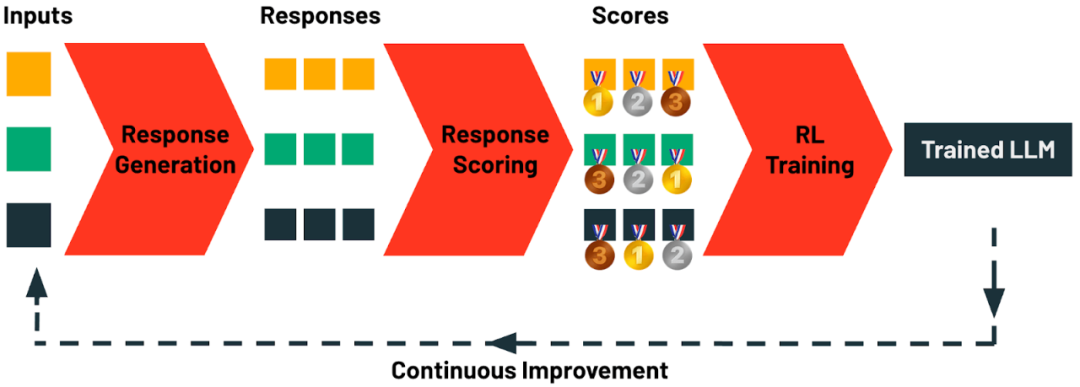
持续改进:TAO 仅需 LLM 输入样本作为数据源。用户与 LLM 的日常交互自然形成该数据 —— 一旦模型摆设使用,即可自动天生下一轮 TAO 练习数据。在 Databricks 平台上,借助 TAO 机制,模型会随着使用频次增长而持续进化。
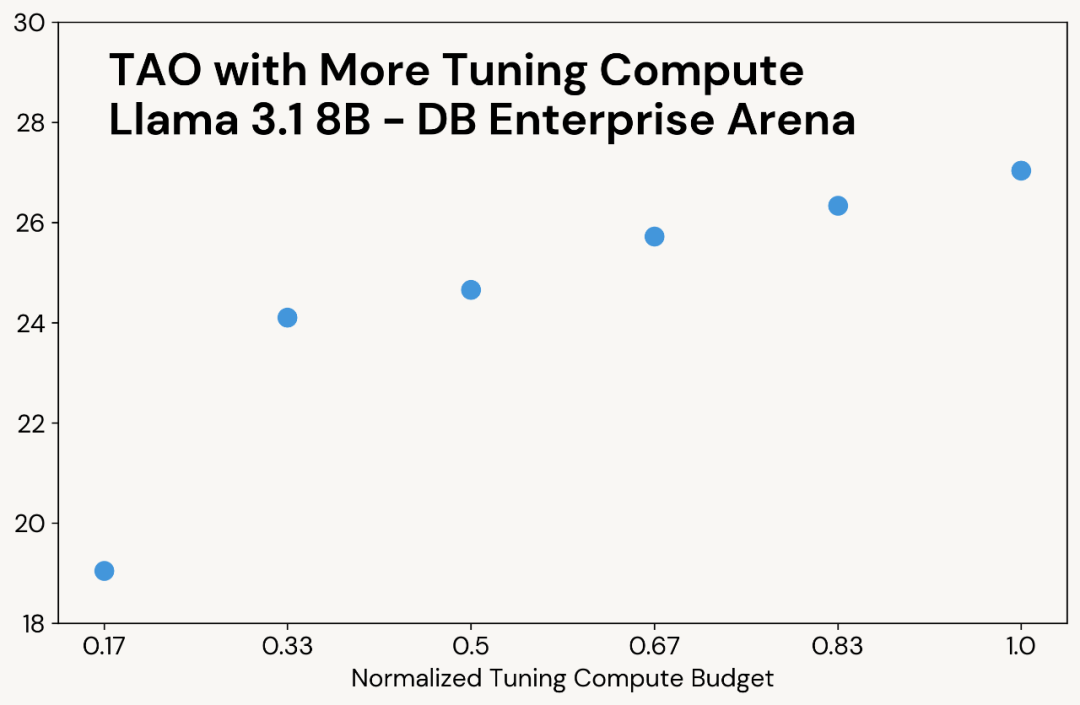
虽然 TAO 在练习阶段使用了测试时盘算,但终极产出的模型在执行任务时仍保持低推理本钱。这意味着颠末 TAO 调优的模型在推理阶段 —— 与原版模型相比 —— 具有完全雷同的盘算开销和响应速度,显著优于 o1、o3 和 R1 等依赖测试时盘算的模型。实行表明:采用 TAO 练习的高效开源模型,在质量上足以比肩顶尖的商业闭源模型。
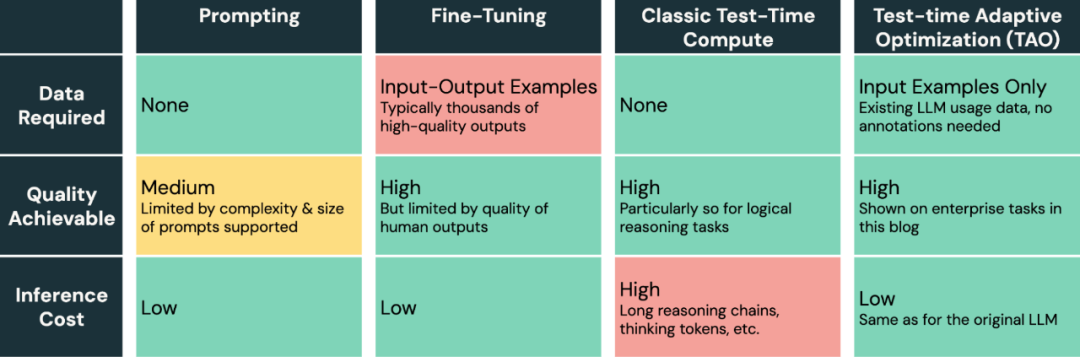
TAO 为 AI 模型调优提供了一种突破性方法:
差别于耗时且易堕落的提示工程;
也区别于需要昂贵人工标注数据的传统微调;
TAO 仅需工程师提供任务相关的典型输入样本,即可实现杰出性能。
LLM 差别调优方法比较。
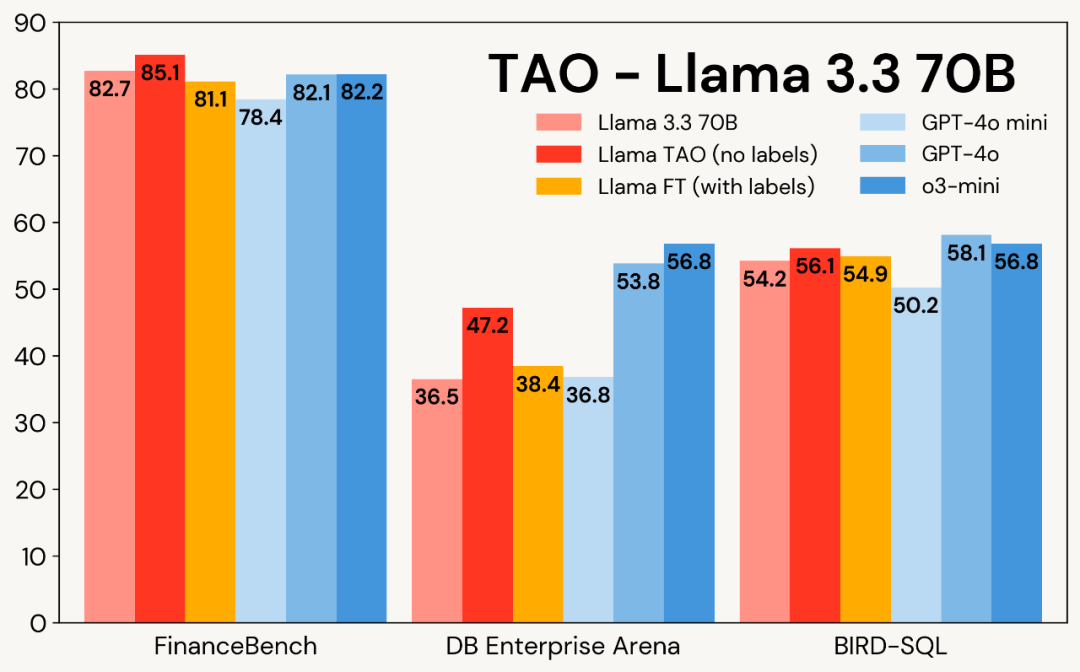
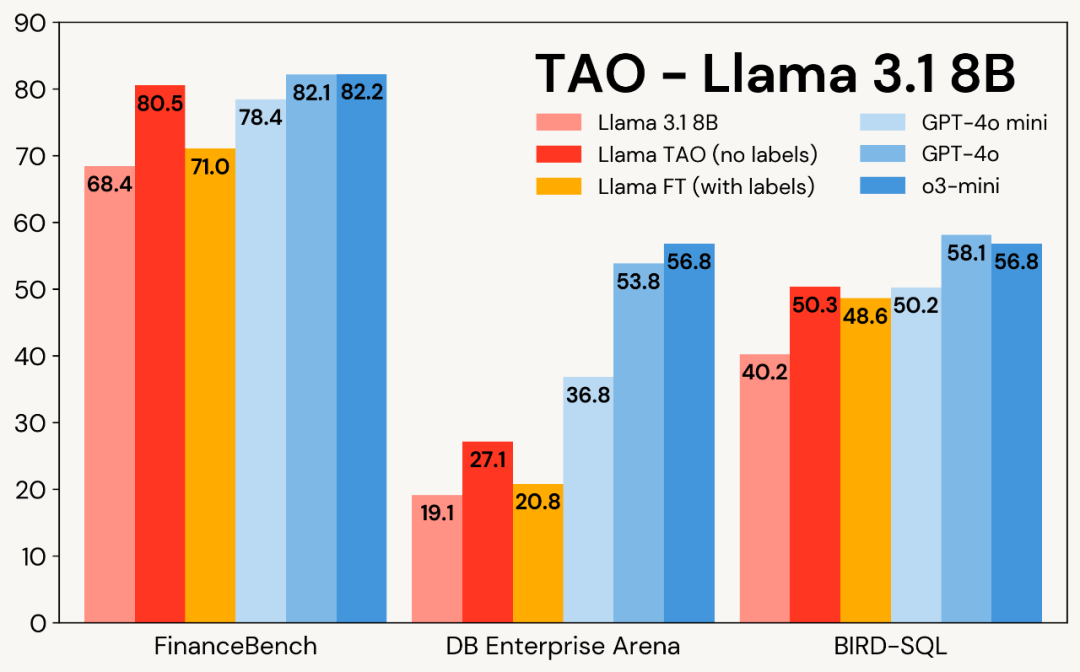
实行及结果
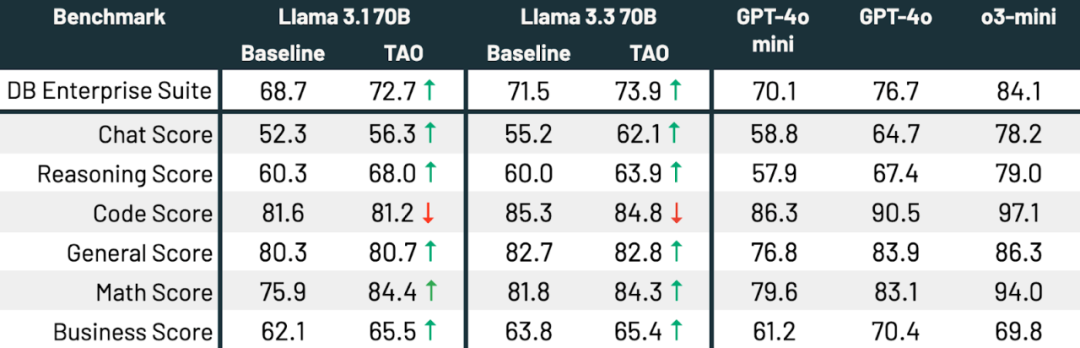
接下来,文章深入探讨了怎样使用 TAO 针对专门的企业任务调优 LLM。本文选择了三个具有代表性的基准。