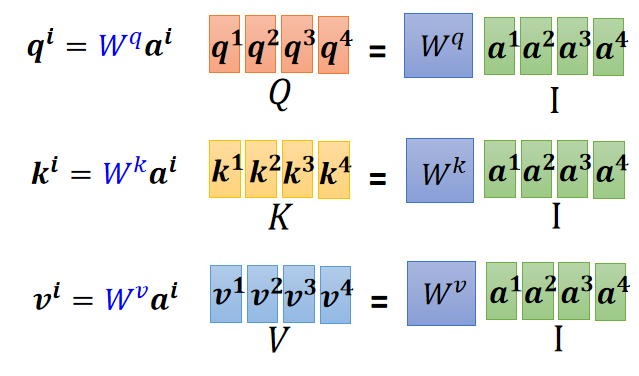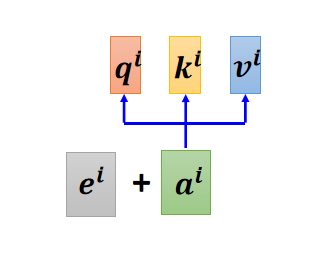IT评测·应用市场-qidao123.com技术社区
标题:
【深度学习—李宏毅教程条记】Self-attention
[打印本页]
作者:
愛在花開的季節
时间:
7 天前
标题:
【深度学习—李宏毅教程条记】Self-attention
目次
一、Self-attention 的引入
1、多样化的输入情势
2、典型的下游任务下游任务
3、传统“全连接 + 窗口”方法的局限
4、Self‑Attention 的引入
二、Self-attention 的架构
1、Self-attention层的框图表示
2、Self-attention 层的矩阵运算过程
三、Multi-head Self-attention
四、位置编码
五、Self-attention 的应用
1、在自然语言处置惩罚(NLP)中的典型应用
2、在语音信号处置惩罚中的应用
3、在计算机视觉中的应用
4、Self‑Attention 与卷积神经网络(CNN)的对比
5、Self‑Attention 与循环神经网络(RNN)的对比
6、在图结构数据(GNN)中的应用
7、高效 Transformer 与将来方向
8、总结
一、Self-attention 的引入
1、多样化的输入情势
对于常见的机器学习任务,输入情势是多样的:
单向量(Vector)
最底子的输入情势,例如将一段文本或一帧语音直接映射为实数向量。
向量集合(Set of Vectors)
句子中每个单词、语音信号中的每一帧、图结构中的每个节点,都可看作一个向量,模型的输入即这一组向量。
而这种输入情势正是适合 Self-attention 的输入情势。
例如:
文本中单词的 one‑hot 编码或预训练词向量
语音信号按帧提取的 MFCC 或滤波器组特性
社交网络中每个用户节点的属性向量
2、典型的下游任务下游任务
根据输入向量集合,模型的输出情势主要有以下几类:
逐向量标注(Sequence Labeling)
对每个输入向量分别打标签,常见任务如词性标注(POS Tagging)、命名实体辨认(NER)等。
序列级分类(Sequence Classification)
对整个向量序列赋予一个标签,如情绪分析、话者辨认等。
动态标签数预测
模型无需预先固定标签数量,例如聚类任务或机器翻译中的对齐机制。
序列到序列映射(Seq2Seq)
输入和输出均为向量序列,典型应用为神经机器翻译
3、传统“全连接 + 窗口”方法的局限
全连接层(Fully‑Connected)
:只能将每个向量独立映射,缺乏上下文信息;
滑动窗口(Window)
:固然可引入局部邻域信息,但窗口巨细有限,难以捕获远距离依靠;
问题示例
:单句“I saw a saw”,对第二个“saw”需要同时考虑前文的“I saw a”与后文的寄义,但窗口方法可能覆盖不到全部上下文
4、Self‑Attention 的引入
为了办理上述方法无法建模全局依靠的问题,在此处引入
Self‑Attention
概念:
核心头脑
在给定序列中,每个元素不仅与自身相关,还与序列中所有其他元素进行交互,通过计算相似度权重来聚合全局信息。
预期效果
既能机动捕获长距离依靠,又能保存序列中各元素的相对位置信息(后续可联合位置编码)。
后续睁开
详细计算方式包括 Query/Key/Value 的映射、点积打分、缩放与 Softmax、加权求和,以及多头机制等。
二、Self-attention 的架构
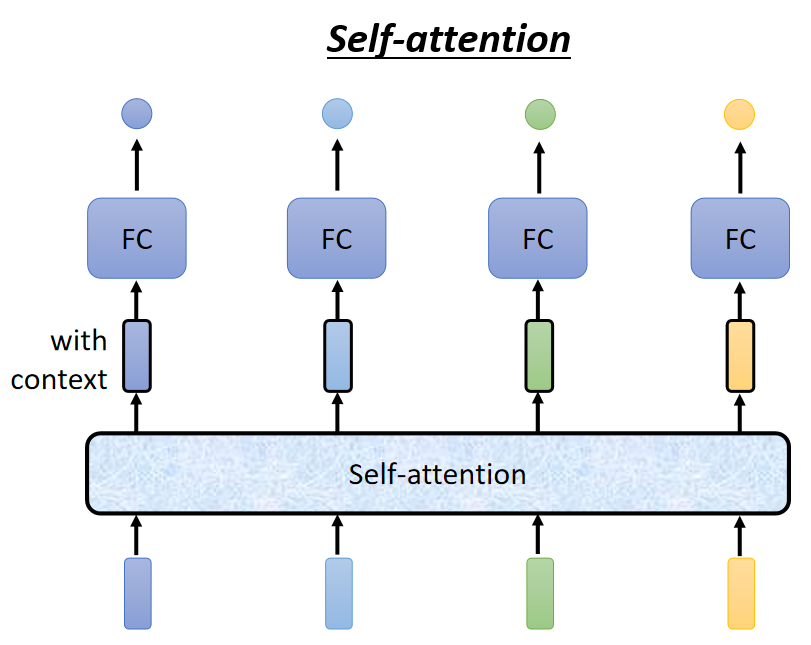
1、Self-attention层的框图表示
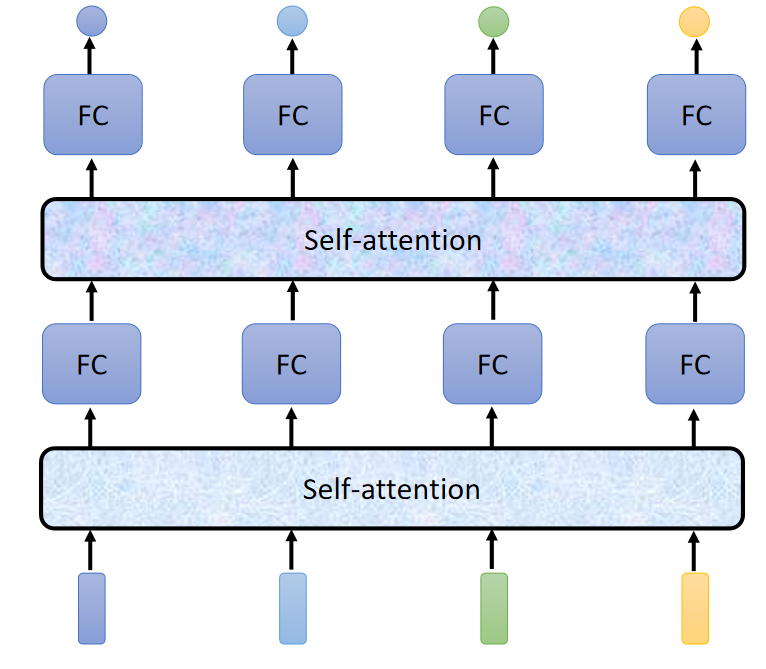
Self-attention 的架构大体就上面的图片上的样子,有时在应用时可叠多层,如下图:
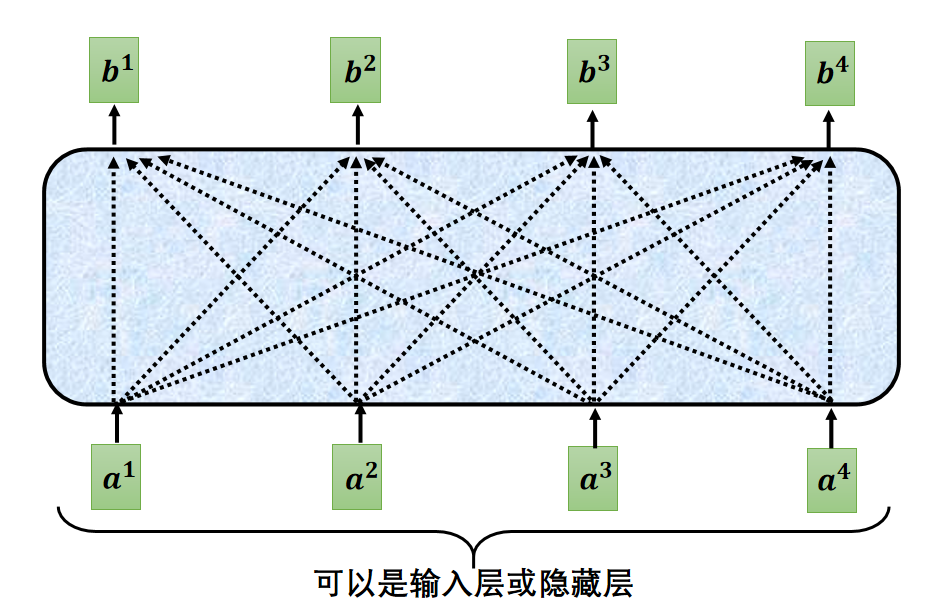
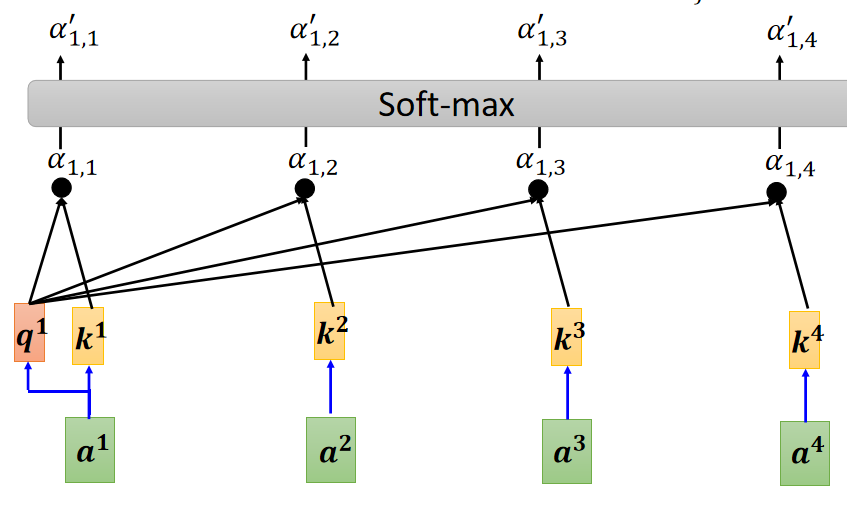
其中的每一个输出不仅仅只与对应的一个输入有关,其余的说有输入都影响到这个输出,比如
不仅仅与
有关,还受
的影响,如下图:
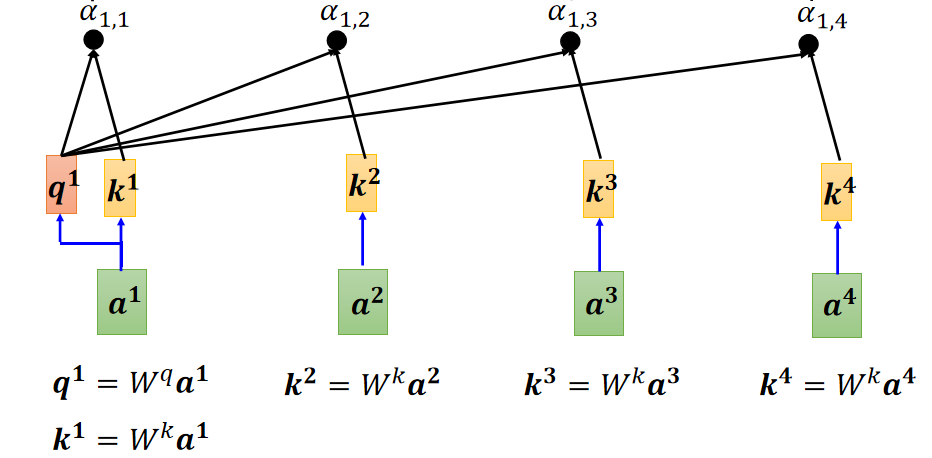
在计算
时,可先建立
与
的联系,用
表示,如下图:
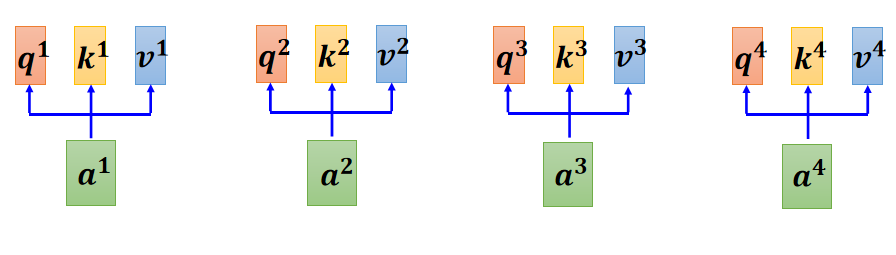
每一个输入都有一个自己的 Query、Key、Value,(Value后续用到)。Query、Key、Value都由相应的输入和一个参数矩阵
,
,
相乘得到,对于每一个输入,用的参数矩阵
,
,
都是相同的。
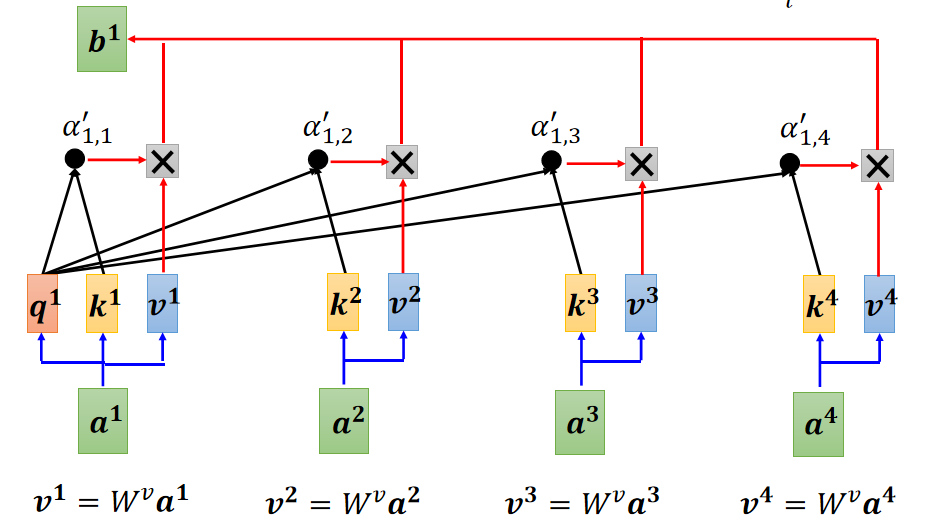
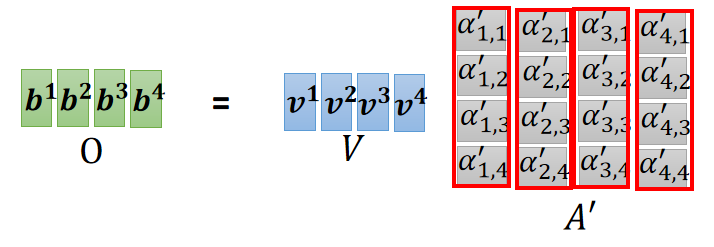
得到了 各个输入之间的关系
,后将他们送到softmax层进行归一化,再与各个输入的 Value 相乘后加一起,就得到了
,如下图:
这就是 Self-attention 层从输入到输出的过程。所有的输出都是
并行的
。
2、Self-attention 层的矩阵运算过程
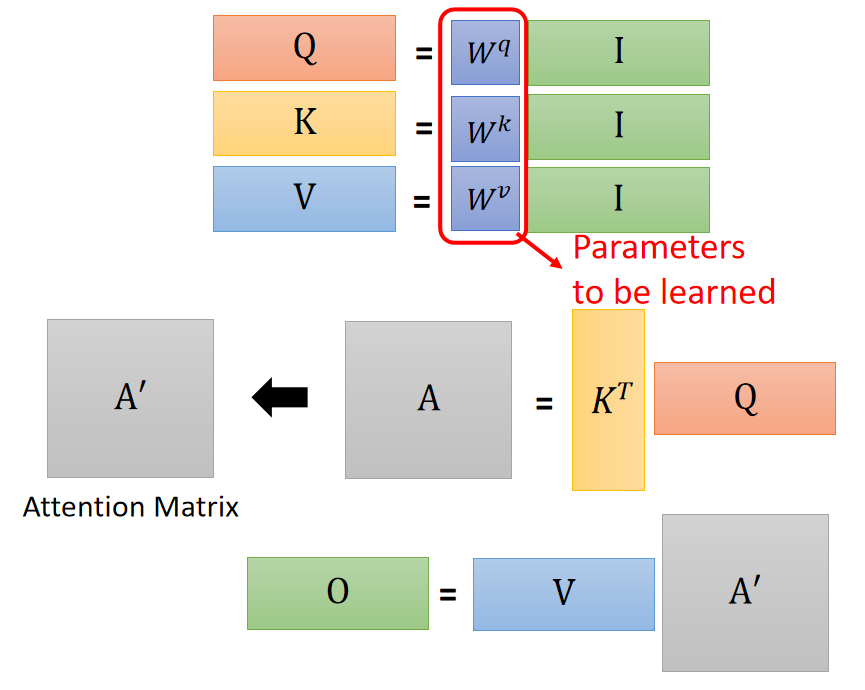
步骤一:
一个 Self-attention 层的参数就只有三个矩阵:
,
,
,它们三个的任务是与输入分别相乘得到每个输入对应的 Query、Key、Value ,详细如下:
步骤二:
接着由矩阵
和矩阵
相乘得到矩阵
,再经过softmax得到
步骤三:
然后再由矩阵
和矩阵
相乘得到 输出矩阵
可更清楚得表示为
步骤一:
步骤二:
步骤三:
即全流程为:
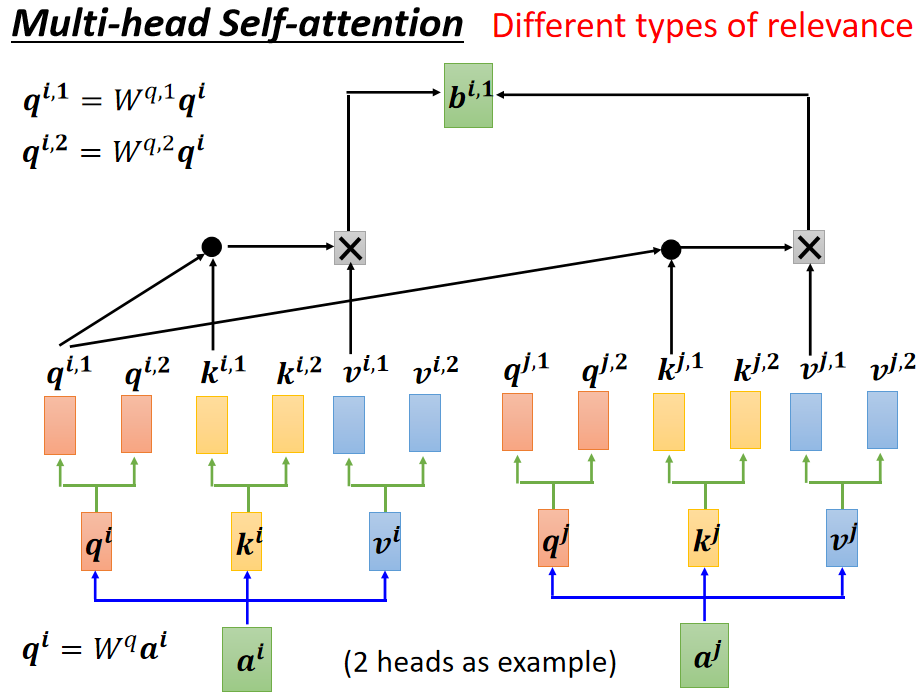
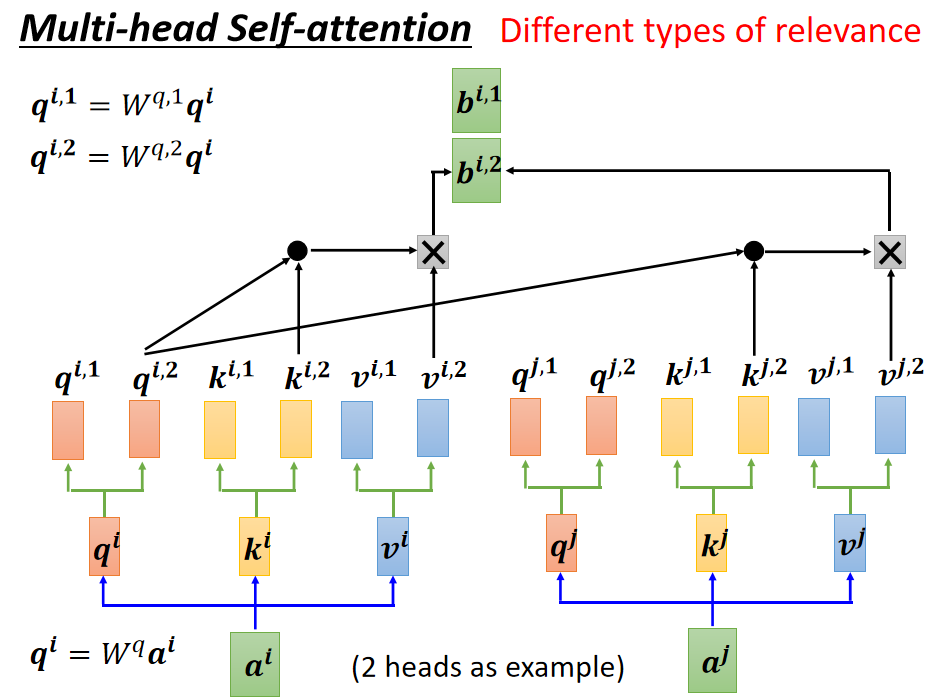
三、Multi-head Self-attention
再平常 Self-attention 的底子上 添加多个注意力矩阵的运算,通过多头注意力找到输入之间的多种差别的相关性,即:
得到
和
,再将它两个乘上一个矩阵变成一个,即
四、位置编码
对于上面的 Self-attention ,其中忽略了输入之间的位置信息,但这并不能说位置信息就丢失了,在学习过程中,位置信息会被学到,但如果提前加入位置信息,那么对于位置信息,模型就能更轻易的得到,相当于帮助了模型对位置信息的学习,也可以说对位置信息提前加入了先验,效果更好。所以说就有了位置编码。
位置编码的方式:
给输入
加上一个向量
,即:
向量
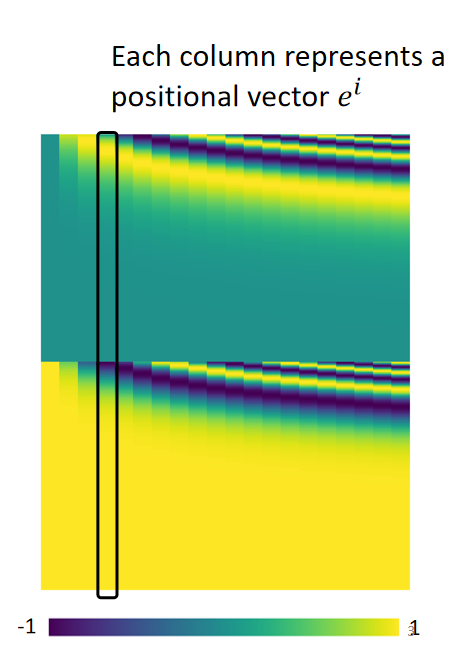
长什么样子呢?最早的论文中的向量
如下图:
每个列都代表一个向量,从左到右依次是
,
,
,
,玄色框里的是
.
在论文 《All attention is you need》中它的位置向量是通过一个固定的规则所产生的,这个规则是一个很神奇的 sin cos 的函数所产生的。
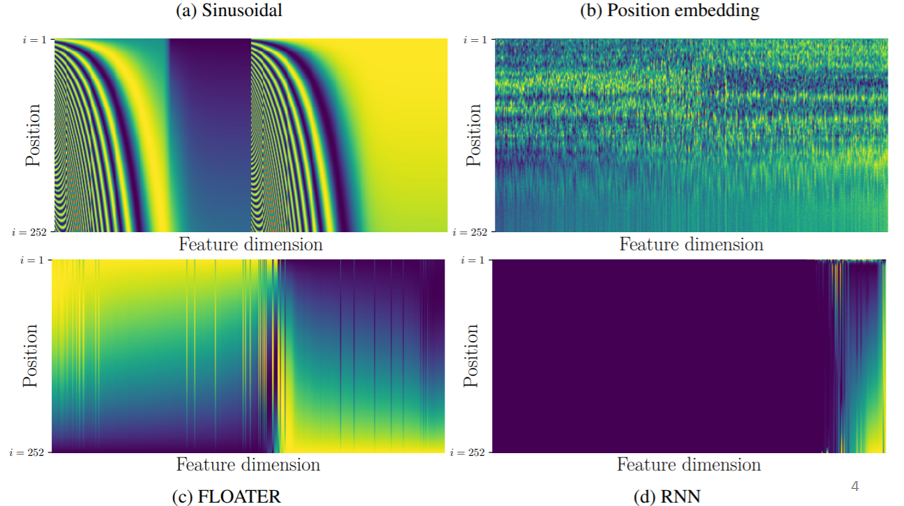
更多的位置编码:
第一个图的位置向量是横着看的,是用 sin 函数产生的,第二个图是学出来的,即位置向量通过学习得到的,
五、Self-attention 的应用
1、在自然语言处置惩罚(NLP)中的典型应用
Transformer 与 BERT
:
Transformer 架构首次将全局自注意力引入序列建模,实现了并行化训练和长距离依靠捕获。
BERT 在预训练阶段利用双向自注意力,有用地学习上下文表示,推动了阅读理解、文本分类等任务性能大幅提升。
2、在语音信号处置惩罚中的应用
长序列带来的挑战
:语音信号通常以 10ms 为帧长,序列长度极大,直接计算全局注意力矩阵代价高。
截断自注意力(Truncated Self‑Attention)
:仅对固定窗口或范围内的帧计算注意力,减少计算复杂度;
局部范围内的注意力
:联合局部上下文,有助于捕获短时特性,同时兼顾部分全局信息。
3、在计算机视觉中的应用
Self‑Attention GAN
(SAGAN)
在生成对抗网络中加入自注意力模块,加强远距离像素间的信息交互,提高生成图像的细节同等性。
Detection Transformer(DETR)
将检测任务情势化为集合预测,引入全局自注意力取代传统的区域建议或锚框策略,实现端到端目标检测。
4、Self‑Attention 与卷积神经网络(CNN)的对比
感受野
:
CNN:固定且局部的感受野,由卷积核巨细决定。
Self‑Attention:学习到的注意力权重即可视作可调治的“感受野”,可跨越全局。
表达本领
:
Self‑Attention 是带可学习权重的复杂版本,可以大概机动建模恣意位置间的关系;CNN 是其简化情势。
5、Self‑Attention 与循环神经网络(RNN)的对比
并行性
:
RNN 串行处置惩罚,难以并行;Self‑Attention 并行度高,训练速度快。
依靠建模
:
Self‑Attention 天然捕获长距离依靠;RNN 随序列长度增长易产生梯度消失。
记忆机制
:
自注意力通过键值对存储中心信息,类似可扩展的外部记忆。
6、在图结构数据(GNN)中的应用
图注意力网络(GAT)
:
对图中的每条边应用自注意力,仅在相邻节点间计算注意力分数,实现节点特性的加权聚合。
优势
:更机动地建模异质图结构中的节点关系,提升节点分类、链路预测等任务性能。
7、高效 Transformer 与将来方向
Efficient Transformers
(《Efficient Transformers: A Survey》)
梳理了各种低落注意力复杂度的方法,如稀疏注意力、分块注意力、低秩分解等。
Long Range Arena
基准
提供了对比差别高效 Transformer 在多种长序列任务上的表现,为后续模型设计提供评测标准。
8、总结
Self‑Attention 作为一种通用的关系建模机制,已广泛渗出到 NLP、语音、视觉、图神经网络等领域。其核心优势在于并行化训练、长距离依靠捕获与可学习的全局感受野;同时,面对序列长度过大时,也催生了各类高效变体(如截断、稀疏、分层注意力)来平衡性能与计算资源。
免责声明:如果侵犯了您的权益,请联系站长,我们会及时删除侵权内容,谢谢合作!更多信息从访问主页:qidao123.com:ToB企服之家,中国第一个企服评测及商务社交产业平台。
欢迎光临 IT评测·应用市场-qidao123.com技术社区 (https://dis.qidao123.com/)
Powered by Discuz! X3.4