IT评测·应用市场-qidao123.com技术社区
标题:
借助内核逻辑锁pagecache到内存
[打印本页]
作者:
麻花痒
时间:
前天 02:01
标题:
借助内核逻辑锁pagecache到内存
一、配景
内存管理是一个永恒的主题,尤其在内存紧张触发内存回收的时间。系统在通过磁盘获取磁盘上的文件的内容时,若不开启O_DIRECT方式进行读写,磁盘上的任何东西都会被缓存到系统里,我们称之为page cache。可以想象,假如如许的举动持续,且假如我们持续地不断要访问磁盘上新的文件时,那么page cache就会不绝增长,page cache究竟也是占用物理内存的,所以物理内存终有一天还是会不够的。
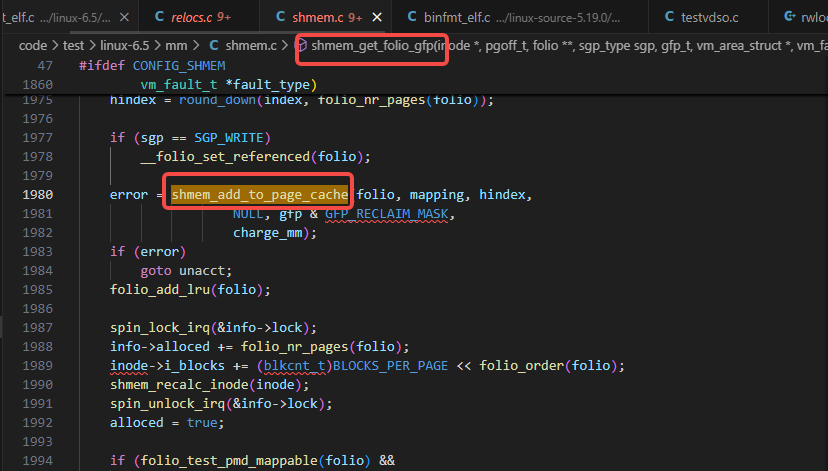
针对这种场景,内核有一些现有的机制,如使能swap分区,如许可以把不生动的匿名页给交换出去,交换到磁盘上,在背面再使用的时间再给交换回来,另有就是回收掉page cache,因为大部分的page cache上的数据都是有磁盘文件与之对应的,为什么说大部分,因为另有一部分是共享内存的数据,如使用shm_open出来的共享内存的数据,它也被统计进了free -h里的buff/cache里,所以,你说它算是pagecache,也是OK的,究竟shmem.c里的shmem_get_folio_gfp里有如下调用:
但是,另外一方面,它还是比较特别的,因为这部分共享内存的数据是没有磁盘对应的文件的,所以它除了被交换到swap分区之外,它对应的内存是不能回收的。另外,这块内存虽然统计到buff/cache里,但是并没有统计到/proc/meminfo里的Active(file)和Inactive(file)里,所以严酷意义上来说,它又不是pagecache。
剔除共享内存这种特殊的pagecache以外,对于真正的文件页pagecache,在不开swap分区的话,这部分文件页的pagecache仍旧会被系统里的内存回收逻辑给回收。触发该内存回收逻辑的可能有node里的memory zone触及了低水位,也有memory cgroup触及memory.high水位,还可能是加的内核功能逻辑去主动做释放的动作。
假如一旦内核把一些将来会被用到的文件页给回收了,那么就会造成下次再次使用时重新从磁盘上读取该文件页的同步读的性能损耗。为了淘汰如许的性能损耗,我们可以把系统里的一些关键的代码段或者一些关键的文件对应的内存锁住,不让系统在回收时选择它们。
我们可以使用一些上层的手段如mlock去锁住,但是用mlock去锁相关文件页的一个条件是这个历程得不绝在,假如历程退出,mlock的锁住的举动就会被“释放”。而假如用内核手段去锁住文件页,那么这个锁住状态是持久了,不会因为历程的退出而释放。我们只必要在必要的时间去解锁即可。
这篇博客里下面第二章会给出锁住文件页的一个内核模块的示例程序,并演示效果。在第三章里,我们对第二章代码里的细节做出分析和原明白释。
二、源码及效果展示
2.1 锁文件page的内核模块代码
#include <linux/module.h>
#include <linux/kernel.h>
#include <linux/fs.h>
#include <linux/init.h>
#include <linux/slab.h>
#include <linux/dcache.h>
#include <linux/namei.h>
#include <linux/pagemap.h>
// 模块参数
static char *filepath = "/tmp/testfile"; // 默认文件路径
module_param(filepath, charp, S_IRUGO);
MODULE_PARM_DESC(filepath, "Path of the file to open");
static char *mode = "nothing";
module_param(mode, charp, S_IRUGO);
char buffer[4096];
int getfullpath(struct inode *inode)
{
struct dentry *dentry;
printk("inode = %p\n", inode);
hlist_for_each_entry(dentry, &inode->i_dentry, d_u.d_alias) {
char *path;
path = dentry_path_raw(dentry, buffer, PAGE_SIZE);
if (IS_ERR(path)){
continue;
}
printk("dentry name = %s , path = %s\n", dentry->d_name.name, path);
}
return 0;
}
static int __init my_module_init(void) {
struct file *file;
printk(KERN_INFO "Opening file: %s\n", filepath);
// 打开文件
file = filp_open(filepath, O_RDONLY, 0);
printk(KERN_INFO "file[%p]\n", file);
if (IS_ERR(file)) {
printk(KERN_ERR "Error opening file: %ld\n", PTR_ERR(file));
return PTR_ERR(file);
}
// getfullpath(file->f_inode);
// do {
// char *path;
// path = dentry_path_raw(file->f_path.dentry, buffer, PAGE_SIZE);
// if (IS_ERR(path)){
// break;
// }
// printk("[2] dentry name = %s , path = %s\n", file->f_path.dentry->d_name.name, path);
// } while(0);
// lock pages of the input filepath file
if (strcmp(mode, "nothing") != 0) {
struct address_space *mapping = file->f_mapping;
struct page *page;
pgoff_t index;
unsigned long start_index, end_index;
start_index = 0;
printk("i_size=%ld\n", mapping->host->i_size);
end_index = (mapping->host->i_size >> PAGE_SHIFT);
//printk("end_index=%lu\n", end_index);
#if 1
for (index = start_index; index < end_index; index++) {
if (strcmp(mode, "lock") == 0) {
page = find_get_page(mapping, index);
if (!page) {
page = read_cache_page_gfp(mapping, index, GFP_KERNEL);
if (!page) {
printk("page[%lu] is NULL!\n", index);
}
else {
//get_page(page);
//SetPageMlocked(page);
//page = find_get_page(mapping, index);
unsigned long ref_count = page_ref_count(page);
printk("page[%lu] ref=%lu\n", index, ref_count);
}
}
else {
unsigned long ref_count = page_ref_count(page);
printk("page[%lu] ref=%lu\n", index, ref_count);
}
//mapping_set_unevictable(mapping);
}
else if (strcmp(mode, "unlock") == 0) {
page = find_get_page(mapping, index);
if (page) {
//__ClearPageMlocked(page);
put_page(page);
put_page(page);
}
//mapping_clear_unevictable(mapping);
}
else if (strcmp(mode, "query") == 0) {
page = find_get_page(mapping, index);
if (!page) {
printk("page[%lu] is NULL!\n", index);
}
else {
//get_page(page);
//SetPageMlocked(page);
//page = find_get_page(mapping, index);
unsigned long ref_count = page_ref_count(page);
printk("page[%lu] ref=%lu\n", index, ref_count);
put_page(page);
}
}
// else if (strcmp(mode, "grablock") == 0) {
// page = grab_cache_page(mapping, index);
// if (!page) {
// printk("page[%lu] is NULL!\n", index);
// }
// else {
// unsigned long ref_count = page_ref_count(page);
// printk("page[%lu] ref=%lu\n", index, ref_count);
// }
// }
}
#endif
}
// 关闭文件
filp_close(file, NULL);
return -EINVAL;
}
static void __exit my_module_exit(void) {
printk(KERN_INFO "Module exiting\n");
}
module_init(my_module_init);
module_exit(my_module_exit);
MODULE_LICENSE("GPL");
MODULE_AUTHOR("Zhaoxin");
MODULE_DESCRIPTION("A simple module to read file and lock pagecache");
复制代码
2.2 配合做实验的用户态程序代码
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <fcntl.h>
#include <unistd.h>
#include <sys/mman.h>
#include <sys/stat.h>
#include <sys/types.h>
#include <errno.h>
#include <sys/resource.h>
#define FILE_NAME "large_file.img"
#define FILE_SIZE 1024*1024*1024ull
int main() {
int fd;
//char *buffer;
// 创建并打开文件
//fd = open(FILE_NAME, O_RDWR | O_CREAT | O_TRUNC, S_IRUSR | S_IWUSR);
fd = open(FILE_NAME, O_RDWR, S_IRUSR | S_IWUSR);
if (fd == -1) {
perror("open");
return EXIT_FAILURE;
}
//buffer = (char*)malloc(FILE_SIZE);
// if (!buffer) {
// perror("malloc");
// close(fd);
// return EXIT_FAILURE;
// }
// memset(buffer, 0, FILE_SIZE);
// const char *data = "This is some sample data to be written to the file.";
// strncpy(buffer, data, FILE_SIZE);
// getchar();
char *mapped = (char*)mmap(NULL, FILE_SIZE, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0);
if (mapped == MAP_FAILED) {
perror("mmap");
close(fd);
exit(EXIT_FAILURE);
}
// if (read(fd, buffer, FILE_SIZE) == -1) {
// perror("read");
// free(buffer);
// close(fd);
// return EXIT_FAILURE;
// }
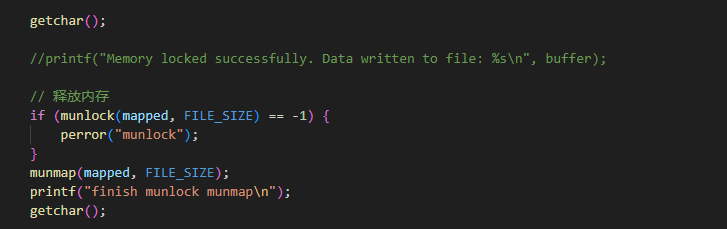
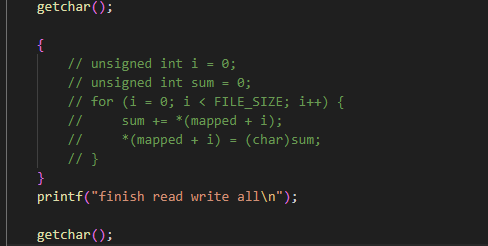
getchar();
{
unsigned int i = 0;
unsigned int sum = 0;
for (i = 0; i < FILE_SIZE; i++) {
sum += *(mapped + i);
*(mapped + i) = (char)sum;
}
}
printf("finish read write all\n");
getchar();
// 锁定内存区域
if (mlock(mapped, FILE_SIZE) == -1) {
perror("mlock");
//free(buffer);
close(fd);
return EXIT_FAILURE;
}
printf("finish mlock\n");
getchar();
//printf("Memory locked successfully. Data written to file: %s\n", buffer);
// 释放内存
if (munlock(mapped, FILE_SIZE) == -1) {
perror("munlock");
}
munmap(mapped, FILE_SIZE);
printf("finish munlock munmap\n");
getchar();
//free(buffer);
close(fd);
return EXIT_SUCCESS;
}
复制代码
2.3 效果展示
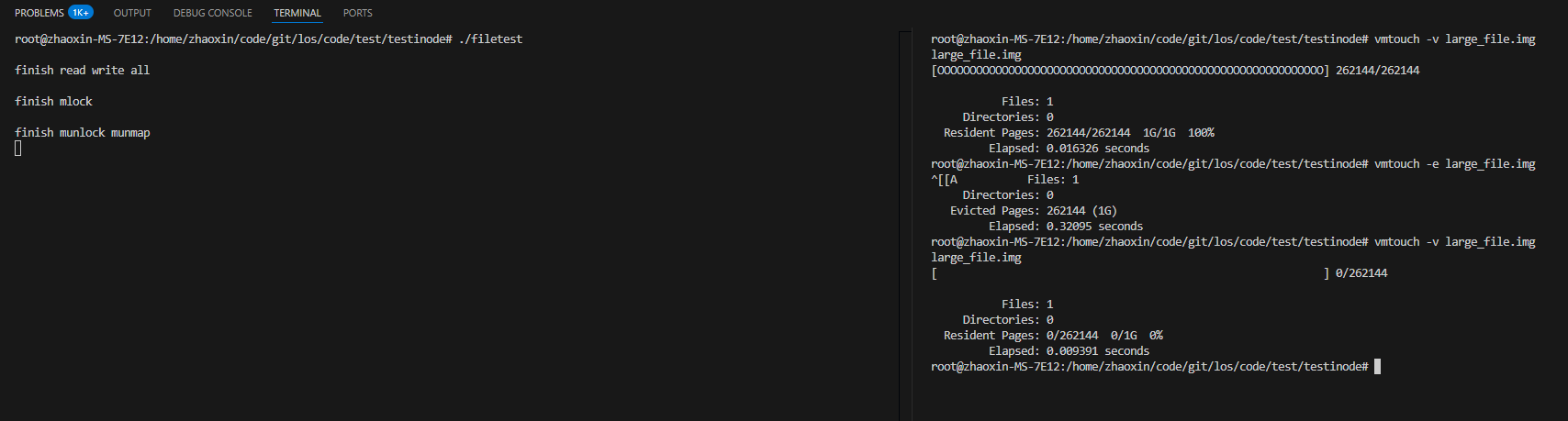
在上面 2.2 里的测试程序里,通过mmap来读写大文件,叫large_file.img,大小是1G。
我们分几种情况来进行测试:
1)mmap方式读写大文件(注意是MAP_SHARED方式),触发完全部页的缺页非常,让磁盘文件都加载进page cache,但不mlock锁定
——在这种情况下通过内核逻辑锁住page cache,并用vmtouch -e来做移除实验
——然后再调用内核逻辑解锁page cache,看是否能vmtouch -e来移除掉
通过读写文件全部的字节来触发完全部页的缺页非常:
2)mmap映射了大文件,但是还未进行任何读写,也就是还未触发缺页非常
——在这种情况下通过内核逻辑锁住page cache,并用vmtouch -v、vmtouch -e来打印情况和做移除实验
——然后再调用内核逻辑解锁page cache,看是否能vmtouch -e来移除掉
3)mmap映射了大文件,并调用mlock锁住内存页
——在这种情况下通过内核逻辑锁住page cache,并用vmtouch -v、vmtouch -e来打印情况和做移除实验
——然后再调用内核逻辑解锁page cache,看是否能vmtouch -e来移除掉
上面 2.2 的测试程序里有多处响应按键的地方,在按第一次按键前,进行了mmap该大文件的映射,但是并未进行任何的读写:
按第一次按键后是进行1Gsize读写,天然会加载进pagecache里:
按第二次按键后,按第三次按键前,调用了mlock锁住了这个1G的内存:
按第三次按键后,程序会执行munlock再munmap后再做退出:
下面,我们针对上面这几次按键的差别场景分别做实验。
2.3.1 mmap方式已触发缺页非常后的场景
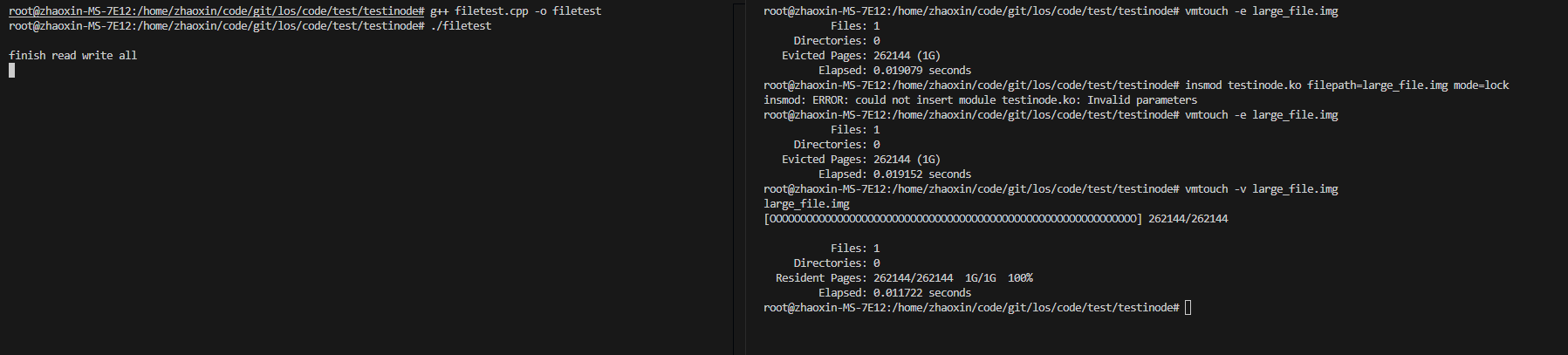
这一节测试的场景是mmap方式,并已经触发了缺页非常,但是还未mlock锁定的场景下,执行我们的内核模块程序来进行内核态锁住逻辑,看执行完是否能驱逐掉,再进行内核态解锁,看是否能驱逐掉。
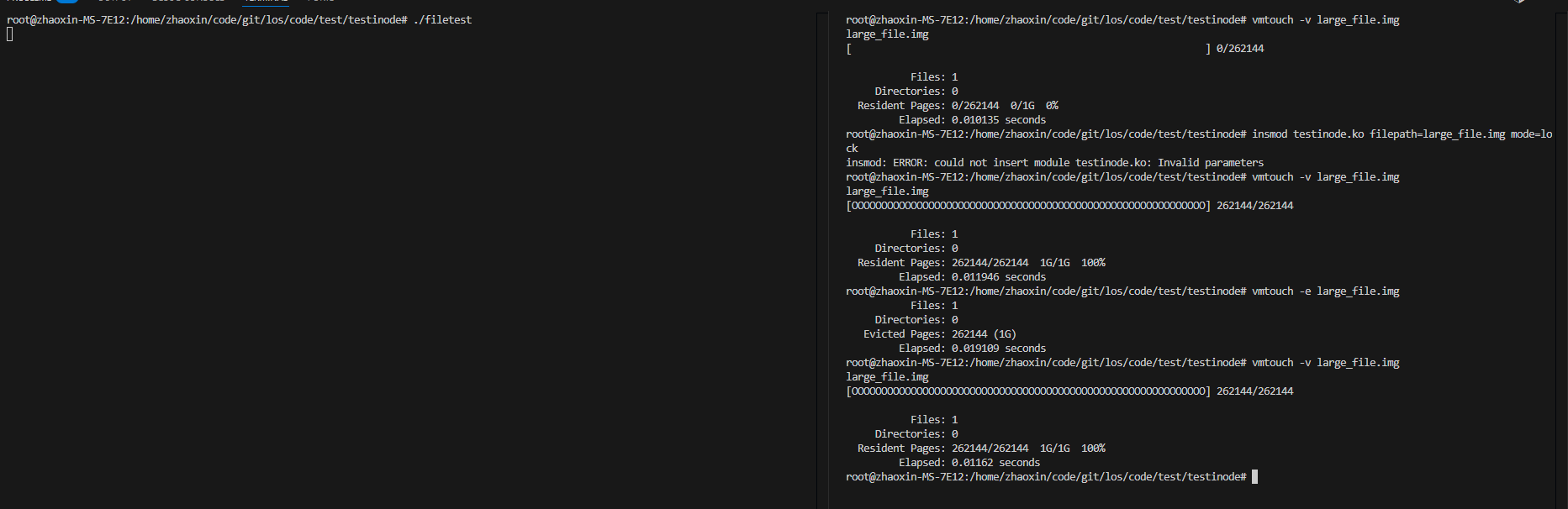
如下图,触发缺页非常之后,large_file.img这个文件对应的pagecache都加载进去了。
我们进行内核态锁定后,可以看到是驱逐不掉的:
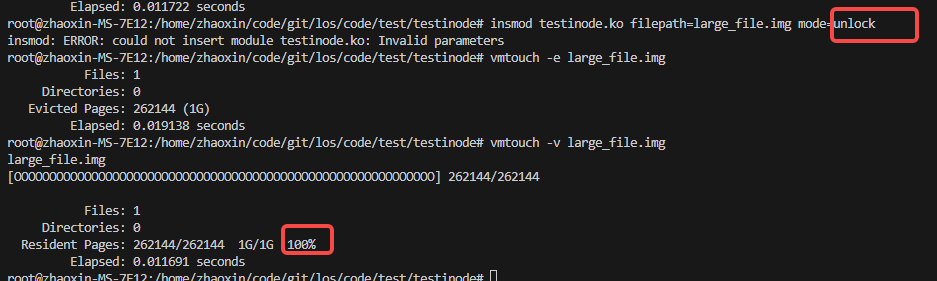
然后通过内核态解锁后,可以看到已经发生缺页非常的部分,在没有munmap时就算不mlock也是不能驱逐掉的:
这个原因会在下面 3.2 里进行表明。
我们下面展示一下,不进行内核逻辑的锁定,看是否能驱逐出去这部分已经触发了缺页非常的pagecache:
如上图可以看到,对于mmap方式(MAP_SHARED方式)进行读写,就算不调用mlock,在munmap之前,就算不用内核锁定逻辑,对应的pagecache都是驱逐不出去的。
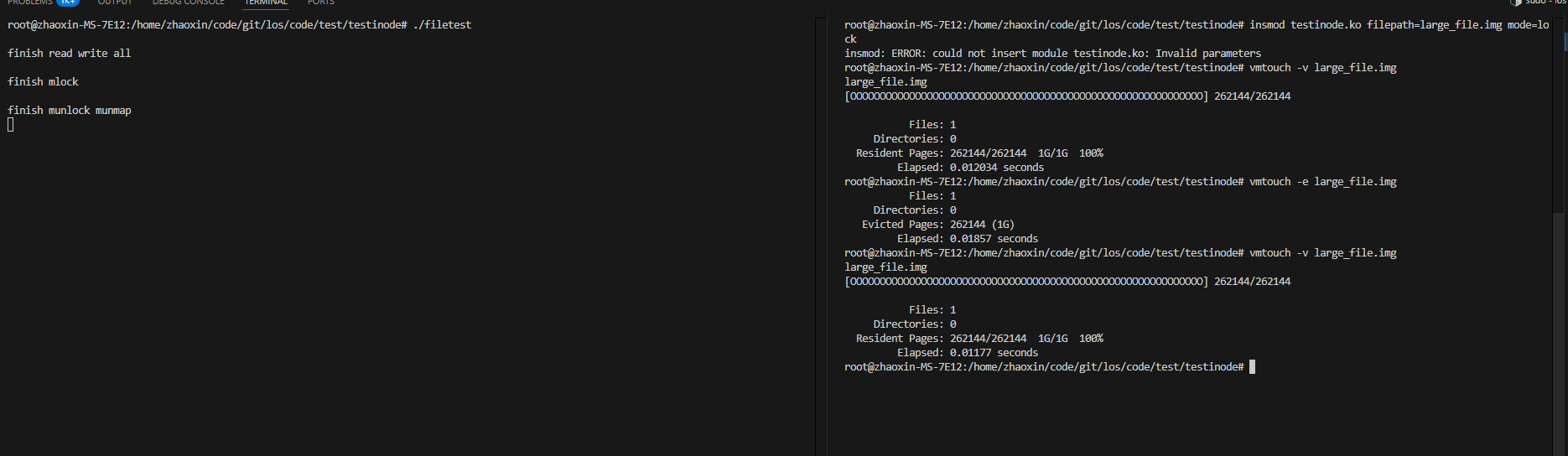
2.3.2 mmap方式未触发缺页非常后的场景
分两种情况来测,先测执行filetest但是不触发缺页非常,看vmtouch -v的情况,然后加载内核模块进行锁定,再看vmtouch -v的情况,并看是否可以驱逐出去;然后我们再测,在执行filetest之前直接运行内核模块的锁定逻辑,再运行filetest但是不触发缺页非常,看是否可以驱逐出去。
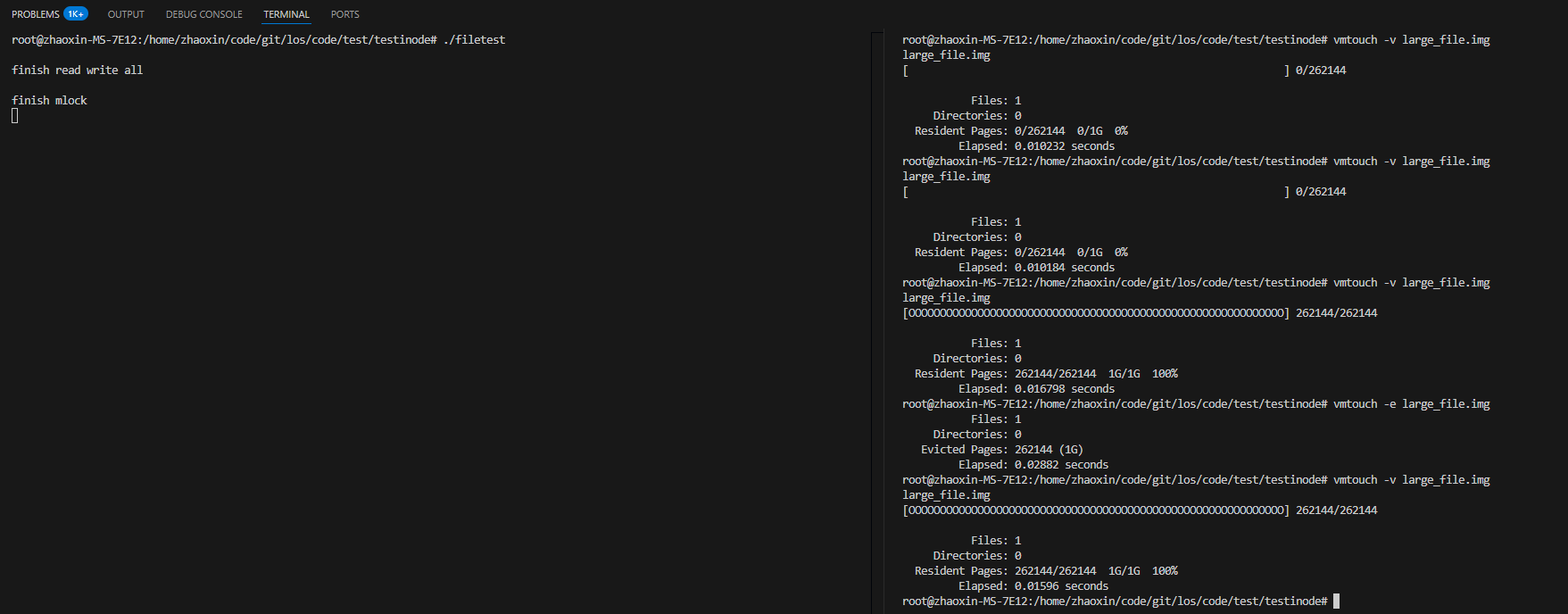
如上图可以看到,在filetest未触发缺页非常时,相关的pagecache未被加载,然后调用了内核逻辑,让其全部被加载,并驱逐无效。
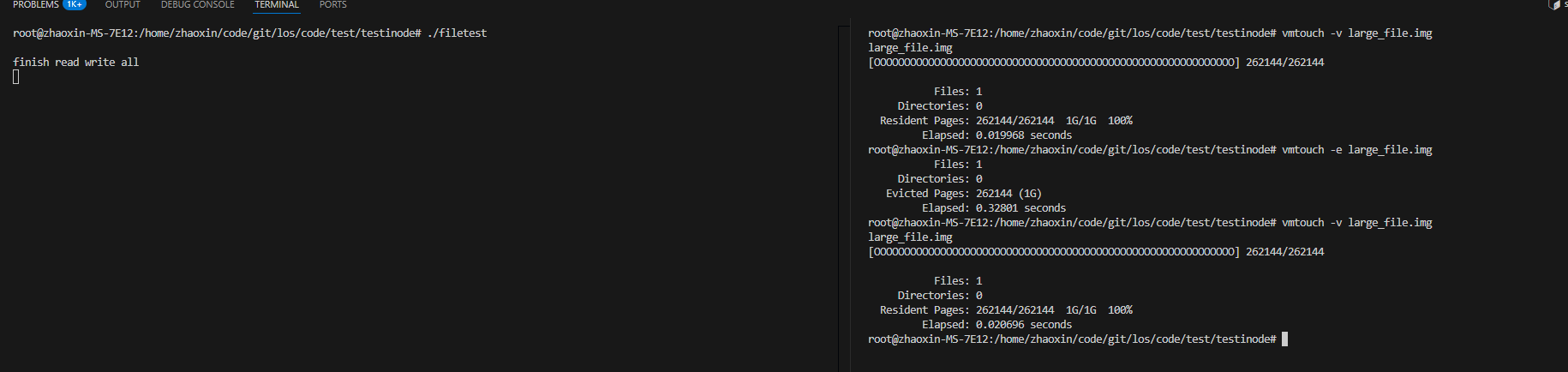
下面我们测试看先调用内核模块的锁定逻辑,再调用filetest并不触发缺页非常,看是否可以驱逐出去,可以从下图看到,同样是驱逐不出去的:
2.3.3 mmap方式mlock后及munmap后的场景
其实在上面 2.3.1 的实验里,我们已经知道,假如是mmap方式MAP_SHARED方式对于已经触发缺页非常的部分,就算不做mlock对应的pagecache也是无法被驱逐的。
我们这里只需再做补充实验,就是不调用内核锁定逻辑,并不触发缺页非常,直接调用mlock,看是否相关pagecache已经被加载进来了,并看是否可以被驱逐掉。
我们改写一下程序,让触发缺页非常的逻辑干掉:
看不调用内核逻辑锁定,只靠mlock是否可以保证mmap MAP_SHARED的读写方式对应的pagecache是不是会被驱逐。
如下图可以看到是不会被驱逐的:
关于mlock的内核逻辑之前的博客有具体的介绍,可以参考 内存管理相关——malloc,mmap,mlock与unevictable列表-CSDN博客。
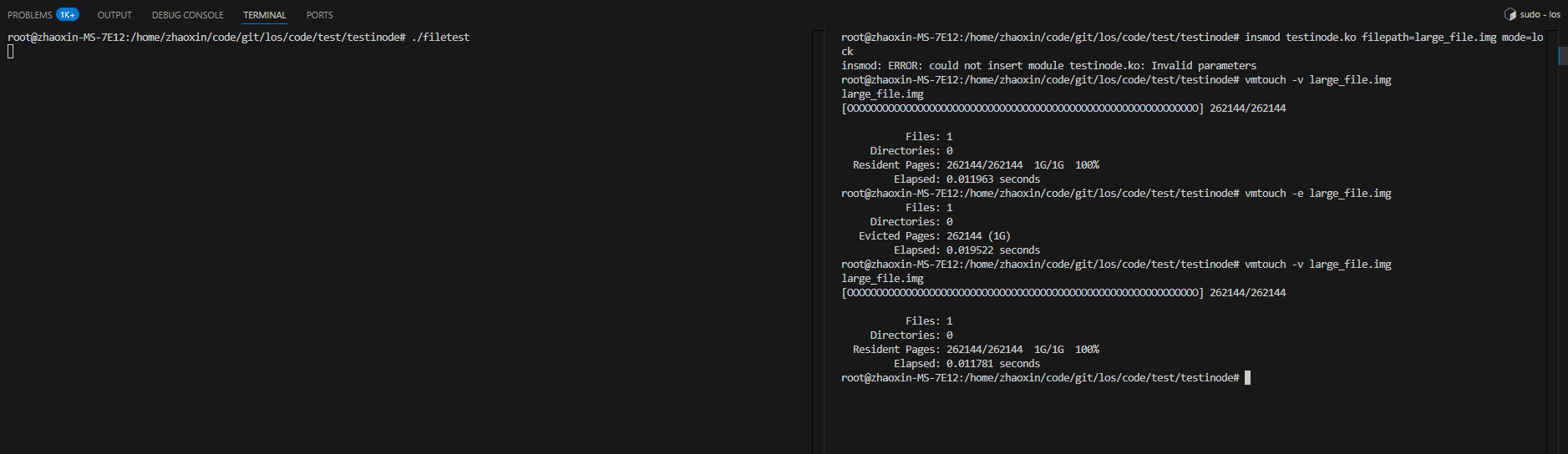
我们下面再看一下munmap后,假如不调用内核锁定逻辑看是否可以被驱逐,如下图看到是可以被驱逐的:
然后,我们试一下,执行过内核锁定逻辑之后,在munmap后是否能被驱逐:
可以从上图看到,是不会被驱逐的。
三、源码分析及原明白释
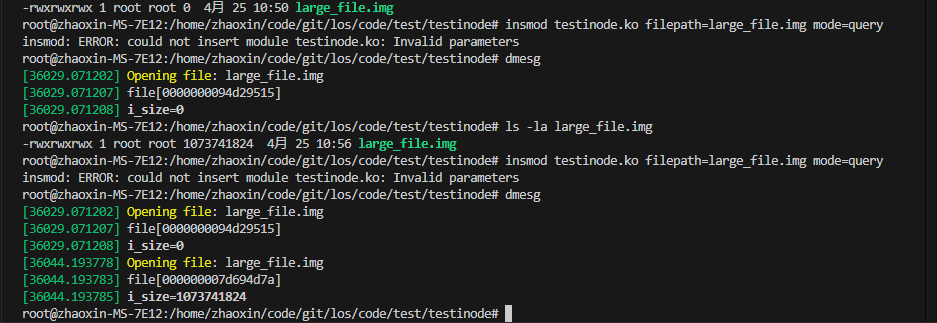
3.1 使用inode的i_size获取文件的大小
通过file->f_mapping->host可以获得打开的文件对应inode,这里的file是指历程地址空间实例的file,通过inode->i_size可以得到文件的大小:
上图对应的是执行两次filetest,第一次没有写入文件,第二次写入了一段时间就ctrl+c停止了:
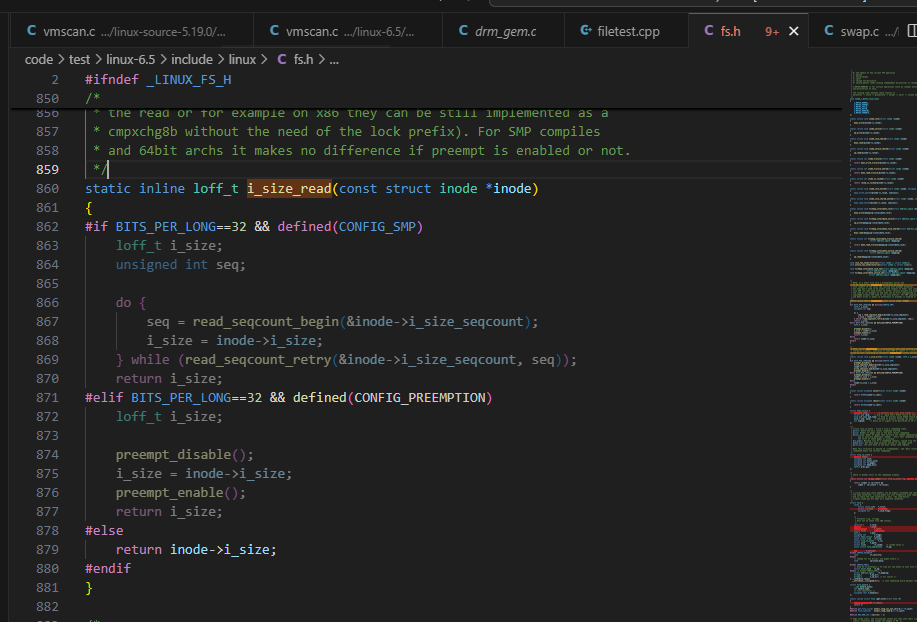
对于64位系统上,直接获取inode->i_size是没有什么题目标,假如是32bit系统上,得使用i_size_read来获取,如i_size_read里的实现,使用到了次序锁,次序锁的细节见之前的博客 次序锁的原理和使用注意事项-CSDN博客:
3.2 对于mmap文件出来的地址空间,一旦触发了缺页非常,其pagecache不会回收
上面 2.3.1 的实验可以看到,假如mmap一个磁盘上的文件到一个历程的假造地址空间之后,一旦触发了缺页非常,就算不执行mlock,也不执行内核态的锁pagecache,这些mmap且已经触发缺页非常的pagecache系统是回收不了的。
对于系统里的程序,假如程序并未退出,mmap加载的一些so库(程序的代码段都是mmap方式加载进地址空间)假如一旦触发过缺页非常,那么它们对应的pagecache是不会被回收的。但是要注意,对于一些会退出的历程,一旦历程退出,对应的代码段就可以被回收了,比如像grep/ls等这些系统命令的代码段。
通过mlock或者内核态的锁定逻辑可以提前把这些代码段给加载进pagecache,假如加上锁定后,它们就不绝不回被回收了(假如用内核逻辑进行锁定,就算程序退出后,相关已经锁定的代码段也不会被回收了)。
3.2.1 mmap的MAP_PRIVATE方式的说明
虽然我们这篇博客里的示例程序用的是MAP_SHARED方式进行的读写,但是对于库文件来说,一般都是用的MAP_PRIVATE方式。
MAP_PRIVATE方式要注意的是,假如是读,那其pagecache肯定是可以多个历程共享同一个so的代码文件的。但是对于可写的部分,MAP_PRIVATE方式进行的映射会把可写的部分触发一个COW分配匿名内存并拷贝一份出来改写,如许原代码文件不会被改写,这也是so库里的data段也是这么一个方式。
对于我们这篇博客里的示例程序而言,假如用MAP_PRVIATE方式,假如要进行写的话,那么就写的是匿名内存,那么全部的pagecache的实验都不凑效了。但是假如用MAP_PRIVATE方式只是读的话,那么这篇博客里的实验也是一样凑效的。
3.3 对于非mmap方式的文件读写情况的说明
所谓非mmap方式的文件读写,就是直接通过read/write/fread/fwrite的如许的文件系统的接口来读写文件数据。这种方式,由于并没有直接映射相关文件到历程地址空间,而是借助vfs进行代码读写,在完成读写之后,内核是可以对其pagecache内容进行回收的。
对于读和写还得分开来看,对于读而言,虽然不放面使用mlock(因为通过通例手段不mmap根本拿不到pagecache对应的假造内存),但是可以使用内核模块的锁定逻辑进行锁定。
但是对于写而言,要特别注意,
假如是一个1G文件,重新O_CREAT创建并从开头开始写入,那么对于旧文件的这些锁定逻辑包括内核锁定逻辑,由于文件大小已经变更回过0了,所以之前的page是可以被拿去回收的,这一点要额外注意
。
3.4 通过增长page引用计数来防止被驱逐
通过page引用计数来方式被内存回收的做法,其实在之前的博客 内存管理之——get_user_pages和pin_user_pages及缺页非常_get user page-CSDN博客 里也有讲到。
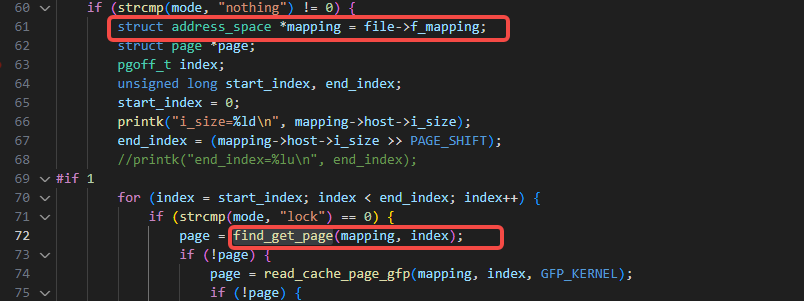
这里,我们的关键逻辑是如何找到文件相关的page,如下方式通过find_get_page来根据address_space来获取到指定index的page:
address_space的指针可通过file的f_mapping拿到,另外上图里的index即address_space的映射的pages里的序号。
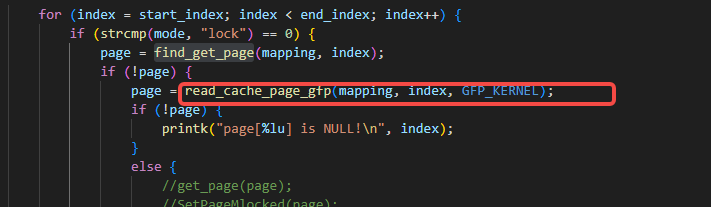
假如find_get_page找不到的话,再通过read_cache_page_gfp来读取磁盘上的文件读到pagecache,固然天然必要按需创建pagecache的内存,所以必要传入分配内存时的gfp参数:
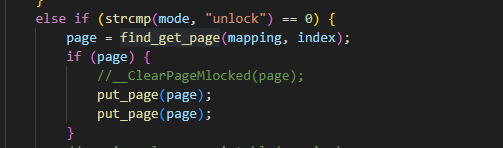
由于find_get_page和read_cache_page_gfp都是会增长page的引用计数的,所以就没必要再get_page一次了。只需在对应的unlock逻辑里也得相应的扣除引用计数(多put_page一次就是为了扣除,另一次是抵消find_get_page的引用计数):
免责声明:如果侵犯了您的权益,请联系站长,我们会及时删除侵权内容,谢谢合作!更多信息从访问主页:qidao123.com:ToB企服之家,中国第一个企服评测及商务社交产业平台。
欢迎光临 IT评测·应用市场-qidao123.com技术社区 (https://dis.qidao123.com/)
Powered by Discuz! X3.4