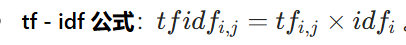IT评测·应用市场-qidao123.com技术社区
标题:
机器学习 Day11 决议树
[打印本页]
作者:
立山
时间:
2025-4-18 06:58
标题:
机器学习 Day11 决议树
1.决议树简介
原理
:头脑源于步伐计划的 if - else 条件分支布局 ,是一种树形布局。内部节点表现属性判断,分支是判断效果输出,叶节点是分类效果 。
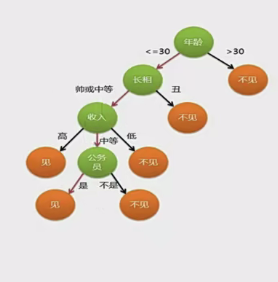
案例
:以母亲给女儿先容男朋侪为例。女儿依次询问年龄(≤30 )、长相(帅或中等 )、收入(中等 )、是否为公务员(是 ),通过一系列判断决定去见男方。
由什么来决定年龄放在最上面呢?
熵
概念
:物理学中是 “混乱” 程度度量。体系越有序越会合,熵值越低;越混乱分散,熵值越高 。1948 年香农提出信息熵概念。从信息完整性看,数据越会合熵值越小;从信息有序性看,体系越有序熵值越低 ,纯度越高。
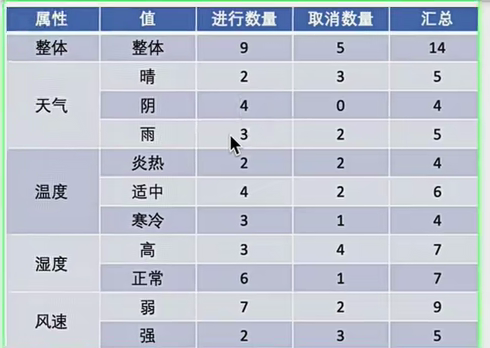
信息熵案例
2.分类原理
2.1信息增益(ID3算法)
2.1.1理论
其实Ent(D)就是我们上边讲的熵的计算公式,类别就是标签值,Ent(D,a)的分数部门就是在总样本中被该属性分类的样本占比,后面那个Ent(D^v)就是在对应的分类中,每个标签值的概率求信息熵。
2.2.2案例:
你看那个ent(D^1/2)里边就是分母就是这个类别的总数,分子就是标签值对应的数。。,可以看到决议树对分类数据很友好。对于数值类数据如何做,之后有例子。
2.2信息增益率(C4.5算法)
2.2.1概念
概念
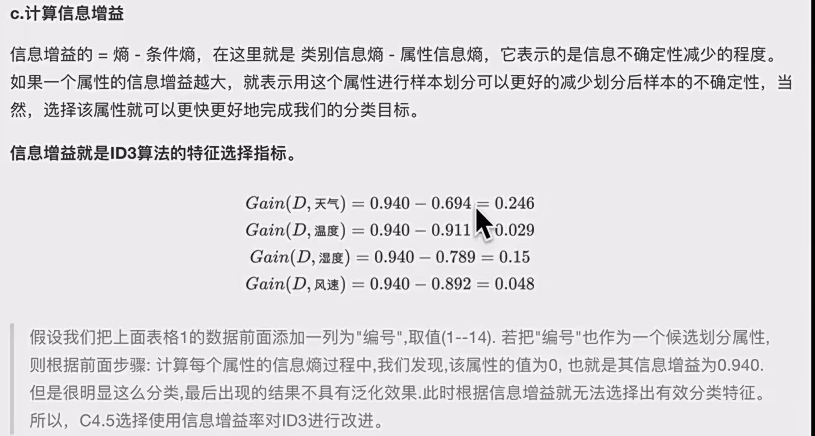
信息增益的局限性
:信息增益准则对可取值数目较多的属性有偏好。如将 “编号” 作为候选分别属性时,按信息增益公式计算其信息增益很大,但这样分别出的效果不具泛化效果,无法有效猜测新样本。因此需要引入增益率。
信息增益率定义
:为淘汰上述偏好带来的不利影响,C4.5 决议树算法使用信息增益率选择最优分别属性 。
分母就是上一节的信息增益,分子就是总体被属性分成多少份中的每一份占比,套用熵的公式,只不外是属性分类树,而不是熵中标签值数了。。。
2.2.2案例
a.计算总信息熵
以上计算就是2.1中的计算
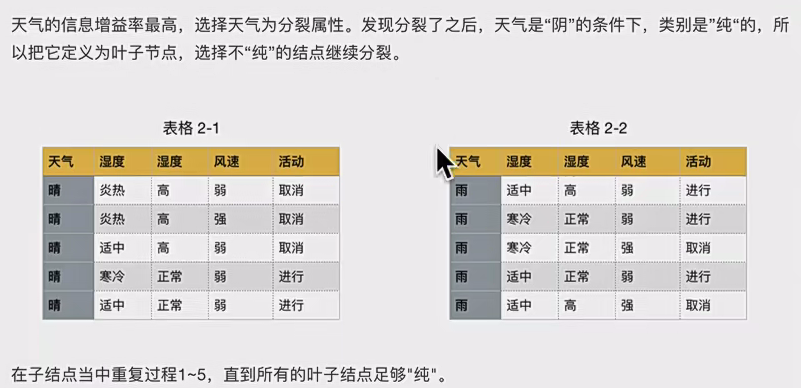
d.分裂继续执行
但是事实上经常做不到分完是纯的 ,而且id3和c4.5得到的数不肯定是二叉树。
2.2.3 C4.5的优点
2.3基尼指数(CART算法)
2.3.1原理
基尼指数和那个信息增益很相识,只不外把ent(D^v)该为了gini(D^v)
注意,这个算法分别后肯定是二叉树,它只有不是(或者大于)这个属性的某个值或者是(或者小于)这个属性的某个值,可以看这个案例:
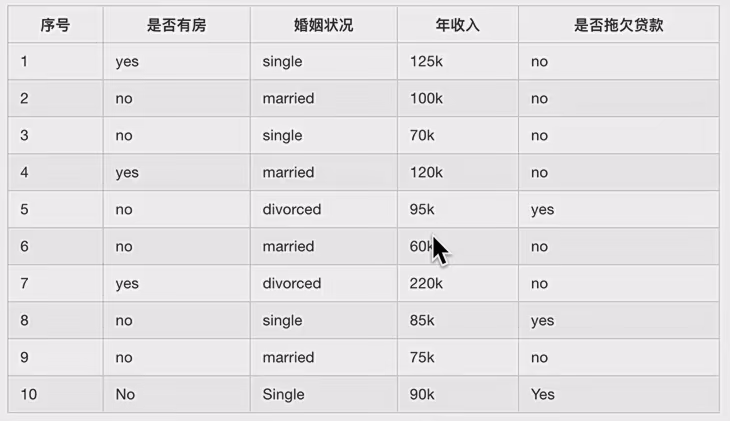
2.3.2案例
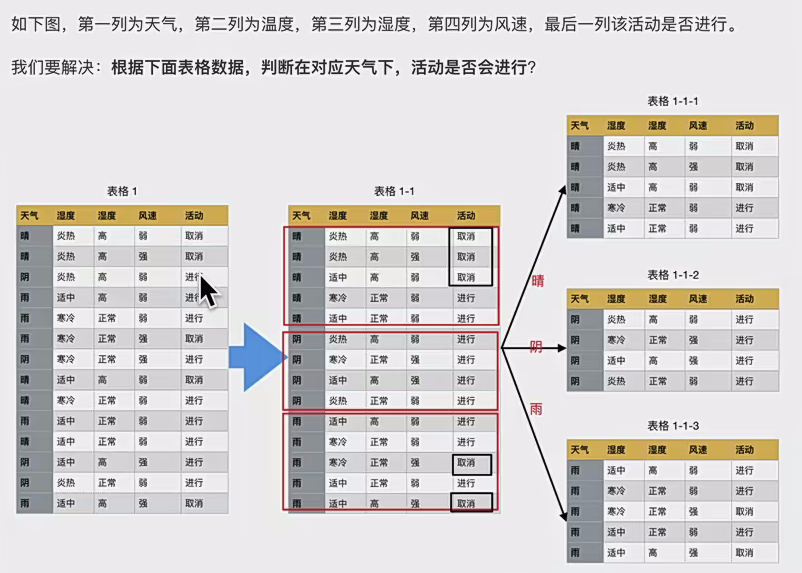
这是数据
你看这里就是表现了是一个二叉树,因为当一个属性有大于两个值时,你要一个一个算,每次把一个当做左子树,其他作为右子树,这样每个都算完后,选一个最小的分类值作为要分类节点,左子树是属于这个,右子树是其他的。(可以发现分类数据可以做这个处置惩罚,假如是数值类型数据该如何处置惩罚??)
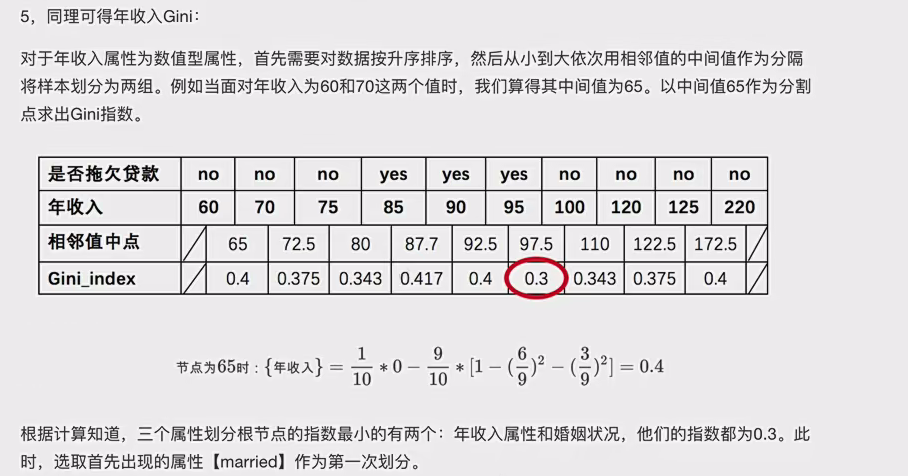
:说一下怎么来的,其实和信息增益一样,非常之1和9就是假如按照65来分别会将10个样本分别为小于65的一份和大于65的9份。。然后它们乘的就是每份里的基尼指数,比如第一份里边标签值都是no说以就是(1-(1/1)^2-(0/1)^2)=0 第二个同样,9份里边6个no,3个yes于是就是图里那样,瞥见没其实计算方法和信息增益是一样的。只不外前者是乘上ent(D^v)
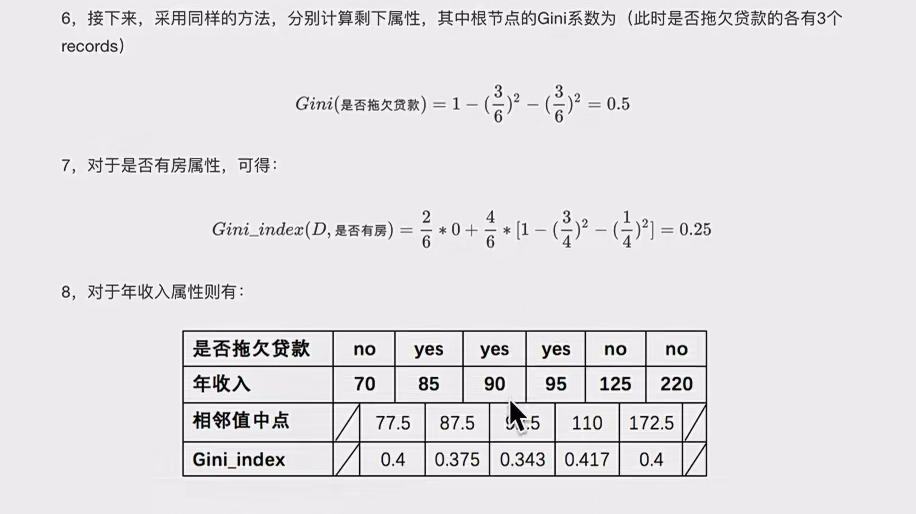
这个数值类型你要一个一个算,然后看那个最小来选择最小的,假设上面选择了以65为中间值的。
选好第一次节点以及属性值后,分割数据,循环到竣事
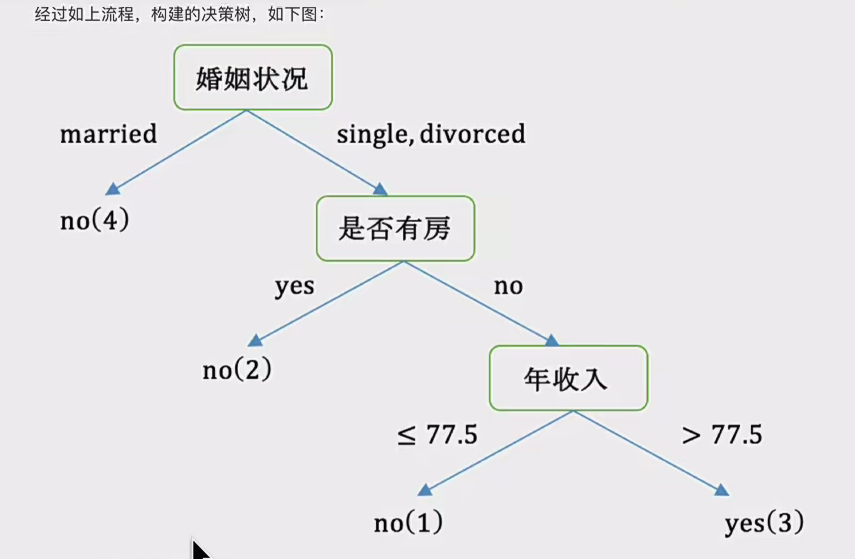
最后有如下决议树:
总而言之,算法流程就是:
2.4总结
记住,id3只能用于分类变量,c4.5可以用连续性变量,它们用于分类。cart均可以而且也可以用往返归。多变量决议树采用特征的线性组合。
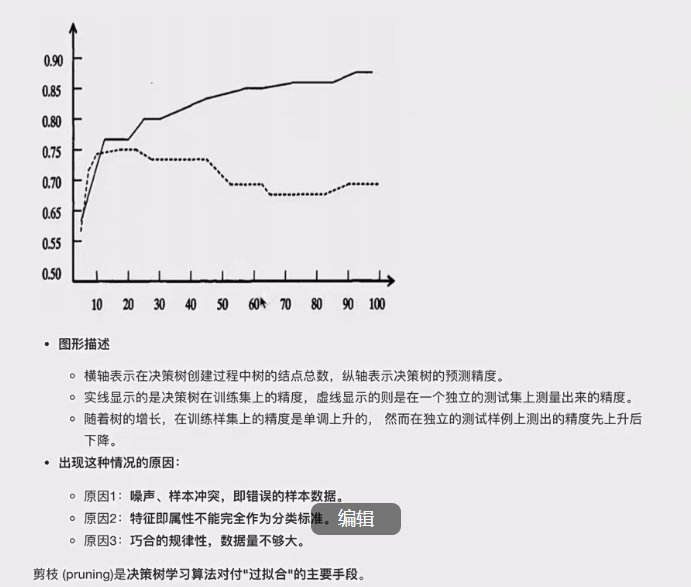
3.剪枝(防止过拟合)
3.1引入
这个就叫做剪枝.
3.2剪枝类型
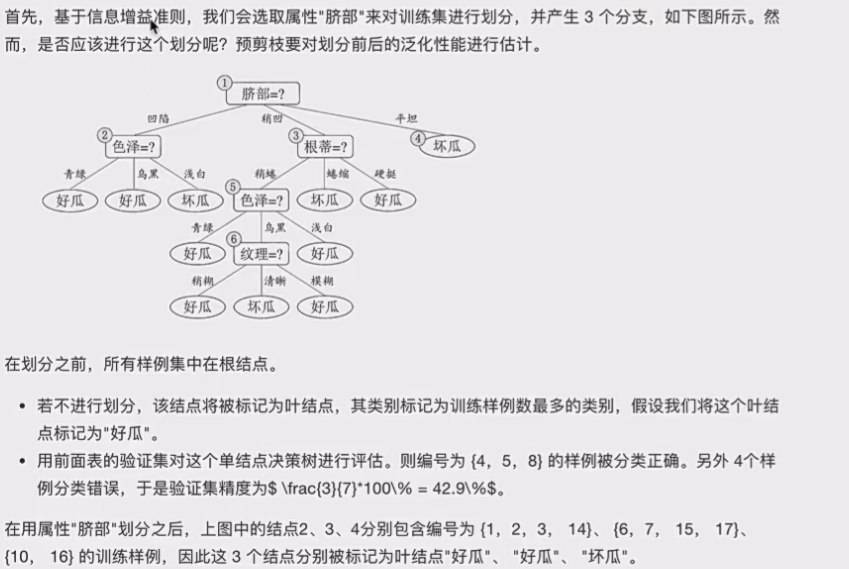
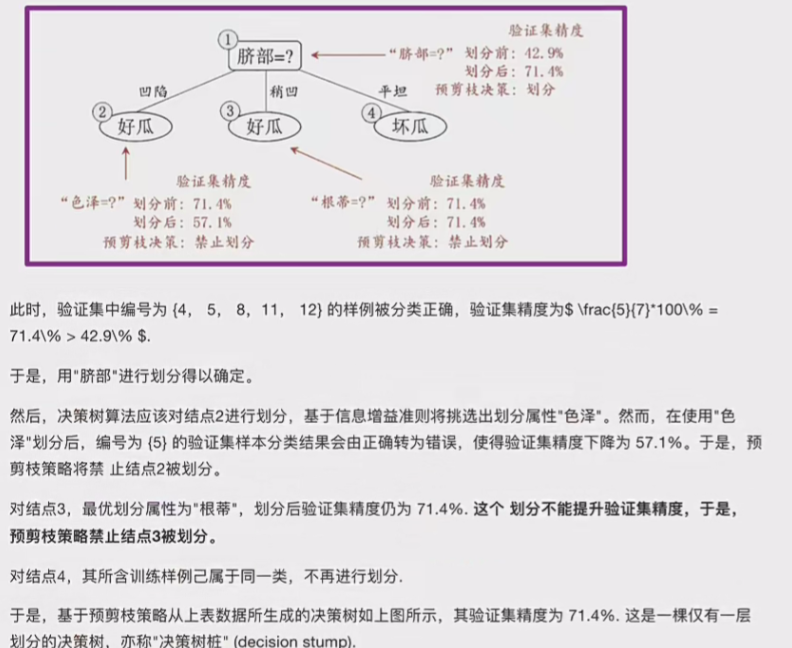
3.2.1预剪枝
注意,要用验证集去进行准确率丈量,因为要制止过拟合,提高泛化型
这就是预剪枝的过程。
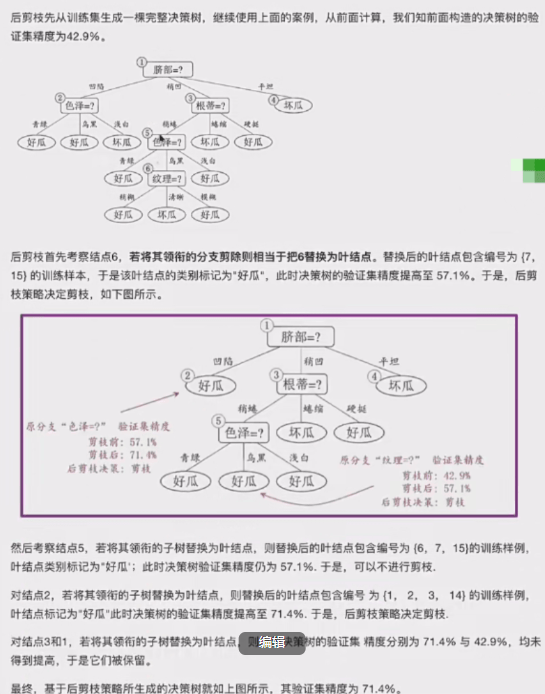
3.2.2后剪枝
3.2.3两种方法对比
1. 焦点差别对比
对比维度
预剪枝
后剪枝
剪枝时机
树生成过程中树完全生成后
剪枝方向
自上而下自底向上
分支保存情况
较少分支较多分支
时间复杂度
O(n) - 较低O(n²) - 较高
空间复杂度
较低需要存储完整树,较高
实现难度
较简单较复杂
2. 性能
后剪枝优势显着
:
保存了更多可能有效的分支路径
通过"过后验证"能更准确判断哪些分支应该保存
典范情况下泛化精度比预剪枝高10-15%
预剪枝局限性
:
早期制止可能导致丢失有潜力的分支
"目光如豆"问题:无法预见后续可能出现的有效分别
3. 时间开销详解
3.1 预剪枝时间构成
结点分别评估:每次分别前计算验证集精度
比力决议:单次比力即可决定是否分别
总时间 ≈ 树深度 × 结点评估时间
3.2 后剪枝时间构成
完整树构建时间
后处置惩罚时间:
需要考察每个非叶结点
每个结点的剪枝评估需要重新计算验证集精度
最坏情况下需评估O(n²)次(n为结点数)
3.3 实测数据参考
在UCI标准数据集上的实行效果:
预剪枝耗时:完整树构建时间的30-50%
后剪枝耗时:完整树构建时间的200-300%
4. 现实应用建议
4.1 推荐使用后剪枝的场景
数据量中等(万级以下样本)
对模子精度要求极高
计算资源富足
特征维度较高时
4.2 推荐使用预剪枝的场景
超大规模数据集(百万级以上)
实时性要求高
资源受限环境
特征维度较低时
4.3 混合计谋建议
对于关键业务场景可思量:
先使用预剪枝快速生成初步模子
在紧张分支区域使用后剪枝精细调整
通过交织验证确定最佳剪枝强度
4.特征工程----------特征提取
4.1. 特征提取概述
特征提取是将原始数据(如文本、图像、字典等)转换为机器学习算法可以理解的数值特征的过程。这是机器学习预处置惩罚的关键步骤。
主要分类
:
字典特征提取(特征离散化)
文本特征提取
图像特征提取(之后讲)
4.2. 字典特征提代替码
4.2.1 DictVectorizer使用
Scikit-learn提供了DictVectorizer类来实现字典特征提取:先实例化,再使用fit_transform(数据)转化。
注意X的规定几乎是字典,现实中要提取,需要写为字典,或者可以用以前学过的one-hot编码。,即pd.get_dummies()函数
from sklearn.feature_extraction import DictVectorizer
data = [{'city': '北京', 'temperature': 100},
{'city': '上海', 'temperature': 60},
{'city': '深圳', 'temperature': 30}]
# 实例化转换器,sparse=False表示返回密集矩阵
transfer = DictVectorizer(sparse=False)
# 转换数据
data_new = transfer.fit_transform(data)
print("转换结果:\n", data_new)
print("特征名称:\n", transfer.get_feature_names())
复制代码
4.2.2 输出效果分析
这是一个sparse矩阵,,它只储存了不为0的位置,前面的坐标就是那个位置,在一个二维矩阵里那些位置不为0的坐标,加上True效果是这个:(其实sparse矩阵就是下面这个矩阵的非零位置)
转换效果
:
[[ 0. 1. 0. 100.]
[ 1. 0. 0. 60.]
[ 0. 0. 1. 30.]]
复制代码
其实这个就是我们之前讲过的One-Hot编码,让我们再复习一遍
4.2.3. One-Hot编码原理
4.2.3.1 什么是One-Hot编码
One-Hot编码是将分类变量转换为机器学习算法更易理解的形式的过程。它为每个类别创建一个新的二进制特征(0或1)。
4.2.3.2 编码示例
原始数据:
Sample Category
1 Human
2 Human
3 Penguin
4 Octopus
5 Alien
6 Octopus
7 Alien
复制代码
One-Hot编码后:
SampleHumanPenguinOctopusAlien11000210003010040010500016001070001
4.2.3.3 One-Hot编码特点
制止数值偏见
:防止算法误以为类别之间有数值关系(如以为Alien>
enguin)
维度增加
:类别变量有N个不同值,将生成N个新特征
希罕性
:每个样本在新特征中只有一个1,别的都是0
4.2.4. 应用场景与注意事项
4.2.4.1 适用场景
分类特征没有内在顺序关系时
类别数目不太大时(制止维度灾难)
基于树的模子通常不需要One-Hot编码(参考决议树)
4.2.4.2 注意事项
维度控制
:当类别过多时,思量:
合并低频类别
使用其他编码方式(如目标编码)
数值特征
:像temperature这样的连续数值特征不需要One-Hot编码
内存思量
:大数据集使用希罕矩阵表现更节省内存
4.3文本特征提取(其实就是对词的一个统计)
使用CountVectorizer这个实例化可以进行特征提取
注意X是文本或者包含文本的可迭代对象,stop_words=[]列表里放的是我们不需要统计的词
4.3.1只含有英文的文本
比如有以下数据(注意是纯英文的)
from sklearn.feature_extraction.text import CountVectorizer
def text_count_demo():
"""
对文本进行特征抽取,countvectorizer
:return: None
"""
data = ["life is short,i like like python", "life is too long,i dislike python"]
# 1、实例化一个转换器类
transfer = CountVectorizer()
# 2、调用fit_transform
data = transfer.fit_transform(data)
print("文本特征抽取的结果: \n", data.toarray())
print("返回特征名字: \n", transfer.get_feature_names())
return None
if __name__ == "__main__":
text_count_demo()
复制代码
注意data本来返回的还是sparse矩阵,由于这里不能使用sparse=Flase转化为可以辨认的格式,,,我们需要用toarray()给它转化为可以理解的数组 。
上面那个矩阵就是下面的词在每句话里的出现的次数 ,注意不统计标点和单个字符
4.3.2含有中文的文本
之所以能对含有英文的文本进行处置惩罚是因为英文单词之间有自然的空格,而中文没有,那怎么办呢?其实分词后就和上别一样了
4.3.2.1分词
使用jieba分词处置惩罚:注意返回的是一个生成器,要进行转化。
案例:
from sklearn.feature_extraction.text import CountVectorizer
import jieba
def cut_word(text):
"""
对中文进行分词
"我爱北京天安门"——>"我 爱 北京 天安门"
:param text: 输入的中文文本
:return: 分词后的文本(以空格连接词语的字符串形式)
"""
# 用结巴对中文字符串进行分词
text = " ".join(list(jieba.cut(text)))
#"a".join(可迭代对象)就是把可迭代对象的每个元素用a连接起来
#返回字符串
return text
def text_chinese_count_demo2():
"""
对中文进行特征抽取
:return: None
"""
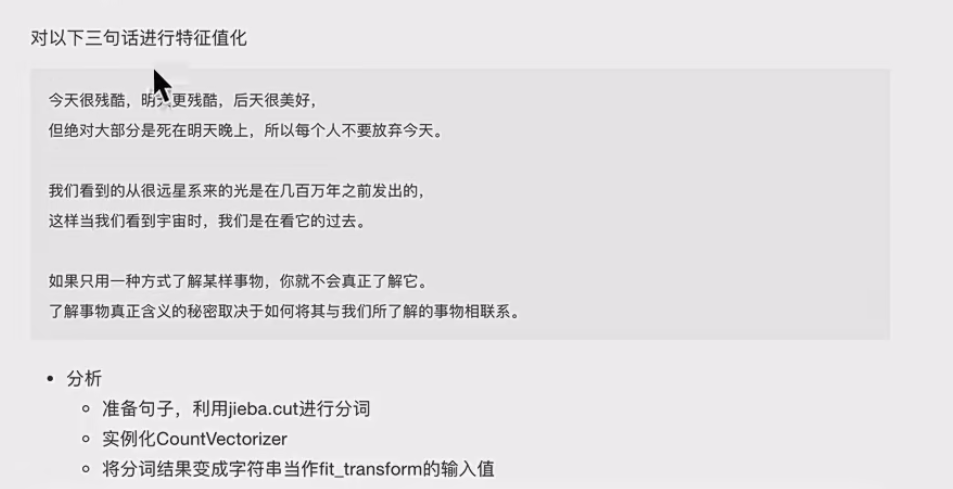
data = [
"一种还是一种今天很残酷,明天更残酷,后天很美好,但绝对大部分是死在明天晚上,所以每个人不要放弃",
"我们看到的从很远星系来的光是在几百万年之前发出的,这样当我们看到宇宙时,我们是在看它的过去。",
"如果只用一种方式了解某样事物,你就不会真正了解它。了解事物真正含义的秘密取决于如何将其与我们所"
]
# 将原始数据转换成分好词的形式
text_list = []
for sent in data:
text_list.append(cut_word(sent))
print(text_list)
# 1、实例化一个转换器类
transfer = CountVectorizer()
# 2、调用fit_transform
data = transfer.fit_transform(text_list)
print("文本特征抽取的结果: \n", data.toarray())
print("返回特征名字: \n", transfer.get_feature_names())
return None
if __name__ == "__main__":
text_chinese_count_demo2()
复制代码
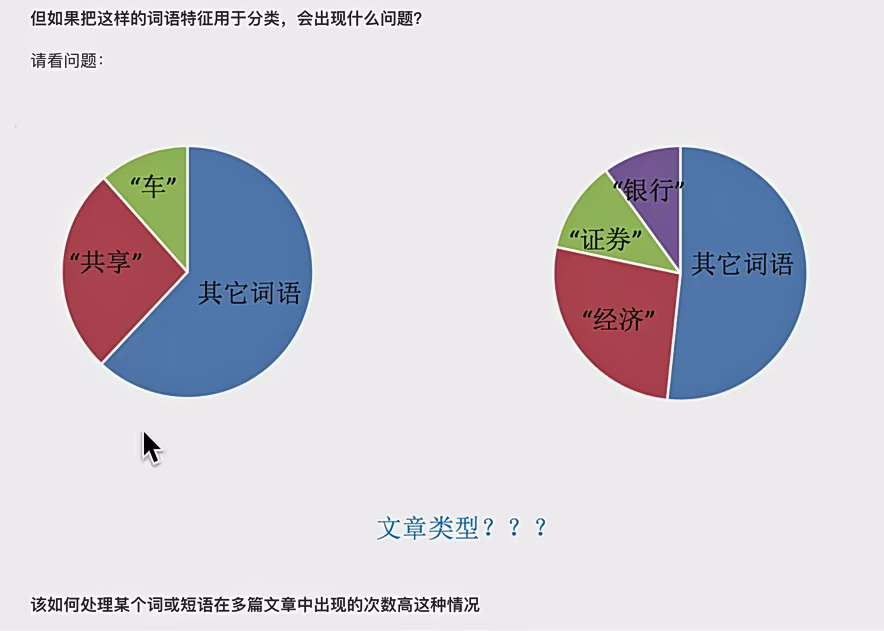
4.4高频词处置惩罚:
TF - idf 文本特征提取
主要头脑
:假如某个词语在一篇文章中出现的概率高,并且在其他文章中很少出现,就以为此词语具有很好的类别区分能力,适适用来对文本进行分类。比方在体育类文章中频仍出现的 “足球”“比赛” 等词,在科技类文章中很少出现,这些词对于区分体育类文本就很有价值。
作用
:用于评估一个字词对于一个文件集或一个语料库中的某一份文件的紧张程度。比如在学术论文会合,专业术语在相干主题论文中紧张程度高,通过 TF - idf 可以衡量出其紧张性。
3.5.1 公式
词频(term frequency, tf)
:指的是某一个给定的词语在该文件中出现的频率。计算方法是词语在文件中出现的次数除以文件的总词语数 。比方,若一篇文章总词语数是 100 个,词语 “非常” 出现了 5 次,那么 “非常” 一词在该文件中的词频就是 5÷100 = 0.05 。
逆向文档频率(inverse document frequency, idf)
:是一个词语广泛紧张性的度量。计算方式为总文件数目除以包含该词语之文件的数目,再将得到的商取以 10 为底的对数 。比如 “非常” 一词在 1,000 份文件出现过,而文件总数是 10,000,000 份,其逆向文件频率就是 lg (10,000,000÷1,000) = 3 。
tf - idf 公式
:
。此中tfij是词语i在文档j中的词频,idfi是词语i的逆向文档频率。终极得出的tfidf效果可以理解为词语i在文档j中的紧张程度 。如上述例子中,“非常” 对于这篇文档的 tf - idf 的分数为 0.05×3 = 0.15 。
通过 TF - idf 方法,可以量化文本中词语的紧张性,在文本分类、信息检索等自然语言处置惩罚任务中广泛应用,帮助筛选出对文本内容有紧张表征作用的词语。
5.决议树算法的API,还是先实例化在调用
6.案例
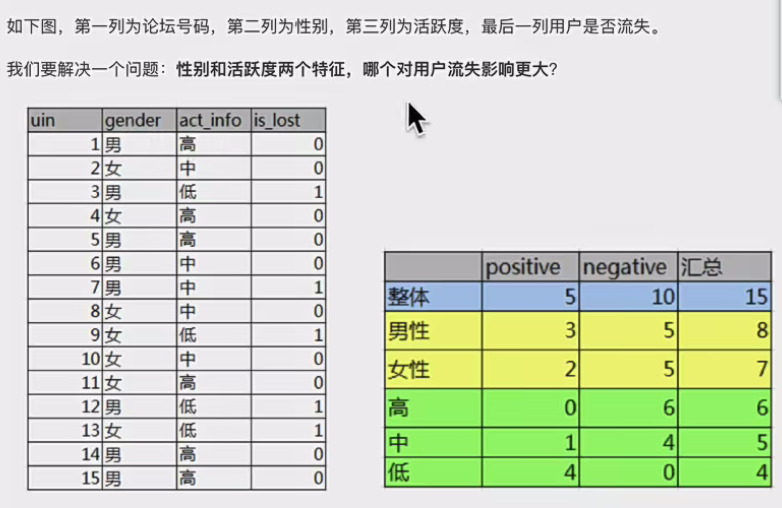
6.1案例配景
6.2步骤分析
6.3代码
import pandas as pd
import numpy as np
from sklearn.feature_extraction import DictVectorizer
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier, export_graphviz
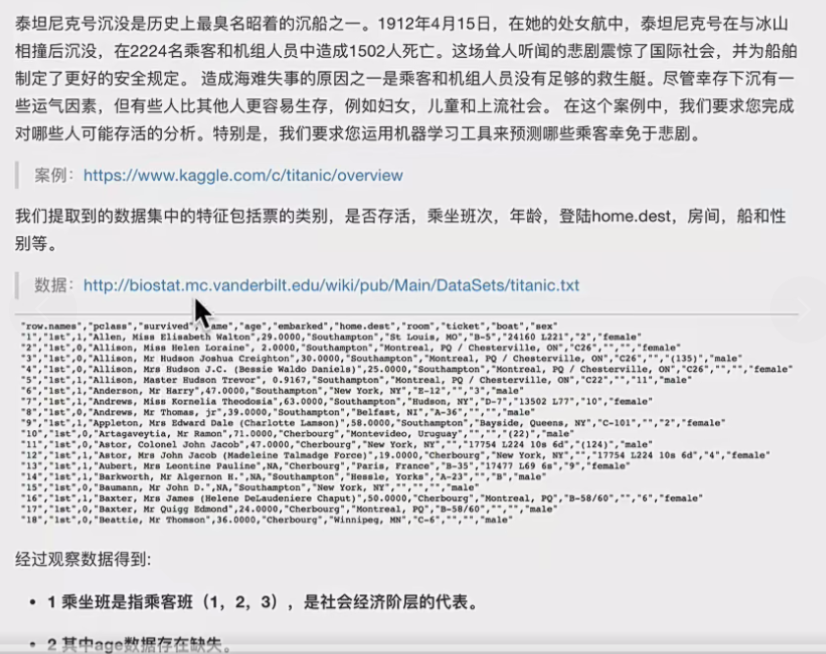
# 1. 获取数据
titan = pd.read_csv("http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic.txt")
# 2. 数据基本处理
# 2.1 确定特征值、目标值
x = titan[["pclass", "age", "sex"]]
y = titan["survived"]
# 2.2 缺失值处理
x['age'].fillna(x['age'].mean(), inplace=True)
# 2.3 数据集划分
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=22)
# 3. 特征工程(字典特征抽取)
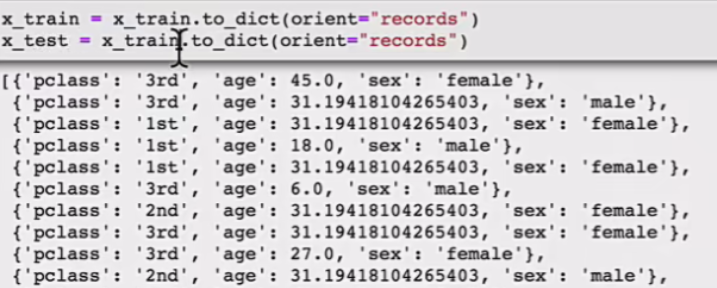
# 对于x转换成字典数据x.to_dict(orient="records")
# [{"pclass": "1st", "age": 29.00, "sex": "female"}, {}]
transfer = DictVectorizer(sparse=False)
x_train = transfer.fit_transform(x_train.to_dict(orient="records"))
x_test = transfer.fit_transform(x_test.to_dict(orient="records"))
# 4. 决策树模型训练和模型评估
# 4. 机器学习(决策树)
estimator = DecisionTreeClassifier(criterion="entropy", max_depth=5)
estimator.fit(x_train, y_train)
# 5. 模型评估
score = estimator.score(x_test, y_test)
print("模型得分:", score)
y_predict = estimator.predict(x_test)
print("预测结果:", y_predict)
复制代码
注意里边的字典转化:
参数意义:
7.决议树可视化
8.回归决议树
8.1算法描述
意思就是我们的回归决议树也是循环所有的特征所有的取值,看哪一个让损失函数最小 ,而分类决议树是让信息差最大。其次回归决议树采取的是这一分类的平均值进行输出。
可以看到那个优化的公式,我们还是和基尼指数一样,给他分别为一个二叉树。
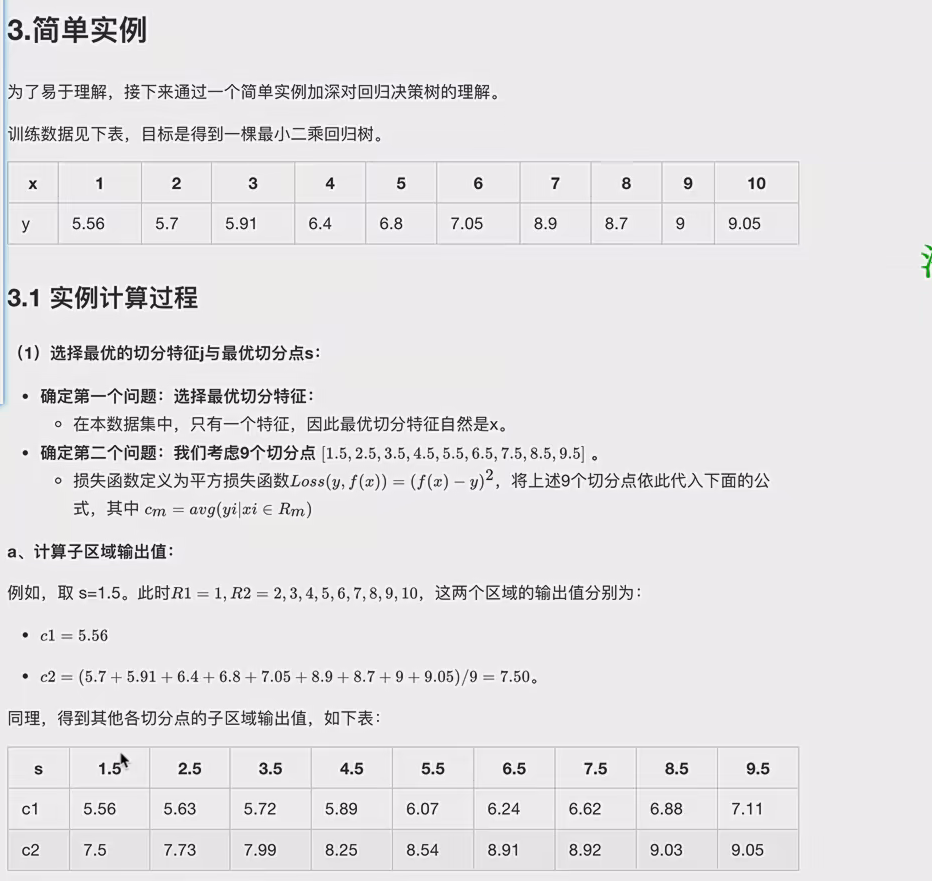
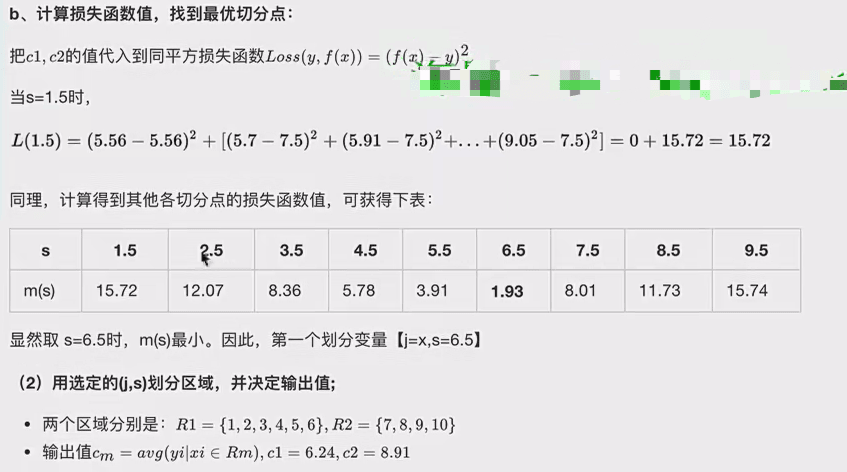
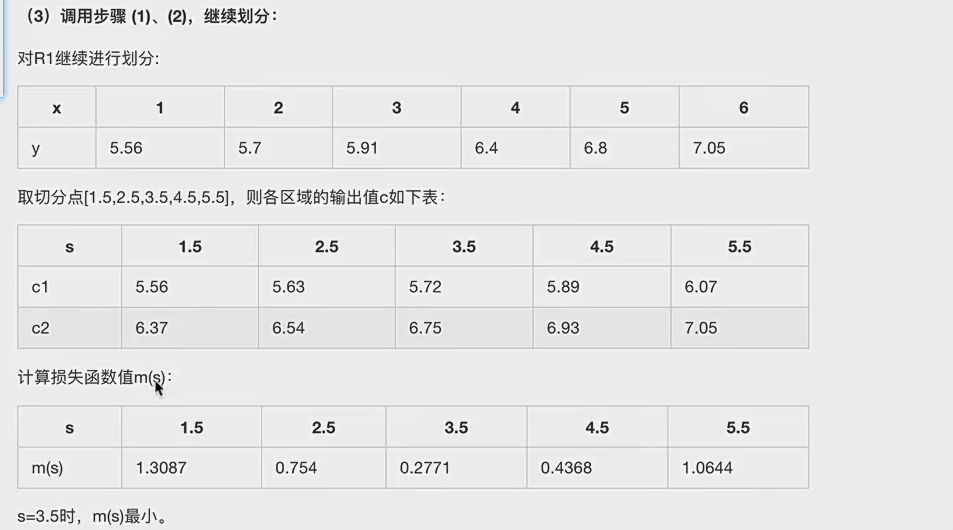
8.2案例
8.3代码对比
import numpy as np
import matplotlib.pyplot as plt
from sklearn.tree import DecisionTreeRegressor
from sklearn import linear_model
# 生成数据
x = np.array(list(range(1, 11))).reshape(-1, 1)
y = np.array([5.56, 5.70, 5.91, 6.40, 6.80, 7.05, 8.90, 8.70, 9.00, 9.05])
# 训练模型
model1 = DecisionTreeRegressor(max_depth=1)#决策树回归
model2 = DecisionTreeRegressor(max_depth=3)#决策树回归
model3 = linear_model.LinearRegression()#简单的线性回归
model1.fit(x, y)
model2.fit(x, y)
model3.fit(x, y)
# 模型预测
X_test = np.arange(0.0, 10.0, 0.01).reshape(-1, 1) # 生成1000个数,用于训练模型
y_1 = model1.predict(X_test)
y_2 = model2.predict(X_test)
y_3 = model3.predict(X_test)
# 结果可视化
plt.figure(figsize=(10, 6), dpi=100)
plt.scatter(x, y, label="data")
plt.plot(X_test, y_1, label="max_depth=1")
plt.plot(X_test, y_2, label="max_depth=3")
plt.plot(X_test, y_3, label='liner regression')
plt.xlabel("data")
plt.ylabel("target")
plt.title("Decision Tree Regression")
plt.legend()
plt.show()
复制代码
注意我们生成数据因为要猜测,我们必须转化为二维的,仅仅是np.array(list(range(1,11)))是一个一维数组,所以通过形状转变变为二维。
x = np.array(list(range(1, 11))).reshape(-1, 1)
复制代码
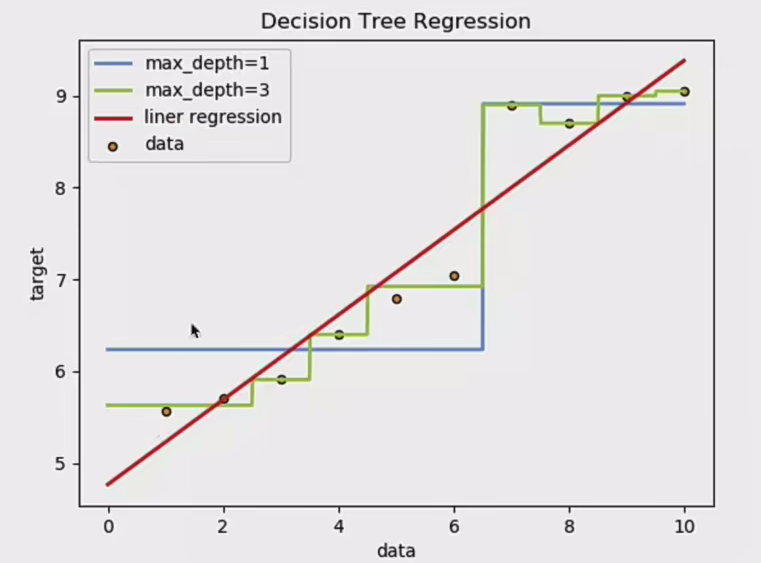
图如下:
很正常,我们看决议树回归的算法就是选取某一段的平均值,你看所以这幅图绿和蓝线都是阶梯形状的。
8.4优缺点
免责声明:如果侵犯了您的权益,请联系站长,我们会及时删除侵权内容,谢谢合作!更多信息从访问主页:qidao123.com:ToB企服之家,中国第一个企服评测及商务社交产业平台。
欢迎光临 IT评测·应用市场-qidao123.com技术社区 (https://dis.qidao123.com/)
Powered by Discuz! X3.4











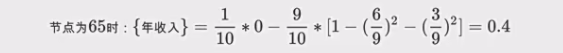








 enguin)
enguin)