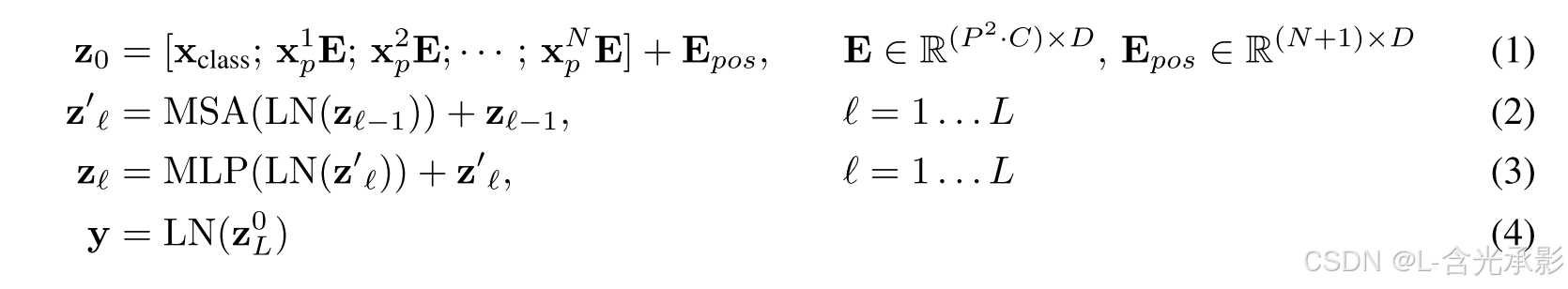This blog introduces Vision Transformer (ViT), a groundbreaking image classification model that replaces the local inductive bias of traditional convolutional neural networks (CNNs) by segmenting images into fixed-size patches (e.g., 16×16 pixels) and processing them as sequential inputs through a standard Transformer architecture. To address the challenge of adapting grid-structured images to sequence-based modeling, ViT employs patch embedding to linearly project flattened patches into vectors, learnable positional embeddings to encode spatial relationships, and a class token to aggregate global features. By stacking multiple Transformer encoder layers with self-attention mechanisms, ViT captures long-range dependencies across image regions, culminating in classification predictions via an MLP head. Experiments demonstrate that when pretrained on large-scale datasets like JFT-300M, ViT outperforms contemporary CNNs on tasks such as ImageNet while requiring fewer computational resources. Despite its advantages in global feature modeling and scalability, ViT heavily relies on extensive pretraining data and suffers from quadratic computational complexity relative to input resolution. Future research may focus on lightweight architectures, dynamic positional encoding, and hybrid local-global attention mechanisms to enhance its practicality in real-world applications. 文章信息
Title:AN IMAGE IS WORTH 16X16 WORDS:TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE Author:Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby. Source:https://arxiv.org/abs/2010.11929 弁言
其中, x p i x_p^i xpi表示第i个patch, E E E和 E p o s E_{pos} Epos分别表示Token Embedding和Positional Embedding, Z 0 Z_0 Z0是Transformer Encoder的输入,公式(2)是计算multi-head attention的过程,公式(3)是计算MLP的过程,公式(4)是最终分类任务,LN表示是一个简单的线性分类模型, Z L 0 Z_L^0 ZL0是得到的 cls token 对应的输出效果。
CNN的归纳偏置