核心改进点说明计谋梯度优化通过Actor网络直接优化计谋,适应连续动作问题: θ n e w = θ o l d + α ∇ θ J ( θ ) \theta_{new} = \theta_{old} + \alpha \nabla_\theta J(\theta) θnew=θold+α∇θJ(θ) PG 网络更新 – 基于蒙特卡洛估计的 REINFORCE
∇ θ J ( θ ) ≈ ∑ t = 0 T − 1 ∇ θ log π θ ( a t ∣ s t ) G t ,where G t = ∑ t ′ = t T γ t ′ − t r t ′ \nabla_\theta J(\theta) \approx \sum_{t=0}^{T-1} \nabla_\theta \log \pi_\theta(a_t | s_t) G_t,\text{where } G_t = \sum_{t'=t}^{T} \gamma^{t' - t} r_{t'} ∇θJ(θ)≈t=0∑T−1∇θlogπθ(at∣st)Gt,where Gt=t′=t∑Tγt′−trt′ 详细网络更新公式推导
计谋更新目的:使得 θ \theta θ 计谋下得到的全部轨迹 τ \tau τ 的回报期望 R ˉ θ \bar{R}_\theta Rˉθ 最大化: 可以用 N 条轨迹的均值近似
τ = { s 1 , a 1 , r 1 , s 2 , a 2 , r 2 , … , s τ , a τ , r τ } \tau = \{s_1, a_1, r_1, s_2, a_2, r_2, \dots, s_\tau, a_\tau, r_\tau\} τ={s1,a1,r1,s2,a2,r2,…,sτ,aτ,rτ}
R ˉ θ = ∑ τ R ( τ ) P ( τ ∣ θ ) ≈ 1 N ∑ n N R ( τ n ) \bar{R}_\theta =\textcolor{red}{\sum_\tau} R(\tau) \textcolor{red}{P(\tau | \theta)} \approx \textcolor{blue}{\frac{1}{N} \sum_n^N}R(\tau^n) Rˉθ=τ∑R(τ)P(τ∣θ)≈N1n∑NR(τn)
盘算梯度 (近似)
∇ R ˉ θ = ∑ τ R ( τ ) ∇ P ( τ ∣ θ ) = ∑ τ R ( τ ) P ( τ ∣ θ ) ∇ P ( τ ∣ θ ) P ( τ ∣ θ ) = ∑ τ R ( τ ) P ( τ ∣ θ ) ∇ θ log P ( τ ∣ θ ) ≈ 1 N ∑ n = 1 N R ( τ n ) ∇ θ log P ( τ n ∣ θ ) \nabla \bar{R}_\theta = \sum_{\tau} R(\tau) \nabla P(\tau | \theta) = \sum_\tau R(\tau) P(\tau | \theta) \frac{\nabla P(\tau | \theta)}{P(\tau | \theta)}=\textcolor{red}{\sum_\tau} R(\tau) \textcolor{red}{P(\tau | \theta)} \nabla_\theta \log P(\tau | \theta)\\ \approx \textcolor{blue}{\frac{1}{N} \sum_{n=1}^N} R(\tau^n) \nabla_\theta \log P(\tau^n | \theta) ∇Rˉθ=τ∑R(τ)∇P(τ∣θ)=τ∑R(τ)P(τ∣θ)P(τ∣θ)∇P(τ∣θ)=τ∑R(τ)P(τ∣θ)∇θlogP(τ∣θ)≈N1n=1∑NR(τn)∇θlogP(τn∣θ)
注:转为 log 时利用了公式 d log ( f ( x ) ) d x = 1 f ( x ) ⋅ d f ( x ) d x \frac{d \log(f(x))}{dx} = \frac{1}{f(x)} \cdot \frac{d f(x)}{dx} dxdlog(f(x))=f(x)1⋅dxdf(x)
其中, ∇ θ log P ( τ n ∣ θ ) \nabla_\theta\log P(\tau^n | \theta) ∇θlogP(τn∣θ) 可以做进一步表现
P ( τ ∣ θ ) = p ( s 1 ) ∏ t = 1 T p ( a t ∣ s t , θ ) p ( r t , s t + 1 ∣ s t , a t ) log P ( τ ∣ θ ) = log p ( s 1 ) + ∑ t = 1 T log p ( a t ∣ s t , θ ) + log p ( r t , s t + 1 ∣ s t , a t ) ∇ θ log P ( τ ∣ θ ) = ∑ t = 1 T ∇ θ log p ( a t ∣ s t , θ ) P(\tau|\theta) = p(s_1) \prod_{t=1}^{T} p(a_t|s_t, \theta) p(r_t, s_{t+1}|s_t, a_t) \\ \log P(\tau|\theta) = \log p(s_1) + \sum_{t=1}^{T} \log p(a_t|s_t, \theta) + \log p(r_t, s_{t+1}|s_t, a_t)\\ \nabla_\theta\log P(\tau | \theta) = \sum_{t=1}^{T} \nabla_\theta \log p(a_t | s_t, \theta) P(τ∣θ)=p(s1)t=1∏Tp(at∣st,θ)p(rt,st+1∣st,at)logP(τ∣θ)=logp(s1)+t=1∑Tlogp(at∣st,θ)+logp(rt,st+1∣st,at)∇θlogP(τ∣θ)=t=1∑T∇θlogp(at∣st,θ)
以是梯度 (近似)的表现更新为
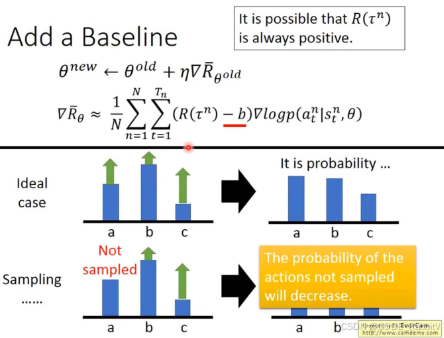
∇ R ˉ θ ≈ 1 N ∑ n = 1 N ∑ t = 1 T n R ( τ n ) ∇ θ log p ( a t n ∣ s t n , θ ) \nabla \bar{R}_\theta \approx {\frac{1}{N} \sum_{n=1}^N} \sum_{t=1}^{T^n} R(\tau^n) \nabla_\theta \log p(a_t^n | s_t^n, \theta) ∇Rˉθ≈N1n=1∑Nt=1∑TnR(τn)∇θlogp(atn∣stn,θ)
注:梯度用的是总的回报 R ( τ n ) R(\tau^n) R(τn) 而不是 a t n a_t^n atn 对应的即时嘉奖,也就是说,总的回报会加强/减弱轨迹上全部有利/有害的动作输出;进一步,由于对于第 t 个step,所选择的动作只会影响未来的 U t n = ∑ t T n r t n U^n_t = \sum_t^{T^n} r^n_t Utn=t∑Tnrtn 以是 R ( τ n ) R(\tau^n) R(τn) 可以被优化为 U t n U^n_t Utn,对应本文一开始所给出的梯度公式
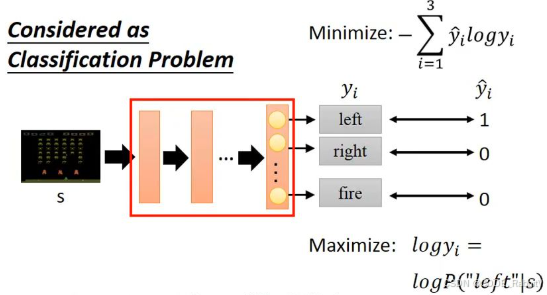
关于如何明确这个梯度,李宏毅老师类比分类学习的讲法也很有开导,强烈推荐学习下 【PG 李宏毅 B 站】