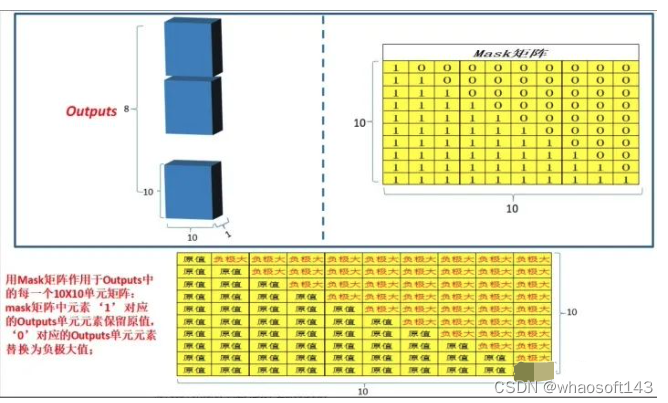
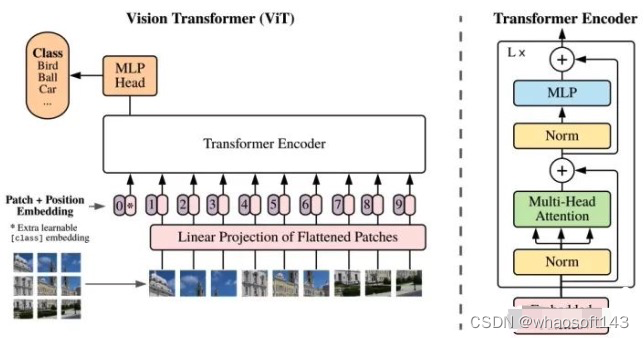
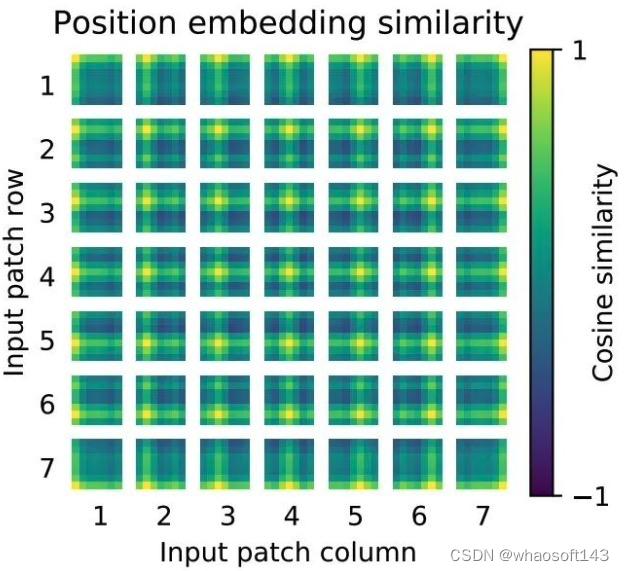
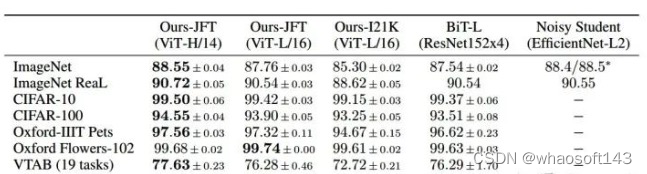
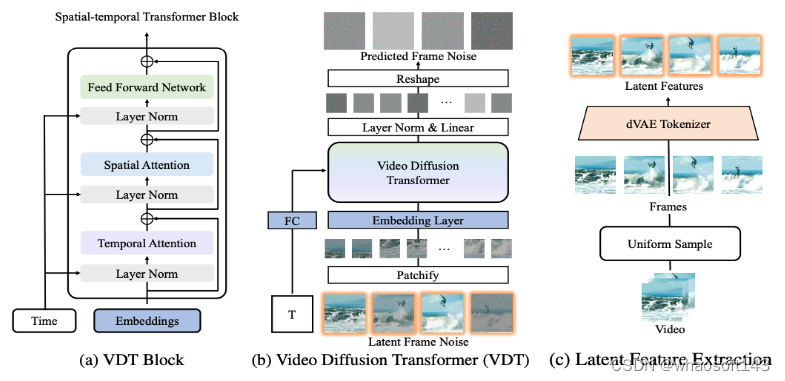
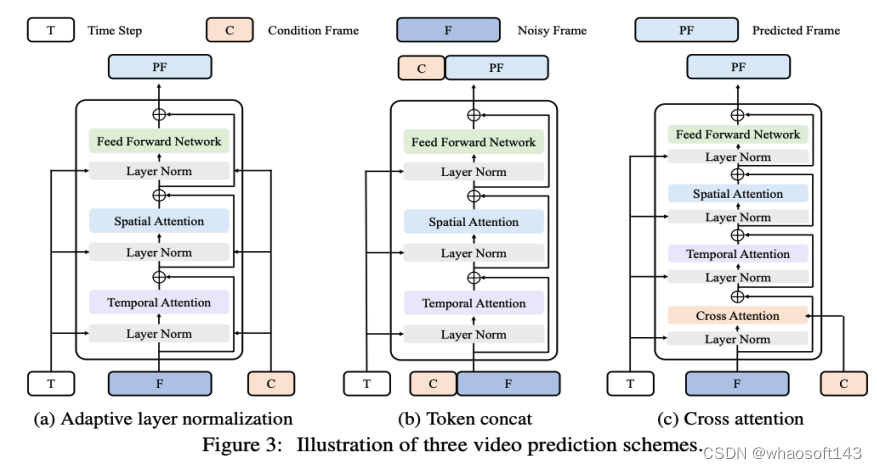
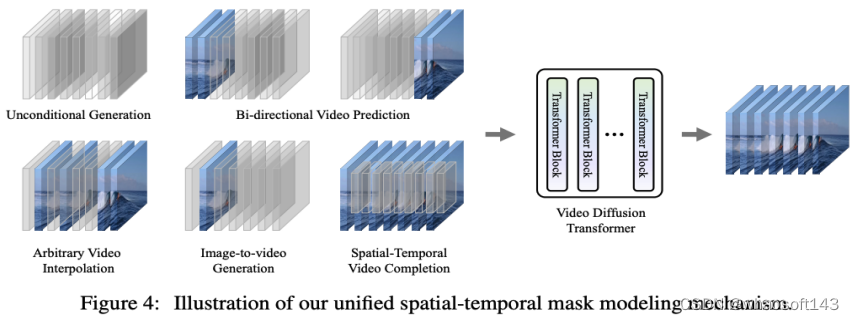
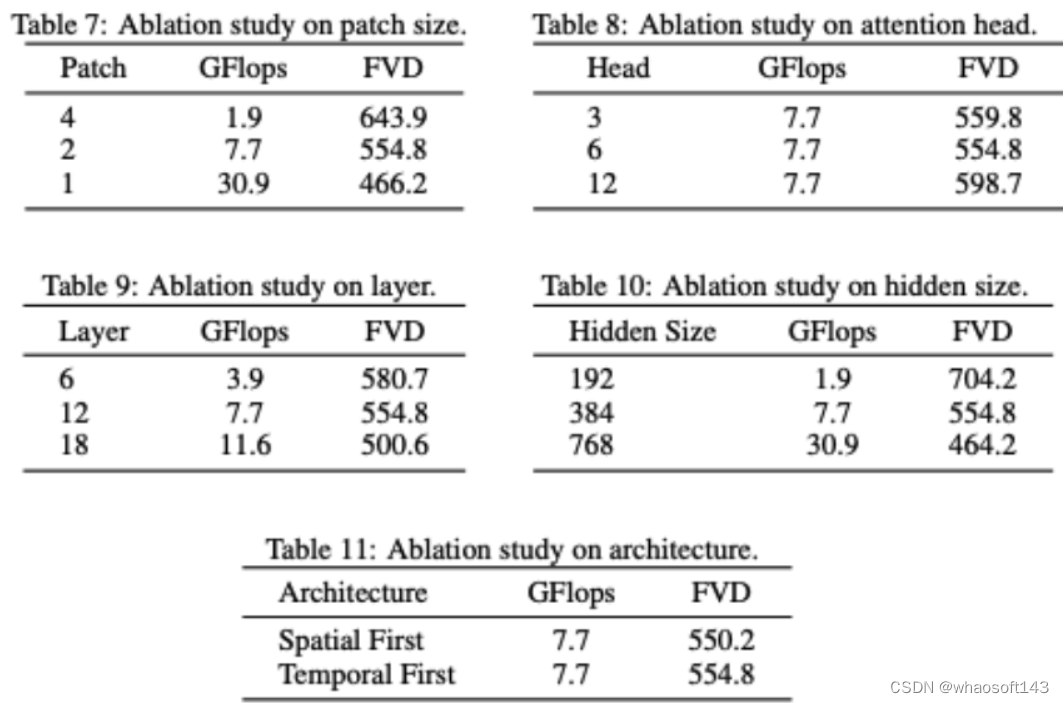
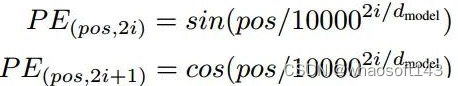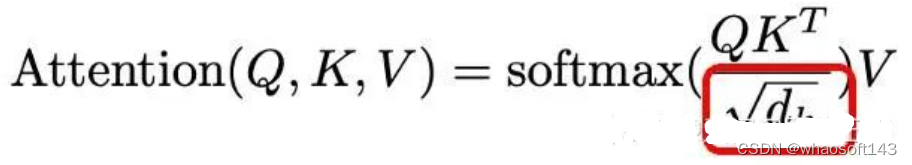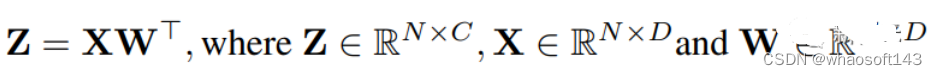新框架 Task Definition
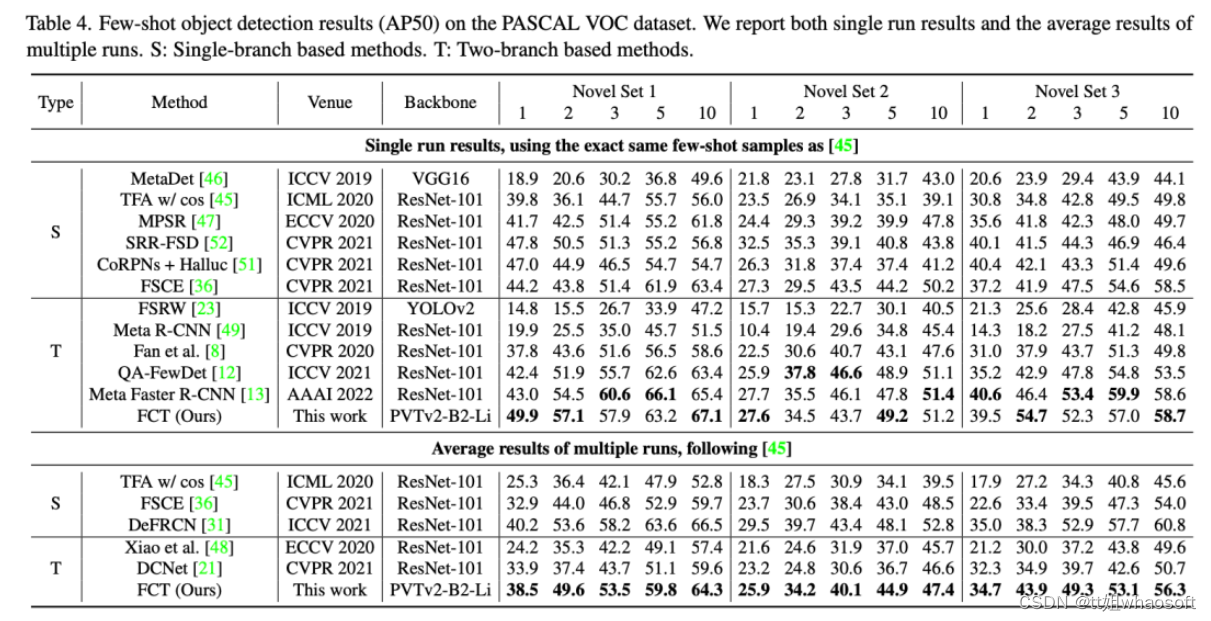
在小样本目标检测(FSOD)中,有两组类C=Cbase∪Cnovel和Cbase∩Cnovel=∅,其中基类Cbase每个类都有大量训练数据,而新类Cnovel(也称为支持类)只有每个类的训练示例很少(也称为支持图像)。对于K-shot(例如,K=1,5,10)目标检测,研究者为每个新种别c∈Cnovel准确地利用K个边界框解释作为训练数据。FSOD的目标是利用数据丰富的基类来帮忙检测少样本的新类。 Overview of Our Proposed Model (FCT)
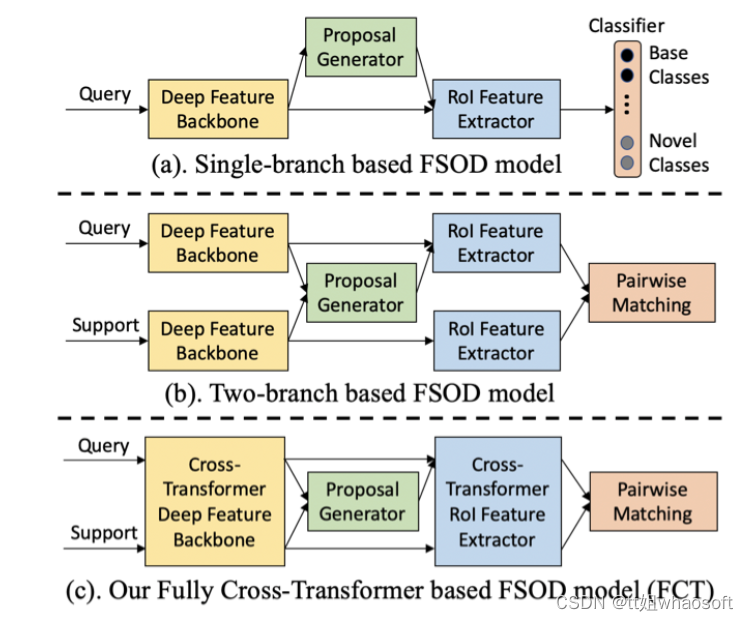
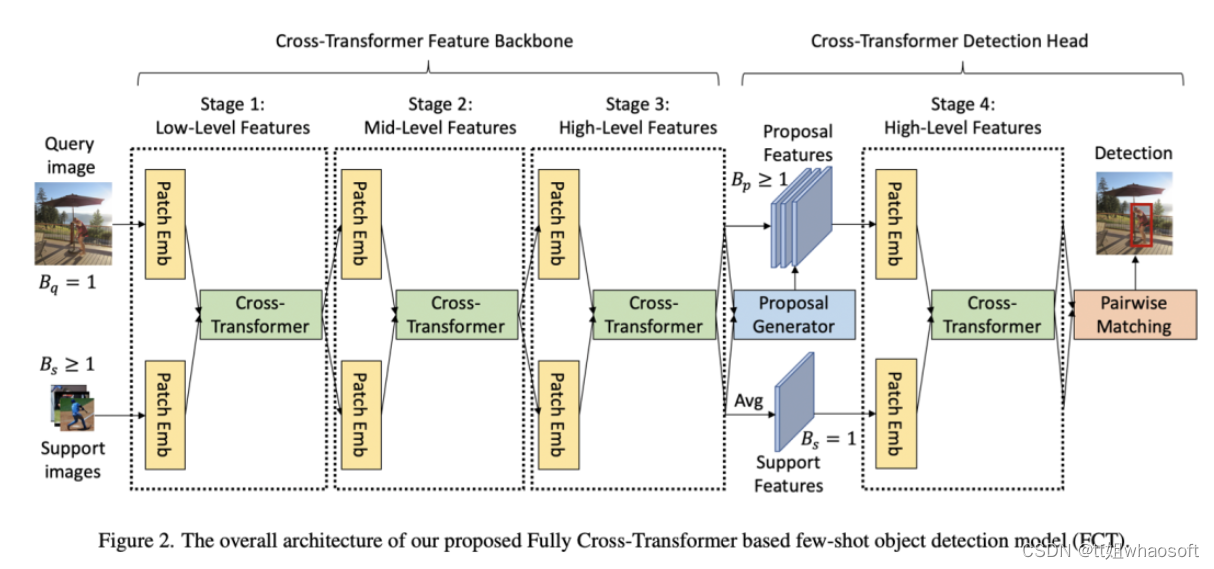
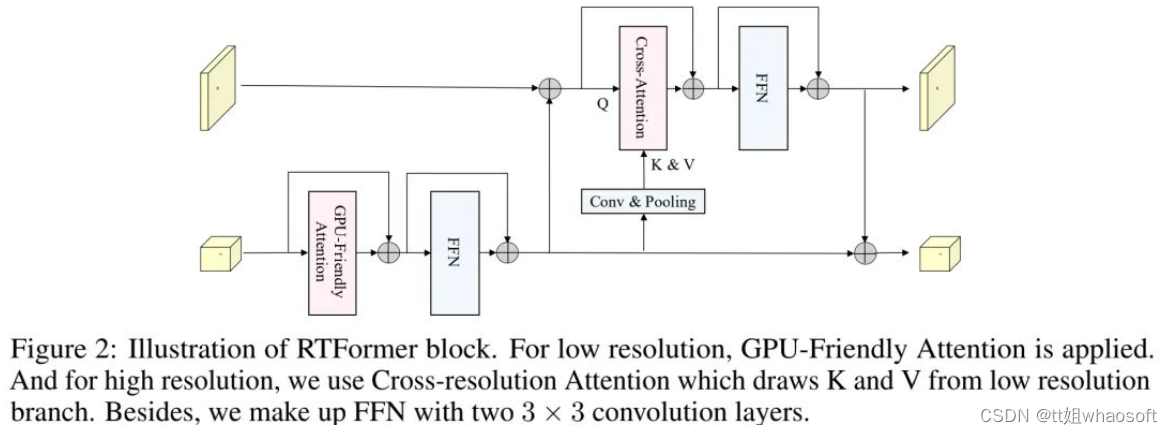
研究者以为以往的two-branch方法只关注了detection head部分的特性交互,忽略了特性提取部分;于是这篇论文的motivation就出来了。因此研究者在Faster RCNN上提出了Fully Cross-Transformer(FCT)的小样本检测方法,在每个阶段都进行特性交互。如下图所示:
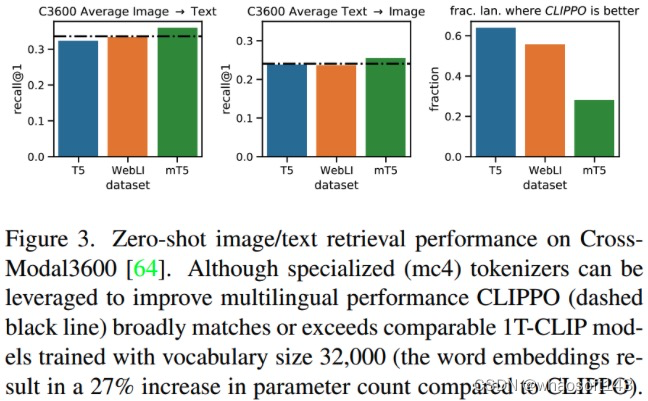
The Cross-Transformer Feature Backbone
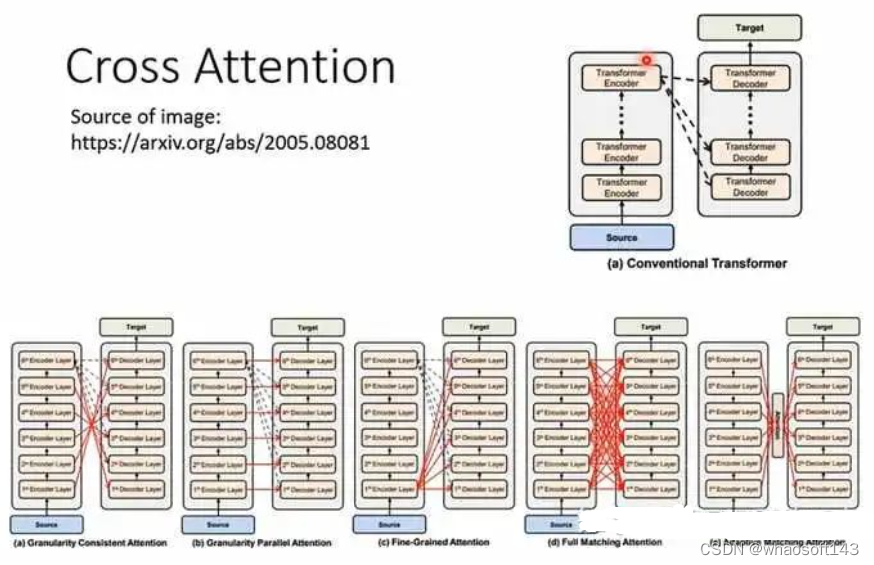
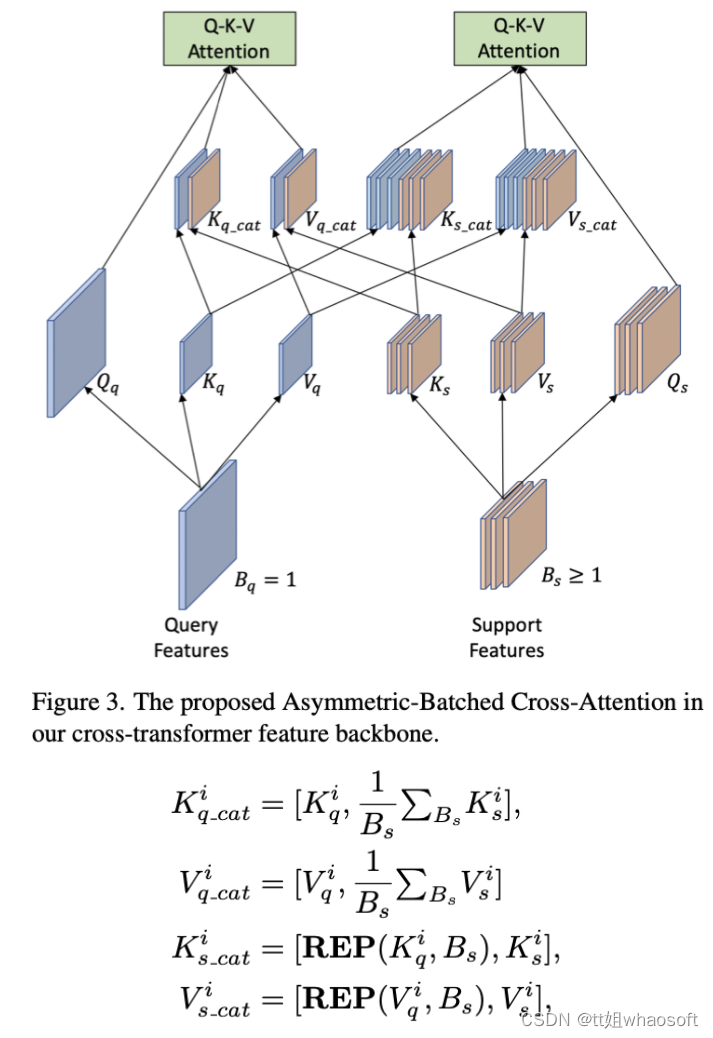
在cross-transformer中计算Q-K-V attention时为了减少计算量,研究者接纳了PVTv2的方式。上面大致介绍了query和support特性提取,在特性交互上作者提出了 Asymmetric-Batched Cross-Attention。详细做法如下图和公式所示:
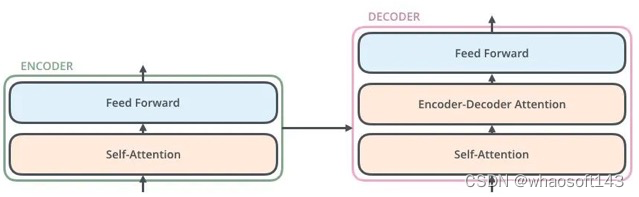
评论。研究者彻底研究了提出的模子中两个视觉分支之间的多层次交互。cross-transformer特性主干中的三个阶段使两个分支与低级、中级和高级视觉特性逐渐有效交互。 The Cross-Transformer Detection Head
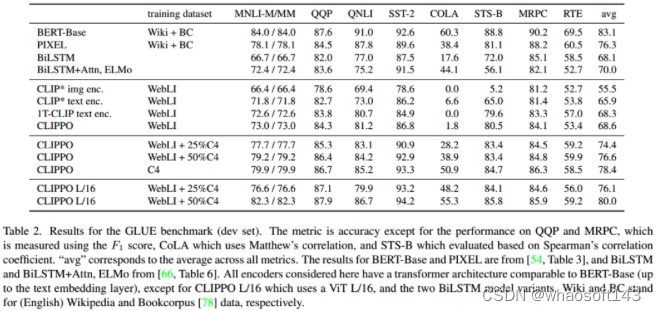
在detection head部分,和以上操作相反,在每张query上提取完proposal之后颠末ROI Align可以得到ROI特性fp∈RBp∗H′∗W′∗C3,其中Bp=100,为了减少计算复杂度还是对support进行ave操作fs′=1Bs∑Bsfs,fs′∈R1∗H′∗W′∗C3,然后利用Asymmetric-Batched Cross-Attention计算俩分支attention,差别的是,query分支Bp≥1 and Bs′=1 。
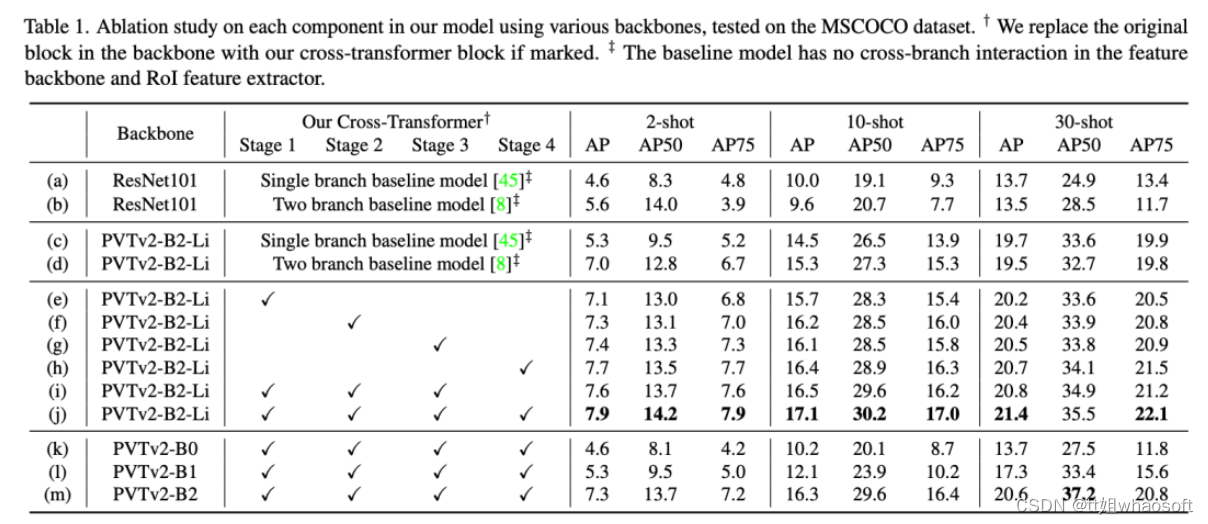
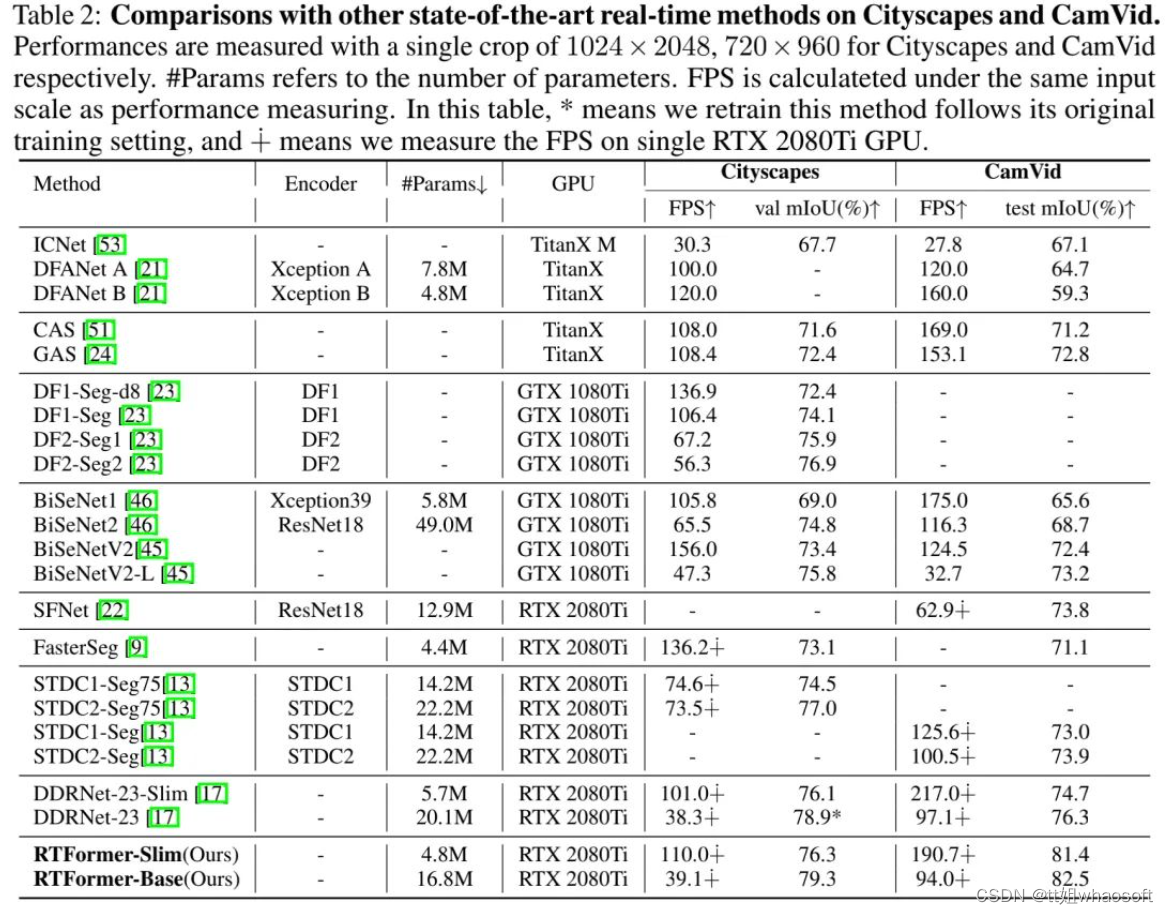
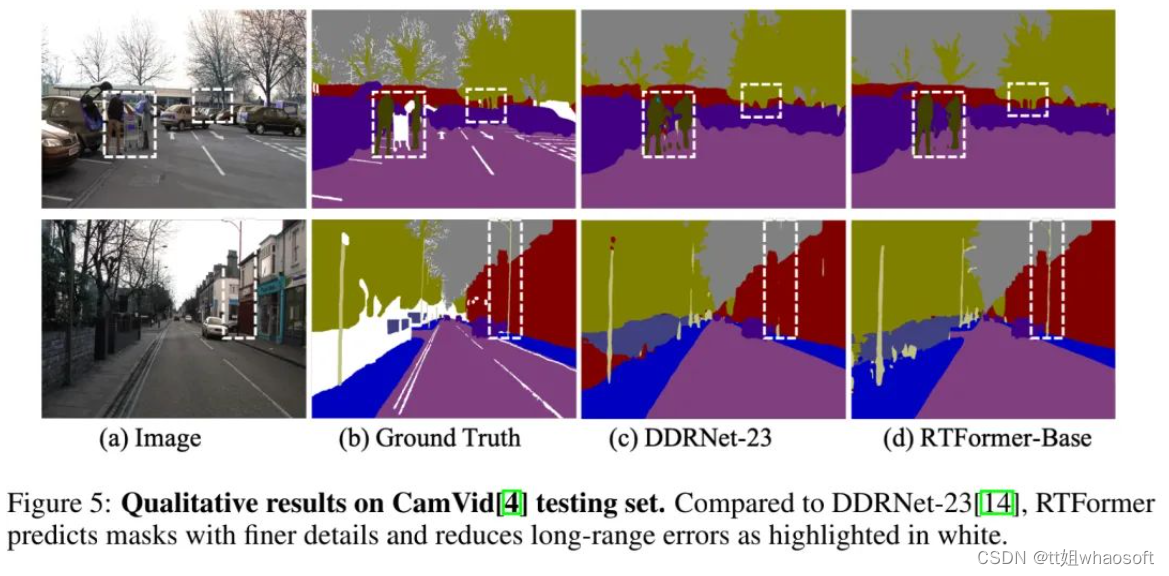
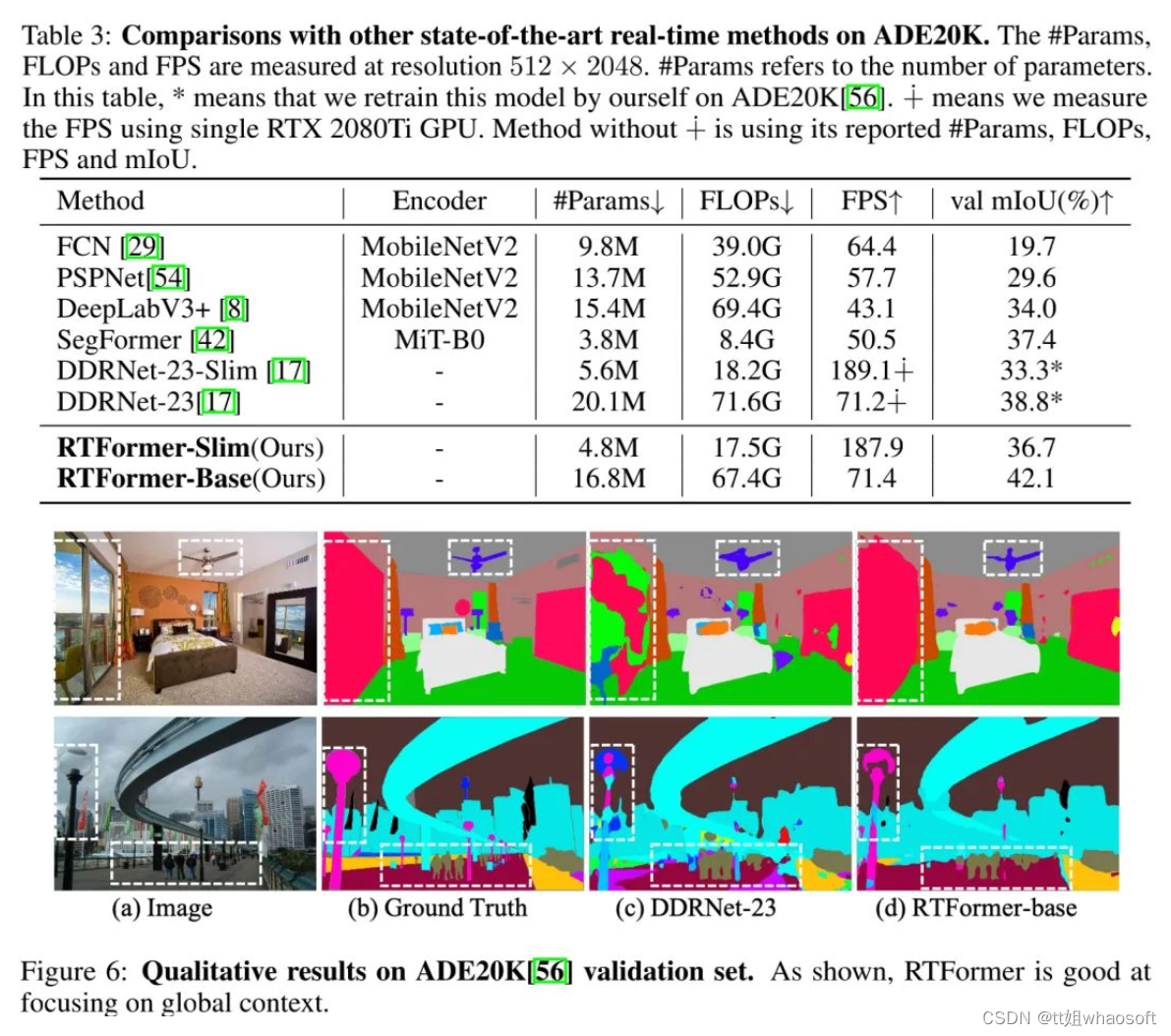
实验
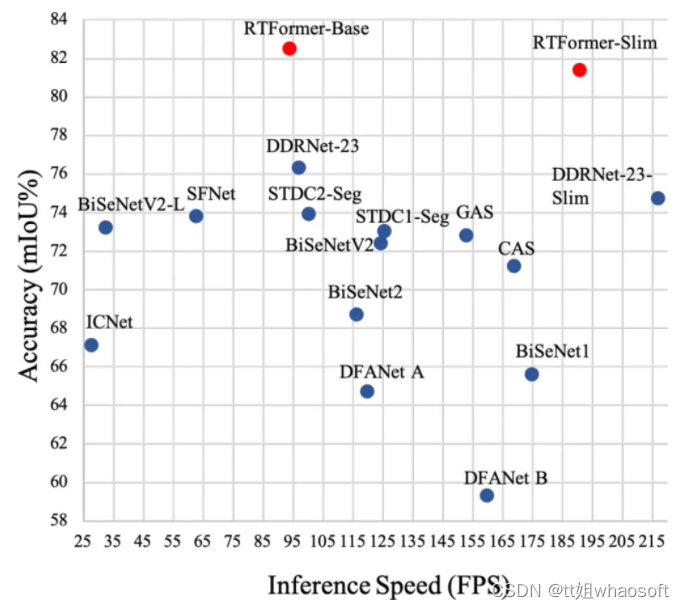
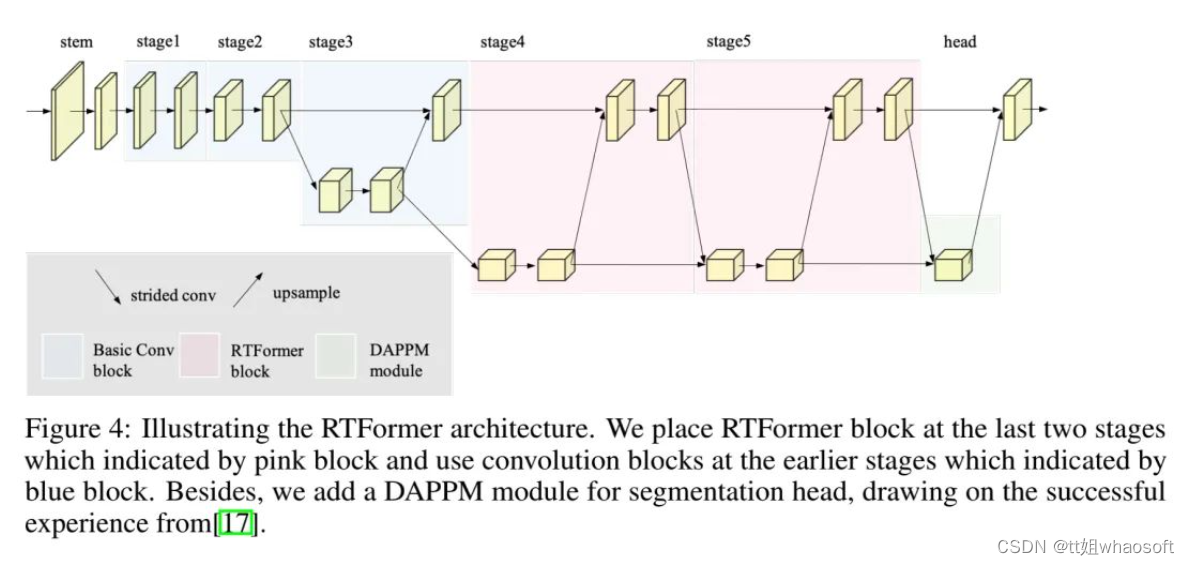
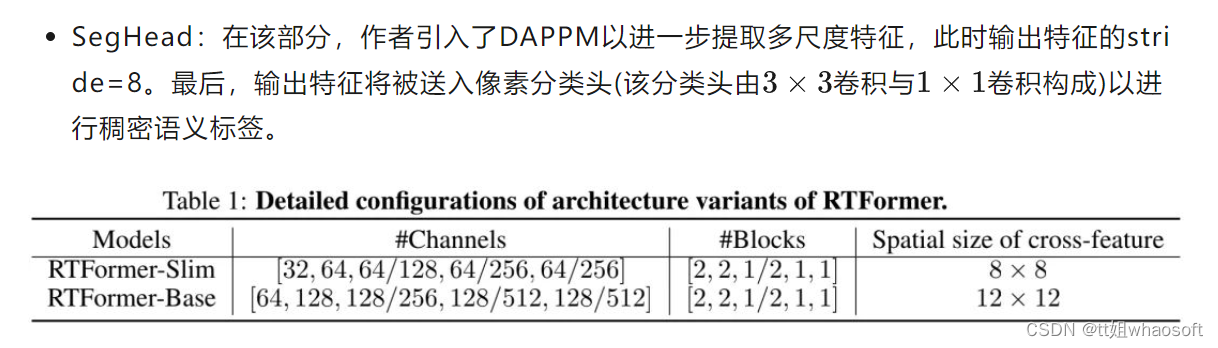
这是一篇综述吧~
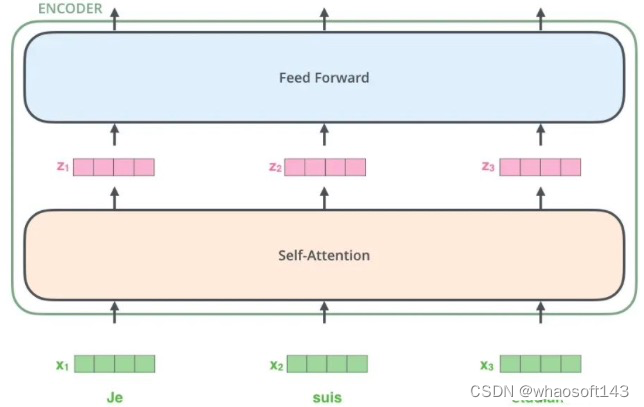
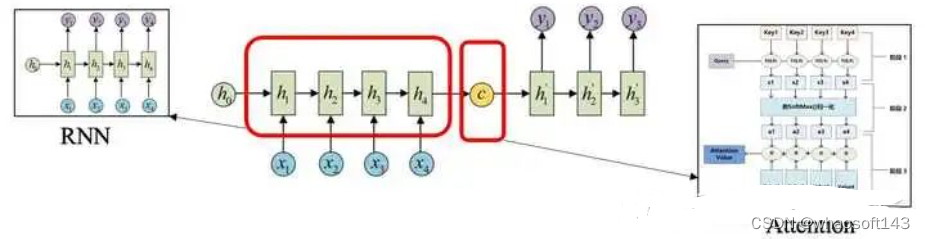
Transformer整个网络布局完全由Attention机制组成,其出色的性能在多个任务上都取得了非常好的效果。本文从Transformer的布局出发,结合视觉中的成果进行了分析,能够帮助初学者们快速入门。
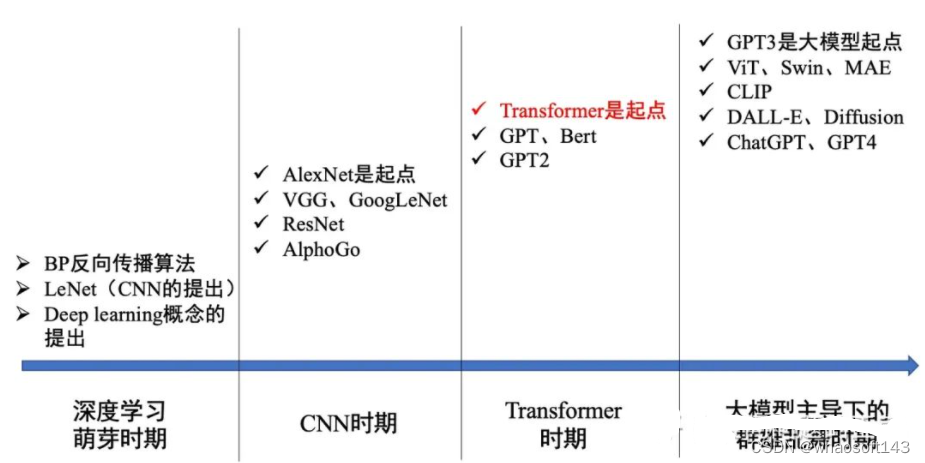
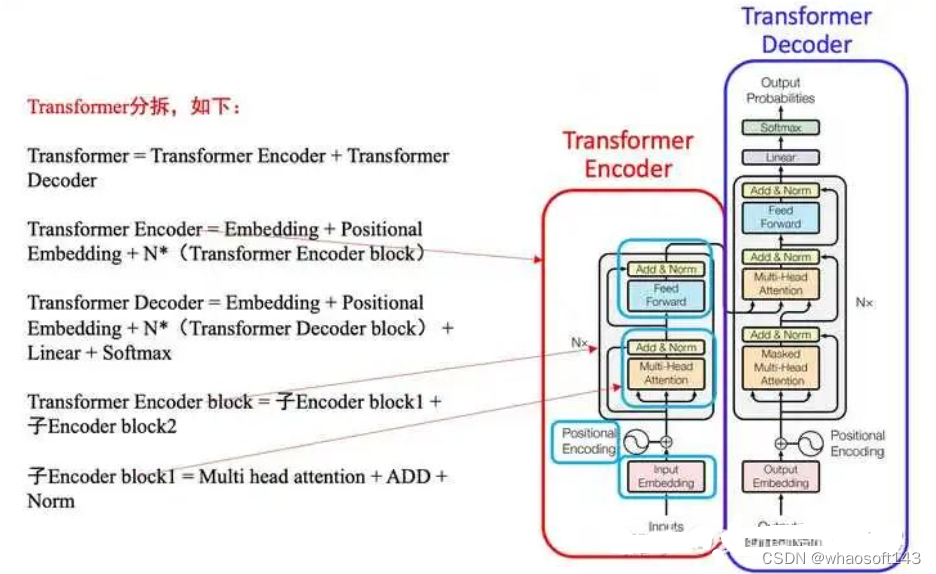
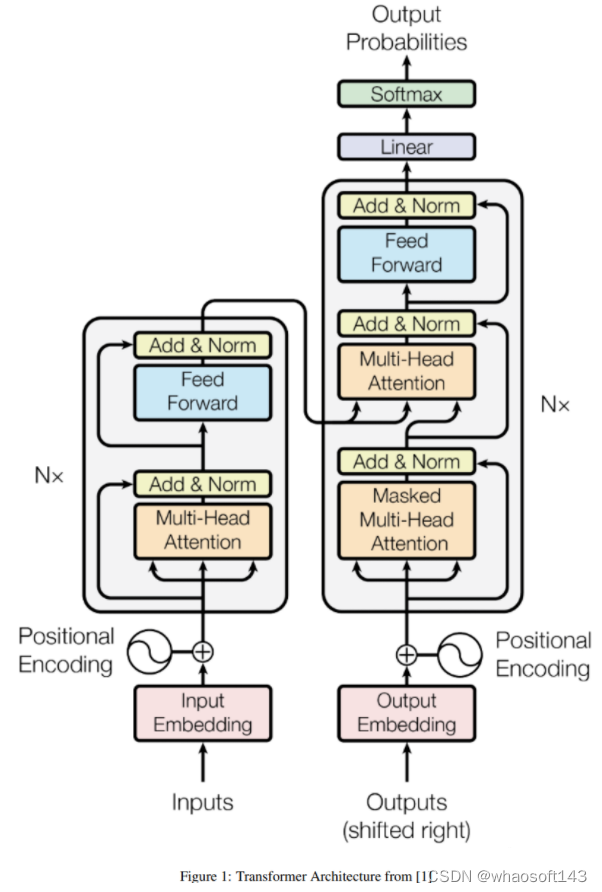
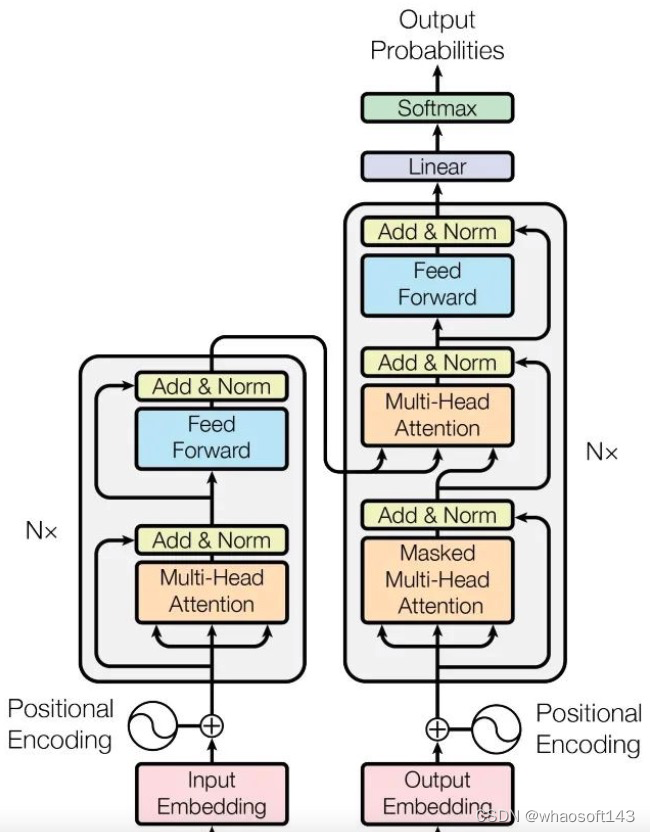
transformer布局是google在17年的Attention Is All You Need论文中提出,在NLP的多个任务上取得了非常好的效果,可以说如今NLP发展都离不开transformer。最大特点是抛弃了传统的CNN和RNN,整个网络布局完全是由Attention机制组成。由于其出色性能以及对卑鄙任务的友好性大概说卑鄙任务仅仅微调即可得到不错效果,在计算机视觉领域不停有人实验将transformer引入,近期也出现了一些效果不错的实验,典型的如目标检测领域的detr和可变形detr,分类领域的vision transformer等等。本文从transformer布局出发,结合视觉中的transformer成果(详细是vision transformer和detr)进行分析,希望能够帮助cv领域想相识transformer的初学者快速入门。由于本人接触transformer时间也不长,也算初学者,故如果有描述大概理解错误的地方欢迎指正。
transformer介绍
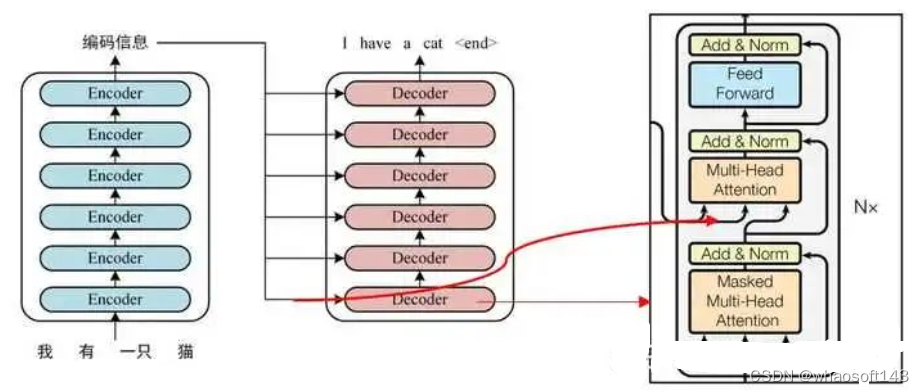
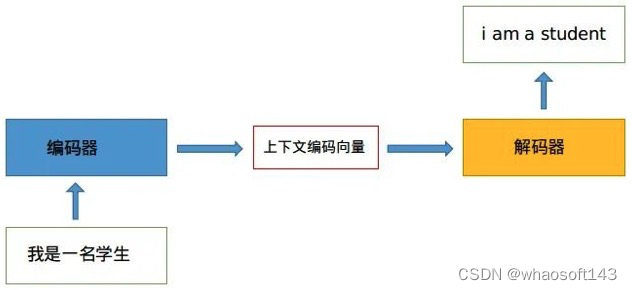
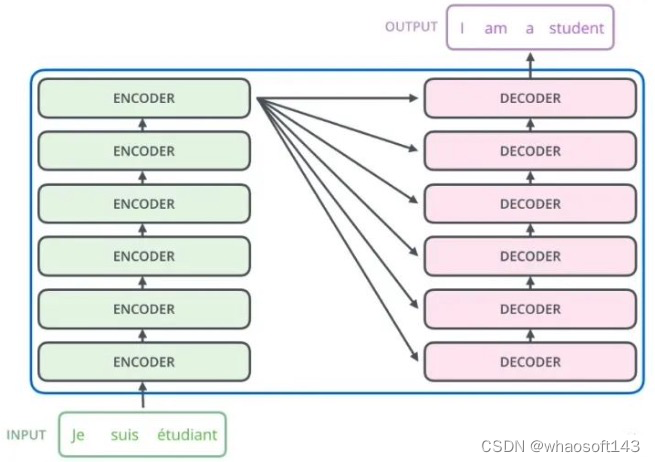
一般讲解transformer都会以机器翻译任务为例子讲解,机器翻译任务是指将一种语言转换得到另一种语言,例如英语翻译为中文任务。从最上层来看,如下所示:
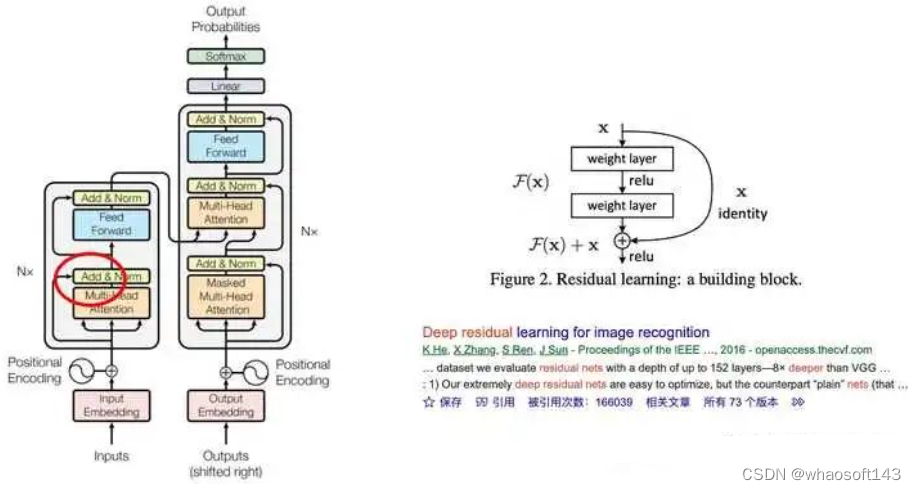
最大题目应该是无法并行训练,不利于大规模快速训练和部署,也不利于整个算法领域发展,故在Attention Is All You Need论文中抛弃了传统的CNN和RNN,将attention机制发挥到底,整个网络布局完全是由Attention机制组成,这是一个比较大的进步。
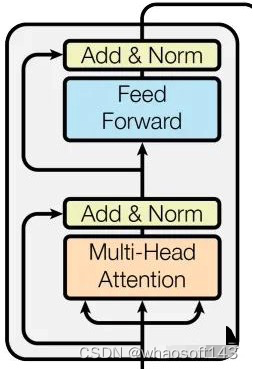
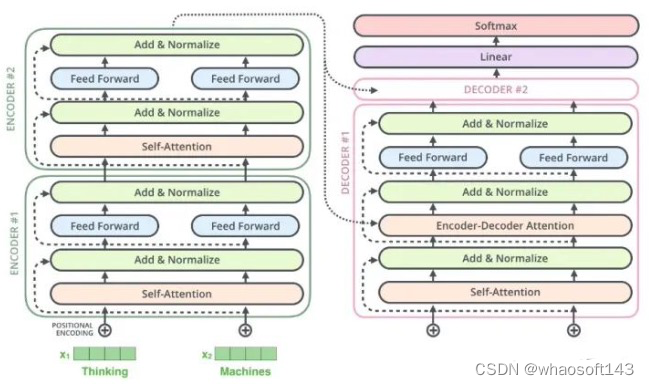
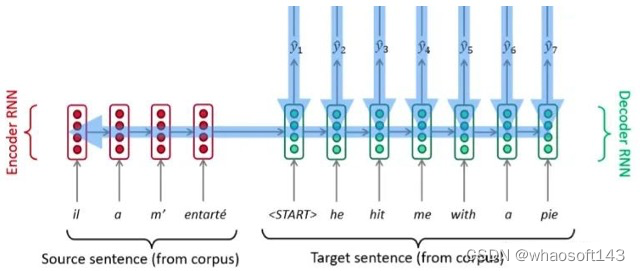
google所提基于transformer的seq2seq团体布局如下所示:
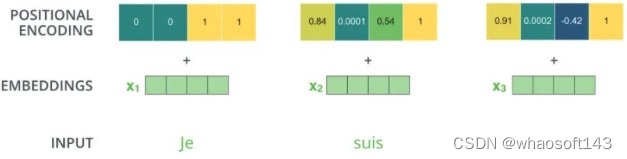
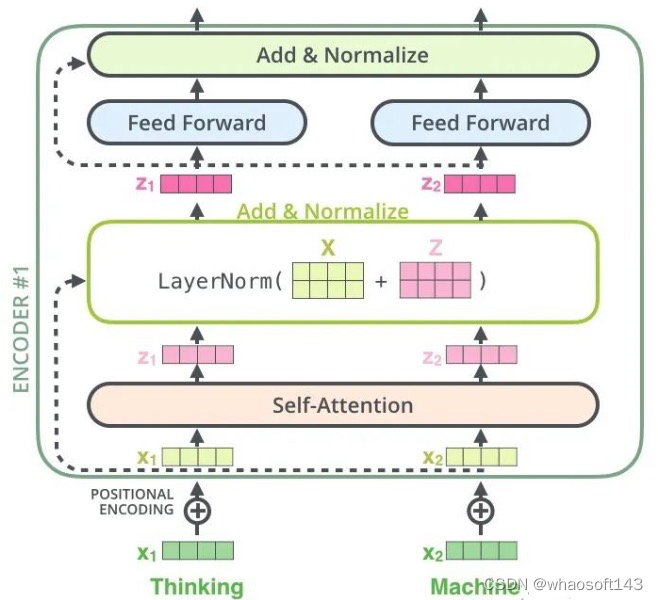
注意上图没有绘制出单词嵌入向量和位置编码向量相加过程,但是是存在的。 (1) 自注意力层
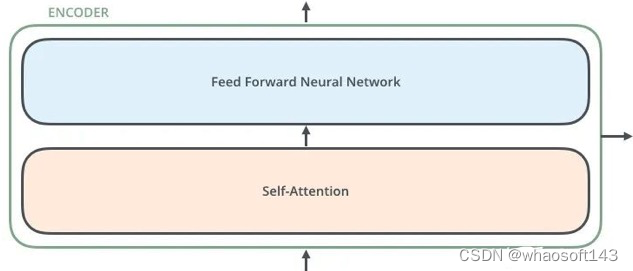
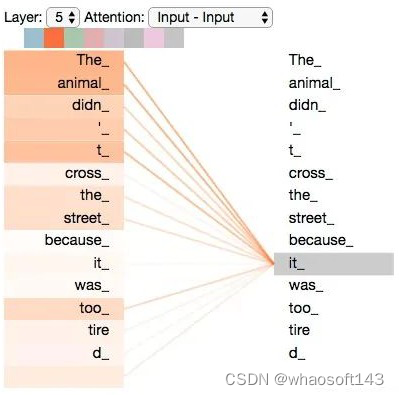
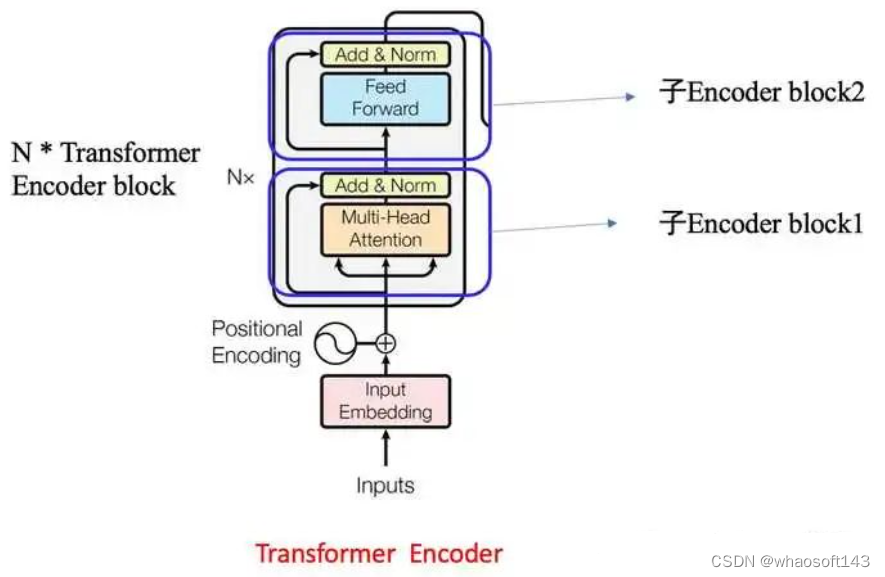
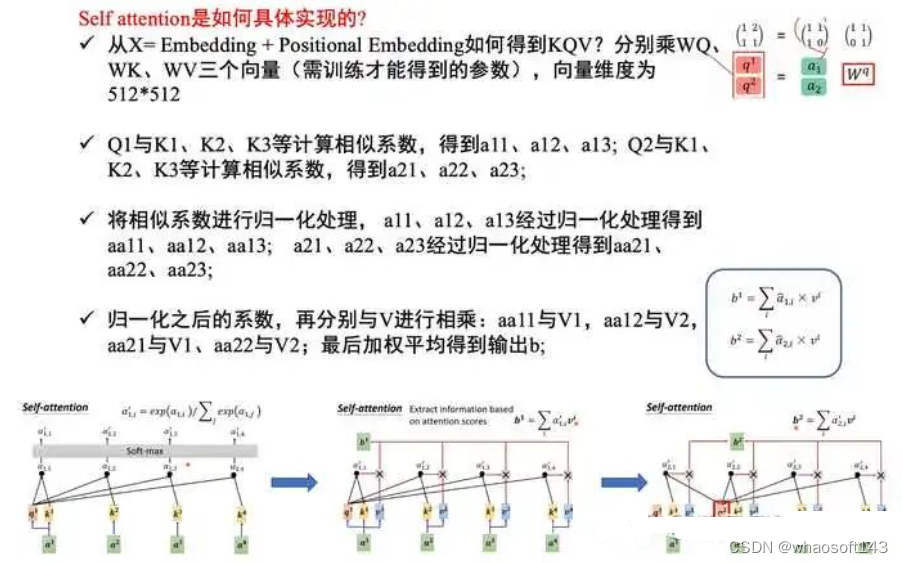
通过前面分析我们知道自注意力层实在就是attention操作,而且由于其QKV来自同一个输入,故称为自注意力层。我想各人应该能想到这里attention层作用,在参考资料1博客里面举了个简单例子来阐明attention的作用:假设我们想要翻译的输入句子为The animal didn't cross the street because it was too tired,这个“it”在这个句子是指什么呢?它指的是street还是这个animal呢?这对于人类来说是一个简单的题目,但是对于算法则不是。当模子处理这个单词“it”的时间,自注意力机制会允许“it”与“animal”建立联系即随着模子处理输入序列的每个单词,自注意力会关注整个输入序列的全部单词,帮助模子对本单词更好地进行编码。现实上训练完成后确实如此,google提供了可视化工具,如下所示:
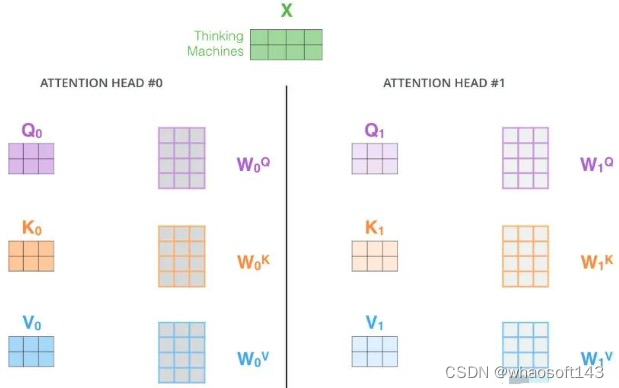
它扩展了模子专注于差别位置的能力。在上面的例子中,固然每个编码都在z1中有或多或少的表现,但是它大概被现实的单词自己所支配。如果我们翻译一个句子,比如“The animal didn’t cross the street because it was too tired”,我们会想知道“it”指的是哪个词,这时模子的“多头”注意机制会起到作用。
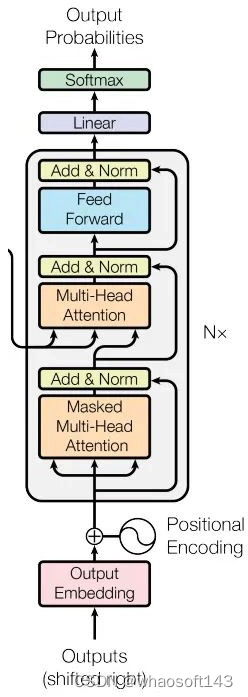
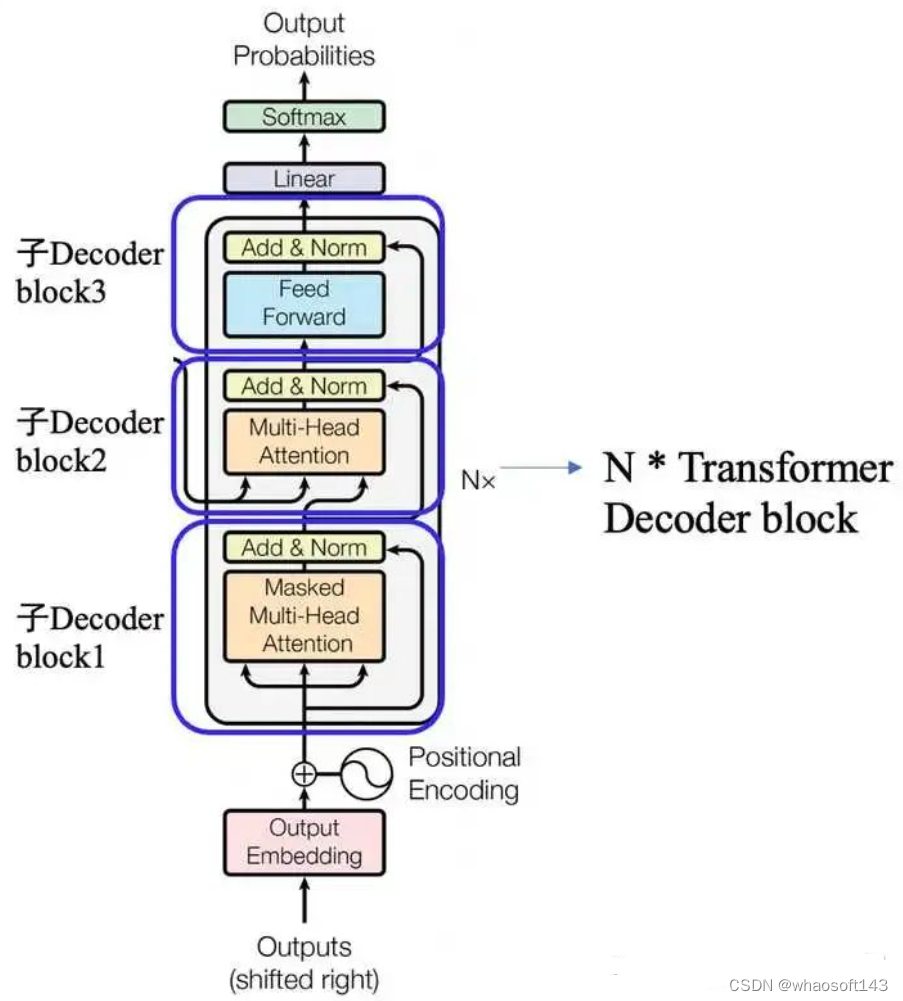
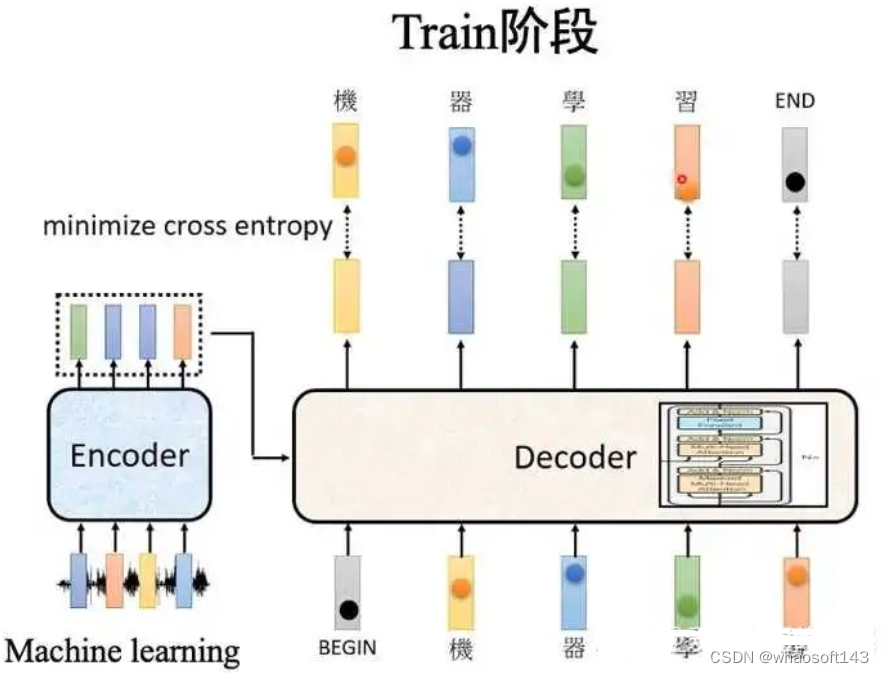
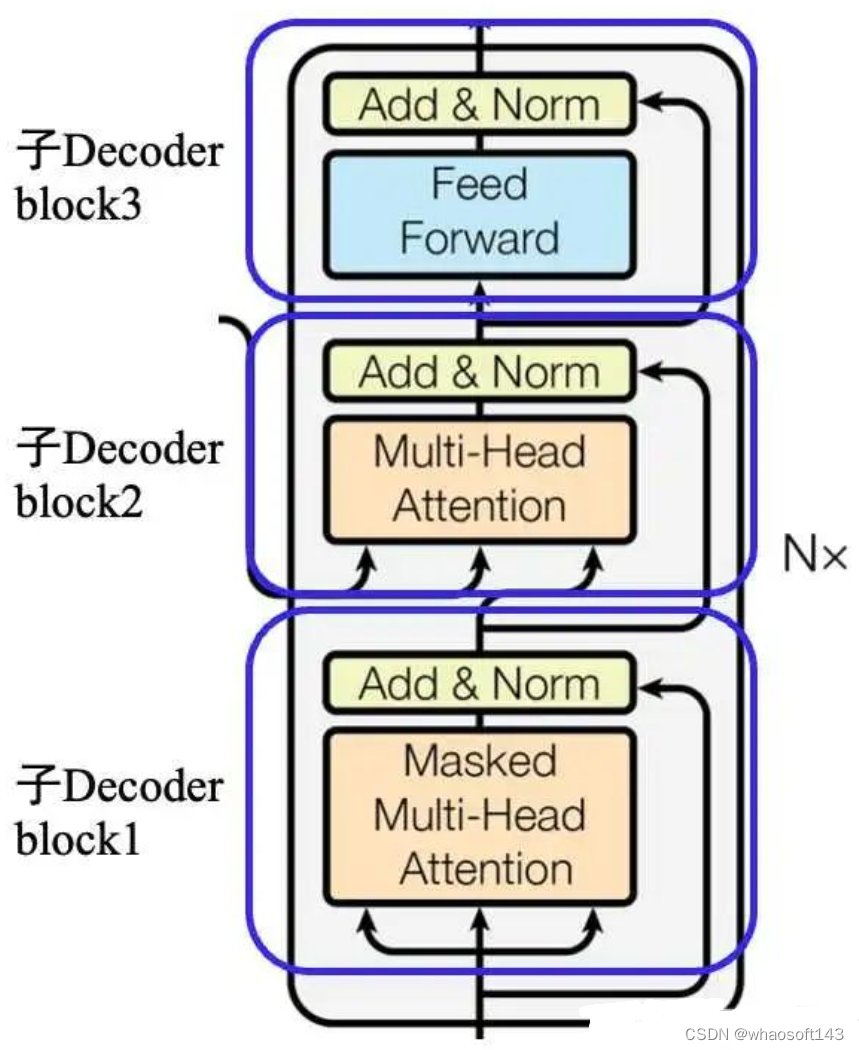
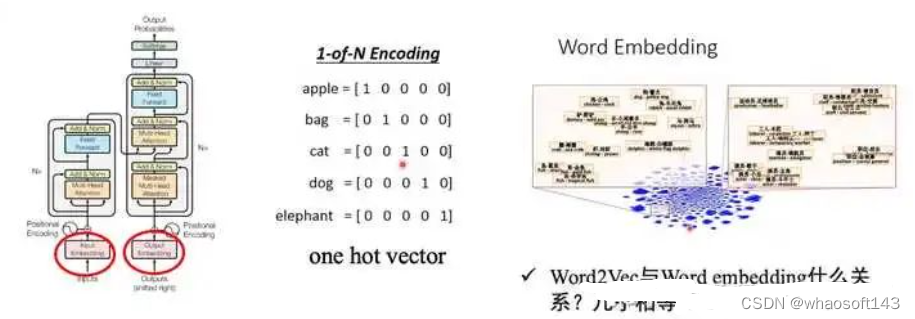
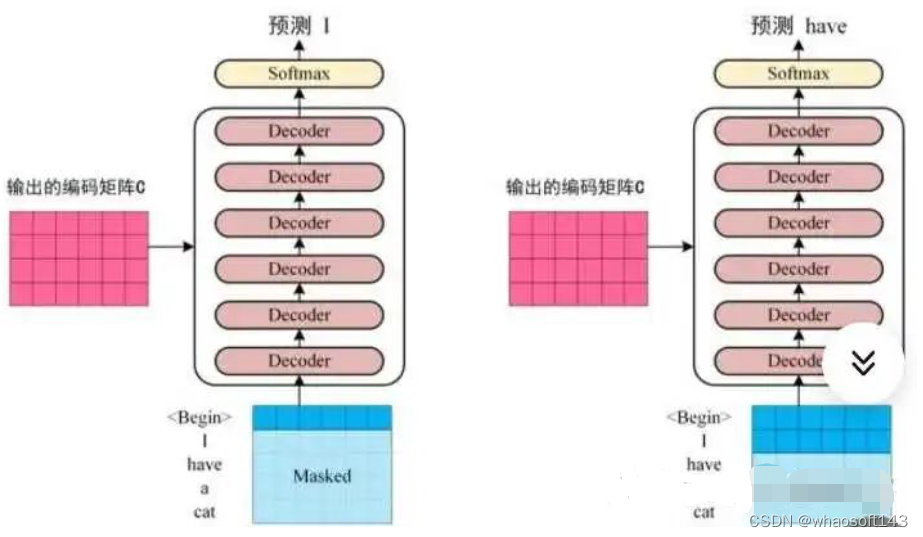
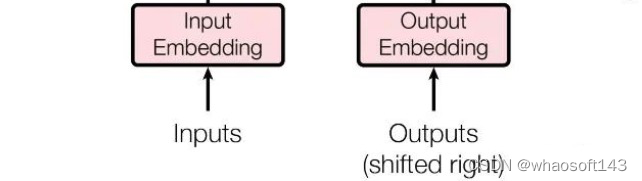
其输入数据处理也要区分第一个解码器和后续解码器,和编码器类似,第一个解码器输入不仅包罗末了一个编码器输出,还需要额外的输出嵌入向量,而后续解码器输入是来自末了一个编码器输出和前面解码器输出。 (1) 目标单词嵌入
这个操作和源单词嵌入过程完全雷同,维度也是512,假设输出是i am a student,那么需要对这4个单词也利用word2vec算法转化为4x512的矩阵,作为第一个解码器的单词嵌入输入。 (2) 位置编码
同样的也需要对解码器输入引入位置编码,做法和编码器部分完全雷同,且将目标单词嵌入向量和位置编码向量相加即可作为第一个解码器输入。
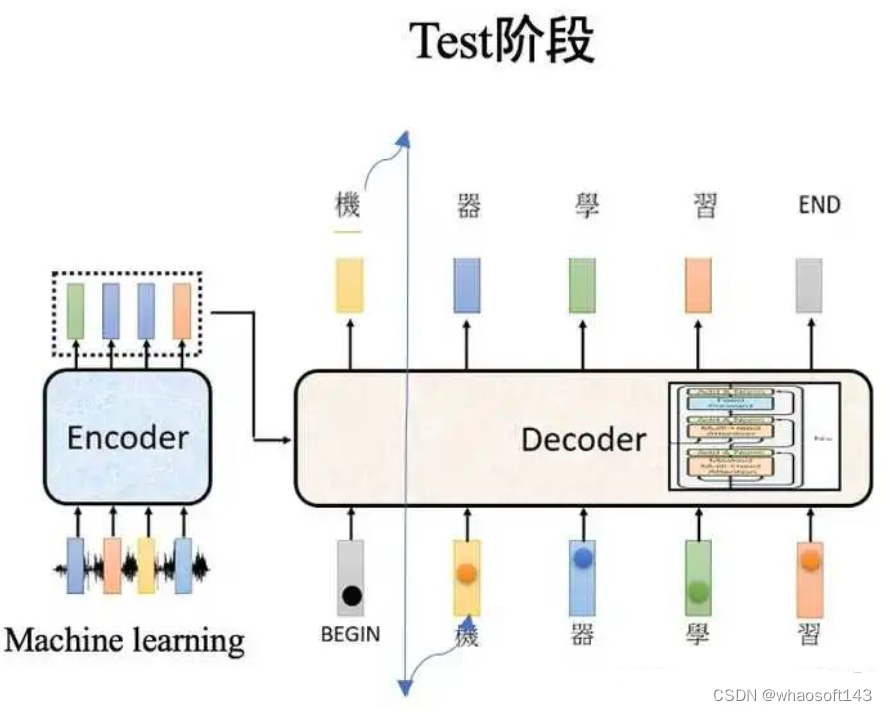
和编码器单词嵌入差别的地方是在进行目标单词嵌入前,还需要将目标单词即是i am a student右移动一位,新增长的一个位置接纳提前定义好的标记位BOS_WORD代替,如今就酿成[BOS_WORD,i,am,a,student],为啥要右移?因为解码过程和seq2seq一样是顺序解码的,需要提供一个开始解码标记,。否则第一个时间步的解码单词i是如何输出的呢?详细解码过程实在是:输入BOS_WORD,解码器输出i;输入前面已经解码的BOS_WORD和i,解码器输出am...,输入已经解码的BOS_WORD、i、am、a和student,解码器输出解码结束标记位EOS_WORD,每次解码都会利用前面已经解码输出的全部单词嵌入信息
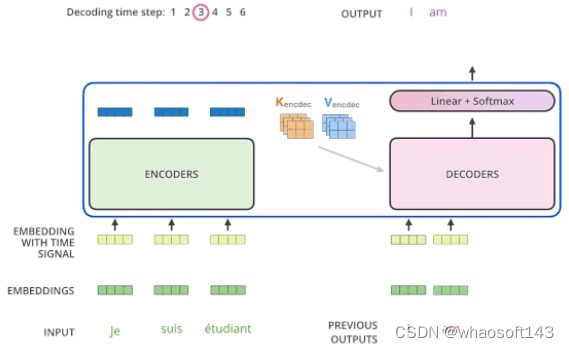
下面有个非常清晰的gif图,一目了然:
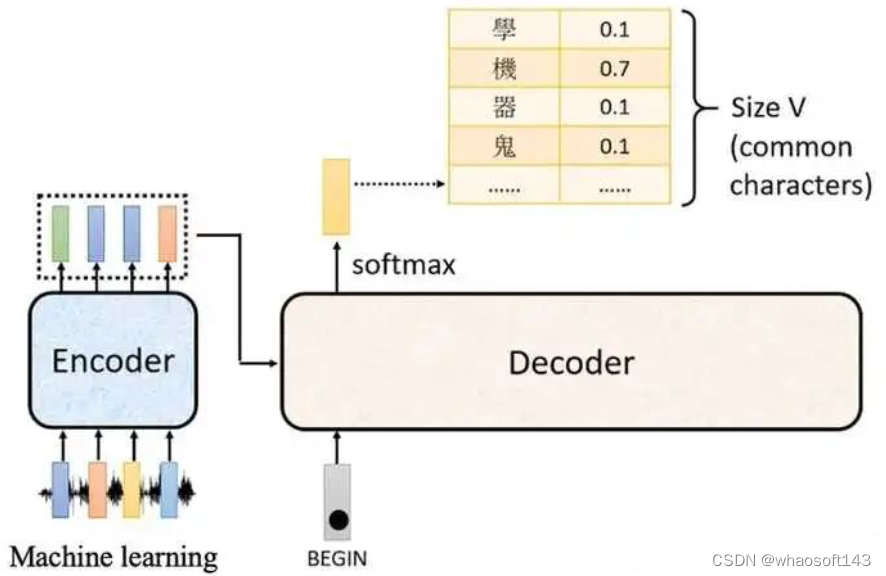
分类层
在进行编码器-解码器后输出依然是向量,需要在背面接fc+softmax层进行分类训练。假设当前训练过程是翻译任务需要输出i am a student EOS_WORD这5个单词。假设我们的模子是从训练会集学习一万个差别的英语单词(我们模子的“输出词表”)。因此softmax后输出为一万个单元格长度的向量,每个单元格对应某一个单词的分数,这实在就是普通多分类题目,只不过维度比较大而已。
依然从前面例子为例,假设编码器输出shape是(b,100,512),颠末fc后酿成(b,100,10000),然后对末了一个维度进行softmax操作,得到bx100个单词的概率分布,在训练过程中bx100个单词是知道label的,故可以直接接纳ce loss进行训练。
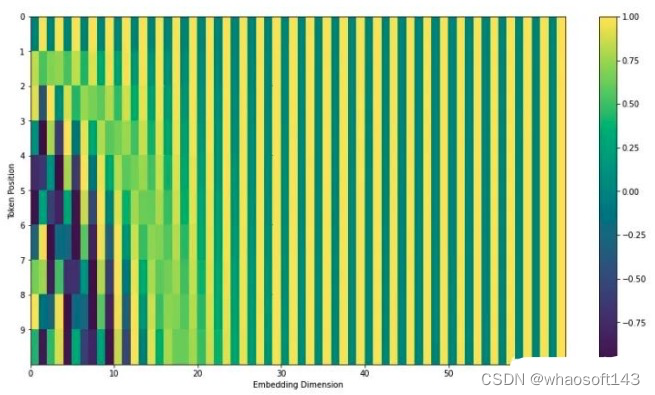
可以看出对于h//32,w//32的2d图像特性,不是类似vision transoformer做法简单的将其拉伸为h//32 x w//32,然后从0-n进行长度为256的位置编码,而是考虑了xy方向同时编码,每个方向各编码128维向量,这种编码方式更符合图像特定。
还有一个细节需要注意:原始transformer的n个编码器输入中,只有第一个编码器需要输入位置编码向量,但是detr里面对每个编码器都输入了同一个位置编码向量,论文中没有写为啥要如此修改。 b) QKV处理逻辑差别
作者设置编码器一共6个,而且位置编码向量仅仅加到QK中,V中没有到场位置信息,这个和原始做法不一样,原始做法是QKV都加上了位置编码,论文中也没有写为啥要如此修改。
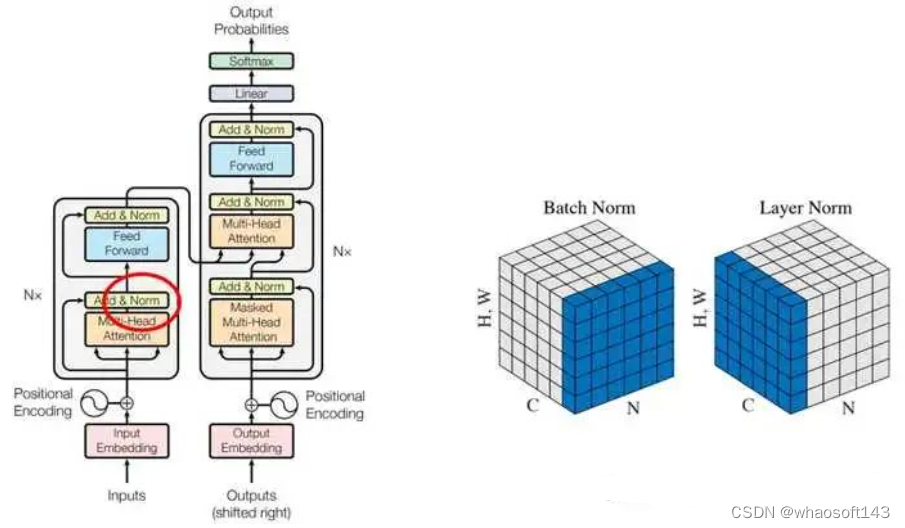
其余地方就完全雷同了,故代码就没须要贴了。总结下和原始transformer编码器差别的地方:
输入编码器的位置编码需要考虑2d空间位置
位置编码向量需要到场到每个编码器中
在编码器内部位置编码仅仅和QK相加,V不做任那边理
颠末6个编码器forward后,输出shape为(h//32xw//32,b,256)。 c) 编码器部分团体运行流程
6个编码器团体forward流程如下:
作者对比了差别类型的位置编码效果,因为query_embed(output pos)是必不可少的,所以该列没有进行对比实验,始终都有,末了一行效果最好,所以作者接纳的就是该方案,sine at attn表现每个注意力层都到场了sine位置编码,相比仅仅在input增长位置编码效果更好。 (3) 注意力可视化
前面说过transformer具有很好的可表明性,故在训练完成后终极提出了几种可视化形式 a) bbox输出可视化
图21 scaled操作在attention中的位置
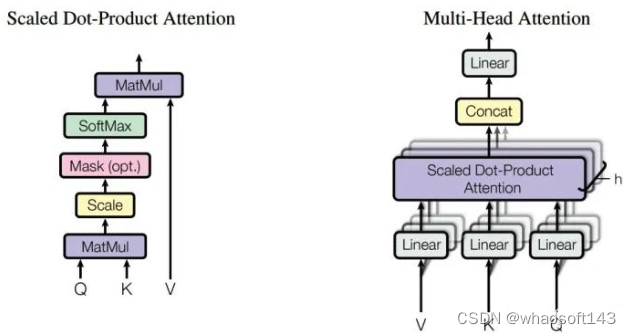
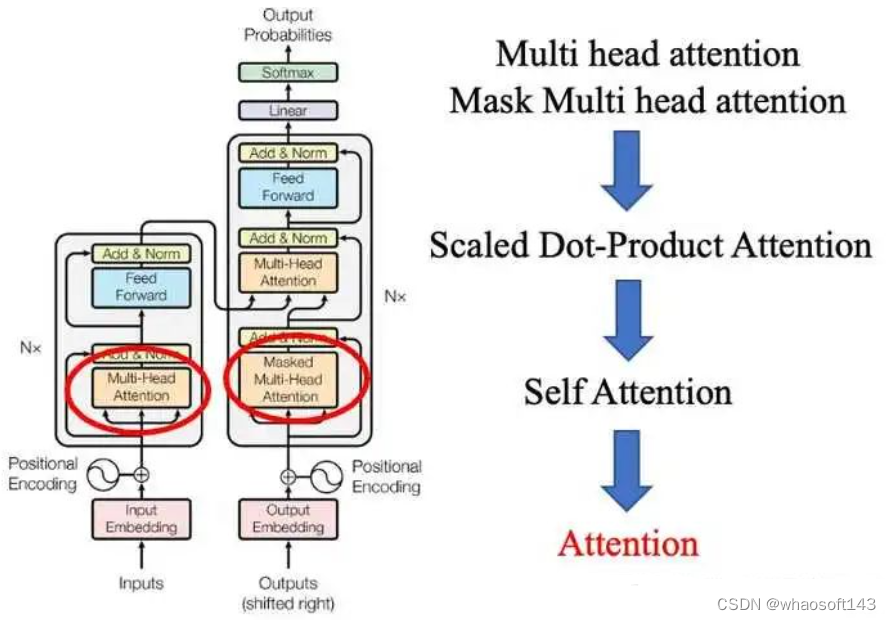
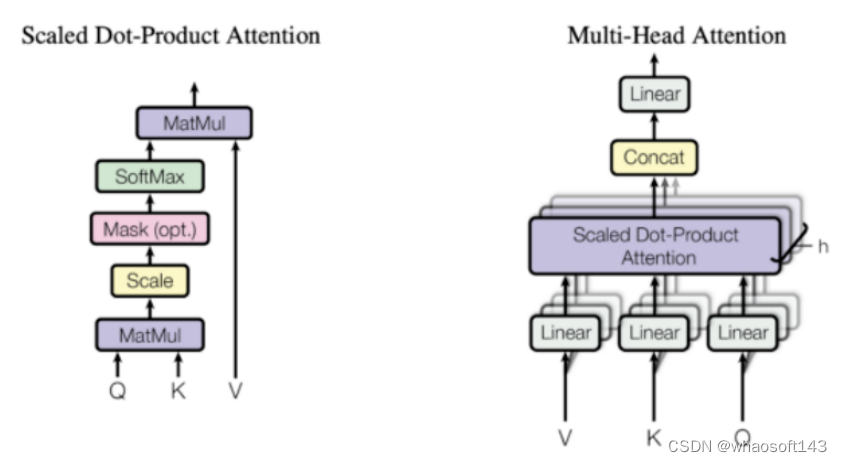
12. 什么是Multi head attention?
12.1 Multi head attention在Transformer架构中的位置如图15所示。
12.2 提出背景:CNN具有多个channel,可以提取图像差别维度的特性信息,那么Self attention是否可以有类似操作,可以提取差别隔断token的多个维度信息呢?
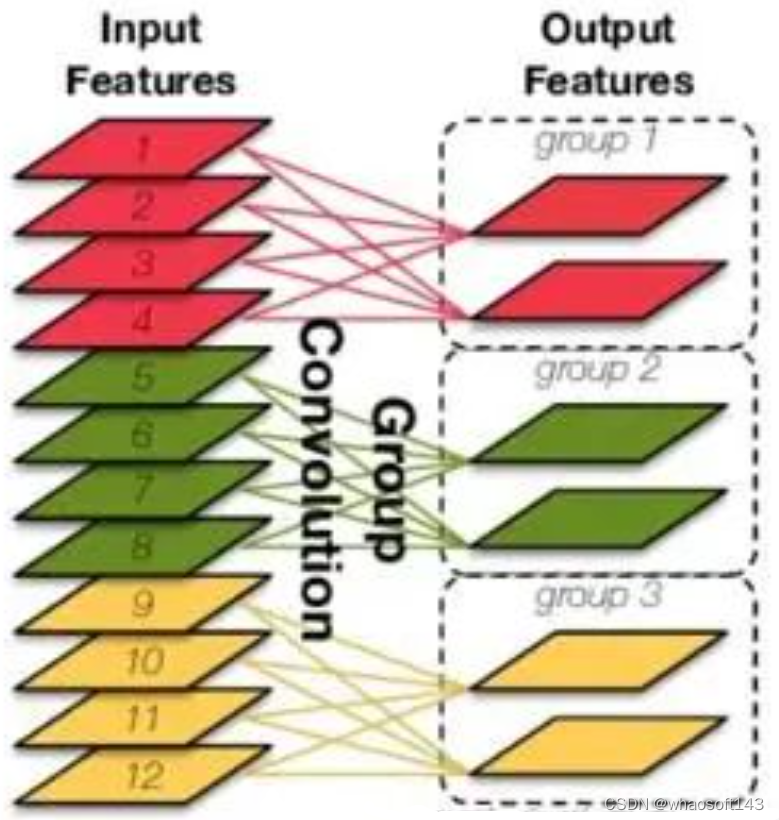
12.3 什么是group 卷积?如图22所示,将输入的特性多个channel分成几个group单独做卷积,末了再进行con c操作。
图22 group卷积
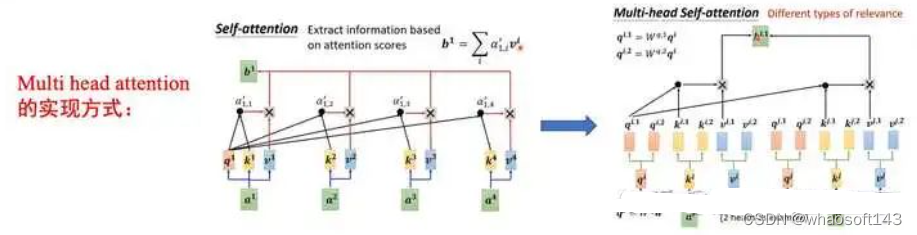
12.4 Multi head attention的实现方式?与self attention根本差别是什么?
如图23所示,以2个head的为例,将输入的Q、K、V分成两份,每一小份的Q与对应的K、V分别操作,末了计算得到的向量再进行conc操作,由此可以看出,Multi head attention与group卷积有着相似的实现方式。
图23 Multi head attention与self attention的区别
12.5 如何从输入输出维度,角度来理解Multi head attention?如图24所示。
图24 Multi head attention的输入输出维度
13. 什么是Mask Multi head attention?
13.1 Mask Multi head attention在transformer架构中的位置如图15所示。
13.2 为什么要有Mask这种操作?
Transformer预测第T个时刻的输出,不能看到T时刻之后的那些输入,从而保证训练和预测同等。
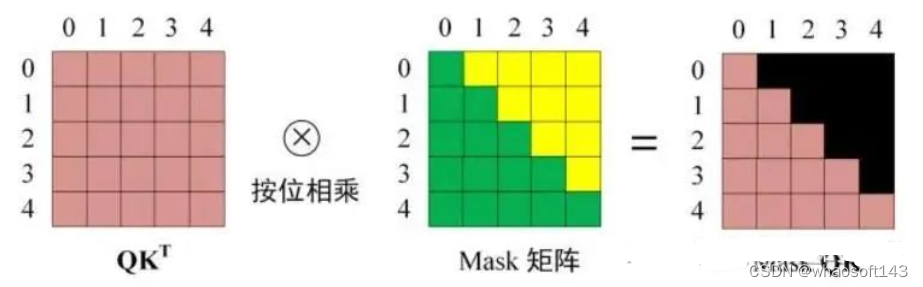
通过 Masked 操作可以防止第 i 个单词知道 i+1 个单词之后的信息,如图25所示。
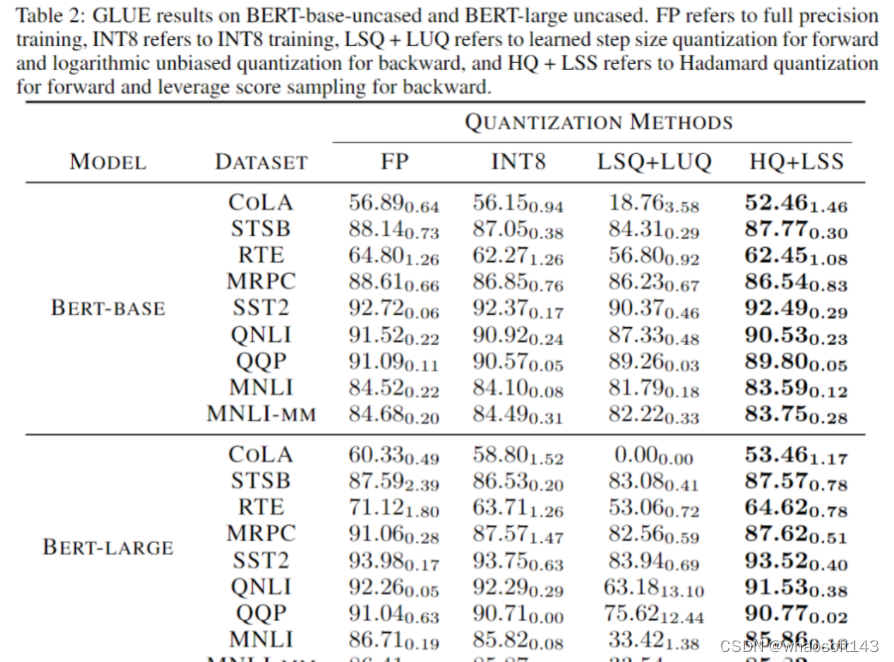
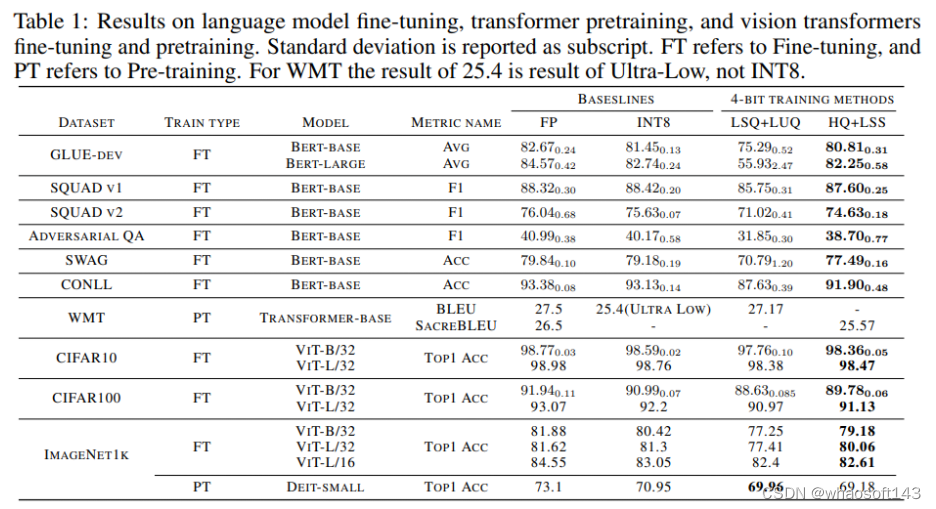
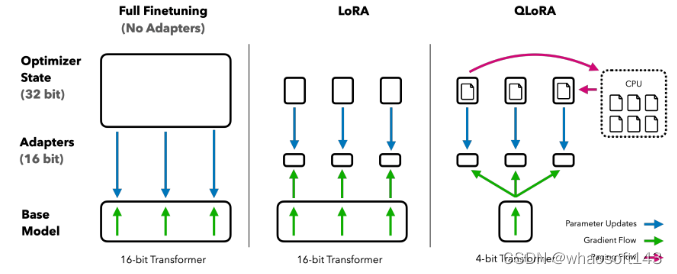
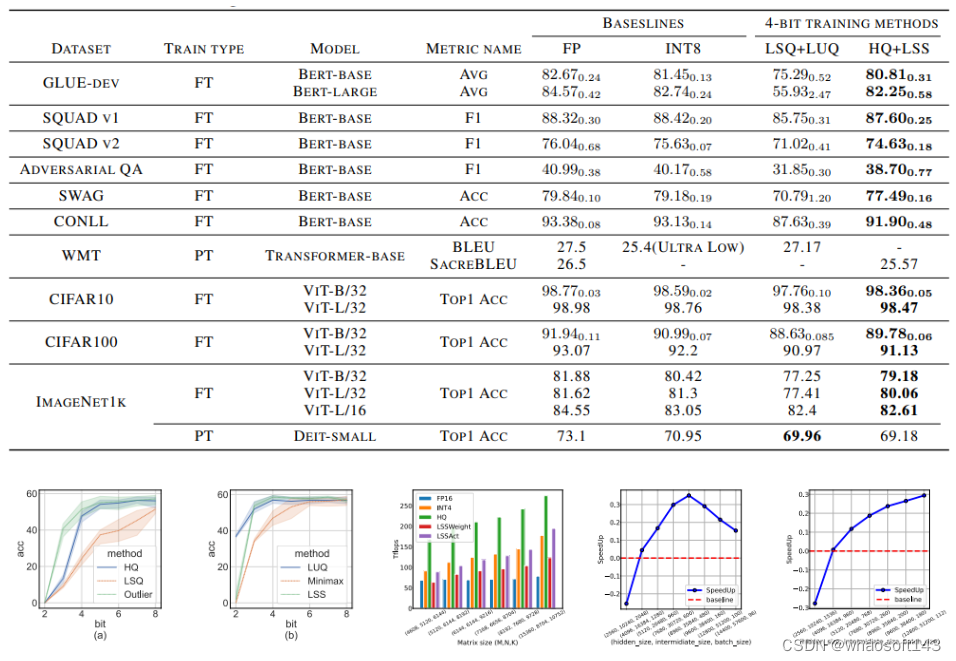
【QLoRA自己讲的是模子自己用4bit加载,训练时把数值反量化到bf16后进行训练,利用LoRA[2]可以锁定原模子参数不到场训练,只训练少量LoRA参数的特性使得训练所需的显存大大减少。例如33B的LLaMA模子颠末这种方式可以在24 GB的显卡上训练,也就是说单卡4090、3090都可以实现,大大低落了微调的门槛】QLORA: Efficient Finetuning of Quantized LLMs
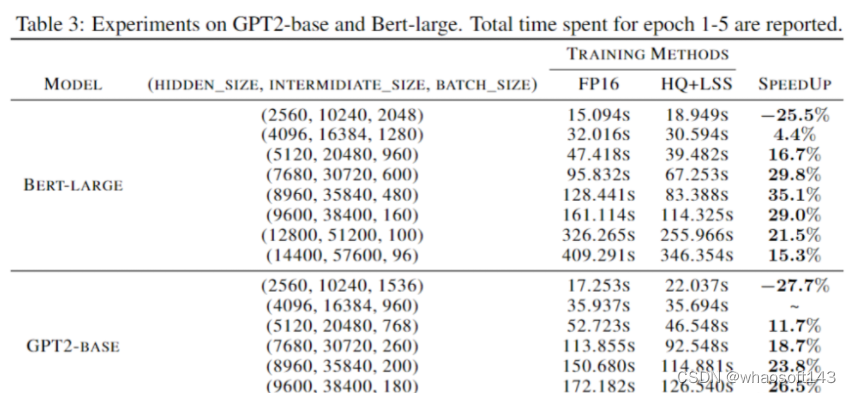
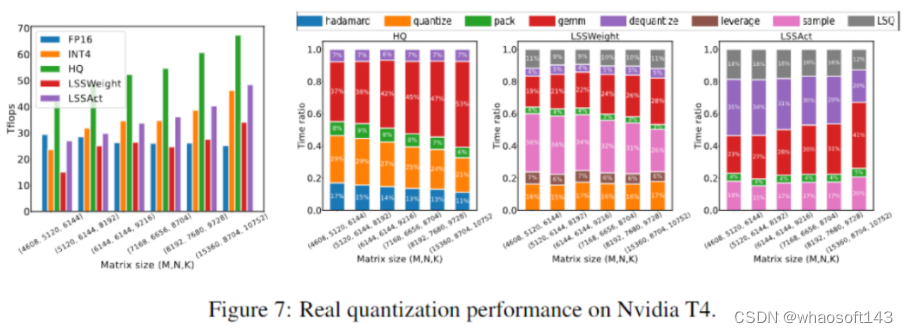
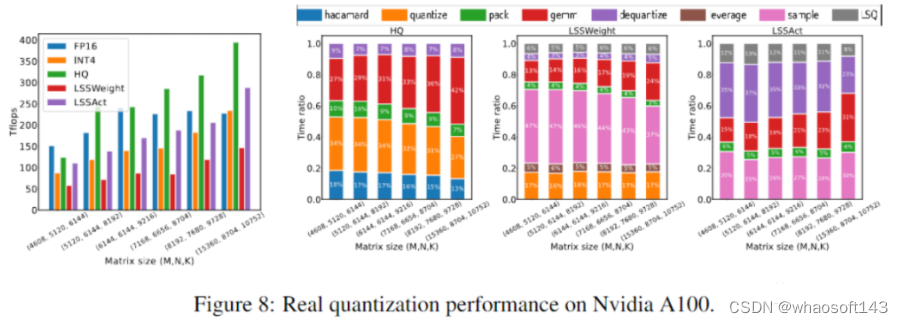
与从前的4-bit训练方法差别,我们的算法可以在当前一代的GPU上实现。我们的原型线性算子实现速率是FP16的2.2倍,训练速率提高了35.1%。
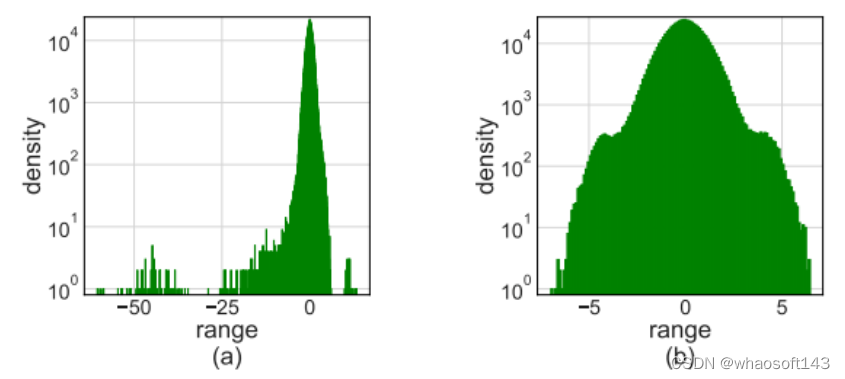
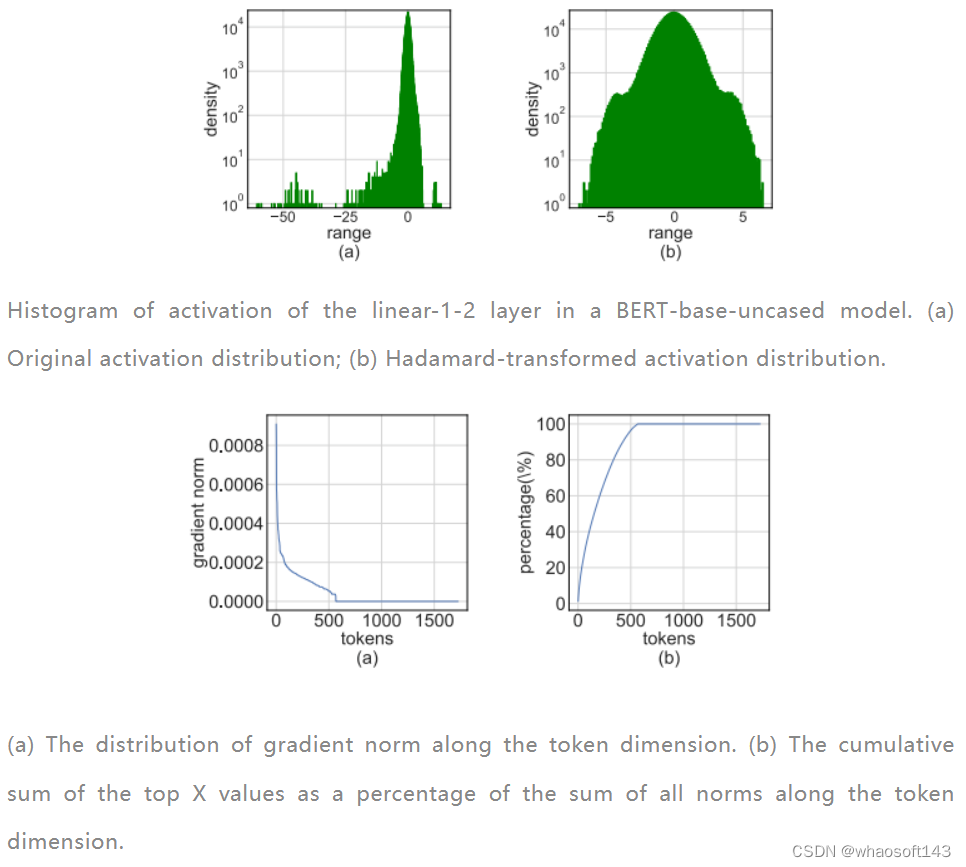
训练神经网络在计算上要求很高。低精度算术训练(也称为全量化训练或FQT)有望提高计算和记忆服从。FQT方法在原来的全精度计算图中添加了一些量化器和反量化器,并用便宜的低精度运算取代了昂贵的浮点运算。FQT的研究旨在低落训练的数值精度,而不捐躯太多的收敛速率或精度。所需的数值精度已从FP16低落到FP8、INT32+INT8和INT8+INT5。FP8训练是在英伟达的H100 GPU和变压器引擎中实现的,为大型变压器的训练实现了令人印象深刻的加速。
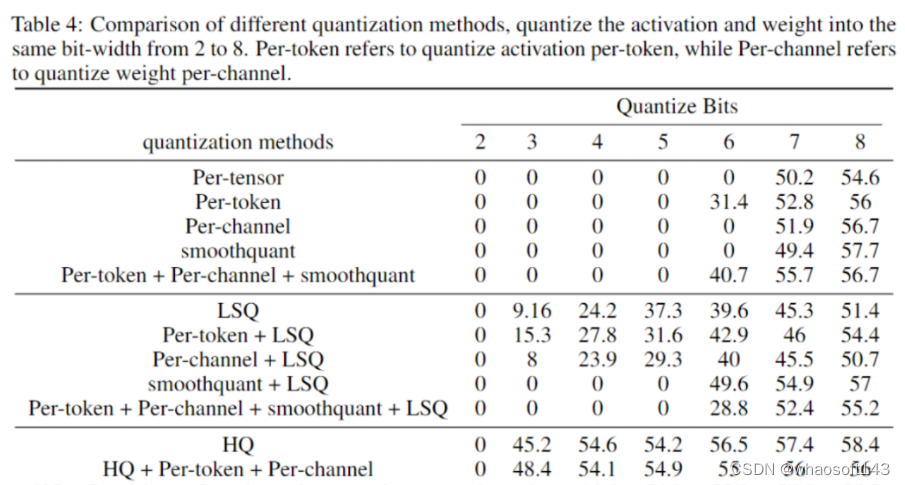
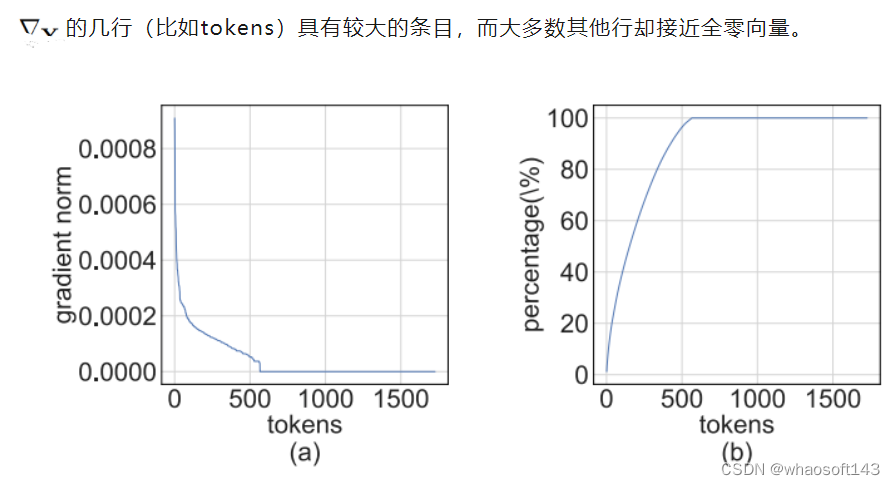
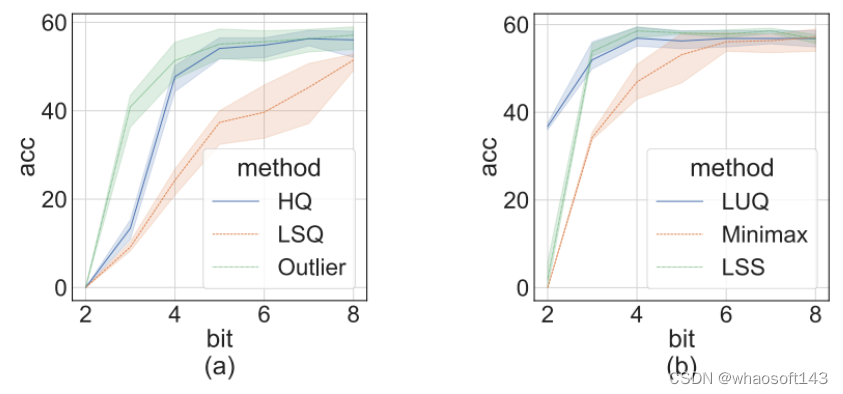
最近,训练数值精度已被低落到4位。Sun等人成功地用INT4激活/权重和FP4梯度训练了几个当代网络;和Chmiel等人提出了一种自定义的4位对数数字格式,以进一步提高精度。然而,这些4位训练方法不能直接用于加速,因为它们需要当代硬件不支持的自定义数字格式。在极低的4位程度上训练神经网络存在重大的优化挑衅。首先,前向传播中的不可微量化器使丧失景观变得坎坷不平,其中基于梯度的优化器很容易陷入局部最优。其次,梯度仅以低精度近似计算。这种不精确的梯度减缓了训练过程,甚至导致训练不稳固或偏离。 Fully Quantized Training
全量化训练(FQT)方法通过将激活、权重和梯度量化到低精度来加速训练,因此训练过程中的线性和非线性算子可以用低精度算法实现。FQT的研究计划了新的数值格式和量化算法,可以更好地逼近全精度张量。如今的研究前沿是4位FQT。由于梯度的巨大数值范围和从头开始训练量化网络的优化题目,FQT具有挑衅性。由于这些挑衅,现有的4位FQT算法在某些任务上的精度仍有1-2.5%的下降,而且它们无法支持当代硬件。 Other Efficient Training Methods
Mixture-of-experts【Outrageously large neural networks: The sparsely-gated mixture-of-experts layer】在不增长训练预算的情况下提高了模子的能力。布局丢弃利用计算上有效的方法来正则化模子。有效的注意力减少了计算注意力的二次时间复杂度。分布式训练体系通过利用更多的计算资源来减少训练时间。我们低落数值精度的工作与这些方向正交。 新框架
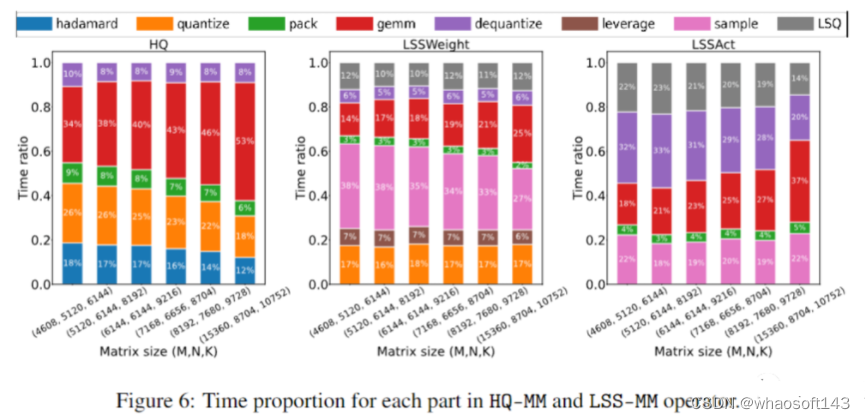
神经网络训练是一种迭代优化过程,通过前向和后向传播计算随机梯度。我们利用4位整数(INT4)算法加速正向和反向传播。首先描述我们的训练程序的正向传播。前向传播可以公式化为线性和非线性(GeLU、归一化、softmax等)算子的组合。在我们的训练过程中,我们利用INT4算法加速全部线性算子,并将全部计算麋集度较低的非线性算子保存为16位浮点(FP16)格式。变压器中的全部线性运算都可以写成矩阵乘法(MM)形式。
文章作者Xavier (Xavi) Amatriain于2005年博士毕业于西班牙庞培法布拉大学,如今是LinkedIn工程部副总裁,重要负责产品人工智能战略。
什么是Transformer?
Transformer是一类深度学习模子,具有一些独特的架构特性,最早出如今谷歌研究职员于2017年发表的著名的「Attention is All you Need」论文中,该论文在短短5年内积累了惊人的38000次引用。
Transformer架构也属于编码器-解码器模子(encoder-decoder),只不过在此之前的模子,注意力只是其中的机制之一,大多都是基于LSTM(黑白时记忆)和其他RNN(循环神经网络)的变体。
提出Transformer的这篇论文的一个关键见解如标题所说,注意力机制可以作为推导输入和输出之间依靠关系的唯一机制,这篇论文并不打算深入研究Transformer架构的全部细节,感兴趣的朋侪可以搜刮「The Illustrated Transformer」博客。


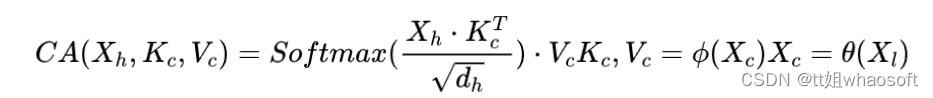


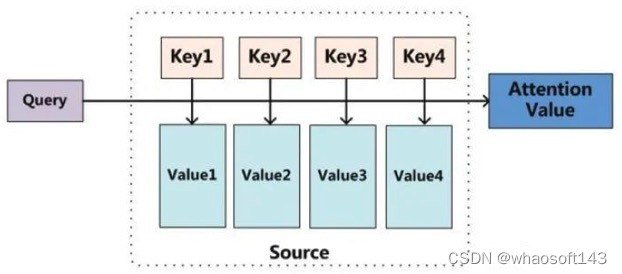
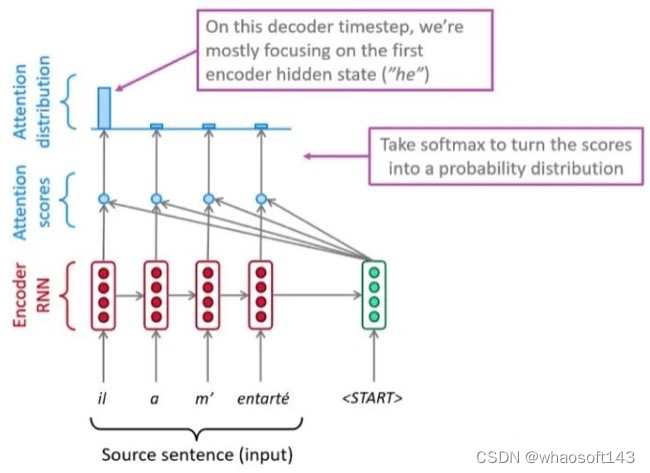
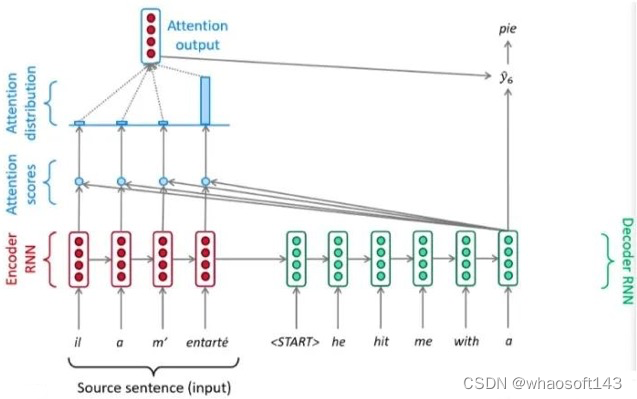
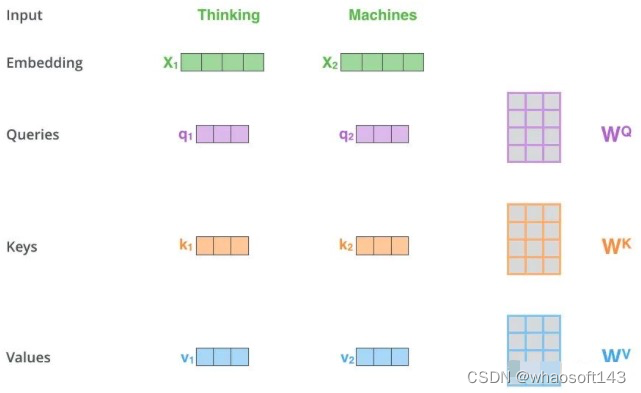
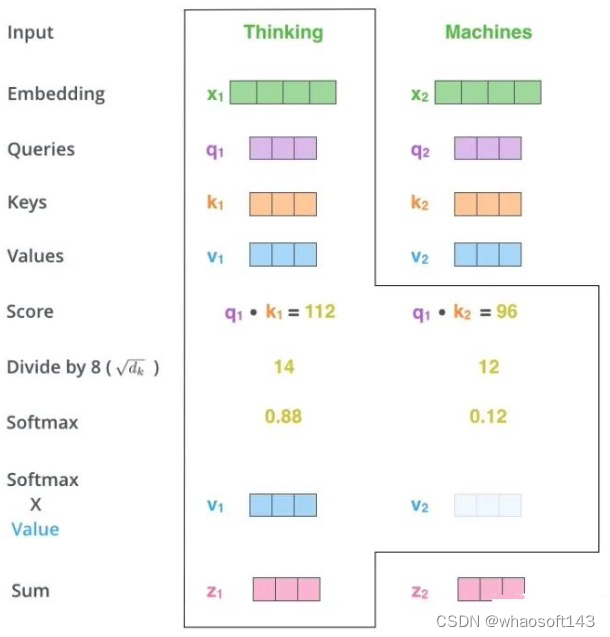
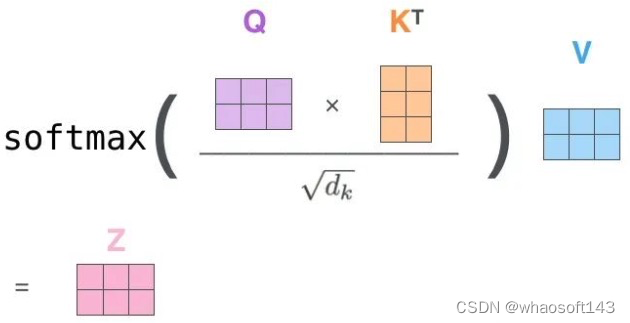
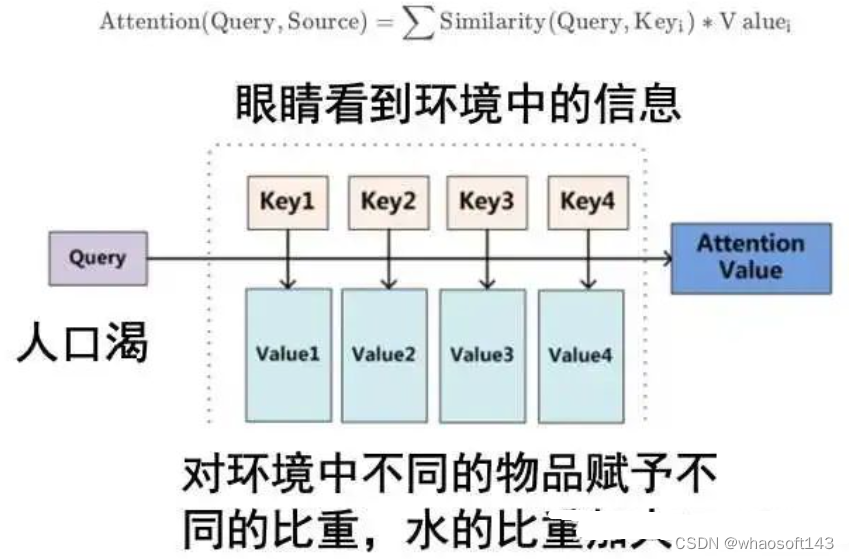
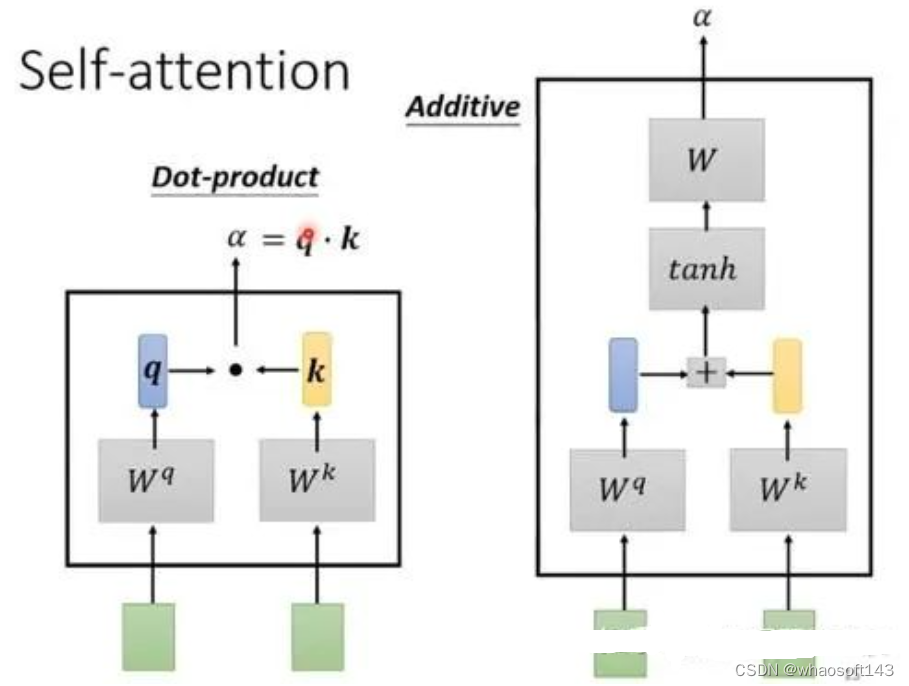
 和全部K计算相似性;对相似性接纳softmax转化为概率分布;将概率分布和V进行一一对应相乘,末了相加得到新的和Q一样长的向量输出即可,重点是下面要讲的transformer布局。
和全部K计算相似性;对相似性接纳softmax转化为概率分布;将概率分布和V进行一一对应相乘,末了相加得到新的和Q一样长的向量输出即可,重点是下面要讲的transformer布局。