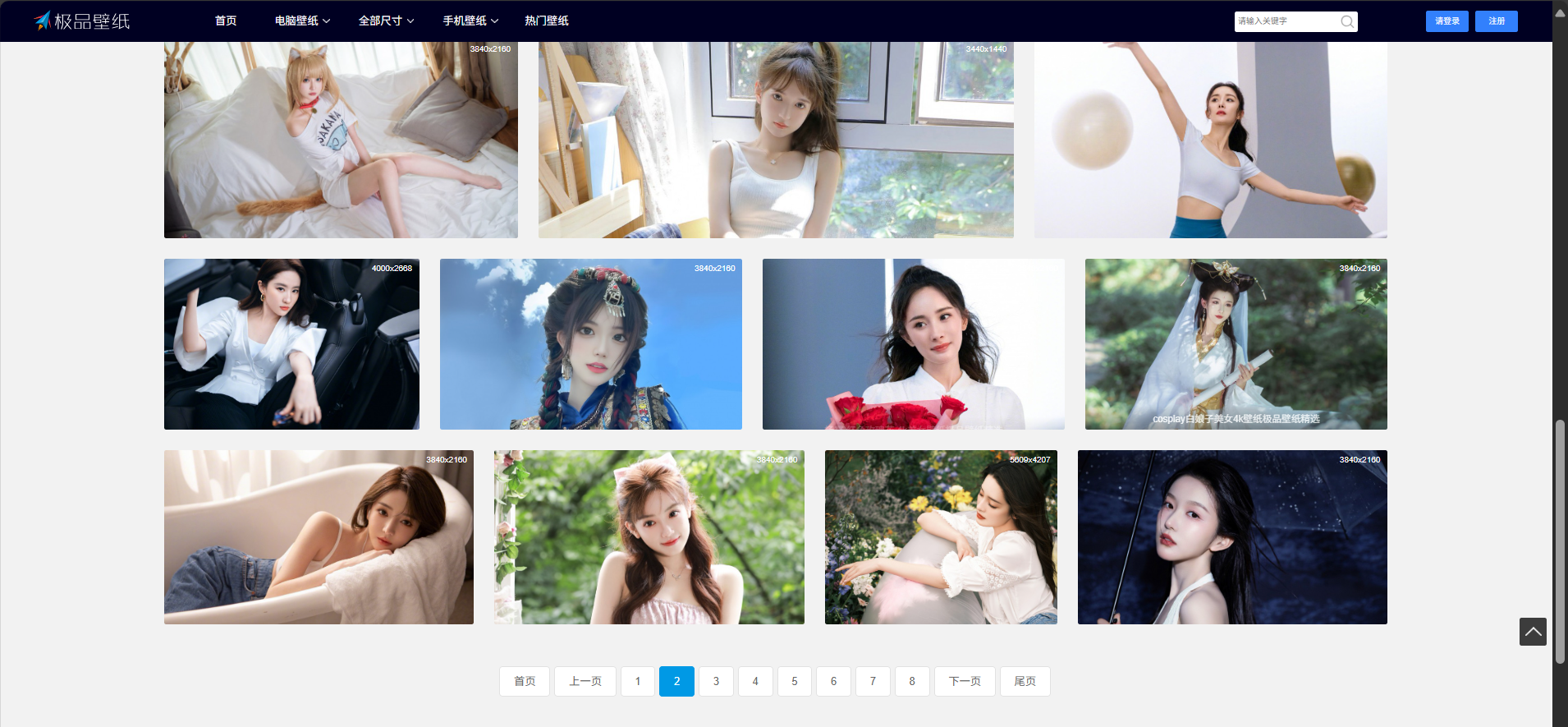
思绪:由于这次搜索的目的网页是分页式的,以是采用requests+lxml技能爬取数据。但是这次的网站图片数据累计4296张图片,如果采用单线程爬取这些数据,那么爬完所有数据将多花费一些时间,而如果采用多线程ThreadPoolExecutor技能,那么爬取数据的速度将会大大提高。
下面是目的网页
由于所有页面的的url链接只有一个参数不同,所有采用循环的方式,将其封装成一个列表url_list并返回。
img_url_dict是一个字典,键是图片的名字,值是图片的url,这样封装好后,方便后面的调用。
下面是爬虫模块,其中将图片的src链接中的newpc202302替换成lan20221010,可以提高图片的清晰度,只管最终得到的图片依然不是4K高清的,但已经较为清晰。
利用ThreadPoolExecutor函数,开五个线程同时爬取网页图片
| 欢迎光临 qidao123.com技术社区-IT企服评测·应用市场 (https://dis.qidao123.com/) | Powered by Discuz! X3.4 |