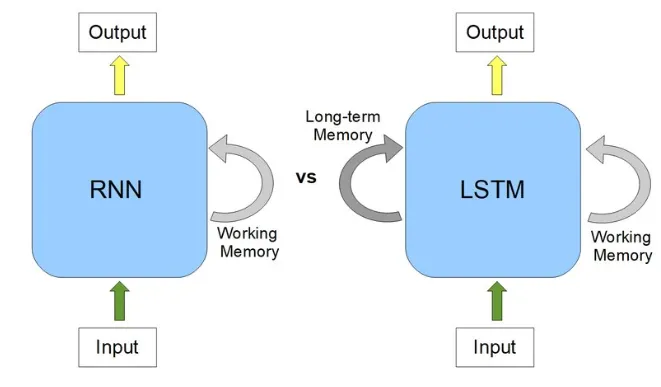
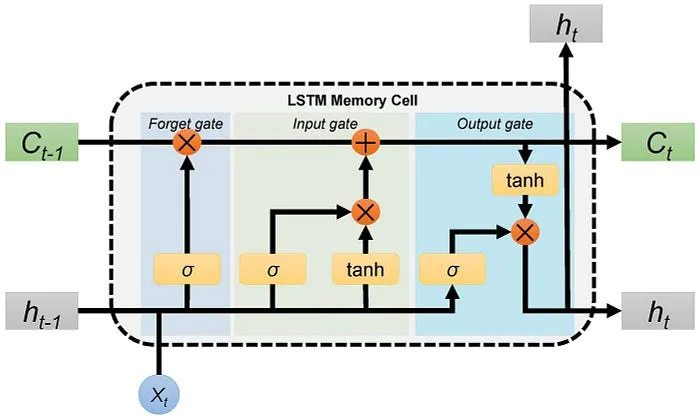
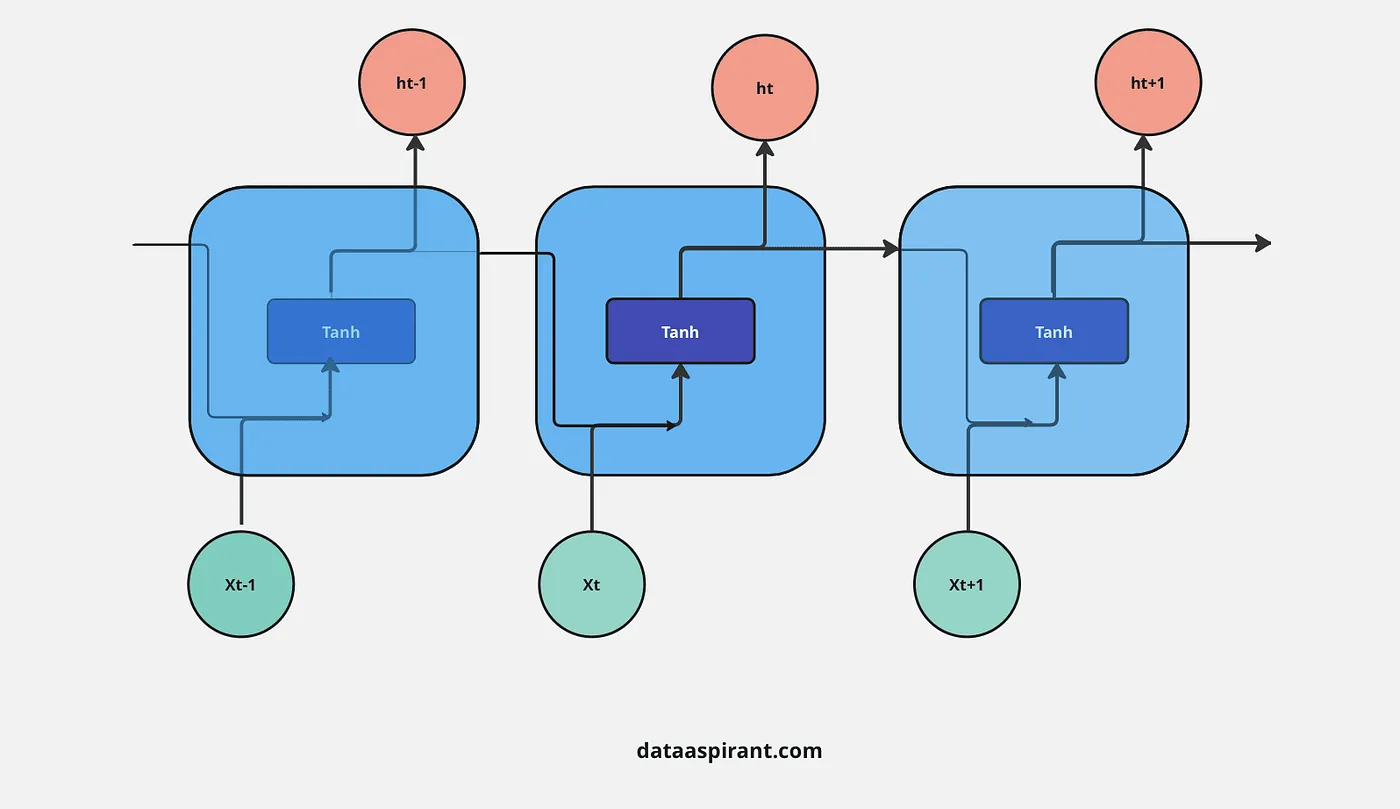
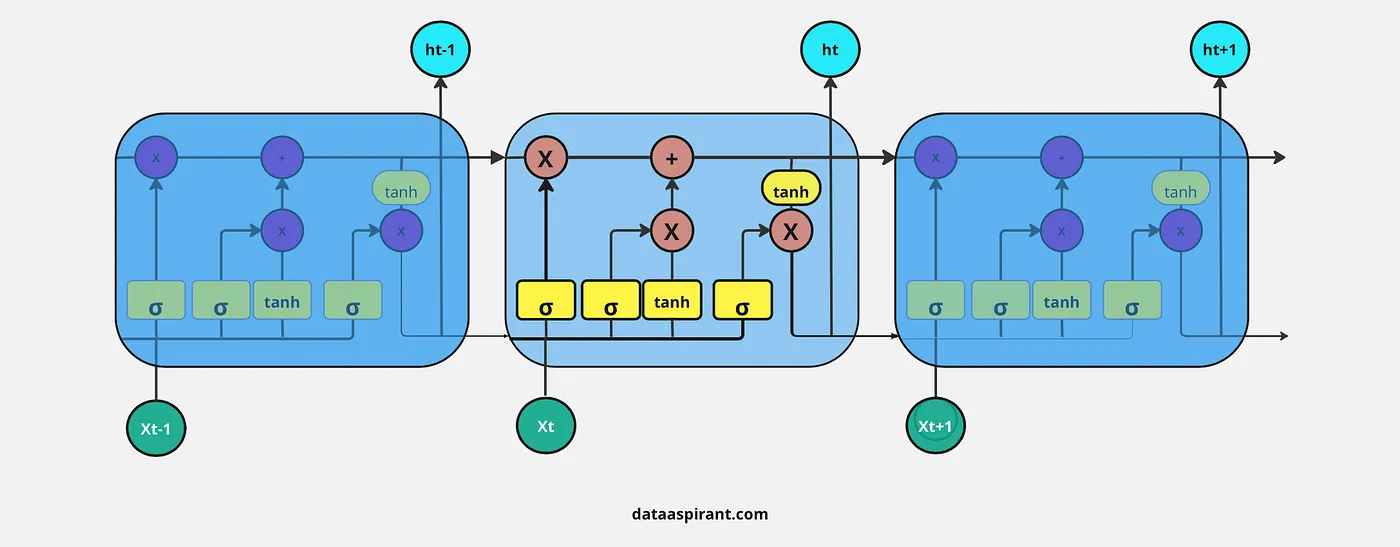
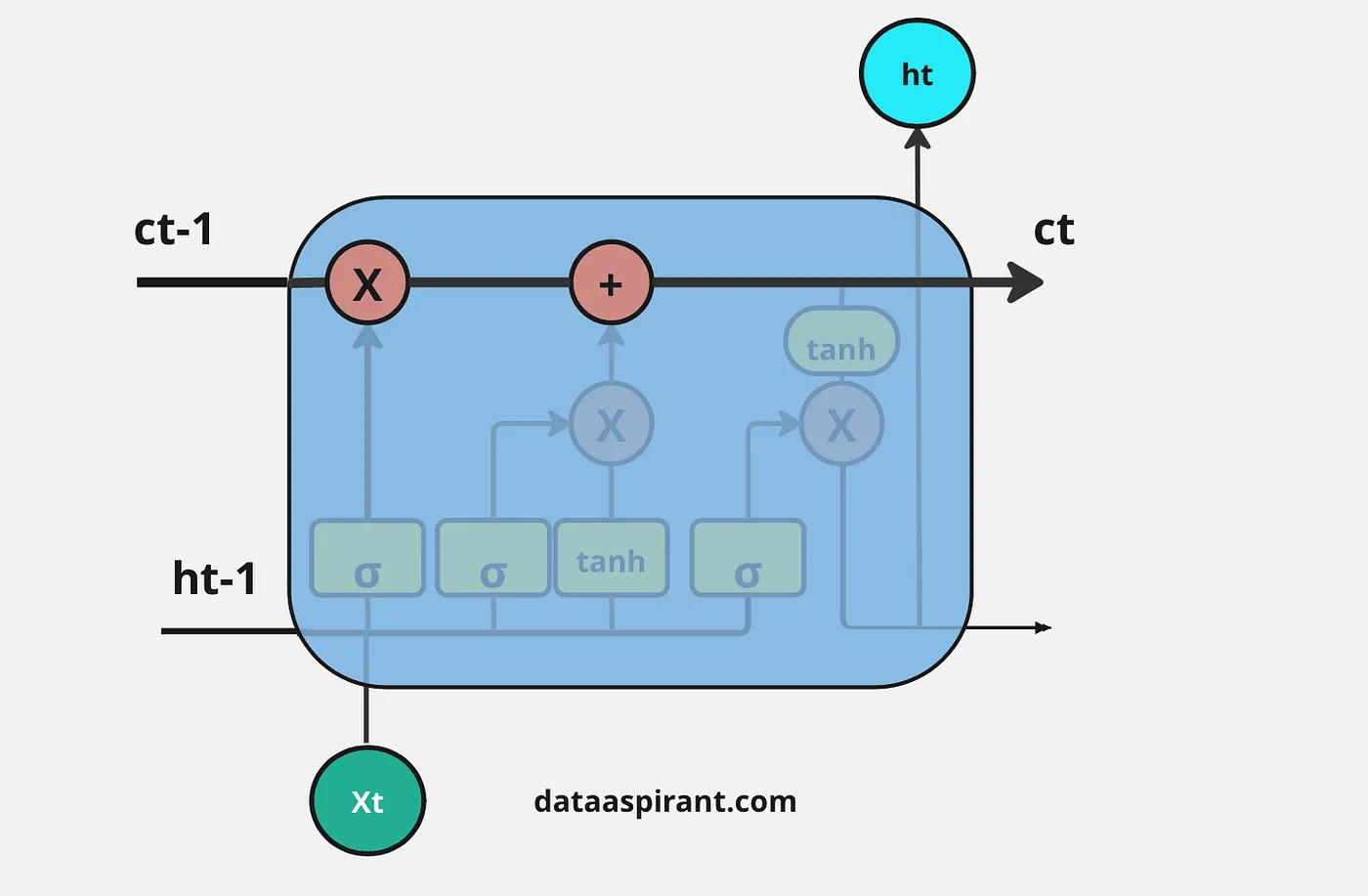
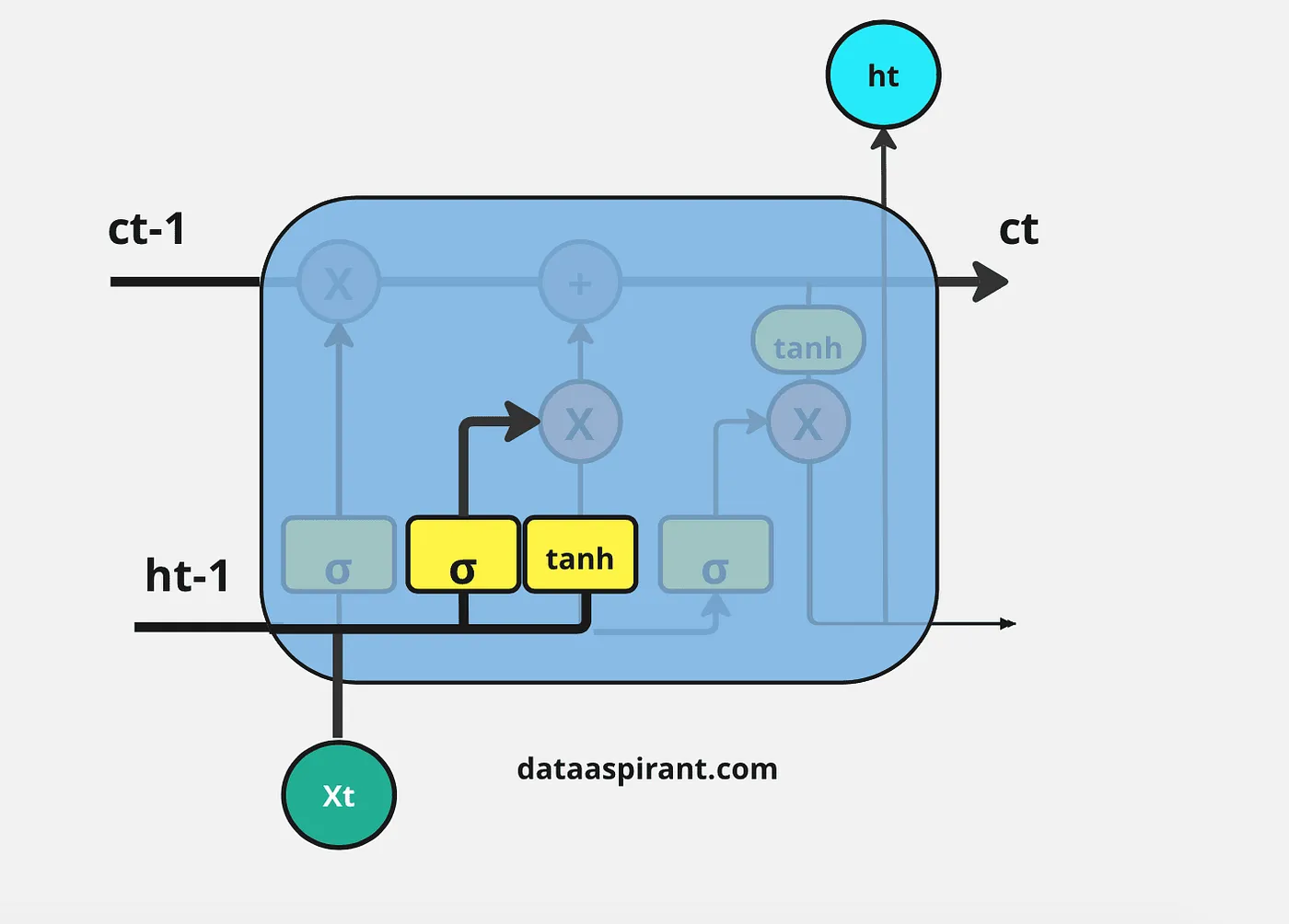
LSTM架构中的首要步调是决定哪些信息是重要的,哪些信息必要从上一个细胞状态中抛弃。在LSTM中实行这一过程的第一个门是“忘记门”。
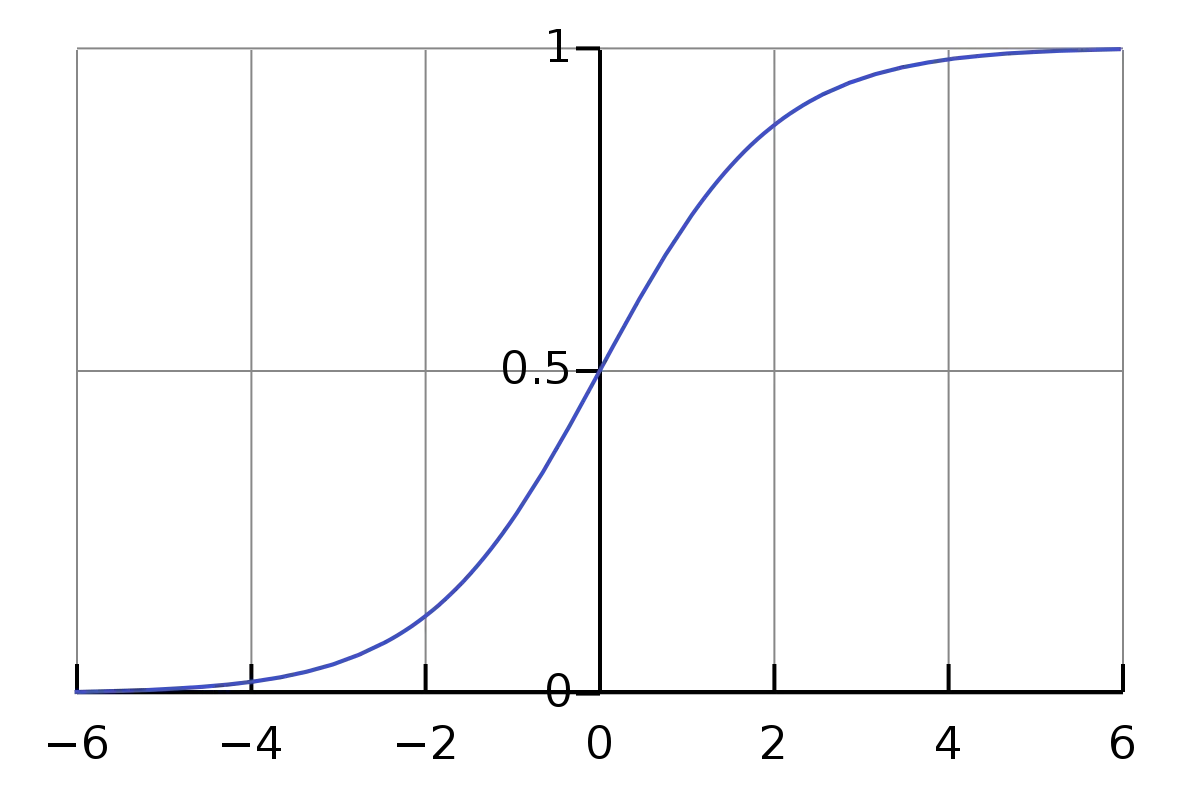
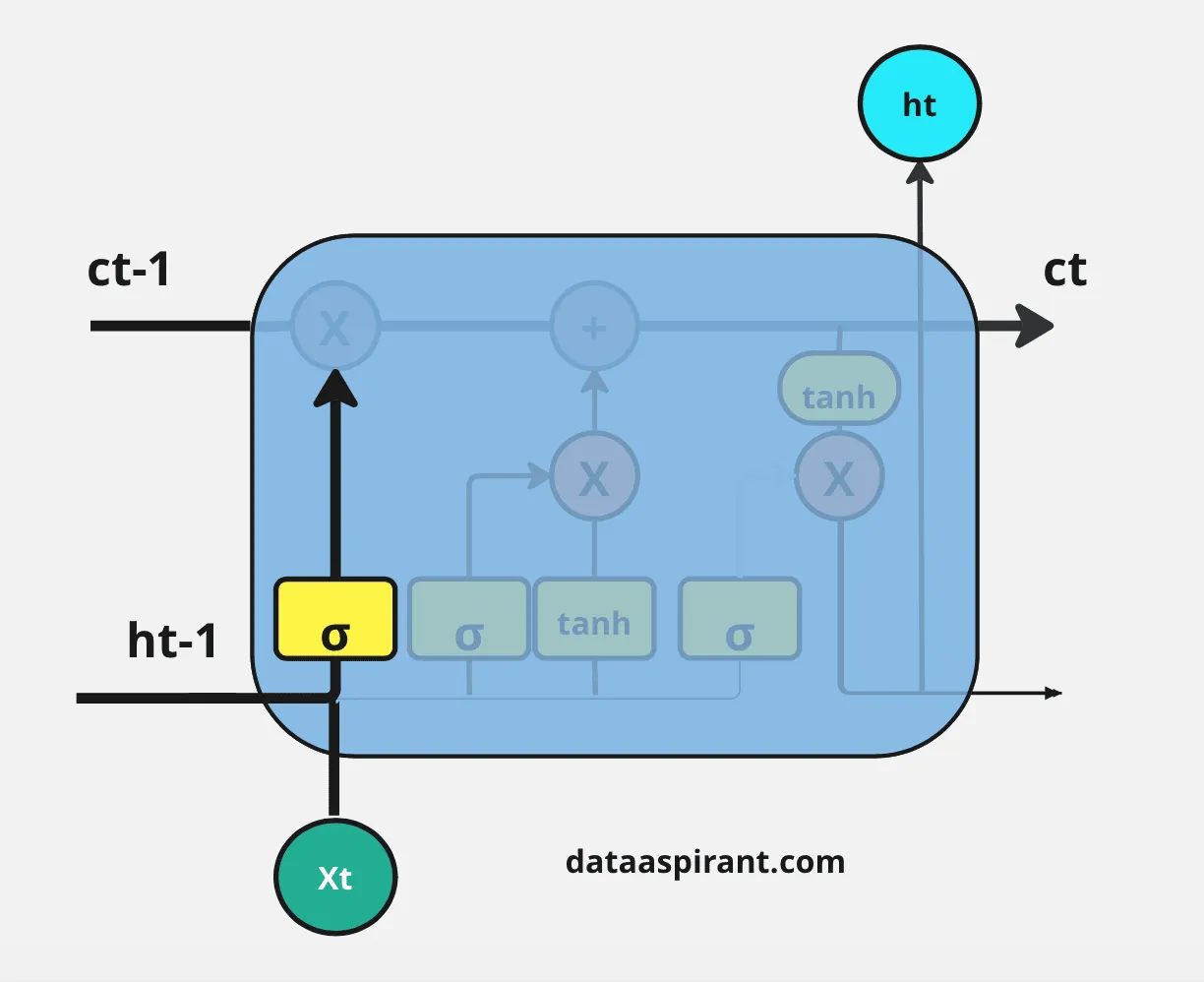
忘记门的输入是上一个时间步的隐蔽层信息( h t − 1 h_{t-1} ht−1)和当前时间步的输入( x t x_t xt),然后将其通过Sigmoid神经网络层。
结果是以向量情势出现,包罗0和1的值。然后,对上一个细胞状态( C t − 1 C_{t-1} Ct−1)的信息(向量情势)和Sigmoid函数的输出( f t f_t ft)进行逐元素乘法操作。
忘记门的最终输出中,1表示“完全保存这条信息”,0表示“不保存这条信息”。
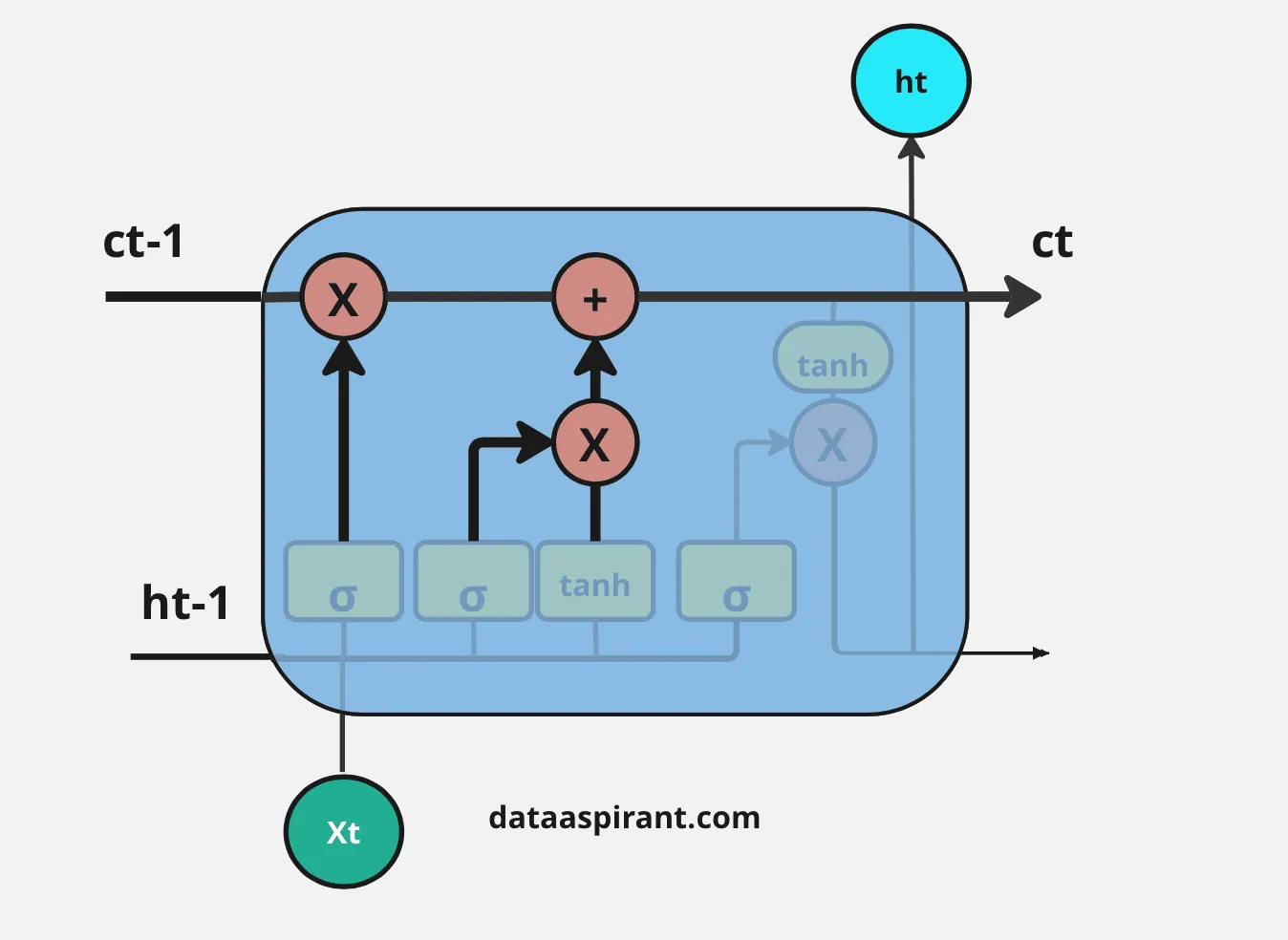
接下来的步调是决定将哪些信息存储在当前细胞状态( C t C_t Ct)中。另一个门会实行这个使命,LSTM架构中的第二个门是“输入门”。
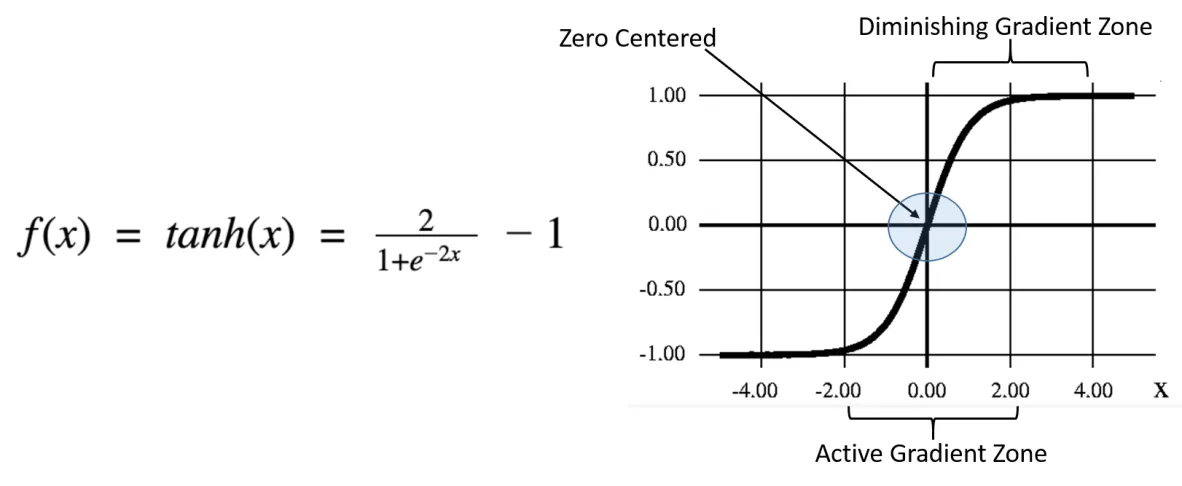
用新的重要信息更新细胞状态的整个过程将通过两种激活函数/神经网络层来完成,即Sigmoid神经网络层和Tanh神经网络层。
首先,Sigmoid网络层的输入和忘记门一样:上一个时间步的隐蔽层信息( h t − 1 h_{t-1} ht−1)和当前时间步( x t x_t xt)。
这个过程决定了我们将更新哪些值。然后,Tanh神经网络层也接收与Sigmoid神经网络层相同的输入。它以向量( C ~ t \tilde{C}_t C~t)的情势创建新的候选值,以调节网络。
如今,我们对Sigmoid层和Tanh层的输出进行逐元素乘法操作。之后,我们必要对忘记门的输出和输入门中逐元素乘法的结果进行逐元素加法操作,以更新当前细胞状态信息( C t C_t Ct)。
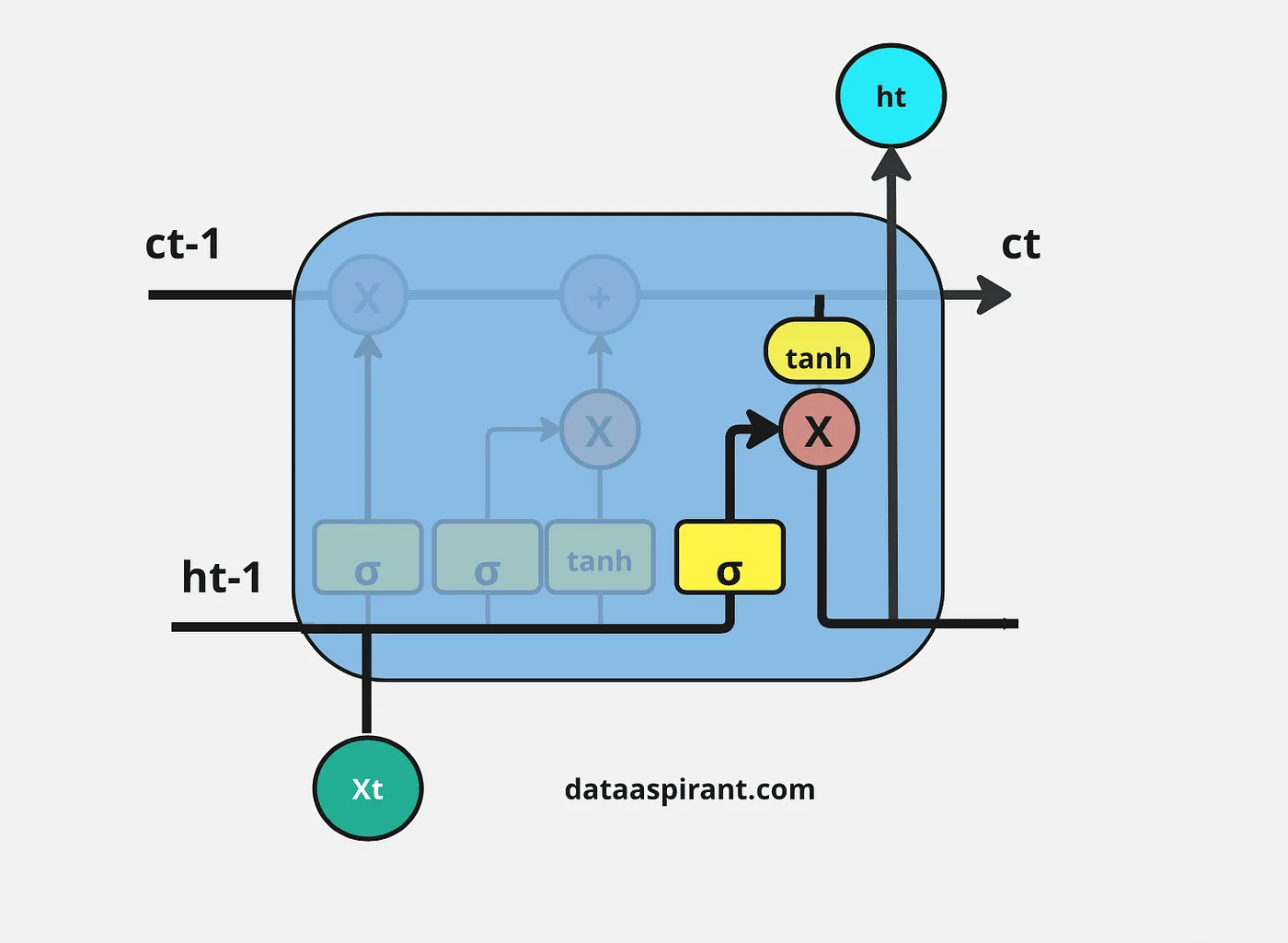
LSTM架构中的最后一步是决定将哪些信息作为输出;在LSTM中实行这一过程的最后一个门是“输出门”。这个输出将基于我们的细胞状态,但会是经过筛选的版本。
在这个门中,我们首先应用Sigmoid神经网络,它的输入和之前门的Sigmoid层一样:上一个时间步的隐蔽层信息( h t − 1 h_{t-1} ht−1)和当前时间输入( x t x_t xt),以决定细胞状态信息的哪些部分将作为输出。
然后将更新后的细胞状态信息通过Tanh神经网络层进行调节(将值压缩到-1和1之间),然后对Sigmoid神经网络层和Tanh神经网络层的两个结果进行逐元素乘法操作。