IT评测·应用市场-qidao123.com技术社区
标题:
PyTorch深度学习框架60天进阶学习计划 - 第49天:联邦学习安全(二)
[打印本页]
作者:
三尺非寒
时间:
前天 08:12
标题:
PyTorch深度学习框架60天进阶学习计划 - 第49天:联邦学习安全(二)
PyTorch深度学习框架60天进阶学习计划 - 第49天:联邦学习安全(二)
第二部门:同态加密与安全多方计算的通信开销对比
在第一部门中,我们深入探讨了差分隐私噪声注入机制。
如今,我们将转向联邦学习安全中另外两个关键技术:
同态加密(Homomorphic Encryption, HE)和安全多方计算(Secure Multi-party Computation, MPC),主要对比它们的通信开销、计算复杂度和现实应用场景。
1. 同态加密基础
同态加密是一种特殊的加密技术,它允许在加密数据上直接进行计算,且运算结果解密后与对原始数据进行雷同运算的结果一致。
1.1 同态加密的数学基础
同态加密的焦点基于数学中的同态性质。如果我们有一个加密函数E息争密函数D,则对于操作⊕,如果满意:
D(E(a) ⊗ E(b)) = a ⊕ b
复制代码
那么E就是关于操作⊕的同态加密。
差别范例的同态加密:
部门同态加密
:只支持一种运算(加法或乘法)
RSA:乘法同态
Paillier:加法同态
全同态加密
:支持任意计算,但计算开销大
CKKS:近似同态加密,适用于浮点数计算
BGV/BFV:适用于整数计算
1.2 PyTorch中实现Paillier同态加密
下面我们实现一个基于Paillier加密的安全联邦学习体系,专注于梯度加密和聚合:
import numpy as np
import torch
import time
import phe # 引入Python的同态加密库
from phe import paillier
import pickle
import os
import matplotlib.pyplot as plt
from collections import OrderedDict
class PaillierCrypto:
"""Paillier同态加密实现"""
def __init__(self, key_length=2048):
"""
初始化Paillier密钥对
参数:
key_length: 密钥长度,默认2048位
"""
self.key_length = key_length
self.public_key = None
self.private_key = None
def generate_keypair(self):
"""生成新的密钥对"""
self.public_key, self.private_key = paillier.generate_paillier_keypair(n_length=self.key_length)
return self.public_key, self.private_key
def load_keypair(self, public_key_file, private_key_file=None):
"""从文件加载密钥对"""
with open(public_key_file, 'rb') as f:
self.public_key = pickle.load(f)
if private_key_file:
with open(private_key_file, 'rb') as f:
self.private_key = pickle.load(f)
return self.public_key, self.private_key
def save_keypair(self, public_key_file, private_key_file):
"""保存密钥对到文件"""
if not self.public_key or not self.private_key:
raise ValueError("密钥对尚未生成")
with open(public_key_file, 'wb') as f:
pickle.dump(self.public_key, f)
with open(private_key_file, 'wb') as f:
pickle.dump(self.private_key, f)
def encrypt_value(self, value):
"""加密单个浮点值"""
if not self.public_key:
raise ValueError("公钥未设置")
return self.public_key.encrypt(float(value))
def decrypt_value(self, encrypted_value):
"""解密单个加密值"""
if not self.private_key:
raise ValueError("私钥未设置")
return self.private_key.decrypt(encrypted_value)
def encrypt_vector(self, vector):
"""加密向量(数组或张量)"""
if isinstance(vector, torch.Tensor):
vector = vector.cpu().numpy().flatten()
else:
vector = np.array(vector).flatten()
encrypted_vector = [self.encrypt_value(v) for v in vector]
return encrypted_vector
def decrypt_vector(self, encrypted_vector):
"""解密向量"""
decrypted_vector = [self.decrypt_value(v) for v in encrypted_vector]
return np.array(decrypted_vector)
def encrypt_model_gradients(self, gradients):
"""
加密模型梯度
参数:
gradients: OrderedDict,包含模型的参数名称和梯度
返回:
加密后的梯度字典
"""
encrypted_gradients = OrderedDict()
for name, grad in gradients.items():
# 转换为NumPy数组并加密
grad_np = grad.cpu().numpy()
encrypted_grad = {}
encrypted_grad['shape'] = grad_np.shape
encrypted_grad['data'] = self.encrypt_vector(grad_np)
encrypted_gradients[name] = encrypted_grad
return encrypted_gradients
def decrypt_model_gradients(self, encrypted_gradients):
"""
解密模型梯度
参数:
encrypted_gradients: 加密后的梯度字典
返回:
解密后的梯度OrderedDict
"""
decrypted_gradients = OrderedDict()
for name, encrypted_grad in encrypted_gradients.items():
# 解密并重塑为原始形状
shape = encrypted_grad['shape']
decrypted_data = self.decrypt_vector(encrypted_grad['data'])
decrypted_data = decrypted_data.reshape(shape)
# 转换为PyTorch张量
decrypted_gradients[name] = torch.tensor(decrypted_data)
return decrypted_gradients
class HomomorphicFederatedLearning:
"""使用同态加密的联邦学习系统"""
def __init__(self, global_model, crypto=None, key_length=2048):
"""
初始化同态加密联邦学习系统
参数:
global_model: 全局PyTorch模型
crypto: 可选的PaillierCrypto实例
key_length: 如果未提供crypto,创建新实例时使用的密钥长度
"""
self.global_model = global_model
# 初始化或使用提供的加密系统
if crypto:
self.crypto = crypto
else:
self.crypto = PaillierCrypto(key_length=key_length)
self.crypto.generate_keypair()
# 跟踪通信开销
self.communication_overhead = {
'encrypted_size': 0,
'decrypted_size': 0,
'encryption_time': 0,
'decryption_time': 0,
'communication_time': 0
}
def train_client(self, client_id, dataloader, epochs=1, lr=0.01):
"""
训练单个客户端模型
参数:
client_id: 客户端ID
dataloader: 客户端本地数据加载器
epochs: 本地训练轮数
lr: 学习率
返回:
加密后的梯度更新
"""
# 复制全局模型作为客户端本地模型
client_model = type(self.global_model)()
client_model.load_state_dict(self.global_model.state_dict())
client_model.train()
# 设置优化器
optimizer = torch.optim.SGD(client_model.parameters(), lr=lr)
criterion = torch.nn.CrossEntropyLoss()
# 训练模型
for epoch in range(epochs):
epoch_loss = 0
for data, target in dataloader:
optimizer.zero_grad()
output = client_model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
epoch_loss += loss.item()
print(f'Client {client_id}, Epoch {epoch+1}/{epochs}, Loss: {epoch_loss/len(dataloader):.4f}')
# 计算梯度更新 (全局模型参数 - 本地更新后的参数)
gradient_updates = OrderedDict()
for name, param in self.global_model.named_parameters():
client_param = dict(client_model.named_parameters())[name]
gradient_updates[name] = param.data - client_param.data
# 测量未加密梯度的大小
unencrypted_size = self._calculate_size(gradient_updates)
self.communication_overhead['decrypted_size'] += unencrypted_size
# 加密梯度更新
start_time = time.time()
encrypted_updates = self.crypto.encrypt_model_gradients(gradient_updates)
encryption_time = time.time() - start_time
self.communication_overhead['encryption_time'] += encryption_time
# 测量加密梯度的大小
encrypted_size = self._calculate_size(encrypted_updates)
self.communication_overhead['encrypted_size'] += encrypted_size
# 模拟通信延迟
self._simulate_communication(encrypted_size)
print(f'Client {client_id} gradients encrypted. Size: {unencrypted_size/1024:.2f} KB -> {encrypted_size/1024:.2f} KB')
print(f'Encryption time: {encryption_time:.2f} seconds')
return encrypted_updates
def aggregate_encrypted_gradients(self, all_encrypted_gradients, weights=None):
"""
聚合加密的梯度更新
参数:
all_encrypted_gradients: 所有客户端的加密梯度列表
weights: 客户端权重列表,默认为等权重
返回:
聚合后的加密梯度
"""
if not all_encrypted_gradients:
return None
# 如果未提供权重,使用等权重
n_clients = len(all_encrypted_gradients)
if weights is None:
weights = [1.0 / n_clients] * n_clients
# 获取所有参数名称(假设所有客户端具有相同的参数结构)
param_names = all_encrypted_gradients[0].keys()
# 聚合加密梯度
aggregated_gradients = OrderedDict()
for name in param_names:
# 为每个参数初始化聚合结果
encrypted_param_gradients = [client_grads[name] for client_grads in all_encrypted_gradients]
# 同态加密支持加权加法,直接在加密域中进行聚合
aggregated_param = {}
aggregated_param['shape'] = encrypted_param_gradients[0]['shape']
# 初始化加密数据
aggregated_data = []
for i in range(len(encrypted_param_gradients[0]['data'])):
# 加权求和第一个客户端的梯度
weighted_sum = weights[0] * encrypted_param_gradients[0]['data'][i]
# 加权求和其余客户端的梯度
for client_idx in range(1, n_clients):
# 同态加法
weighted_grad = weights[client_idx] * encrypted_param_gradients[client_idx]['data'][i]
weighted_sum += weighted_grad
aggregated_data.append(weighted_sum)
aggregated_param['data'] = aggregated_data
aggregated_gradients[name] = aggregated_param
return aggregated_gradients
def update_global_model(self, aggregated_encrypted_gradients):
"""
使用聚合的加密梯度更新全局模型
参数:
aggregated_encrypted_gradients: 聚合后的加密梯度
"""
if not aggregated_encrypted_gradients:
return
# 解密聚合的梯度
start_time = time.time()
decrypted_gradients = self.crypto.decrypt_model_gradients(aggregated_encrypted_gradients)
decryption_time = time.time() - start_time
self.communication_overhead['decryption_time'] += decryption_time
print(f'Aggregated gradients decrypted. Decryption time: {decryption_time:.2f} seconds')
# 更新全局模型参数
with torch.no_grad():
for name, param in self.global_model.named_parameters():
if name in decrypted_gradients:
# 应用梯度更新: 参数 = 参数 - 梯度
param.sub_(decrypted_gradients[name])
def _calculate_size(self, obj):
"""计算对象的大致大小(字节)"""
return len(pickle.dumps(obj))
def _simulate_communication(self, data_size):
"""模拟通信延迟"""
# 假设带宽为10MB/s
bandwidth = 10 * 1024 * 1024 # bytes per second
# 计算传输时间
transmission_time = data_size / bandwidth
# 添加一些网络延迟(50-200ms)
latency = np.random.uniform(0.05, 0.2)
# 总通信时间
comm_time = transmission_time + latency
self.communication_overhead['communication_time'] += comm_time
# 可选:实际等待以模拟延迟
# time.sleep(comm_time)
return comm_time
def get_communication_stats(self):
"""获取通信统计信息"""
stats = self.communication_overhead.copy()
# 转换大小为MB
stats['encrypted_size_mb'] = stats['encrypted_size'] / (1024 * 1024)
stats['decrypted_size_mb'] = stats['decrypted_size'] / (1024 * 1024)
# 计算加密膨胀率
if stats['decrypted_size'] > 0:
stats['expansion_ratio'] = stats['encrypted_size'] / stats['decrypted_size']
else:
stats['expansion_ratio'] = 0
return stats
# 简单MLP模型用于测试
class SimpleMLP(torch.nn.Module):
def __init__(self, input_dim=784, hidden_dim=128, output_dim=10):
super(SimpleMLP, self).__init__()
self.fc1 = torch.nn.Linear(input_dim, hidden_dim)
self.relu = torch.nn.ReLU()
self.fc2 = torch.nn.Linear(hidden_dim, output_dim)
def forward(self, x):
x = x.view(x.size(0), -1)
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
return x
# 模拟同态加密联邦学习
def simulate_homomorphic_fl(num_clients=3, rounds=2, key_length=1024):
"""
模拟使用同态加密的联邦学习过程
参数:
num_clients: 客户端数量
rounds: 联邦学习轮数
key_length: 加密密钥长度
返回:
训练后的模型和通信统计信息
"""
print("初始化同态加密联邦学习系统...")
# 创建全局模型
global_model = SimpleMLP()
# 初始化同态加密系统
paillier_crypto = PaillierCrypto(key_length=key_length)
paillier_crypto.generate_keypair()
# 初始化联邦学习系统
he_fl = HomomorphicFederatedLearning(global_model, crypto=paillier_crypto)
# 创建模拟数据集
client_data = [create_dummy_data() for _ in range(num_clients)]
client_weights = [1.0 / num_clients] * num_clients # 等权重
# 联邦学习过程
for round_num in range(rounds):
print(f"\n=== 联邦学习轮次 {round_num+1}/{rounds} ===")
# 收集所有客户端的加密梯度
encrypted_gradients = []
for client_id in range(num_clients):
print(f"\n训练客户端 {client_id+1}...")
client_encrypted_grads = he_fl.train_client(client_id, client_data[client_id])
encrypted_gradients.append(client_encrypted_grads)
# 聚合加密梯度
print("\n聚合加密梯度...")
aggregated_encrypted_grads = he_fl.aggregate_encrypted_gradients(encrypted_gradients, client_weights)
# 更新全局模型
print("\n更新全局模型...")
he_fl.update_global_model(aggregated_encrypted_grads)
# 打印通信统计信息
stats = he_fl.get_communication_stats()
print(f"\n当前通信统计:")
print(f"加密数据大小: {stats['encrypted_size_mb']:.2f} MB")
print(f"未加密数据大小: {stats['decrypted_size_mb']:.2f} MB")
print(f"加密膨胀率: {stats['expansion_ratio']:.2f}x")
print(f"加密时间: {stats['encryption_time']:.2f} 秒")
print(f"解密时间: {stats['decryption_time']:.2f} 秒")
print(f"通信时间: {stats['communication_time']:.2f} 秒")
return global_model, he_fl.get_communication_stats()
# 创建模拟数据
def create_dummy_data(n_samples=20, input_dim=784, n_classes=10):
"""创建模拟数据集用于测试"""
X = torch.randn(n_samples, input_dim)
y = torch.randint(0, n_classes, (n_samples,))
dataset = torch.utils.data.TensorDataset(X, y)
dataloader = torch.utils.data.DataLoader(dataset, batch_size=5, shuffle=True)
return dataloader
复制代码
上面的代码实现了基于Paillier同态加密的联邦学习体系,重点关注了通信开销。如今让我们转向安全多方计算的实现。
2. 安全多方计算基础
安全多方计算(MPC)允很多方在不泄露各自私有输入的情况下共同计算函数。在联邦学习中,MPC可用于安全聚合客户端梯度或模子更新。
2.1 MPC主要协议
秘密共享(Secret Sharing)
:将私有数据分割为"份额"分发给多方
混淆电路(Garbled Circuits)
:将函数表现为加密的布尔电路
同态秘密共享(Homomorphic Secret Sharing)
:结合同态特性的秘密共享
2.2 基于秘密共享的MPC实现
下面我们实现一个基于加法秘密共享的安全聚合体系:
import numpy as np
import torch
import time
import pickle
import os
import matplotlib.pyplot as plt
from collections import OrderedDict
class SecretSharing:
"""基于加法秘密共享的实现"""
@staticmethod
def generate_shares(secret, n_shares):
"""
将秘密分割为n份
参数:
secret: 秘密值
n_shares: 份额数量
返回:
生成的份额列表
"""
# 生成n-1个随机份额
shares = [np.random.random() for _ in range(n_shares - 1)]
# 计算最后一个份额,使得所有份额之和等于秘密
last_share = secret - sum(shares)
shares.append(last_share)
return shares
@staticmethod
def reconstruct_secret(shares):
"""
从份额重构秘密
参数:
shares: 份额列表
返回:
重构的秘密
"""
return sum(shares)
@staticmethod
def generate_vector_shares(vector, n_shares):
"""
为向量中的每个元素生成份额
参数:
vector: 向量
n_shares: 份额数量
返回:
向量份额列表
"""
if isinstance(vector, torch.Tensor):
vector = vector.cpu().numpy().flatten()
else:
vector = np.array(vector).flatten()
# 为每个元素生成份额
shares = [np.zeros_like(vector) for _ in range(n_shares)]
for i in range(len(vector)):
element_shares = SecretSharing.generate_shares(vector[i], n_shares)
for j in range(n_shares):
shares[j][i] = element_shares[j]
return shares
@staticmethod
def reconstruct_vector(vector_shares):
"""
从向量份额重构向量
参数:
vector_shares: 向量份额列表
返回:
重构的向量
"""
# 确保所有份额具有相同的形状
shapes = [share.shape for share in vector_shares]
if len(set(shapes)) > 1:
raise ValueError("所有份额必须具有相同的形状")
# 元素级别的重构
reconstructed = np.zeros_like(vector_shares[0])
for i in range(len(reconstructed)):
element_shares = [share[i] for share in vector_shares]
reconstructed[i] = SecretSharing.reconstruct_secret(element_shares)
return reconstructed
class SecureAggregation:
"""基于秘密共享的安全聚合"""
def __init__(self, n_clients):
"""
初始化安全聚合系统
参数:
n_clients: 客户端数量
"""
self.n_clients = n_clients
# 跟踪通信开销
self.communication_overhead = {
'shared_size': 0,
'original_size': 0,
'sharing_time': 0,
'reconstruction_time': 0,
'communication_time': 0
}
def share_gradients(self, gradients):
"""
对梯度进行秘密共享
参数:
gradients: 客户端梯度字典
返回:
秘密共享的梯度
"""
# 测量原始梯度大小
original_size = self._calculate_size(gradients)
self.communication_overhead['original_size'] += original_size
# 为每个参数创建秘密份额
start_time = time.time()
shared_gradients = OrderedDict()
for name, grad in gradients.items():
# 转换为NumPy数组
grad_np = grad.cpu().numpy()
shape = grad_np.shape
# 为每个参数生成份额
grad_shares = SecretSharing.generate_vector_shares(grad_np, self.n_clients)
# 存储参数份额
for i in range(self.n_clients):
if i not in shared_gradients:
shared_gradients[i] = OrderedDict()
shared_gradients[i][name] = {
'shape': shape,
'share': grad_shares[i]
}
sharing_time = time.time() - start_time
self.communication_overhead['sharing_time'] += sharing_time
# 测量份额大小
shared_size = self._calculate_size(shared_gradients)
self.communication_overhead['shared_size'] += shared_size
# 模拟通信延迟
self._simulate_communication(shared_size)
print(f'梯度已共享。大小: {original_size/1024:.2f} KB -> {shared_size/1024:.2f} KB')
print(f'共享时间: {sharing_time:.2f} 秒')
return shared_gradients
def aggregate_shared_gradients(self, all_client_shares):
"""
聚合来自所有客户端的共享梯度
参数:
all_client_shares: 所有客户端的共享梯度列表
返回:
聚合后的梯度
"""
if not all_client_shares:
return None
# 重组份额结构
client_shares = OrderedDict()
for client_id, shares in enumerate(all_client_shares):
for receiver_id, params in shares.items():
if receiver_id not in client_shares:
client_shares[receiver_id] = []
client_shares[receiver_id].append(params)
# 每个客户端聚合自己收到的份额
aggregated_shares = OrderedDict()
for receiver_id, received_shares in client_shares.items():
# 确保每个接收者都收到了所有客户端的份额
if len(received_shares) != len(all_client_shares):
raise ValueError(f"客户端 {receiver_id} 未收到所有份额")
# 聚合每个参数的份额
agg_params = OrderedDict()
# 获取参数名称(假设所有客户端具有相同的参数)
param_names = received_shares[0].keys()
for name in param_names:
# 获取此参数所有份额的形状
shape = received_shares[0][name]['shape']
# 初始化聚合结果
agg_param = np.zeros(shape)
# 聚合此参数的所有份额
for client_shares in received_shares:
share = client_shares[name]['share']
# 安全地聚合份额(加法)
agg_param += share
agg_params[name] = {
'shape': shape,
'share': agg_param
}
aggregated_shares[receiver_id] = agg_params
# 重构聚合后的秘密
start_time = time.time()
reconstructed_gradients = OrderedDict()
# 获取参数名称
param_names = next(iter(aggregated_shares.values())).keys()
for name in param_names:
# 获取此参数所有份额
param_shares = [client_agg[name]['share'] for client_agg in aggregated_shares.values()]
shape = aggregated_shares[next(iter(aggregated_shares))][name]['shape']
# 重构参数
reconstructed = SecretSharing.reconstruct_vector(param_shares)
# 转换为PyTorch张量
reconstructed_gradients[name] = torch.tensor(reconstructed.reshape(shape))
reconstruction_time = time.time() - start_time
self.communication_overhead['reconstruction_time'] += reconstruction_time
print(f'梯度已重构。重构时间: {reconstruction_time:.2f} 秒')
return reconstructed_gradients
def _calculate_size(self, obj):
"""计算对象的大致大小(字节)"""
return len(pickle.dumps(obj))
def _simulate_communication(self, data_size):
"""模拟通信延迟"""
# 假设带宽为20MB/s (MPC通常需要更多带宽)
bandwidth = 20 * 1024 * 1024 # bytes per second
# 计算传输时间
transmission_time = data_size / bandwidth
# 添加一些网络延迟(50-200ms)
latency = np.random.uniform(0.05, 0.2)
# 总通信时间
comm_time = transmission_time + latency
self.communication_overhead['communication_time'] += comm_time
return comm_time
def get_communication_stats(self):
"""获取通信统计信息"""
stats = self.communication_overhead.copy()
# 转换大小为MB
stats['shared_size_mb'] = stats['shared_size'] / (1024 * 1024)
stats['original_size_mb'] = stats['original_size'] / (1024 * 1024)
# 计算扩展率
if stats['original_size'] > 0:
stats['expansion_ratio'] = stats['shared_size'] / stats['original_size']
else:
stats['expansion_ratio'] = 0
return stats
class MPCFederatedLearning:
"""基于安全多方计算的联邦学习系统"""
def __init__(self, global_model, num_clients=3):
"""
初始化MPC联邦学习系统
参数:
global_model: 全局PyTorch模型
num_clients: 客户端数量
"""
self.global_model = global_model
self.num_clients = num_clients
# 初始化安全聚合系统
self.secure_aggregator = SecureAggregation(n_clients=num_clients)
# 为每个客户端创建本地模型
self.client_models = [type(global_model)() for _ in range(num_clients)]
for client_model in self.client_models:
client_model.load_state_dict(global_model.state_dict())
def train_client(self, client_id, dataloader, epochs=1, lr=0.01):
"""
训练单个客户端模型
参数:
client_id: 客户端ID
dataloader: 客户端本地数据加载器
epochs: 本地训练轮数
lr: 学习率
返回:
客户端梯度更新
"""
model = self.client_models[client_id]
model.train()
optimizer = torch.optim.SGD(model.parameters(), lr=lr)
criterion = torch.nn.CrossEntropyLoss()
for epoch in range(epochs):
epoch_loss = 0
for data, target in dataloader:
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
epoch_loss += loss.item()
print(f'Client {client_id}, Epoch {epoch+1}/{epochs}, Loss: {epoch_loss/len(dataloader):.4f}')
# 计算梯度更新 (全局模型参数 - 本地更新后的参数)
gradient_updates = OrderedDict()
for name, param in self.global_model.named_parameters():
client_param = dict(model.named_parameters())[name]
gradient_updates[name] = param.data - client_param.data
return gradient_updates
def secure_aggregation(self, all_client_gradients):
"""
安全聚合所有客户端的梯度
参数:
all_client_gradients: 所有客户端的梯度更新列表
返回:
聚合后的梯度
"""
# 为每个客户端的梯度创建秘密共享
all_shared_gradients = []
for client_id, gradients in enumerate(all_client_gradients):
print(f"为客户端 {client_id} 创建秘密共享...")
shared_gradients = self.secure_aggregator.share_gradients(gradients)
all_shared_gradients.append(shared_gradients)
# 聚合共享的梯度
print("安全聚合梯度...")
aggregated_gradients = self.secure_aggregator.aggregate_shared_gradients(all_shared_gradients)
return aggregated_gradients
def update_global_model(self, aggregated_gradients):
"""
使用聚合的梯度更新全局模型
参数:
aggregated_gradients: 聚合后的梯度
"""
if not aggregated_gradients:
return
# 更新全局模型参数
with torch.no_grad():
for name, param in self.global_model.named_parameters():
if name in aggregated_gradients:
# 应用梯度更新: 参数 = 参数 - 梯度
param.sub_(aggregated_gradients[name])
# 更新客户端模型
for client_model in self.client_models:
client_model.load_state_dict(self.global_model.state_dict())
def train_federated(self, client_dataloaders, rounds=2, local_epochs=1, lr=0.01):
"""
执行联邦学习训练
参数:
client_dataloaders: 每个客户端的数据加载器
rounds: 联邦学习轮数
local_epochs: 每轮本地训练的轮数
lr: 学习率
返回:
训练后的全局模型
"""
for round_num in range(rounds):
print(f"\n=== 联邦学习轮次 {round_num+1}/{rounds} ===")
# 收集所有客户端的梯度
all_client_gradients = []
for client_id in range(self.num_clients):
print(f"\n训练客户端 {client_id+1}...")
client_gradients = self.train_client(
client_id, client_dataloaders[client_id],
epochs=local_epochs, lr=lr
)
all_client_gradients.append(client_gradients)
# 安全聚合梯度
print("\n安全聚合梯度...")
aggregated_gradients = self.secure_aggregation(all_client_gradients)
# 更新全局模型
print("\n更新全局模型...")
self.update_global_model(aggregated_gradients)
# 打印通信统计信息
stats = self.secure_aggregator.get_communication_stats()
print(f"\n当前通信统计:")
print(f"共享数据大小: {stats['shared_size_mb']:.2f} MB")
print(f"原始数据大小: {stats['original_size_mb']:.2f} MB")
print(f"扩展率: {stats['expansion_ratio']:.2f}x")
print(f"共享时间: {stats['sharing_time']:.2f} 秒")
print(f"重构时间: {stats['reconstruction_time']:.2f} 秒")
print(f"通信时间: {stats['communication_time']:.2f} 秒")
return self.global_model, self.secure_aggregator.get_communication_stats()
# 模拟基于MPC的联邦学习
def simulate_mpc_fl(num_clients=3, rounds=2):
"""
模拟基于MPC的联邦学习过程
参数:
num_clients: 客户端数量
rounds: 联邦学习轮数
返回:
训练后的模型和通信统计信息
"""
print("初始化MPC联邦学习系统...")
# 创建全局模型
global_model = SimpleMLP()
# 初始化MPC联邦学习系统
mpc_fl = MPCFederatedLearning(global_model, num_clients=num_clients)
# 创建模拟数据集
client_data = [create_dummy_data() for _ in range(num_clients)]
# 联邦学习过程
model, stats = mpc_fl.train_federated(
client_dataloaders=client_data,
rounds=rounds,
local_epochs=1,
lr=0.01
)
return model, stats
# 比较两种方法的通信开销
def compare_communication_overhead():
"""比较同态加密和MPC的通信开销"""
print("\n=== 比较同态加密和MPC的通信开销 ===\n")
# 运行同态加密联邦学习
print("运行同态加密联邦学习...")
_, he_stats = simulate_homomorphic_fl(num_clients=3, rounds=2, key_length=1024)
# 运行MPC联邦学习
print("\n运行MPC联邦学习...")
_, mpc_stats = simulate_mpc_fl(num_clients=3, rounds=2)
# 比较结果
print("\n=== 通信开销比较 ===")
print(f"同态加密:")
print(f" - 加密数据大小: {he_stats['encrypted_size_mb']:.2f} MB")
print(f" - 未加密数据大小: {he_stats['decrypted_size_mb']:.2f} MB")
print(f" - 加密膨胀率: {he_stats['expansion_ratio']:.2f}x")
print(f" - 加密+解密时间: {he_stats['encryption_time'] + he_stats['decryption_time']:.2f} 秒")
print(f" - 通信时间: {he_stats['communication_time']:.2f} 秒")
print(f"\nMPC (秘密共享):")
print(f" - 共享数据大小: {mpc_stats['shared_size_mb']:.2f} MB")
print(f" - 原始数据大小: {mpc_stats['original_size_mb']:.2f} MB")
print(f" - 扩展率: {mpc_stats['expansion_ratio']:.2f}x")
print(f" - 共享+重构时间: {mpc_stats['sharing_time'] + mpc_stats['reconstruction_time']:.2f} 秒")
print(f" - 通信时间: {mpc_stats['communication_time']:.2f} 秒")
# 绘制比较图
plt.figure(figsize=(15, 10))
# 数据大小比较
plt.subplot(2, 2, 1)
sizes = [he_stats['encrypted_size_mb'], mpc_stats['shared_size_mb']]
original_sizes = [he_stats['decrypted_size_mb'], mpc_stats['original_size_mb']]
labels = ['同态加密', 'MPC']
x = np.arange(len(labels))
width = 0.35
plt.bar(x - width/2, sizes, width, label='加密/共享数据')
plt.bar(x + width/2, original_sizes, width, label='原始数据')
plt.xlabel('方法')
plt.ylabel('数据大小 (MB)')
plt.title('数据大小比较')
plt.xticks(x, labels)
plt.legend()
# 扩展率比较
plt.subplot(2, 2, 2)
expansion_ratios = [he_stats['expansion_ratio'], mpc_stats['expansion_ratio']]
plt.bar(labels, expansion_ratios)
plt.xlabel('方法')
plt.ylabel('扩展率')
plt.title('扩展率比较')
# 处理时间比较
plt.subplot(2, 2, 3)
he_process_time = he_stats['encryption_time'] + he_stats['decryption_time']
mpc_process_time = mpc_stats['sharing_time'] + mpc_stats['reconstruction_time']
process_times = [he_process_time, mpc_process_time]
plt.bar(labels, process_times)
plt.xlabel('方法')
plt.ylabel('处理时间 (秒)')
plt.title('加密/共享处理时间比较')
# 通信时间比较
plt.subplot(2, 2, 4)
comm_times = [he_stats['communication_time'], mpc_stats['communication_time']]
plt.bar(labels, comm_times)
plt.xlabel('方法')
plt.ylabel('通信时间 (秒)')
plt.title('通信时间比较')
plt.tight_layout()
plt.savefig('he_vs_mpc_comparison.png')
plt.show()
return he_stats, mpc_stats
if __name__ == "__main__":
compare_communication_overhead()
复制代码
3. 同态加密与安全多方计算的通信开销对比
如今让我们具体分析同态加密和安全多方计算在联邦学习中的通信开销,并绘制这些通信流程图以清楚地展示各自的特点。
3.1 通信模式对比
让我们通过表格来比较同态加密和安全多方计算的通信特点:
特性同态加密安全多方计算通信拓扑星型(客户端-服务器)网格型(全连接或环形)通信轮次2轮(发送加密梯度,接收更新模子)2-3轮(分发份额,接收结果)通信量随客户端数量变化线性增长平方级增长单点故障风险高(服务器)低(分布式)数据扩展率非常高 (10-100倍)中等 (n倍,n为到场方数量)
3.2 具体通信开销分析
3.2.1 同态加密通信开销
以下是同态加密在联邦学习中的通信开销分析:
def analyze_he_overhead(param_sizes=[1000, 10000, 100000], key_lengths=[1024, 2048, 4096]):
"""分析不同参数大小和密钥长度下的同态加密开销"""
results = []
for param_size in param_sizes:
for key_length in key_lengths:
# 创建随机参数
params = torch.randn(param_size)
# 初始化同态加密系统
paillier_crypto = PaillierCrypto(key_length=key_length)
paillier_crypto.generate_keypair()
# 测量加密时间和大小
start_time = time.time()
encrypted_params = paillier_crypto.encrypt_vector(params)
encryption_time = time.time() - start_time
# 测量解密时间
start_time = time.time()
decrypted_params = paillier_crypto.decrypt_vector(encrypted_params)
decryption_time = time.time() - start_time
# 测量大小
original_size = len(pickle.dumps(params))
encrypted_size = len(pickle.dumps(encrypted_params))
# 记录结果
results.append({
'param_size': param_size,
'key_length': key_length,
'encryption_time': encryption_time,
'decryption_time': decryption_time,
'original_size': original_size,
'encrypted_size': encrypted_size,
'expansion_ratio': encrypted_size / original_size
})
print(f"参数大小: {param_size}, 密钥长度: {key_length}")
print(f" 加密时间: {encryption_time:.2f}秒, 解密时间: {decryption_time:.2f}秒")
print(f" 原始大小: {original_size/1024:.2f}KB, 加密大小: {encrypted_size/1024:.2f}KB")
print(f" 扩展率: {encrypted_size/original_size:.2f}x")
# 绘制结果
plt.figure(figsize=(15, 10))
# 按参数大小分组
for param_size in param_sizes:
param_results = [r for r in results if r['param_size'] == param_size]
key_lengths = [r['key_length'] for r in param_results]
expansion_ratios = [r['expansion_ratio'] for r in param_results]
plt.subplot(2, 2, 1)
plt.plot(key_lengths, expansion_ratios, marker='o', label=f'{param_size} 参数')
plt.xlabel('密钥长度')
plt.ylabel('扩展率')
plt.title('同态加密扩展率 vs. 密钥长度')
plt.legend()
plt.grid(True)
# 加密时间
for param_size in param_sizes:
param_results = [r for r in results if r['param_size'] == param_size]
key_lengths = [r['key_length'] for r in param_results]
encryption_times = [r['encryption_time'] for r in param_results]
plt.subplot(2, 2, 2)
plt.plot(key_lengths, encryption_times, marker='o', label=f'{param_size} 参数')
plt.xlabel('密钥长度')
plt.ylabel('加密时间 (秒)')
plt.title('加密时间 vs. 密钥长度')
plt.legend()
plt.grid(True)
# 通信开销
param_sizes_log = np.log10(param_sizes)
encrypted_sizes = [r['encrypted_size']/1024/1024 for r in results if r['key_length'] == 2048]
plt.subplot(2, 2, 3)
plt.plot(param_sizes_log, encrypted_sizes, marker='o')
plt.xlabel('参数大小 (log10)')
plt.ylabel('加密大小 (MB)')
plt.title('加密大小 vs. 参数大小 (2048位密钥)')
plt.grid(True)
plt.tight_layout()
plt.savefig('he_overhead_analysis.png')
plt.show()
return results
复制代码
3.2.2 安全多方计算通信开销
下面分析安全多方计算在联邦学习中的通信开销:
def analyze_mpc_overhead(param_sizes=[1000, 10000, 100000], n_clients_list=[2, 3, 5, 10]):
"""分析不同参数大小和客户端数量下的MPC开销"""
results = []
for param_size in param_sizes:
for n_clients in n_clients_list:
# 创建随机参数
params = torch.randn(param_size)
# 测量共享时间和大小
start_time = time.time()
shares = SecretSharing.generate_vector_shares(params, n_clients)
sharing_time = time.time() - start_time
# 测量重构时间
start_time = time.time()
reconstructed = SecretSharing.reconstruct_vector(shares)
reconstruction_time = time.time() - start_time
# 测量大小
original_size = len(pickle.dumps(params))
shared_size = len(pickle.dumps(shares))
# 记录结果
results.append({
'param_size': param_size,
'n_clients': n_clients,
'sharing_time': sharing_time,
'reconstruction_time': reconstruction_time,
'original_size': original_size,
'shared_size': shared_size,
'expansion_ratio': shared_size / original_size
})
print(f"参数大小: {param_size}, 客户端数量: {n_clients}")
print(f" 共享时间: {sharing_time:.2f}秒, 重构时间: {reconstruction_time:.2f}秒")
print(f" 原始大小: {original_size/1024:.2f}KB, 共享大小: {shared_size/1024:.2f}KB")
print(f" 扩展率: {shared_size/original_size:.2f}x")
# 绘制结果
plt.figure(figsize=(15, 10))
# 按参数大小分组
for param_size in param_sizes:
param_results = [r for r in results if r['param_size'] == param_size]
n_clients_list = [r['n_clients'] for r in param_results]
expansion_ratios = [r['expansion_ratio'] for r in param_results]
plt.subplot(2, 2, 1)
plt.plot(n_clients_list, expansion_ratios, marker='o', label=f'{param_size} 参数')
plt.xlabel('客户端数量')
plt.ylabel('扩展率')
plt.title('MPC扩展率 vs. 客户端数量')
plt.legend()
plt.grid(True)
# 共享时间
for param_size in param_sizes:
param_results = [r for r in results if r['param_size'] == param_size]
n_clients_list = [r['n_clients'] for r in param_results]
sharing_times = [r['sharing_time'] for r in param_results]
plt.subplot(2, 2, 2)
plt.plot(n_clients_list, sharing_times, marker='o', label=f'{param_size} 参数')
plt.xlabel('客户端数量')
plt.ylabel('共享时间 (秒)')
plt.title('共享时间 vs. 客户端数量')
plt.legend()
plt.grid(True)
# 总通信量
total_comm = []
for r in results:
if r['param_size'] == param_sizes[1]: # 选择中等参数大小
total_bytes = r['shared_size'] * r['n_clients'] # 每个客户端发送份额给所有其他客户端
total_comm.append(total_bytes / 1024 / 1024) # MB
plt.subplot(2, 2, 3)
plt.plot(n_clients_list, total_comm, marker='o')
plt.xlabel('客户端数量')
plt.ylabel('总通信量 (MB)')
plt.title('总通信量 vs. 客户端数量')
plt.grid(True)
plt.tight_layout()
plt.savefig('mpc_overhead_analysis.png')
plt.show()
return results
复制代码
4. 同态加密与安全多方计算的综合对比
让我们对两种技术进行全面对比,从多个维度分析它们的优缺点:
4.1 两种方法的全面对比表
特性同态加密安全多方计算说明
通信开销
单轮通信量大(约10-100倍原始数据)中等(约n倍原始数据)HE数据膨胀更严重通信轮次少(通常2轮)多(取决于协议,2-4轮)MPC大概必要多轮交互网络拓扑需求星形(中央折务器)网状(点对点连接)MPC必要更复杂的网络架构通信复杂度O(n),n为客户端数量O(n²),n为客户端数量MPC通信量随客户端数量平方增长
计算开销
计算复杂度很高(加密运算昂贵)中等HE计算开销显着更大加密/共享时间长(秒到分钟级)短(毫秒到秒级)HE加密时间显著更长操作复杂性乘法开销很大,有深度限定乘法复杂但可实现HE乘法运算特别昂贵客户端资源需求中等高(必要处理多方交互)MPC客户端负担更重
安全特性
安全假设计算复杂性假设部门诚实到场者假设安全基础差别反抗合谋攻击强(即使服务器和客户端合谋)中等(依赖不合谋假设)HE防合谋性更好容错性弱(中央折务器故障影响全局)强(可容忍部门节点失效)MPC容错性更好隐私包管强度很强(加密数据完全不可知)强(只有全部到场方合谋才能破解)HE隐私包管略强
实用性
实现复杂度中等高MPC协议实现更复杂可扩展性弱(难以扩展到大量到场者)中等MPC扩展性稍好与DP兼容性好(可直接组合)好(可直接组合)两者都可与DP结合成熟度中等较高MPC有更多现实部署案例
4.2 通信开销与计算效率的权衡
同态加密和安全多方计算在通信开销和计算效率上存在显着的权衡。以下代码对比了差别模子大小下两种方法的总开销:
def compare_total_overhead(model_sizes, num_clients):
"""
比较不同模型大小下HE和MPC的总通信和计算开销
参数:
model_sizes: 模型参数数量列表
num_clients: 客户端数量
"""
results = {
'he': [],
'mpc': []
}
# 定义基准性能参数(基于实验观察)
he_params = {
'encryption_time_per_param': 1e-5, # 每个参数的加密时间(秒)
'decryption_time_per_param': 5e-6, # 每个参数的解密时间(秒)
'expansion_ratio': 20.0, # 加密数据膨胀率
'bandwidth': 10 * 1024 * 1024 # 带宽 (10 MB/s)
}
mpc_params = {
'sharing_time_per_param': 2e-6, # 每个参数的共享时间(秒)
'reconstruction_time_per_param': 1e-6, # 每个参数的重构时间(秒)
'expansion_ratio_per_client': 1.5, # 每个客户端的数据膨胀率
'bandwidth': 10 * 1024 * 1024 # 带宽 (10 MB/s)
}
for size in model_sizes:
# 计算HE开销
he_encryption_time = size * he_params['encryption_time_per_param'] * num_clients
he_decryption_time = size * he_params['decryption_time_per_param']
he_original_data_size = size * 4 # 假设每个参数为4字节的浮点数
he_encrypted_data_size = he_original_data_size * he_params['expansion_ratio']
he_communication_time = (he_encrypted_data_size * num_clients) / he_params['bandwidth']
he_total_time = he_encryption_time + he_decryption_time + he_communication_time
# 计算MPC开销
mpc_sharing_time = size * mpc_params['sharing_time_per_param'] * num_clients
mpc_reconstruction_time = size * mpc_params['reconstruction_time_per_param'] * num_clients
mpc_original_data_size = size * 4 # 同上
mpc_shared_data_size = mpc_original_data_size * mpc_params['expansion_ratio_per_client'] * num_clients
mpc_communication_time = (mpc_shared_data_size * num_clients) / mpc_params['bandwidth']
mpc_total_time = mpc_sharing_time + mpc_reconstruction_time + mpc_communication_time
results['he'].append({
'model_size': size,
'encryption_time': he_encryption_time,
'decryption_time': he_decryption_time,
'communication_time': he_communication_time,
'total_time': he_total_time,
'data_size': he_encrypted_data_size / (1024 * 1024) # MB
})
results['mpc'].append({
'model_size': size,
'sharing_time': mpc_sharing_time,
'reconstruction_time': mpc_reconstruction_time,
'communication_time': mpc_communication_time,
'total_time': mpc_total_time,
'data_size': mpc_shared_data_size / (1024 * 1024) # MB
})
# 绘制结果
plt.figure(figsize=(15, 10))
# 总时间对比
plt.subplot(2, 2, 1)
plt.plot([r['model_size'] for r in results['he']],
[r['total_time'] for r in results['he']],
'b-', marker='o', label='同态加密')
plt.plot([r['model_size'] for r in results['mpc']],
[r['total_time'] for r in results['mpc']],
'r-', marker='s', label='安全多方计算')
plt.xlabel('模型大小(参数数量)')
plt.ylabel('总时间(秒)')
plt.title(f'总开销比较({num_clients}个客户端)')
plt.legend()
plt.grid(True)
plt.xscale('log')
plt.yscale('log')
# 数据大小对比
plt.subplot(2, 2, 2)
plt.plot([r['model_size'] for r in results['he']],
[r['data_size'] for r in results['he']],
'b-', marker='o', label='同态加密')
plt.plot([r['model_size'] for r in results['mpc']],
[r['data_size'] for r in results['mpc']],
'r-', marker='s', label='安全多方计算')
plt.xlabel('模型大小(参数数量)')
plt.ylabel('数据大小(MB)')
plt.title('通信数据大小比较')
plt.legend()
plt.grid(True)
plt.xscale('log')
plt.yscale('log')
# 计算与通信时间细分 - HE
plt.subplot(2, 2, 3)
he_comp_times = [r['encryption_time'] + r['decryption_time'] for r in results['he']]
he_comm_times = [r['communication_time'] for r in results['he']]
plt.bar([str(r['model_size']) for r in results['he']],
he_comp_times,
label='计算时间',
alpha=0.7)
plt.bar([str(r['model_size']) for r in results['he']],
he_comm_times,
bottom=he_comp_times,
label='通信时间',
alpha=0.7)
plt.xlabel('模型大小(参数数量)')
plt.ylabel('时间(秒)')
plt.title('同态加密时间细分')
plt.legend()
plt.xticks(rotation=45)
# 计算与通信时间细分 - MPC
plt.subplot(2, 2, 4)
mpc_comp_times = [r['sharing_time'] + r['reconstruction_time'] for r in results['mpc']]
mpc_comm_times = [r['communication_time'] for r in results['mpc']]
plt.bar([str(r['model_size']) for r in results['mpc']],
mpc_comp_times,
label='计算时间',
alpha=0.7)
plt.bar([str(r['model_size']) for r in results['mpc']],
mpc_comm_times,
bottom=mpc_comp_times,
label='通信时间',
alpha=0.7)
plt.xlabel('模型大小(参数数量)')
plt.ylabel('时间(秒)')
plt.title('安全多方计算时间细分')
plt.legend()
plt.xticks(rotation=45)
plt.tight_layout()
plt.savefig('he_vs_mpc_total_overhead.png')
plt.show()
return results
# 调用函数比较不同模型大小下的总开销
model_sizes = [1000, 10000, 100000, 1000000] # 从小模型到大模型
num_clients = 5
overhead_results = compare_total_overhead(model_sizes, num_clients)
复制代码
5. 差别隐私保护技术的组合应用
在现实应用中,同态加密和安全多方计算常常与差分隐私一起使用,下面我们将探讨如何组合这些技术来实现更强的隐私保护。
5.1 HE+DP组合方案
下面实现了一个将同态加密与差分隐私相结合的联邦学习方案:
class HEWithDPFederatedLearning:
"""结合同态加密和差分隐私的联邦学习系统"""
def __init__(self, global_model, crypto=None, key_length=2048, epsilon=1.0, delta=1e-5, clip_norm=1.0):
"""
初始化结合HE和DP的联邦学习系统
参数:
global_model: 全局PyTorch模型
crypto: 可选的PaillierCrypto实例
key_length: 密钥长度
epsilon: 差分隐私参数ε
delta: 差分隐私参数δ
clip_norm: 梯度裁剪阈值
"""
self.global_model = global_model
# 初始化加密系统
if crypto:
self.crypto = crypto
else:
self.crypto = PaillierCrypto(key_length=key_length)
self.crypto.generate_keypair()
# 差分隐私参数
self.epsilon = epsilon
self.delta = delta
self.clip_norm = clip_norm
# 跟踪通信开销
self.communication_overhead = {
'encrypted_size': 0,
'decrypted_size': 0,
'encryption_time': 0,
'decryption_time': 0,
'communication_time': 0
}
def train_client_with_dp(self, client_id, dataloader, epochs=1, lr=0.01):
"""
使用差分隐私训练客户端模型
参数:
client_id: 客户端ID
dataloader: 客户端本地数据加载器
epochs: 本地训练轮数
lr: 学习率
返回:
加密后的带DP的梯度更新
"""
# 复制全局模型
client_model = type(self.global_model)()
client_model.load_state_dict(self.global_model.state_dict())
client_model.train()
optimizer = torch.optim.SGD(client_model.parameters(), lr=lr)
criterion = torch.nn.CrossEntropyLoss()
# 训练模型
for epoch in range(epochs):
epoch_loss = 0
for data, target in dataloader:
optimizer.zero_grad()
output = client_model(data)
loss = criterion(output, target)
loss.backward()
# 应用梯度裁剪(用于DP)
torch.nn.utils.clip_grad_norm_(client_model.parameters(), self.clip_norm)
optimizer.step()
epoch_loss += loss.item()
print(f'Client {client_id}, Epoch {epoch+1}/{epochs}, Loss: {epoch_loss/len(dataloader):.4f}')
# 计算梯度更新
gradient_updates = OrderedDict()
for name, param in self.global_model.named_parameters():
client_param = dict(client_model.named_parameters())[name]
gradient_updates[name] = param.data - client_param.data
# 测量未加密梯度的大小
unencrypted_size = len(pickle.dumps(gradient_updates))
self.communication_overhead['decrypted_size'] += unencrypted_size
# 加密梯度更新
start_time = time.time()
encrypted_updates = self.crypto.encrypt_model_gradients(gradient_updates)
encryption_time = time.time() - start_time
self.communication_overhead['encryption_time'] += encryption_time
# 测量加密梯度的大小
encrypted_size = len(pickle.dumps(encrypted_updates))
self.communication_overhead['encrypted_size'] += encrypted_size
print(f'Client {client_id} gradients encrypted with DP. Size: {unencrypted_size/1024:.2f} KB -> {encrypted_size/1024:.2f} KB')
return encrypted_updates
def aggregate_encrypted_gradients_with_dp(self, all_encrypted_gradients, weights=None, num_samples=None):
"""
聚合加密的梯度并添加差分隐私噪声
参数:
all_encrypted_gradients: 所有客户端的加密梯度
weights: 聚合权重
num_samples: 样本数量,用于缩放噪声
返回:
聚合后的加密梯度(带DP噪声)
"""
# 首先聚合加密梯度(和普通HE方法相同)
aggregated_encrypted_grads = self.aggregate_encrypted_gradients(all_encrypted_gradients, weights)
# 解密聚合的梯度
start_time = time.time()
decrypted_gradients = self.crypto.decrypt_model_gradients(aggregated_encrypted_grads)
decryption_time = time.time() - start_time
self.communication_overhead['decryption_time'] += decryption_time
# 添加差分隐私噪声
noisy_gradients = self.add_dp_noise(decrypted_gradients, num_samples)
# 再次加密带噪声的梯度(在实际应用中,这些带噪声的梯度会直接用于更新模型)
start_time = time.time()
encrypted_noisy_gradients = self.crypto.encrypt_model_gradients(noisy_gradients)
encryption_time = time.time() - start_time
self.communication_overhead['encryption_time'] += encryption_time
print(f'添加差分隐私噪声并重新加密梯度,解密时间: {decryption_time:.2f}秒, 加密时间: {encryption_time:.2f}秒')
return encrypted_noisy_gradients
def add_dp_noise(self, gradients, num_samples):
"""
添加差分隐私噪声到梯度
参数:
gradients: 解密后的梯度
num_samples: 样本数量,用于缩放噪声
返回:
带噪声的梯度
"""
if num_samples is None:
num_samples = 1
# 计算噪声标准差:σ = clip_norm * sqrt(2 * ln(1.25/δ)) / ε
noise_scale = self.clip_norm * np.sqrt(2 * np.log(1.25 / self.delta)) / self.epsilon
# 为每个参数添加噪声
noisy_gradients = OrderedDict()
for name, param in gradients.items():
# 添加高斯噪声
noise = torch.randn_like(param) * noise_scale / np.sqrt(num_samples)
noisy_gradients[name] = param + noise
return noisy_gradients
# 其他方法与HomomorphicFederatedLearning类似...
复制代码
5.2 MPC+DP组合方案
下面是一个结合安全多方计算和差分隐私的实现:
class MPCWithDPFederatedLearning:
"""结合安全多方计算和差分隐私的联邦学习系统"""
def __init__(self, global_model, num_clients=3, epsilon=1.0, delta=1e-5, clip_norm=1.0):
"""
初始化结合MPC和DP的联邦学习系统
参数:
global_model: 全局PyTorch模型
num_clients: 客户端数量
epsilon: 差分隐私参数ε
delta: 差分隐私参数δ
clip_norm: 梯度裁剪阈值
"""
self.global_model = global_model
self.num_clients = num_clients
# 差分隐私参数
self.epsilon = epsilon
self.delta = delta
self.clip_norm = clip_norm
# 初始化安全聚合系统
self.secure_aggregator = SecureAggregation(n_clients=num_clients)
# 为每个客户端创建本地模型
self.client_models = [type(global_model)() for _ in range(num_clients)]
for client_model in self.client_models:
client_model.load_state_dict(global_model.state_dict())
def train_client_with_dp(self, client_id, dataloader, epochs=1, lr=0.01):
"""
使用差分隐私训练客户端模型
参数:
client_id: 客户端ID
dataloader: 客户端本地数据加载器
epochs: 本地训练轮数
lr: 学习率
返回:
带DP的梯度更新
"""
model = self.client_models[client_id]
model.train()
optimizer = torch.optim.SGD(model.parameters(), lr=lr)
criterion = torch.nn.CrossEntropyLoss()
for epoch in range(epochs):
epoch_loss = 0
for data, target in dataloader:
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
# 应用梯度裁剪(用于DP)
torch.nn.utils.clip_grad_norm_(model.parameters(), self.clip_norm)
optimizer.step()
epoch_loss += loss.item()
print(f'Client {client_id}, Epoch {epoch+1}/{epochs}, Loss: {epoch_loss/len(dataloader):.4f}')
# 计算梯度更新
gradient_updates = OrderedDict()
for name, param in self.global_model.named_parameters():
client_param = dict(model.named_parameters())[name]
gradient_updates[name] = param.data - client_param.data
return gradient_updates
def secure_aggregation_with_dp(self, all_client_gradients, num_samples_list):
"""
安全聚合带DP的梯度
参数:
all_client_gradients: 所有客户端的梯度更新
num_samples_list: 每个客户端的样本数量列表
返回:
聚合后的带DP噪声的梯度
"""
# 创建均匀分配的噪声
total_samples = sum(num_samples_list)
# 计算噪声标准差:σ = clip_norm * sqrt(2 * ln(1.25/δ)) / ε
noise_scale = self.clip_norm * np.sqrt(2 * np.log(1.25 / self.delta)) / self.epsilon
# 每个客户端添加部分噪声
for client_id, gradients in enumerate(all_client_gradients):
# 计算此客户端应添加的噪声比例
noise_portion = num_samples_list[client_id] / total_samples
# 为每个参数添加部分噪声
for name, param in gradients.items():
# 添加缩放的高斯噪声
noise = torch.randn_like(param) * noise_scale * np.sqrt(noise_portion) / np.sqrt(total_samples)
gradients[name] = param + noise
# 使用普通的安全聚合
all_shared_gradients = []
for client_id, gradients in enumerate(all_client_gradients):
print(f"为客户端 {client_id} 创建秘密共享...")
shared_gradients = self.secure_aggregator.share_gradients(gradients)
all_shared_gradients.append(shared_gradients)
# 聚合共享的梯度
print("安全聚合梯度...")
aggregated_gradients = self.secure_aggregator.aggregate_shared_gradients(all_shared_gradients)
return aggregated_gradients
# 其他方法与MPCFederatedLearning类似...
复制代码
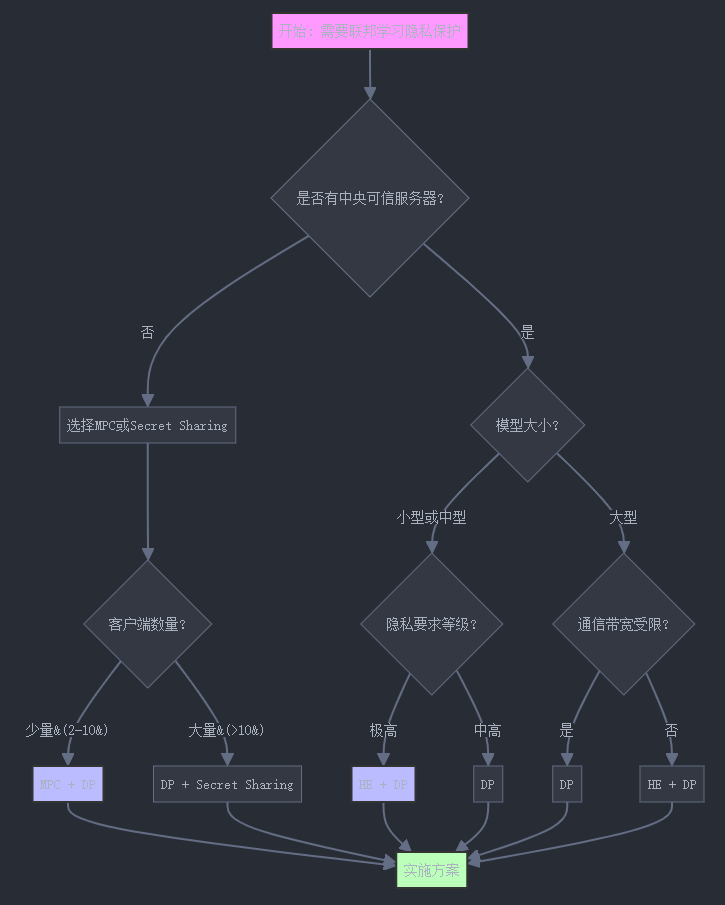
6. 选择最佳方法的决策框架
在决定使用哪种隐私保护技术时,必要思量多种因素。下面提供一个决策框架来帮助选择符合的方法:
6.1 决策流程图
6.2 选择技术的考量因素表
思量因素同态加密更适合的情况安全多方计算更适合的情况体系架构中央化服务器-客户端架构分布式点对点架构网络条件较低带宽,高延迟容忍高带宽,低延迟要求客户端数量较多客户端 (10-100+)较少客户端 (2-10)模子大小小到中等规模模子较小模子隐私要求必要极高隐私包管可接受半诚实假设计算资源服务器资源丰富客户端资源相对充足容错需求低容错要求高容错要求计算复杂度简单操作(主要是加法)复杂操作(包罗乘法)
7. 现实案例分析
下面是几个现实部署案例分析,展示差别场景下如何选择符合的隐私保护技术:
7.1 医疗机构联合建模案例
在多家医院合作进行疾病预测模子训练的场景中:
# 医疗联邦学习场景分析代码示例
def medical_federated_learning_case():
"""医疗机构联合建模案例分析"""
# 场景特点
scenario_features = {
'num_hospitals': 5, # 参与医院数量
'data_sensitivity': 'very high', # 数据敏感度(医疗数据)
'model_size': 'medium', # 模型大小(典型CNN)
'network_condition': 'good', # 网络条件(专用网络)
'computation_resources': 'high' # 计算资源(医院数据中心)
}
print("医疗机构联合建模案例分析:")
print("- 特点:")
for key, value in scenario_features.items():
print(f" * {key}: {value}")
print("\n- 推荐技术方案: HE + DP")
print("- 原因:")
print(" * 医疗数据高度敏感,需要最强的隐私保护")
print(" * 参与方数量适中,适合中心化聚合方案")
print(" * 模型规模中等,HE的计算开销可接受")
print(" * 医院通常有充足的计算资源处理加密操作")
print("\n- 具体实施:")
print(" * 使用阈值Paillier加密保护梯度")
print(" * 添加符合HIPAA标准的差分隐私噪声")
print(" * 设置保守的隐私预算 (ε < 1.0)")
print(" * 使用安全的密钥分发机制")
return "HE + DP"
# 分析不同场景对通信开销的影响
def analyze_medical_scenario_overhead():
"""分析医疗场景的通信开销"""
# 医疗场景的参数
model_params = 5 * 10**6 # 5百万参数
num_hospitals = 5
privacy_level = 'high' # 高隐私保护级别
# 模拟HE+DP的开销
if privacy_level == 'high':
# 高隐私保护(小ε)需要更多噪声
epsilon = 0.5
else:
epsilon = 2.0
# 计算HE开销
he_overhead = {
'encrypted_size_mb': (model_params * 4 * 20) / (1024 * 1024), # 20倍膨胀
'computation_time': model_params * 1e-5 * num_hospitals, # 加密时间
'communication_time': (model_params * 4 * 20 * num_hospitals) / (10 * 1024 * 1024), # 通信时间
'epsilon': epsilon
}
print(f"医疗场景 (ε={epsilon}) 的HE+DP开销估计:")
print(f" 加密数据大小: {he_overhead['encrypted_size_mb']:.2f} MB")
print(f" 计算时间: {he_overhead['computation_time']:.2f} 秒")
print(f" 通信时间: {he_overhead['communication_time']:.2f} 秒")
print(f" 总时间: {he_overhead['computation_time'] + he_overhead['communication_time']:.2f} 秒")
return he_overhead
复制代码
7.2 IoT装备联合学习案例
在大量资源受限的IoT装备上的联合学习场景:
def iot_federated_learning_case():
"""IoT设备联合学习案例分析"""
# 场景特点
scenario_features = {
'num_devices': 1000, # 参与设备数量
'data_sensitivity': 'medium', # 数据敏感度
'model_size': 'small', # 模型大小(轻量级模型)
'network_condition': 'poor', # 网络条件(不稳定,低带宽)
'computation_resources': 'low' # 计算资源(边缘设备)
}
print("IoT设备联合学习案例分析:")
print("- 特点:")
for key, value in scenario_features.items():
print(f" * {key}: {value}")
print("\n- 推荐技术方案: DP + 随机子采样")
print("- 原因:")
print(" * 设备数量大,完全MPC不可行")
print(" * 计算资源有限,HE开销过大")
print(" * 网络条件不佳,需要减少通信量")
print(" * 设备敏感度中等,DP可提供足够保护")
print("\n- 具体实施:")
print(" * 在设备端应用局部差分隐私")
print(" * 每轮随机选择一小部分设备参与")
print(" * 使用模型压缩减少通信量")
print(" * 使用安全聚合保护少量选中设备")
return "DP + 随机子采样"
复制代码
通过本文的具体分析和代码实现,我们深入对比了同态加密与安全多方计算在联邦学习中的通信开销。如今让我完成这个总结部门。
总结
同态加密适用于中央化架构,提供强盛的隐私保护但通信开销大;安全多方计算适用于去中央化架构,通信扩展性更好但必要多轮交互和点对点连接。差分隐私可以作为两种方法的补充,提供更全面的隐私保护。
在现实应用中,最佳方案通常是这些技术的组合,根据具体场景特点进行选择。例如,在高敏感度数据场景中,可以使用HE+DP组合;在到场方较少但计算能力强的场景中,可以选择MPC+DP方案;在大规模分布式体系中,大概更适合使用轻量级的DP方法配合安全聚合。
通信开销是选择隐私保护技术的关键因素之一。同态加密通常会导致10-100倍的数据膨胀,而安全多方计算的数据膨胀与到场方数量成正比。在带宽受限的环境中,这些通信开销大概成为现实部署的瓶颈。
拓展资源
PySyft:用于隐私保护机器学习的Python库,支持HE、MPC和DP
TensorFlow Privacy:Google开辟的差分隐私工具包
TensorFlow Encrypted:基于TensorFlow的加密计算框架
Crypten:Facebook的MPC框架,用于隐私保护机器学习
PySeal:Microsoft SEAL同态加密库的Python封装
通过本章学习,我们不光掌握了差分隐私、同态加密和安全多方计算的根本原理,还深入理解了它们在通信开销方面的差异,以及如何根据具体应用场景选择符合的隐私保护技术。这些知识将帮助我们在现实应用中设计更加高效、安全的联邦学习体系。
清华大学全五版的《DeepSeek教程》完备的文档必要的朋友,关注我私信:deepseek 即可得到。
怎么样今天的内容还满意吗?再次感谢朋友们的观看,关注GZH:凡人的AI工具箱,复兴666,送您代价199的AI大礼包。末了,祝您早日实现财政自由,还请给个赞,谢谢!
免责声明:如果侵犯了您的权益,请联系站长,我们会及时删除侵权内容,谢谢合作!更多信息从访问主页:qidao123.com:ToB企服之家,中国第一个企服评测及商务社交产业平台。
欢迎光临 IT评测·应用市场-qidao123.com技术社区 (https://dis.qidao123.com/)
Powered by Discuz! X3.4