IT评测·应用市场-qidao123.com技术社区
标题:
Hadoop(2)-MapReduce
[打印本页]
作者:
东湖之滨
时间:
2025-4-20 22:27
标题:
Hadoop(2)-MapReduce
MapReduce
mapReduce是一个软件框架,而不是独立运行的中间件。
由于时代的发展,mapreduce逐渐被新的分布式计算框架代替,而mapReduce的思想仍旧是主流。
使用
hadoop -jar xx.jar jobName inputDir outputDir
通过-jar指令,向Hadoop提交一个jar包, jar包内含了计算使命
依赖包:org.apache.hadoop::hadoop-client
优点:
易于编程,高容错 分布式集群,一旦计算失败,可以随时切换到其他节点
高可扩展 计算本事可以任意通过机器举行扩展
海量数据 支持TB级的数据计算
缺点
计算耗时长,启动时间长,中间过程还必要举行磁盘IO写入。 相比于spark是通过内存写入,计算时间太长
流式计算本事弱,
计算不够灵活,计算流程过于固定,
核心思想
整体分为mapper shuffle reduce三个阶段
mapper
用户实现部门
通过InputFormat读取一定结构的数据,如TextInputFormat 按行, 或DBInputFormat ,整体数据源读取比力单一
void map(Object key, Text value, Context context)
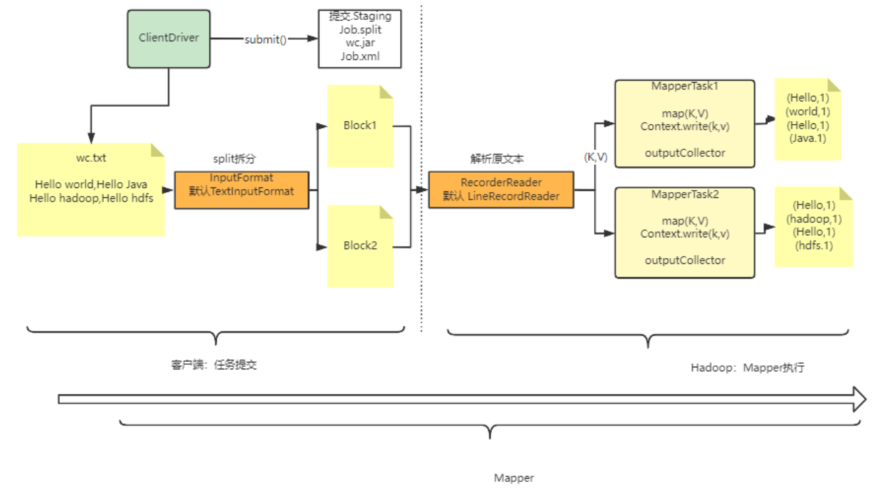
阶段一
,客户端提交使命阶段阶段。主要对文件举行切片和提交使命信息到HDFS
客户端会在提交使命前,对待处置惩罚的数据(主要是文本)举行预处置惩罚,文本数据按照BlockSize巨细举行拆分
客户端将使命信息提交到HDFS
客户端将MapReduce执行的使命文件上传到HDFS后,就会关照Runner执行
阶段二
,MapTask使命执行阶段。这一阶段会启动多个MapTask,执行Mapper使命。MapTask的数量取决于上一阶段分片的个数。
MapTask会先将文件读取成K-V类型的元数据,再交由Mapper执行(按行TextInputFormat等) key=0, value = hello Bob, hello Joy
每一个Block会启动一个MapperTask来处置惩罚,并终极通过outputCollector将分散的处置惩罚结果收集起来
mapper处置惩罚示例:
输入:key=0, value = hello Bob, hello Joy
对数据举行自定义的拆分(按空格) hello, Bob, hello, Joy
执行分为本地执行LocalJobRunner, yarn调度执行YARNRunner
本地执行中,先创建一个运行的目录,写入使命信息,然后启动一个线程run
run方法中,
以线程池分别执行mapper和reduce方法
mapper执行完后,将结果写入到磁盘。
reduce从磁盘读取mapper结果执行(
注:mapper和reduce是独立的两个线程池运行,并没有强制先后关系,reduce只要读取到满足条件的文件,就可以提前执行
)。
使命执行完成后,使命目录和运行目录都会清空
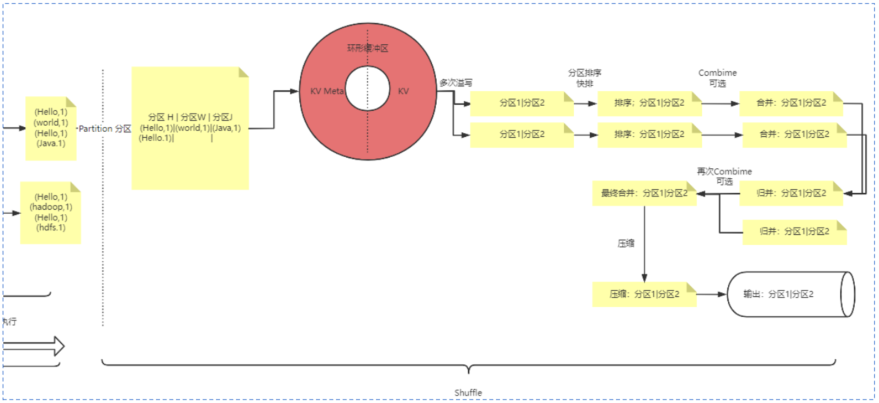
shuffle
shuffle阶段是Hadoop实现的阶段
1 分区
Mapper阶段输出的数据,会颠末Partition举行分区,分区的目的是为了将mapper输出的数据生存到哪个文件。
终极这个生存的文件,是会被reduce读取并计算。
分区操纵是通过Partitioner接口来实现的,默认是HashPartitioner,根据reduce的个数取模:hash(key)%num_red
用户可以通过实现Partitioner的方式自定义分区实现
2 排序
数据通过环形缓冲区溢出后,写入到各分区的磁盘文件,会通过快排算法举行排序。
3 归并
由于环形缓冲区是多次溢出的,会写多个文件,必要将雷同key的文件举行归并并排序。
期间会颠末一次或多次归并排序,终极得到预分区数的文件。
转交给reduce阶段
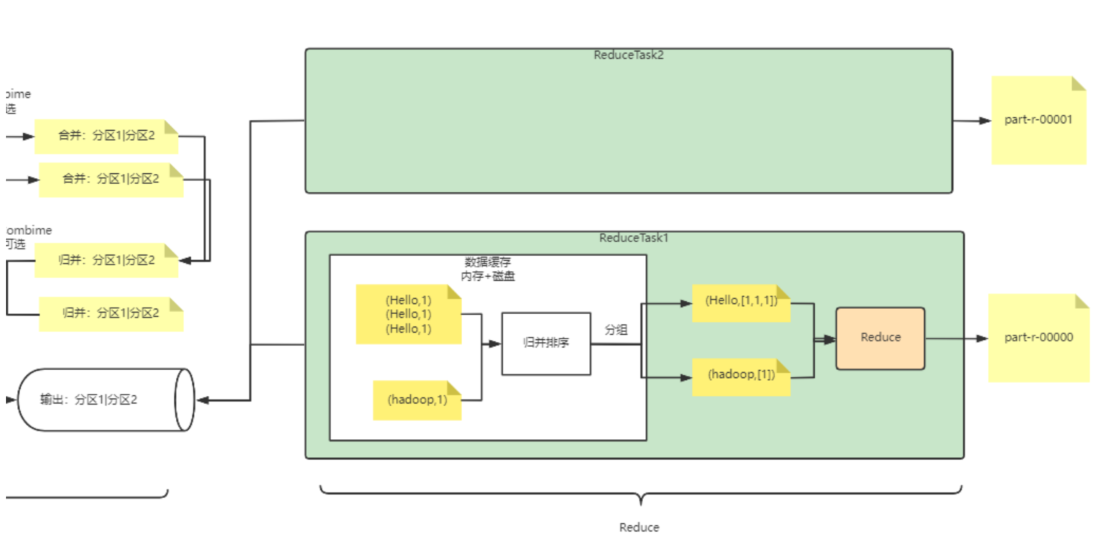
Reduce
由用户实现, 计算shuffle产生的数据
启动时机
通常情况下,Reduce必要收集Mapper输出完的结果,所以必要等全部的Mapper使命执行完成后再启动。但是,Mapreduce框架也会根据计算情况举行优化。在某些Reduce使命所依赖的Mapper使命全部完成了之后,这些Reduce可以提前启动,而不用等待全部的Mapepr使命执行完成
拉取相关数据
1 MapTask的并行度是由切片个数决定的,而ReduceTask的并行度则不同,可以通过setNumReduceTasks方法手动指定,默认是1。
2 MapTask将数据输出到磁盘,ReduceTask自动去磁盘上长途拷贝一片数据。如果数据巨细凌驾了一定阈值,就会将一部门数据写入到磁盘当中。
3 排序之后,Reduce会对数据举行分组,将雷同key的数据整合到一起。之后才进入用户自定义的Reduce方法中举行聚合。
归并数据
ReduceTask在获取到数据之后,会对内存和磁盘中的数据举行归并。将雷同key的数据整合在一起,而Value整合成一个数组
而在归并过程中,为了将雷同的key快速归并到一起,ReduceTask 还会对数据再举行一次排序,排序之后的数据针对雷同的key,局部有序
执行用户自定义reduce
每个Reduce接收到的数据是按key局部有序的,但是多个Reduce使命之间的key并不能包管是有序的
每个Reduce都将结果输出到自己对应的目的文件中,输出的结果同样是按照key在每个文件内局部有序,整体并不包管有序
Reduce的计算结果,终极交由FileOutputFormat的实现类来输出。默认加载的是TextOutputFormat
也可以按指定的形式输出结果,如文本, 数据库 mq等
void reduce(Text key, Iterable<Writeable> values, Context context);
示例:
输入参数:key = hello, values = [1,1]
通过add累加输出。
hello, 2
Bob, 1
Job, 1
高级功能
数据倾斜
shuffle阶段会对数据举行分区处置惩罚,在分区时,一旦分区不均衡,就会导致下个阶段的各个reduce使命不均衡,造成部门reduce空闲。
表现形式就是使命开始处置惩罚很快,然后就变慢了。 这就是mapper shuffle阶段快,到了reduce阶段,由于分区不均造成reduce变慢。
办理:
默认是通过hash分区的,key.hashCode() % reduceNum。
根据分区表达式,要么改变hashCode, 要么改变reduceNum
1 增长reduceNum可以使分区更均衡一些,但只在部门场景有效
2 根据业务情况对只管不重复的数据举行hash,减少hash冲突,也可以更均衡一些。
自定义数据序列化
定义mapper与reduce之间传递的对象
对象必要实现WritableComparable接口
实现的方法有:
compareTo 用于shuffle阶段的排序
write(DataOutput output) 将对象序列化,写入到output流中, 用于各阶段完成后写入到文档中
readFields(DataInput input) 反序列化对象,从input读取流,转为对象, 用于各阶段开始时从文档读取后转对象
原始数据 -mapper-> 结构化数据 -shuffle-> 排序后的结构化数据 -reduce-> 序列化数据 -> 写入文件
自定义输出文件
reduce默认是按各个reduce输出单独的文件,多少个reducer就输出多少文件。
自定义OutputFormat,可以定义reduce终极输出的文件
注:但由于reduce是分区内有序,原始的分区输出,每个分区文件是有序的。如果将多个reduce输出到一个文件中,这个文件并不是有序的。
实现:
实现RecordWriter
方法:
write(Key, Value)
将终极的key value 写入到必要的地方。
close() 关闭资源
RPC通信
服务端
RPC.Server server = RPC.Builer().build()
server.start()
客户端
Interface proxy = RPC.getProxy(Interface);
proxy.xx()
mapred streaming 指令
代替Job编码
免责声明:如果侵犯了您的权益,请联系站长,我们会及时删除侵权内容,谢谢合作!更多信息从访问主页:qidao123.com:ToB企服之家,中国第一个企服评测及商务社交产业平台。
欢迎光临 IT评测·应用市场-qidao123.com技术社区 (https://dis.qidao123.com/)
Powered by Discuz! X3.4