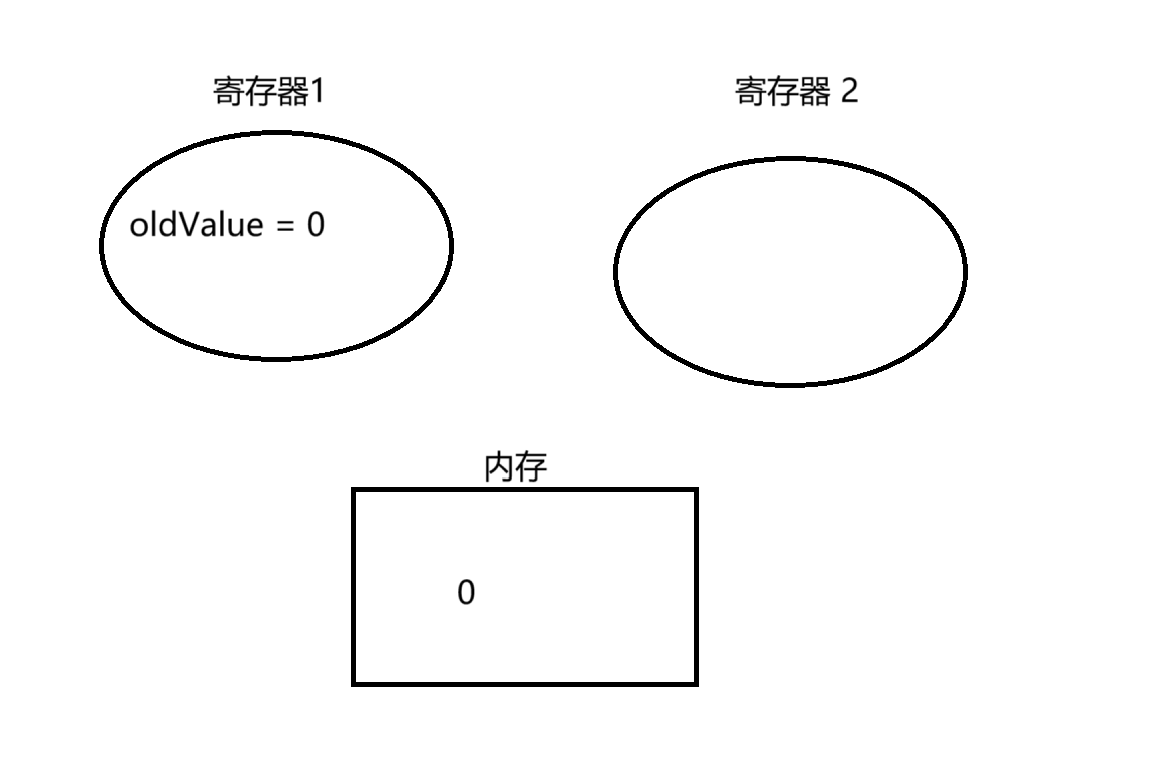
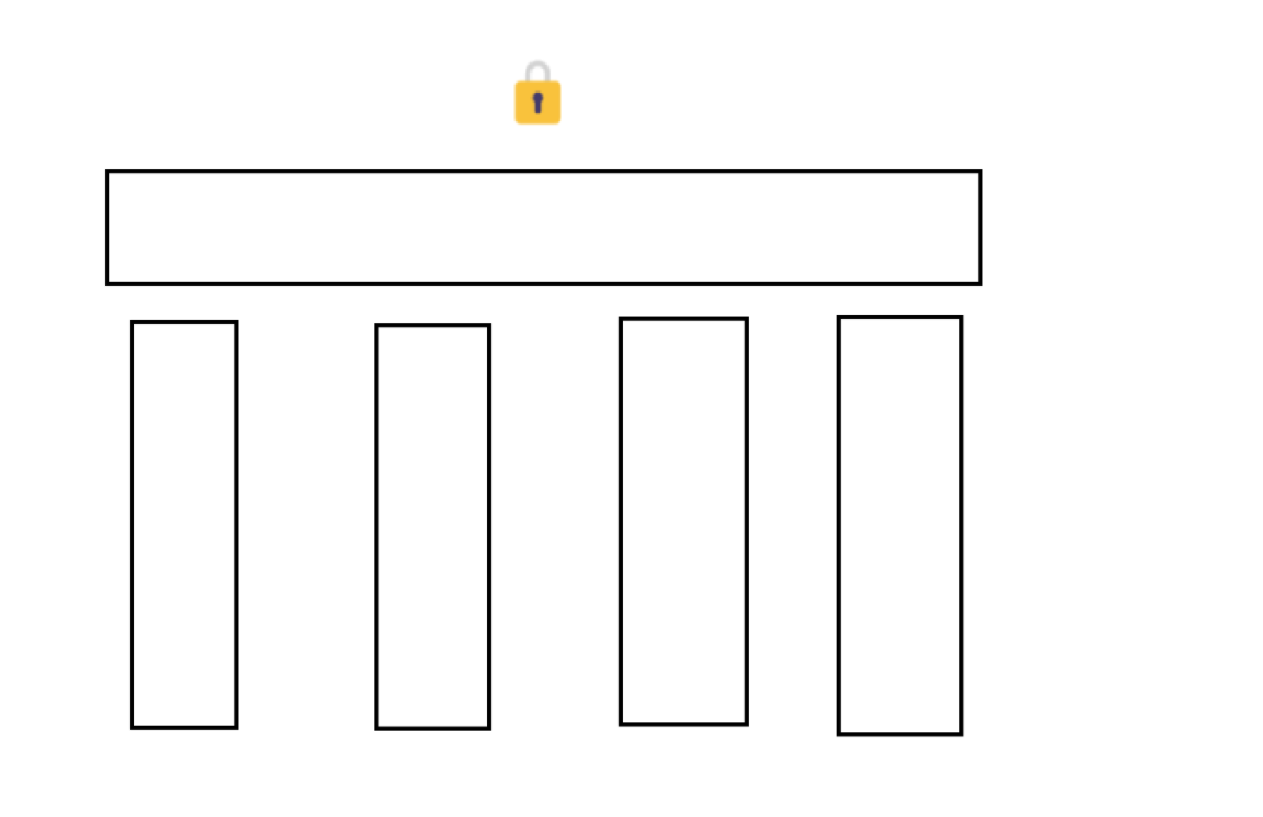
如下图为多线程环境下:
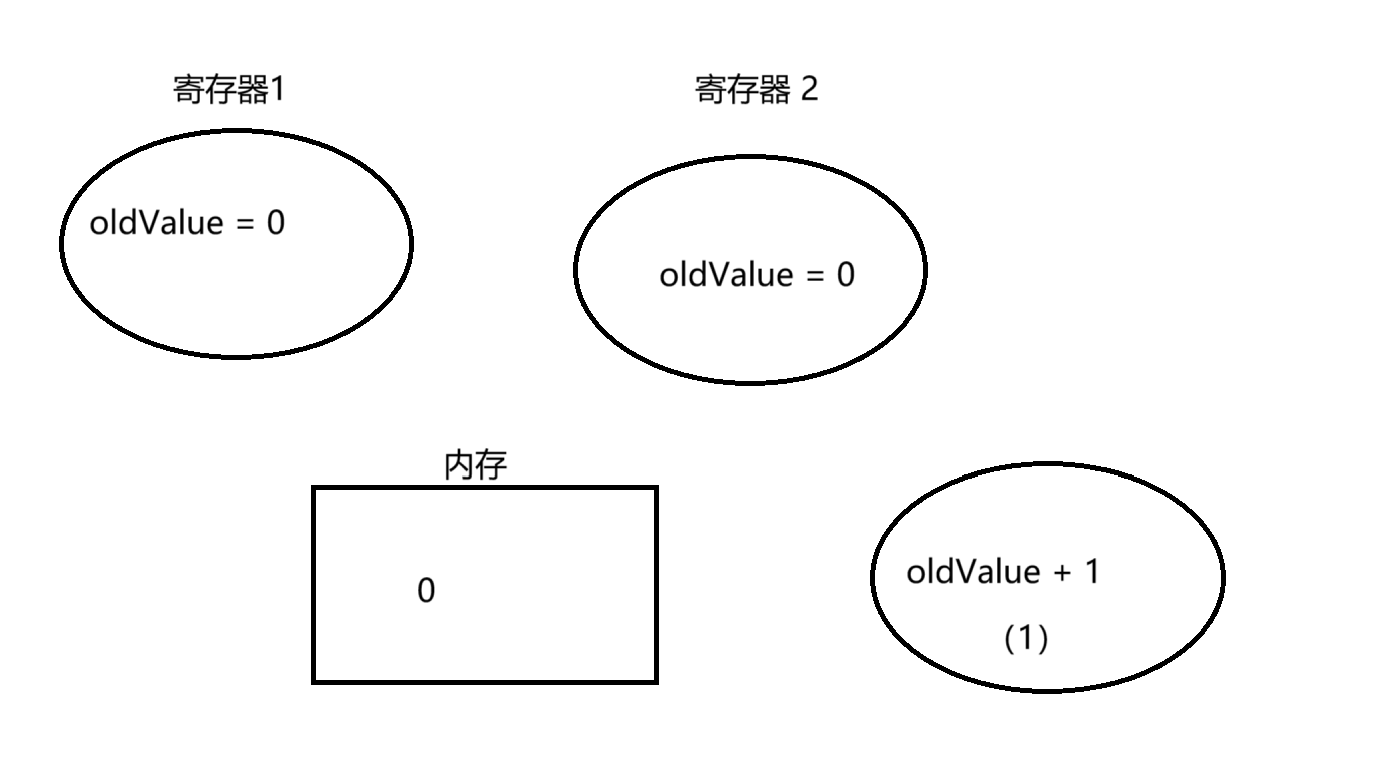
最开始我们初始化 value 为 0
多线程实行 ==》
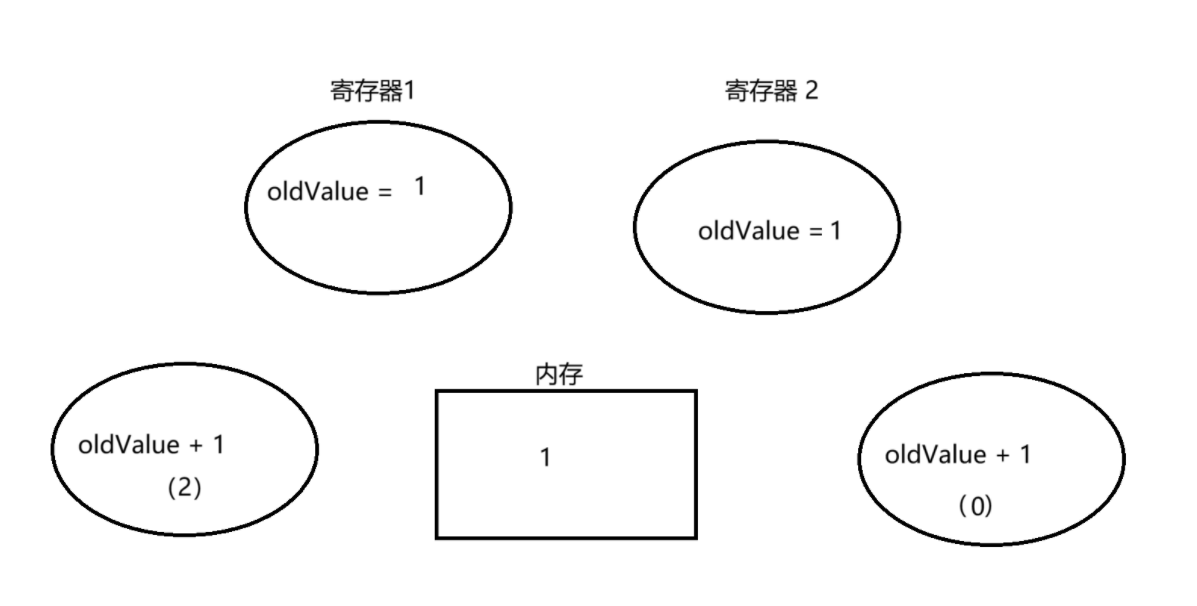
t1 线程,将 value 赋值给 oldValue
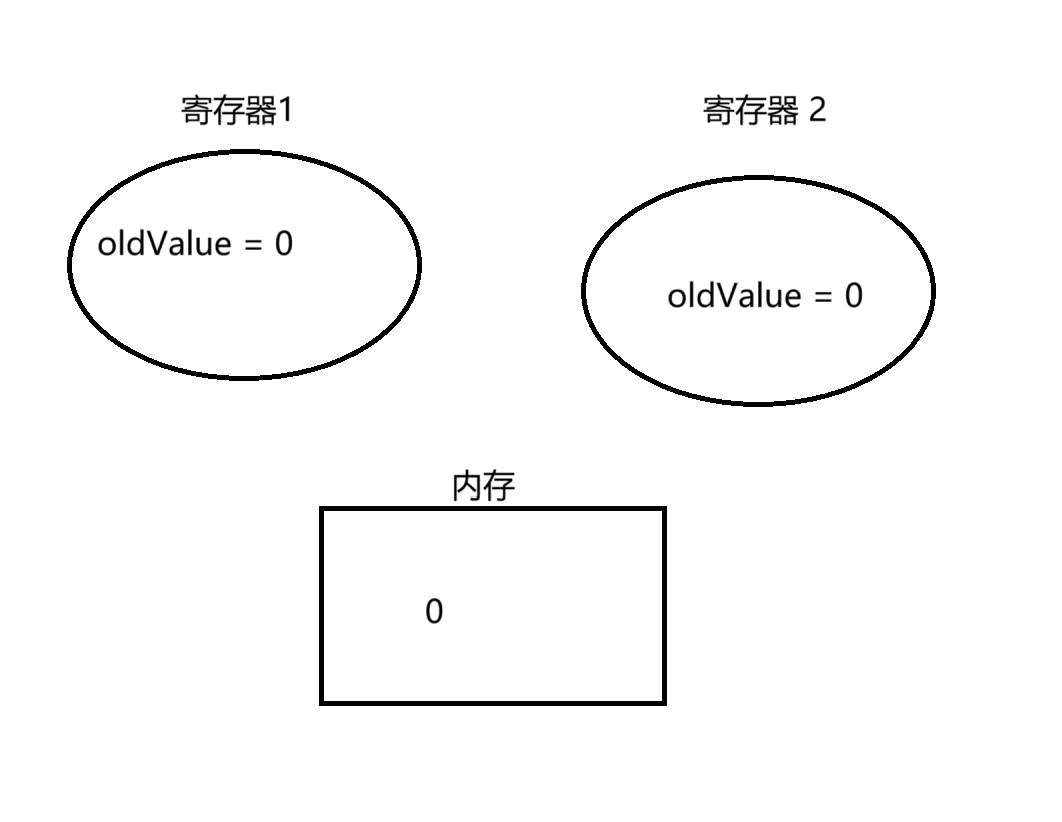
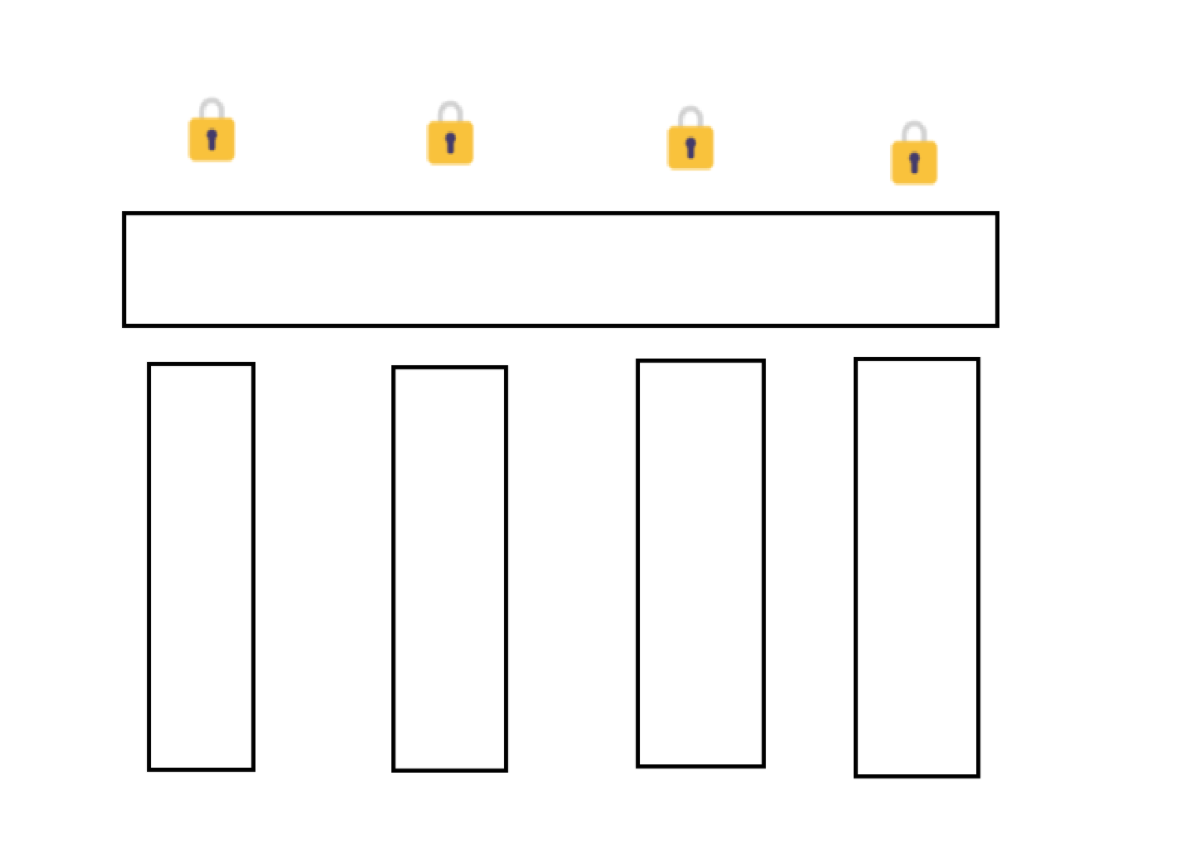
然后调度到 t2 线程实行,t2 线程也赋值 oldValue 为 0
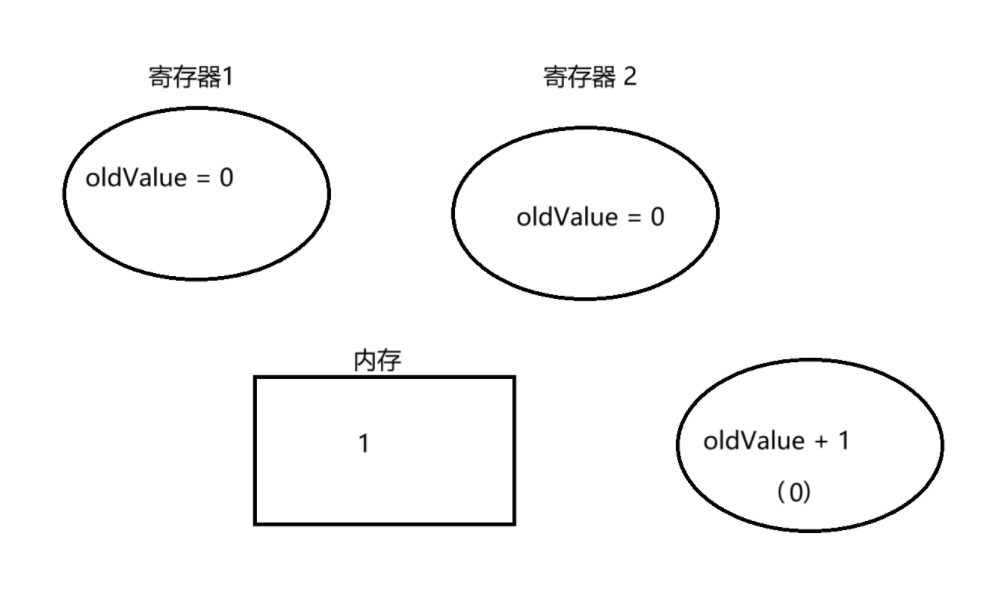
然后 t2 线程进入 while 循环,比力 value 和 oldValue 此时均为 0,此时还有一个寄存器三,为 oldValue + 1(即此时为 1)
会将 oldValue + 1 寄存器中的值 1 和 内存中的 0 进行交换
如许就通过线程 2,将 value 从 0 -> 1,将 value 重新赋给 oldValue 返回 oldValue。
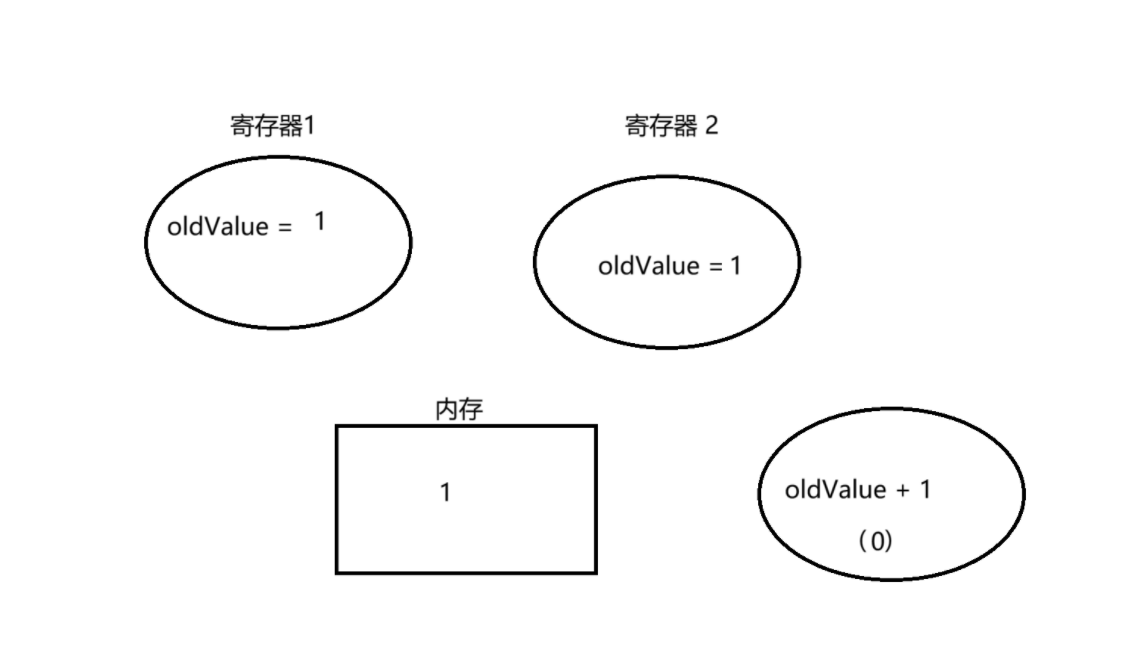
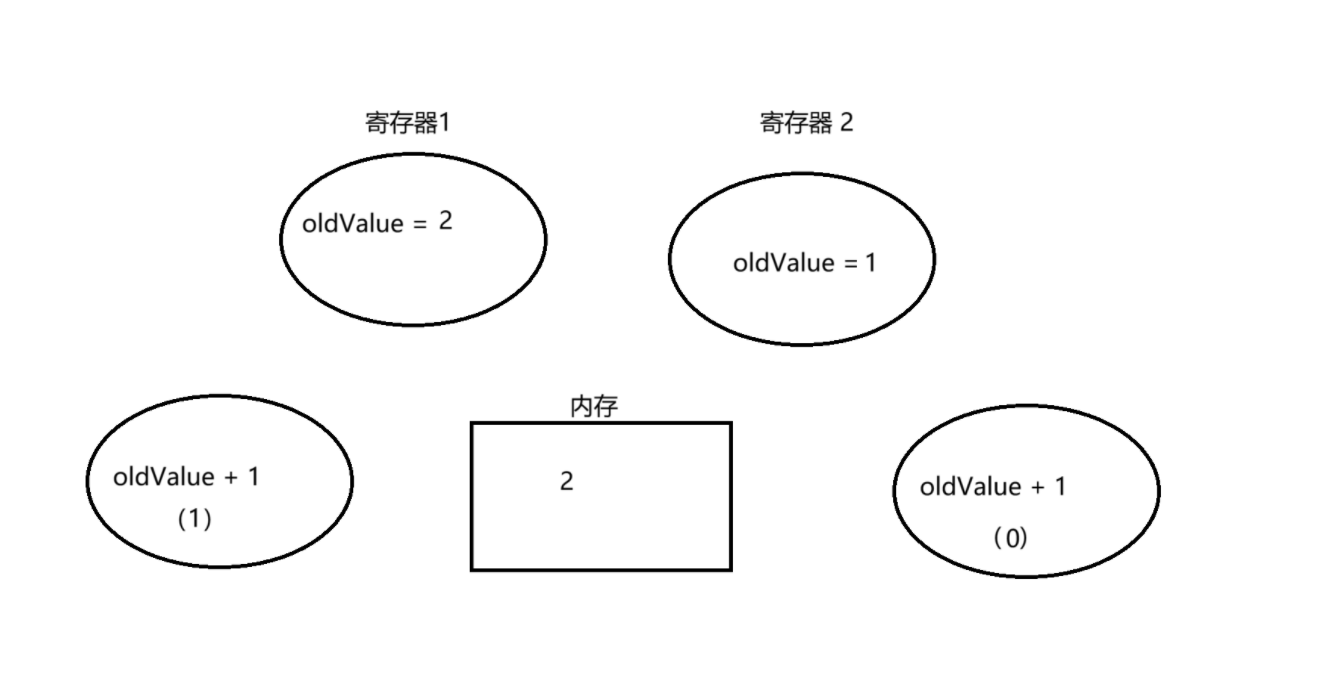
然后 t1 线程又被调度上来了,再实行 t1 线程
注意,这个时候,t1 线程中再实行,value 的值已经过 0 变为 1了,但此时寄存器 1 的 oldValue 记录的仍旧是 0,这里就会发现 value 和 oldValue 差别,意味着在 CAS 之前,另一个线程修改了 value(通过这个方式,能辨认出是否有人修改)所以就不会进行交换,进入while 循环,将 value 的值,重新赋给 oldValue
然后再进入 while 循环,这时候 value 和 oldValue 的值就相同了,然后还有另一个寄存器存储 oldValue + 1
再进行交换,将 value 从 1 -> 2,然后将 value 再赋值给 oldValue 返回 oldValue
之前的线程不安全,是内存变了,但是寄存器中的值没有跟着变,接下来的修改操作就会出错了,但使用 CAS 这种方式,通过一次内存和寄存器值的比力,就能确保辨认出内存的值是不是变了,不会,才会进行修改,假如变了,就会重新读取内存的值,确保是基于内存中的最新的值进行修改。非常巧妙的把之前的线程安全题目就办理了~~~
实现自旋锁
基于 CAS 实现更灵活的锁,获得到更多的控制权 自旋锁伪代码:
当 owner 不为 null 的时候,意味着锁已经被其他线程持有。此时,当前尝试获取锁的线程并不会进入阻塞状态(不会像传统锁机制下调用 wait 方法一样阻塞)而是在这个 while 循环中不停的实行(“忙等”)。持续的尝试 CAS 操作区获取锁,只要获取不成功就不停循环,不放弃 CPU 资源,但也不到场 CPU 调度中的线程上下文切换等调度流程,制止了调度开销~~~但是这种方式的缺点就是自旋的锁会不停占用 CPU,需要消耗更多的 CPU 资源。
CAS 的 ABA 题目