qidao123.com技术社区-IT企服评测·应用市场
标题:
Ubuntu22.04/24.04 P104-100 安装驱动和 CUDA Toolkit
[打印本页]
作者:
盛世宏图
时间:
2025-4-27 23:42
标题:
Ubuntu22.04/24.04 P104-100 安装驱动和 CUDA Toolkit
硬件环境
使用一块技嘉 B85m-DS3H 安装 P104-100, CPU是带集成显卡的i5-4690. 先在BIOS中设置好显示设备优先使用集成显卡(IGX). 然后安装P104-100开机. 登入Ubuntu 后检察硬件信息, 检查P104-100是否已经被检测到
# PCI设备
lspci -v | grep -i nvidia
lspci | grep NVIDIA
# 查看显示设备
sudo lshw -C display
复制代码
安装驱动
安装前删除原有的 nvidia 驱动
sudo apt purge 'nvidia-*'
sudo apt autoremove --purge
sudo apt clean
复制代码
驱动有两种安装方式
使用 ubuntu 堆栈的 nvidia 驱动(nvidia开头)
sudo add-apt-repository ppa:graphics-drivers/ppa
sudo apt update
复制代码
列出驱动的各个版本
ubuntu-drivers devices
复制代码
选择必要的版本安装, 例如 对应CUDA12.4是nvidia-driver-550
sudo apt install nvidia-driver-XXX
复制代码
使用 nvidia 的驱动堆栈(cuda开头)
Doc:
https://docs.nvidia.com/datacenter/tesla/driver-installation-guide/index.html
先下载对应Ubuntu版本的 cuda-keyring
Ubuntu22.04
https://developer.download.nvidia.cn/compute/cuda/repos/ubuntu2204/x86_64/cuda-keyring_1.1-1_all.deb
Ubuntu24.04
https://developer.download.nvidia.cn/compute/cuda/repos/ubuntu2404/x86_64/cuda-keyring_1.1-1_all.deb
用dpkg安装, 然后apt update一下
sudo dpkg -i cuda-keyring_1.1-1_all.deb
sudo apt update
复制代码
这时候可以查询到能安装的版本
apt-cache search cuda-drivers-*
复制代码
挑选自己必要的版本安装, 例如 cuda-drivers-550对应CUDA12.4, cuda-drivers-570对应CUDA12.8, 如果直接安装 cuda-drivers, 会默认安装当前稳定版的最高版本
sudo apt install cuda-drivers-550
复制代码
检查驱动安装结果
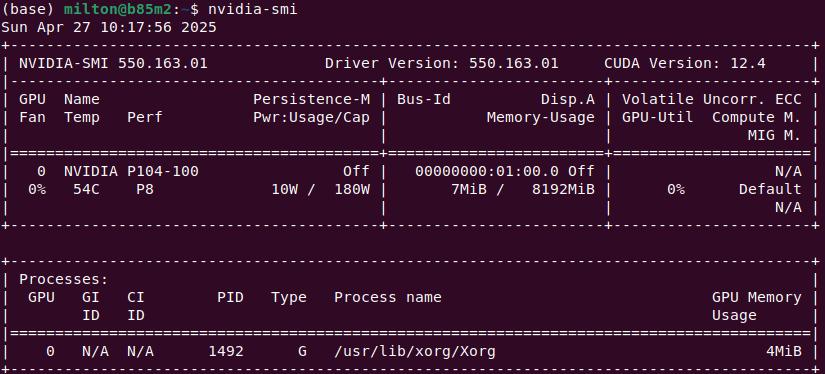
驱动安装完成后重启, 此时应该就可以直接运行 nvidia-smi 检察显卡信息了.
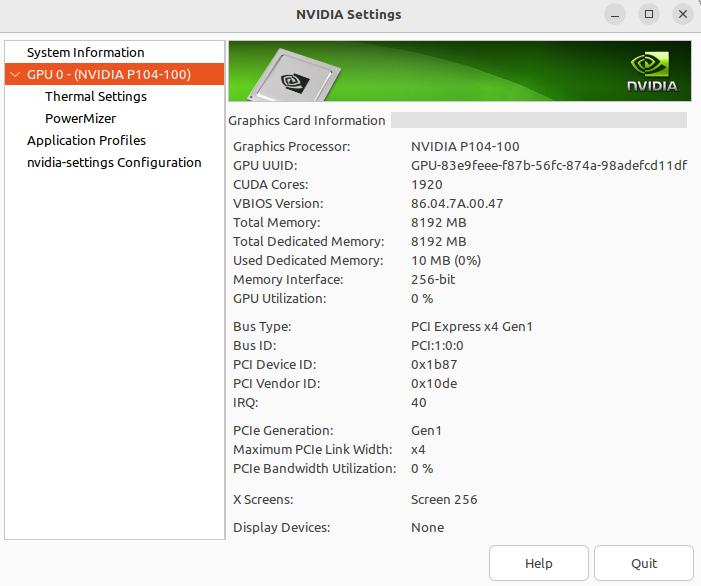
在桌面环境下, 可以直接检察图形界面 Nvidia X Server Settings
# 查看 NVIDIA 内核模块是否加载
lsmod | grep nvidia
# 查看dmesg日志
dmesg | grep -i nvidia
复制代码
另外可以安装两个有用的小工具 nvtop 和 vulkaninfo
nvtop
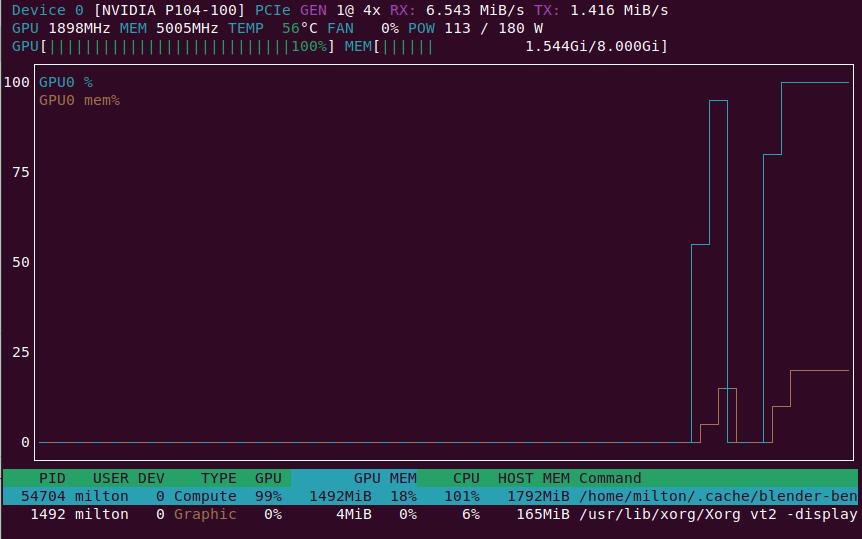
nvtop 可以在命令行下以图形化的方式显示显卡当前的运行状态, 比nvidia-smi -l命令更直观好用
# install
sudo apt install nvtop
# usage
nvtop
复制代码
vulkaninfo
vulkaninfo 可以列出当前体系的GPU信息
# install
sudo apt install vulkan-tools
# show GPU info
vulkaninfo --summary
复制代码
使用prime-select切换集成显卡和Nvidia显卡
安装P104-100后, 体系中可以看到同时存在集成显卡 Intel(R) HD Graphics 4600 和 NVIDIA P104-100, 可以通过 prime-select 切换使用的显卡
# 查询, 默认为 on-demand
prime-select query
# 设置为 P104-100
prime-select nvidia
# 设置为集成显卡
prime-select intel
复制代码
Ubuntu 对于 hybrid graphics 的支持很不错, 安装完驱动后, 步伐已经可以自动选择用哪块显卡, 例如运行 minetest, 就会自动选择 P104-100.
性能测试
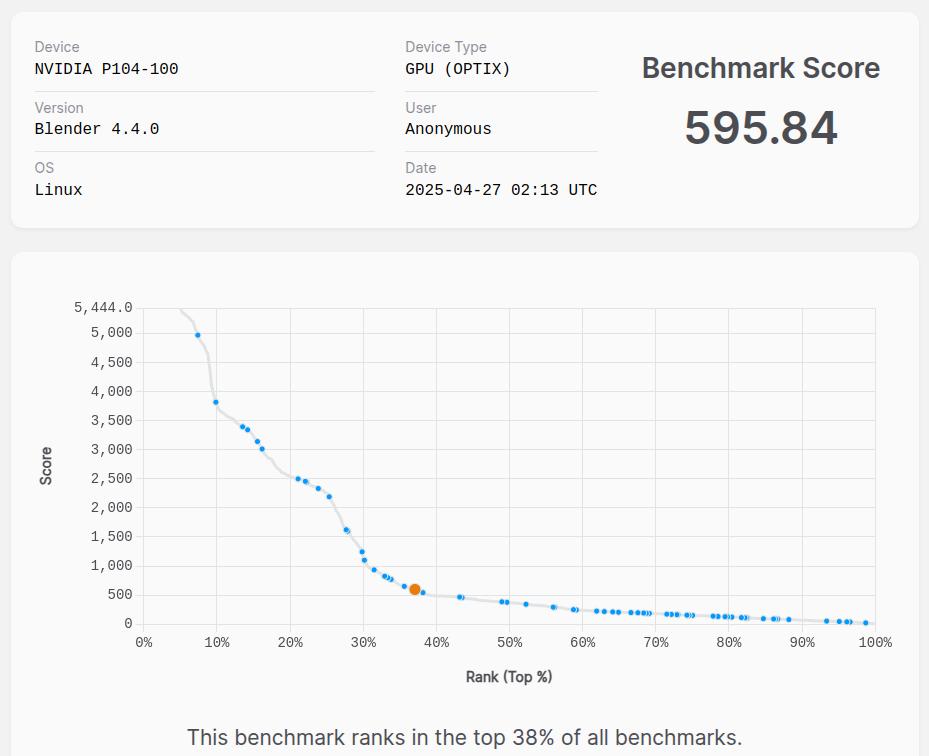
在Ubuntu下可以通过 Blender 的 Blender Benchmark 检测显卡性能, 网站:
https://opendata.blender.org/
, 进行测试前会提示要下载800多M的文件.
P104-100的运行结果分数为 58x~59x 之间, 在首页上有CPU和GPU的排行数据, 可以看到 P104-100的性能和 GTX1080, GTX1070Ti 差不多. 作为对比, i5 4690 集成显卡的测试结果分数只有 51.91, 与 P104-100 相比差距明显.
安装 CUDA Toolkit
使用apt安装
在Ubuntu下可以直接用apt安装CUDA toolkit, 但是这样安装后toolkit的路径是分散的, 不在 /usr/local/cuda 下, 有时候会造成困惑, 建议用 Nvida 提供的安装包进行安装
使用Nvidia提供的安装包
从历史版本列表
https://developer.nvidia.com/cuda-toolkit-archive
选择安装对应当前硬件驱动的 CUDA Toolkit. 对应上面安装的 CUDA 版本为12.4, 因此下载 Cuda Toolkit 12.4. 页面会提供三种安装方式 deb(local), deb(network), runfile(local), 新手用户建议使用前两种, 因为runfile 涉及现场编译, 大概率中间过程会报错. deb(local)和deb(network)的区别就是有一个差不多4G大小的文件, 是先下载到本地了再 apt install, 还是先 apt install完在安装过程中从网络下载. 如果网络不是特别好, 网速不是特别快的, 建议使用 deb(local).
这个是界面上提示的安装命令
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-ubuntu2204.pin
sudo mv cuda-ubuntu2204.pin /etc/apt/preferences.d/cuda-repository-pin-600
wget https://developer.download.nvidia.com/compute/cuda/12.4.1/local_installers/cuda-repo-ubuntu2204-12-4-local_12.4.1-550.54.15-1_amd64.deb
dpkg -i cuda-repo-ubuntu2204-12-4-local_12.4.1-550.54.15-1_amd64.deb
cp /var/cuda-repo-ubuntu2204-12-4-local/cuda-*-keyring.gpg /usr/share/keyrings/
apt update
apt install cuda-toolkit-12-4
复制代码
CUDA的默认安装位置是 /usr/loca/cuda, 安装完成后检查安装结果
/usr/local/cuda/bin/nvcc -V
复制代码
通过这种方式安装的CUDA toolkit 是不会设置用户环境变量的, 必要手动在 .bashrc 里添加一下
export CUDA_HOME=/usr/local/cuda
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:$CUDA_HOME/lib64
export PATH=$PATH:$CUDA_HOME/bin
复制代码
运行 TorchBench
项目地址:
https://github.com/pytorch/benchmark
CUDA Device Query
[CUDA Bandwidth Test] - Starting...
Running on...
Device 0: NVIDIA P104-100
Quick Mode
Host to Device Bandwidth, 1 Device(s)
PINNED Memory Transfers
Transfer Size (Bytes) Bandwidth(GB/s)
32000000 0.4
Device to Host Bandwidth, 1 Device(s)
PINNED Memory Transfers
Transfer Size (Bytes) Bandwidth(GB/s)
32000000 0.4
Device to Device Bandwidth, 1 Device(s)
PINNED Memory Transfers
Transfer Size (Bytes) Bandwidth(GB/s)
32000000 284.0
Result = PASS
复制代码
CUDA Device Query
CUDA Device Query (Runtime API) version (CUDART static linking)
Detected 1 CUDA Capable device(s)
Device 0: "NVIDIA P104-100"
CUDA Driver Version / Runtime Version 12.4 / 12.0
CUDA Capability Major/Minor version number: 6.1
Total amount of global memory: 8109 MBytes (8503230464 bytes)
(015) Multiprocessors, (128) CUDA Cores/MP: 1920 CUDA Cores
GPU Max Clock rate: 1734 MHz (1.73 GHz)
Memory Clock rate: 5005 Mhz
Memory Bus Width: 256-bit
L2 Cache Size: 2097152 bytes
Maximum Texture Dimension Size (x,y,z) 1D=(131072), 2D=(131072, 65536), 3D=(16384, 16384, 16384)
Maximum Layered 1D Texture Size, (num) layers 1D=(32768), 2048 layers
Maximum Layered 2D Texture Size, (num) layers 2D=(32768, 32768), 2048 layers
Total amount of constant memory: 65536 bytes
Total amount of shared memory per block: 49152 bytes
Total shared memory per multiprocessor: 98304 bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per multiprocessor: 2048
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
Maximum memory pitch: 2147483647 bytes
Texture alignment: 512 bytes
Concurrent copy and kernel execution: Yes with 2 copy engine(s)
Run time limit on kernels: Yes
Integrated GPU sharing Host Memory: No
Support host page-locked memory mapping: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Disabled
Device supports Unified Addressing (UVA): Yes
Device supports Managed Memory: Yes
Device supports Compute Preemption: Yes
Supports Cooperative Kernel Launch: Yes
Supports MultiDevice Co-op Kernel Launch: Yes
Device PCI Domain ID / Bus ID / location ID: 0 / 1 / 0
Compute Mode:
< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 12.4, CUDA Runtime Version = 12.0, NumDevs = 1
Result = PASS
复制代码
免责声明:如果侵犯了您的权益,请联系站长,我们会及时删除侵权内容,谢谢合作!更多信息从访问主页:qidao123.com:ToB企服之家,中国第一个企服评测及商务社交产业平台。
欢迎光临 qidao123.com技术社区-IT企服评测·应用市场 (https://dis.qidao123.com/)
Powered by Discuz! X3.4